 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting with Confidence on Unseen Distributions
Jul 07, 2021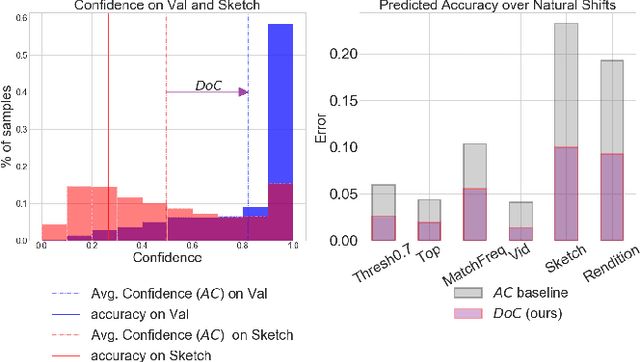
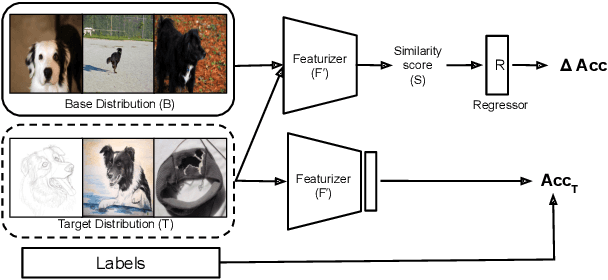
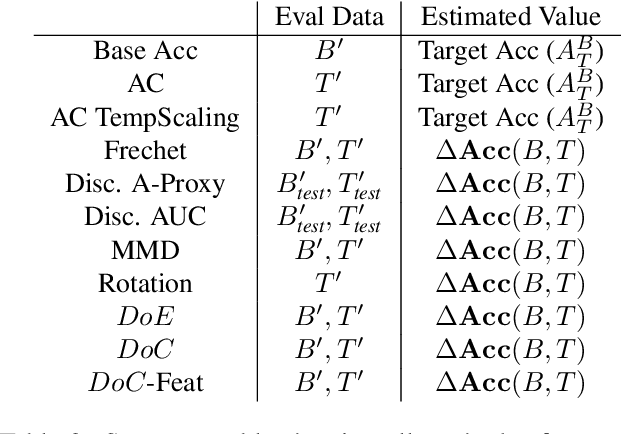
Recent work has shown that the performance of machine learning models can vary substantially when models are evaluated on data drawn from a distribution that is close to but different from the training distribution. As a result, predicting model performance on unseen distributions is an important challenge. Our work connects techniques from domain adaptation and predictive uncertainty literature, and allows us to predict model accuracy on challenging unseen distributions without access to labeled data. In the context of distribution shift, distributional distances are often used to adapt models and improve their performance on new domains, however accuracy estimation, or other forms of predictive uncertainty, are often neglected in these investigations. Through investigating a wide range of established distributional distances, such as Frechet distance or Maximum Mean Discrepancy, we determine that they fail to induce reliable estimates of performance under distribution shift. On the other hand, we find that the difference of confidences (DoC) of a classifier's predictions successfully estimates the classifier's performance change over a variety of shifts. We specifically investigate the distinction between synthetic and natural distribution shifts and observe that despite its simplicity DoC consistently outperforms other quantifications of distributional difference. $DoC$ reduces predictive error by almost half ($46\%$) on several realistic and challenging distribution shifts, e.g., on the ImageNet-Vid-Robust and ImageNet-Rendition datasets.
