 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscreTalk: Text-to-Speech as a Machine Translation Problem
May 12, 2020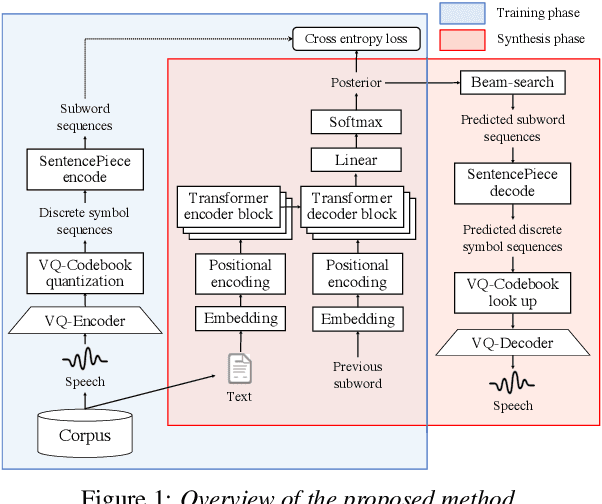

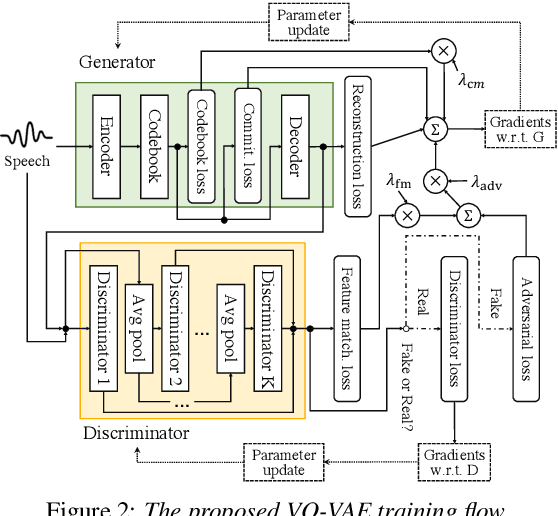

This paper proposes a new end-to-end text-to-speech (E2E-TTS) model based on neural machine translation (NMT). The proposed model consists of two components; a non-autoregressive vector quantized variational autoencoder (VQ-VAE) model and an autoregressive Transformer-NMT model. The VQ-VAE model learns a mapping function from a speech waveform into a sequence of discrete symbols, and then the Transformer-NMT model is trained to estimate this discrete symbol sequence from a given input text. Since the VQ-VAE model can learn such a mapping in a fully-data-driven manner, we do not need to consider hyperparameters of the feature extraction required in the conventional E2E-TTS models. Thanks to the use of discrete symbols, we can use various techniques developed in NMT and automatic speech recognition (ASR) such as beam search, subword units, and fusions with a language model. Furthermore, we can avoid an over smoothing problem of predicted features, which is one of the common issues in TTS. The experimental evaluation with the JSUT corpus shows that the proposed method outperforms the conventional Transformer-TTS model with a non-autoregressive neural vocoder in naturalness, achieving the performance comparable to the reconstruction of the VQ-VAE model.