CLIP-It! Language-Guided Video Summarization
Jul 01, 2021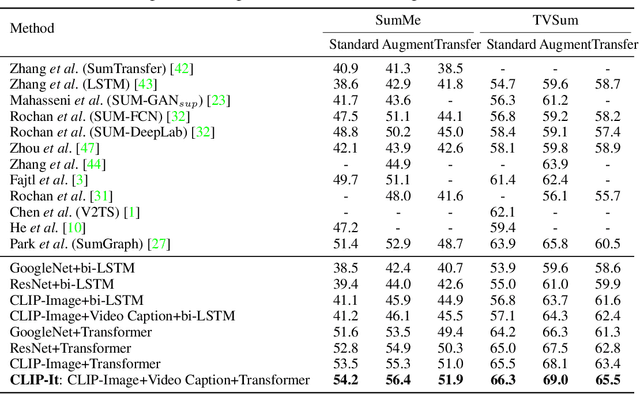
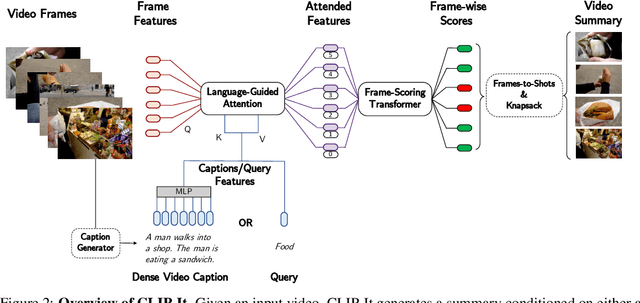
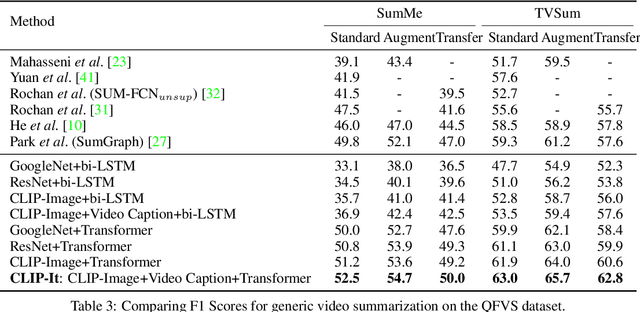
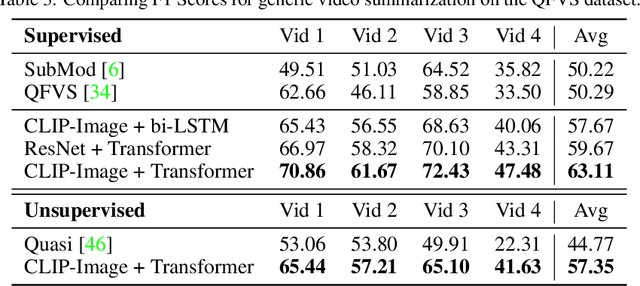
A generic video summary is an abridged version of a video that conveys the whole story and features the most important scenes. Yet the importance of scenes in a video is often subjective, and users should have the option of customizing the summary by using natural language to specify what is important to them. Further, existing models for fully automatic generic summarization have not exploited available language models, which can serve as an effective prior for saliency. This work introduces CLIP-It, a single framework for addressing both generic and query-focused video summarization, typically approached separately in the literature. We propose a language-guided multimodal transformer that learns to score frames in a video based on their importance relative to one another and their correlation with a user-defined query (for query-focused summarization) or an automatically generated dense video caption (for generic video summarization). Our model can be extended to the unsupervised setting by training without ground-truth supervision. We outperform baselines and prior work by a significant margin on both standard video summarization datasets (TVSum and SumMe) and a query-focused video summarization dataset (QFVS). Particularly, we achieve large improvements in the transfer setting, attesting to our method's strong generalization capabilities.
Towards Learning to Play Piano with Dexterous Hands and Touch
Jun 08, 2021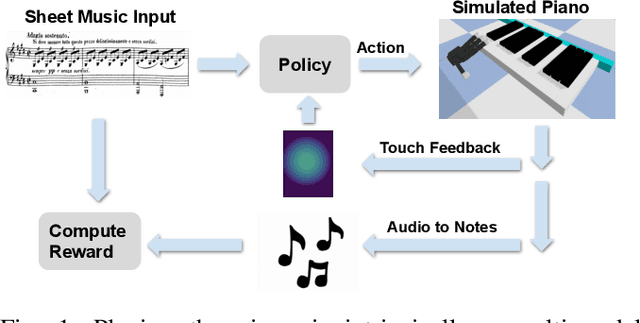
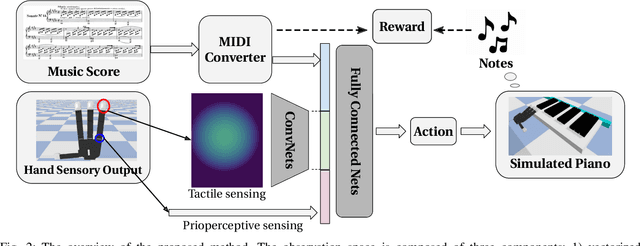

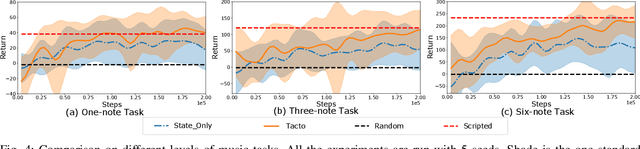
The virtuoso plays the piano with passion, poetry and extraordinary technical ability. As Liszt said (a virtuoso)must call up scent and blossom, and breathe the breath of life. The strongest robots that can play a piano are based on a combination of specialized robot hands/piano and hardcoded planning algorithms. In contrast to that, in this paper, we demonstrate how an agent can learn directly from machine-readable music score to play the piano with dexterous hands on a simulated piano using reinforcement learning (RL) from scratch. We demonstrate the RL agents can not only find the correct key position but also deal with various rhythmic, volume and fingering, requirements. We achieve this by using a touch-augmented reward and a novel curriculum of tasks. We conclude by carefully studying the important aspects to enable such learning algorithms and that can potentially shed light on future research in this direction.
DETReg: Unsupervised Pretraining with Region Priors for Object Detection
Jun 08, 2021
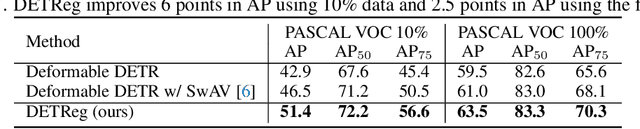
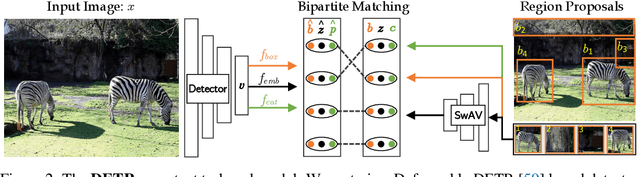
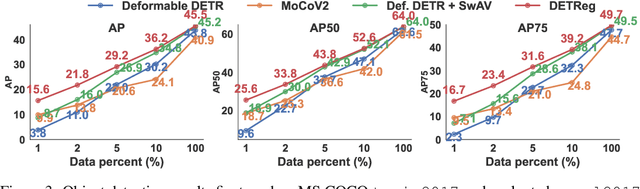
Unsupervised pretraining has recently proven beneficial for computer vision tasks, including object detection. However, previous self-supervised approaches are not designed to handle a key aspect of detection: localizing objects. Here, we present DETReg, an unsupervised pretraining approach for object DEtection with TRansformers using Region priors. Motivated by the two tasks underlying object detection: localization and categorization, we combine two complementary signals for self-supervision. For an object localization signal, we use pseudo ground truth object bounding boxes from an off-the-shelf unsupervised region proposal method, Selective Search, which does not require training data and can detect objects at a high recall rate and very low precision. The categorization signal comes from an object embedding loss that encourages invariant object representations, from which the object category can be inferred. We show how to combine these two signals to train the Deformable DETR detection architecture from large amounts of unlabeled data. DETReg improves the performance over