ESPnet-ST: All-in-One Speech Translation Toolkit
Apr 21, 2020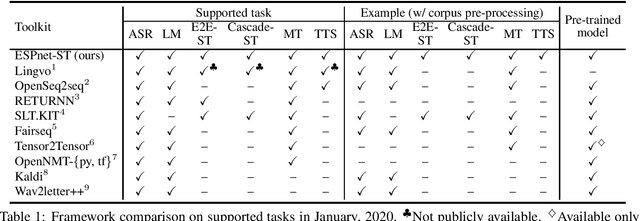
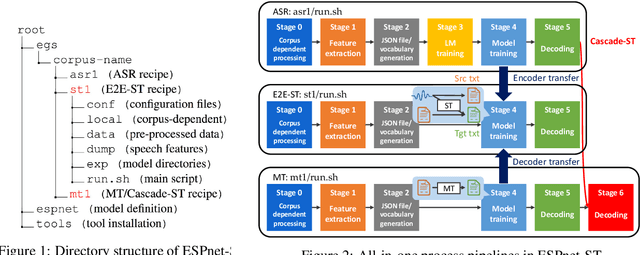


We present ESPnet-ST, which is designed for the quick development of speech-to-speech translation systems in a single framework. ESPnet-ST is a new project inside end-to-end speech processing toolkit, ESPnet, which integrates or newly implements automatic speech recognition, machine translation, and text-to-speech functions for speech translation. We provide all-in-one recipes including data pre-processing, feature extraction, training, and decoding pipelines for a wide range of benchmark datasets. Our reproducible results can match or even outperform the current state-of-the-art performances; these pre-trained models are downloadable. The toolkit is publicly available at https://github.com/espnet/espnet.
End-to-End Automatic Speech Recognition Integrated With CTC-Based Voice Activity Detection
Feb 14, 2020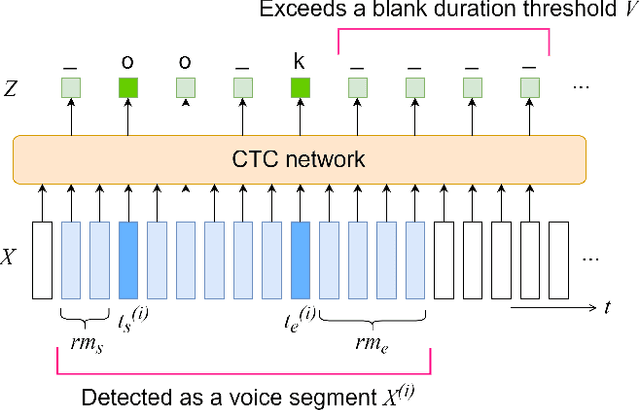
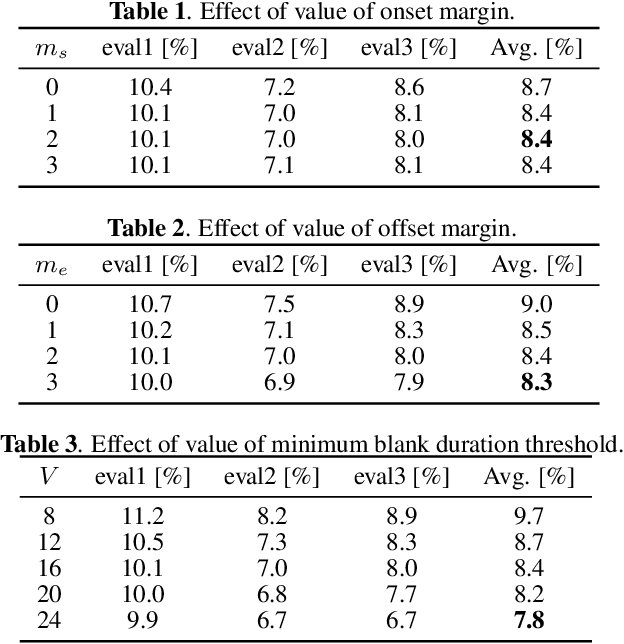
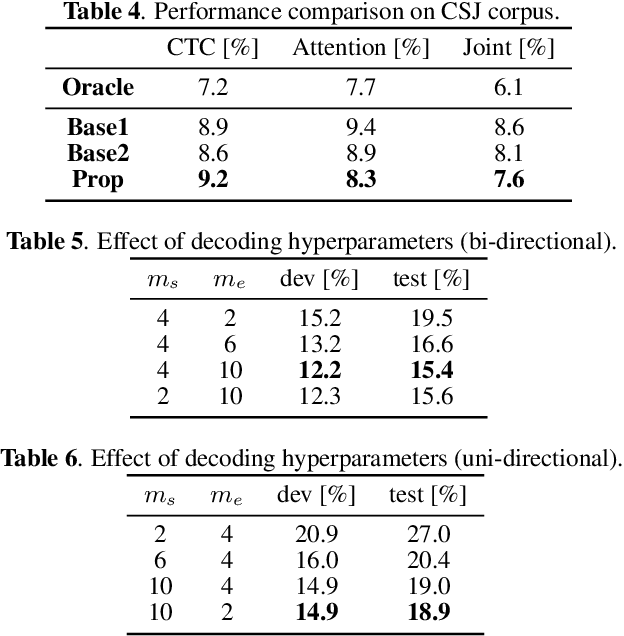