competitive baselines and previous self-supervised methods on standard benchmarks like MS COCO and PASCAL VOC. DETReg also outperforms previous supervised and unsupervised baseline approaches on low-data regime when trained with only 1%, 2%, 5%, and 10% of the labeled data on MS COCO. For code and pretrained models, visit the project page at https://amirbar.net/detreg
PyTouch: A Machine Learning Library for Touch Processing
May 26, 2021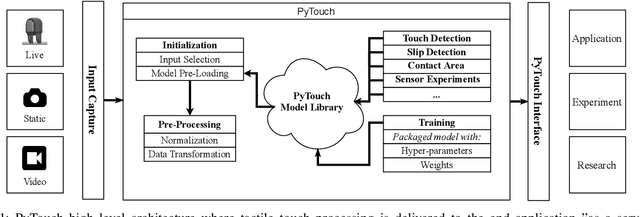
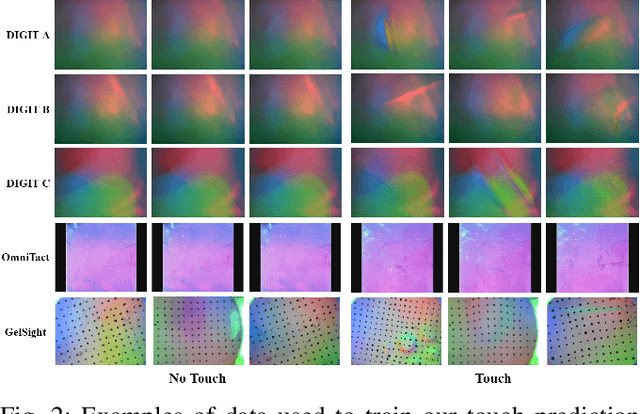
With the increased availability of rich tactile sensors, there is an equally proportional need for open-source and integrated software capable of efficiently and effectively processing raw touch measurements into high-level signals that can be used for control and decision-making. In this paper, we present PyTouch -- the first machine learning library dedicated to the processing of touch sensing signals. PyTouch, is designed to be modular, easy-to-use and provides state-of-the-art touch processing capabilities as a service with the goal of unifying the tactile sensing community by providing a library for building scalable, proven, and performance-validated modules over which applications and research can be built upon. We evaluate PyTouch on real-world data from several tactile sensors on touch processing tasks such as touch detection, slip and object pose estimations. PyTouch is open-sourced at https://github.com/facebookresearch/pytouch .
Fighting Gradients with Gradients: Dynamic Defenses against Adversarial Attacks
May 18, 2021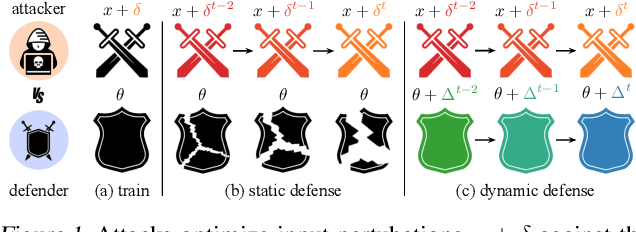
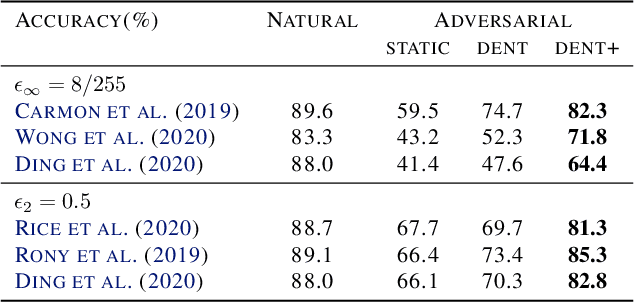


Adversarial attacks optimize against models to defeat defenses. Existing defenses are static, and stay the same once trained, even while attacks change. We argue that models should fight back, and optimize their defenses against attacks at test time. We propose dynamic defenses, to adapt the model and input during testing, by defensive entropy minimization (dent). Dent alters testing, but not training, for compatibility with existing models and train-time defenses. Dent improves the robustness of adversarially-trained defenses and nominally-trained models against white-box, black-box, and adaptive attacks on CIFAR-10/100 and ImageNet. In particular, dent boosts state-of-the-art defenses by 20+ points absolute against AutoAttack on CIFAR-10 at $\epsilon_\infty$ = 8/255.
Robust Object Detection via Instance-Level Temporal Cycle Confusion
Apr 16, 2021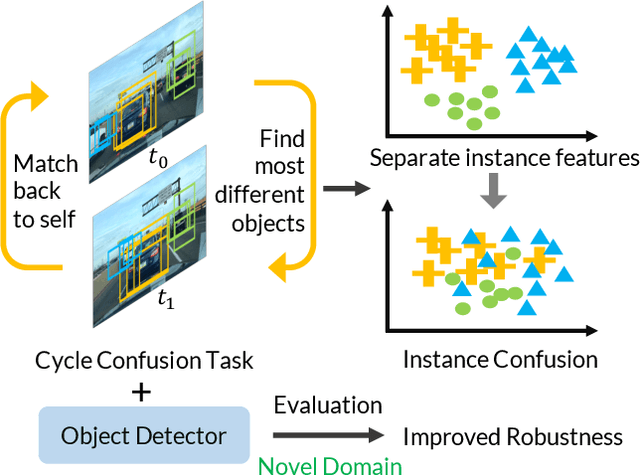
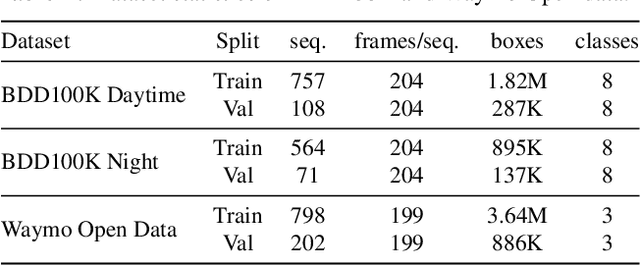
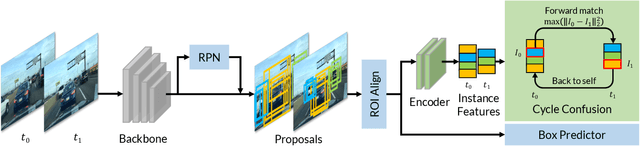
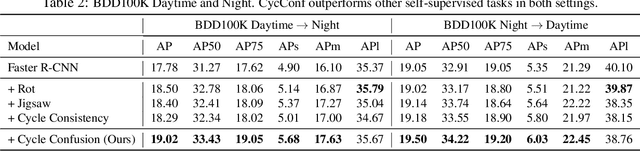
Building reliable object detectors that are robust to domain shifts, such as various changes in context, viewpoint, and object appearances, is critical for real-world applications. In this work, we study the effectiveness of auxiliary self-supervised tasks to improve the out-of-distribution generalization of object detectors. Inspired by the principle of maximum entropy, we introduce a novel self-supervised task, instance-level temporal cycle confusion (CycConf), which operates on the region features of the object detectors. For each object, the task is to find the most different object proposals in the adjacent frame in a video and then cycle back to itself for self-supervision. CycConf encourages the object detector to explore invariant structures across instances under various motions, which leads to improved model robustness in unseen domains at test time. We observe consistent out-of-domain performance improvements when training object detectors in tandem with self-supervised tasks on large-scale video datasets (BDD100K and Waymo open data). The joint training framework also establishes a new state-of-the-art on standard unsupervised domain adaptative detection benchmarks (Cityscapes, Foggy Cityscapes, and Sim10K). The project page is available at https://xinw.ai/cyc-conf.
Auto-Tuned Sim-to-Real Transfer
Apr 15, 2021
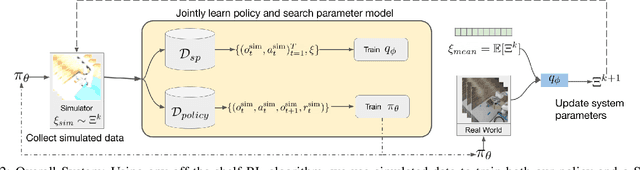
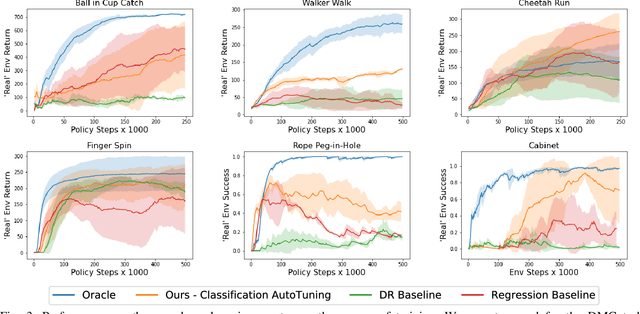
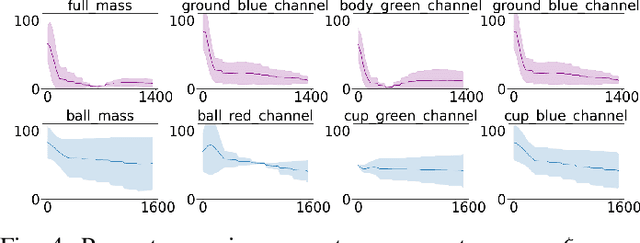
Policies trained in simulation often fail when transferred to the real world due to the `reality gap' where the simulator is unable to accurately capture the dynamics and visual properties of the real world. Current approaches to tackle this problem, such as domain randomization, require prior knowledge and engineering to determine how much to randomize system parameters in order to learn a policy that is robust to sim-to-real transfer while also not being too conservative. We propose a method for automatically tuning simulator system parameters to match the real world using only raw RGB images of the real world without the need to define rewards or estimate state. Our key insight is to reframe the auto-tuning of parameters as a search problem where we iteratively shift the simulation system parameters to approach the real-world system parameters. We propose a Search Param Model (SPM) that, given a sequence of observations and actions and a set of system parameters, predicts whether the given parameters are higher or lower than the true parameters used to generate the observations. We evaluate our method on multiple robotic control tasks in both sim-to-sim and sim-to-real transfer, demonstrating significant improvement over naive domain randomization. Project videos and code at https://yuqingd.github.io/autotuned-sim2real/