This paper integrates a voice activity detection (VAD) function with end-to-end automatic speech recognition toward an online speech interface and transcribing very long audio recordings. We focus on connectionist temporal classification (CTC) and its extension of CTC/attention architectures. As opposed to an attention-based architecture, input-synchronous label prediction can be performed based on a greedy search with the CTC (pre-)softmax output. This prediction includes consecutive long blank labels, which can be regarded as a non-speech region. We use the labels as a cue for detecting speech segments with simple thresholding. The threshold value is directly related to the length of a non-speech region, which is more intuitive and easier to control than conventional VAD hyperparameters. Experimental results on unsegmented data show that the proposed method outperformed the baseline methods using the conventional energy-based and neural-network-based VAD methods and achieved an RTF less than 0.2. The proposed method is publicly available.
Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining
Dec 14, 2019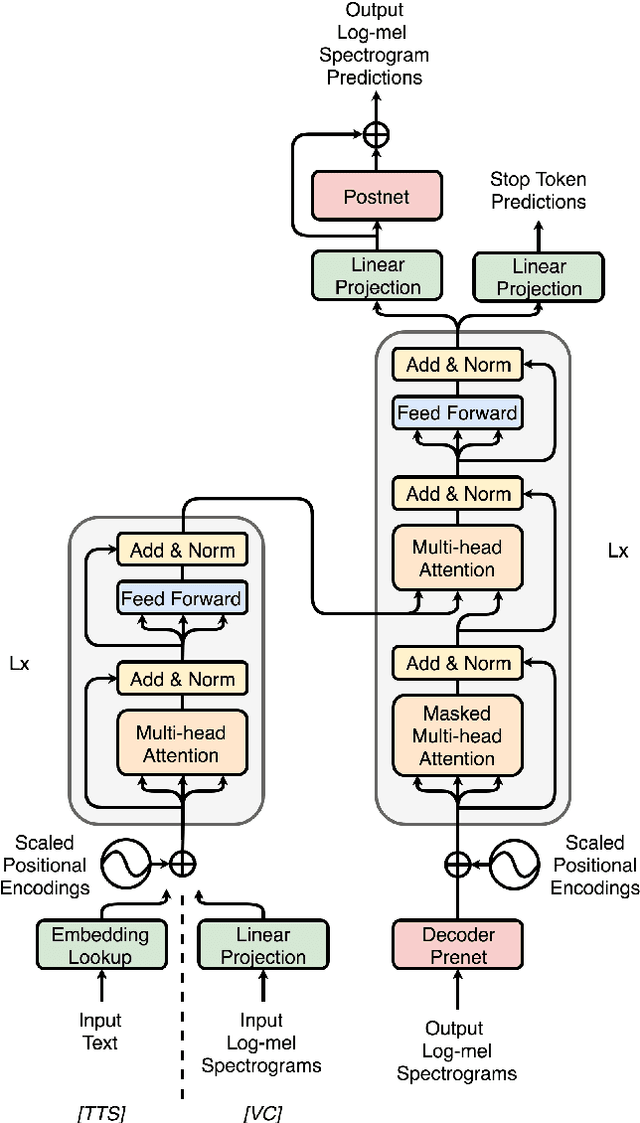
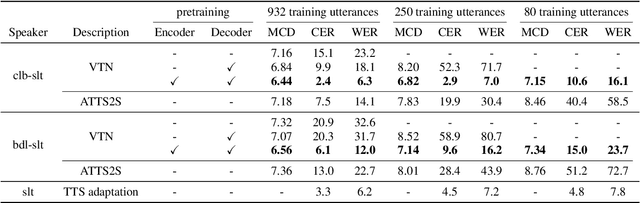
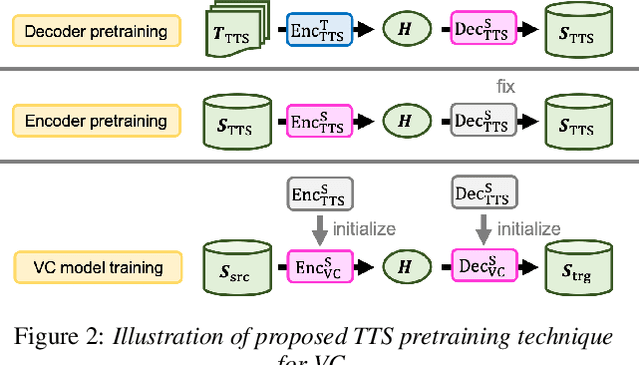
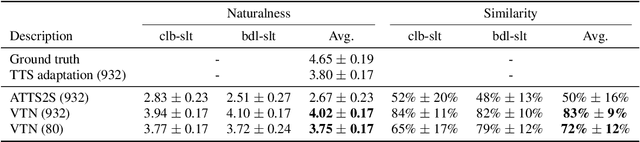