NewsCLIPpings: Automatic Generation of Out-of-Context Multimodal Media
Apr 13, 2021
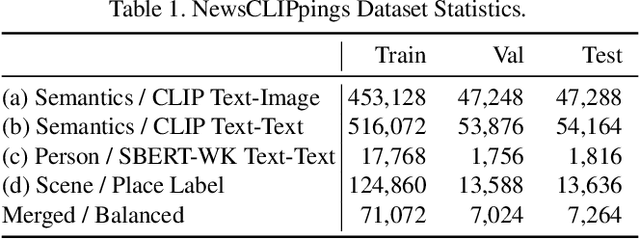

The threat of online misinformation is hard to overestimate, with adversaries relying on a range of tools, from cheap fakes to sophisticated deep fakes. We are motivated by a threat scenario where an image is being used out of context to support a certain narrative expressed in a caption. While some prior datasets for detecting image-text inconsistency can be solved with blind models due to linguistic cues introduced by text manipulation, we propose a dataset where both image and text are unmanipulated but mismatched. We introduce several strategies for automatic retrieval of suitable images for the given captions, capturing cases with related semantics but inconsistent entities as well as matching entities but inconsistent semantic context. Our large-scale automatically generated NewsCLIPpings Dataset requires models to jointly analyze both modalities and to reason about entity mismatch as well as semantic mismatch between text and images in news media.
Strumming to the Beat: Audio-Conditioned Contrastive Video Textures
Apr 06, 2021
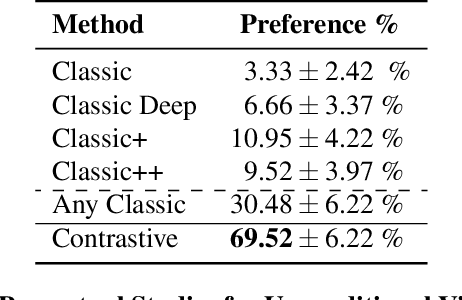

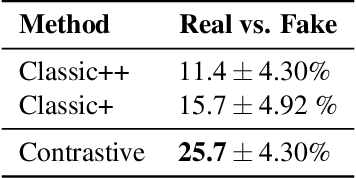
We introduce a non-parametric approach for infinite video texture synthesis using a representation learned via contrastive learning. We take inspiration from Video Textures, which showed that plausible new videos could be generated from a single one by stitching its frames together in a novel yet consistent order. This classic work, however, was constrained by its use of hand-designed distance metrics, limiting its use to simple, repetitive videos. We draw on recent techniques from self-supervised learning to learn this distance metric, allowing us to compare frames in a manner that scales to more challenging dynamics, and to condition on other data, such as audio. We learn representations for video frames and frame-to-frame transition probabilities by fitting a video-specific model trained using contrastive learning. To synthesize a texture, we randomly sample frames with high transition probabilities to generate diverse temporally smooth videos with novel sequences and transitions. The model naturally extends to an audio-conditioned setting without requiring any finetuning. Our model outperforms baselines on human perceptual scores, can handle a diverse range of input videos, and can combine semantic and audio-visual cues in order to synthesize videos that synchronize well with an audio signal.