We introduce a novel sequence-to-sequence (seq2seq) voice conversion (VC) model based on the Transformer architecture with text-to-speech (TTS) pretraining. Seq2seq VC models are attractive owing to their ability to convert prosody. While seq2seq models based on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been successfully applied to VC, the use of the Transformer network, which has shown promising results in various speech processing tasks, has not yet been investigated. Nonetheless, their data-hungry property and the mispronunciation of converted speech make seq2seq models far from practical. To this end, we propose a simple yet effective pretraining technique to transfer knowledge from learned TTS models, which benefit from large-scale, easily accessible TTS corpora. VC models initialized with such pretrained model parameters are able to generate effective hidden representations for high-fidelity, highly intelligible converted speech. Experimental results show that such a pretraining scheme can facilitate data-efficient training and outperform an RNN-based seq2seq VC model in terms of intelligibility, naturalness, and similarity.
ESPnet-TTS: Unified, Reproducible, and Integratable Open Source End-to-End Text-to-Speech Toolkit
Oct 24, 2019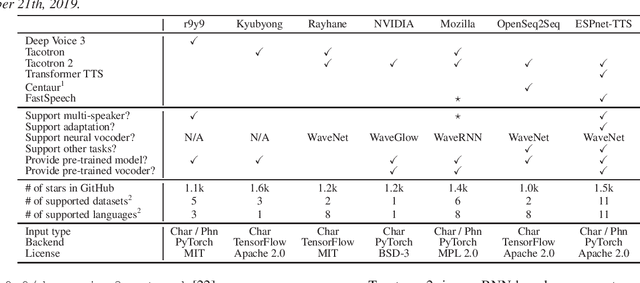
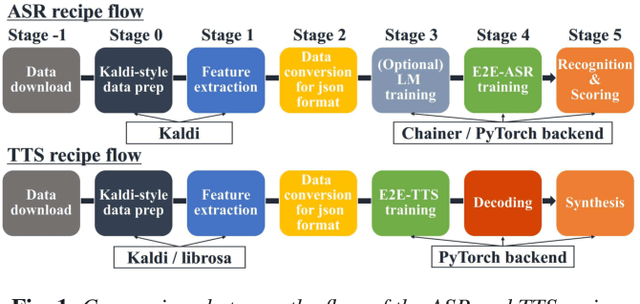
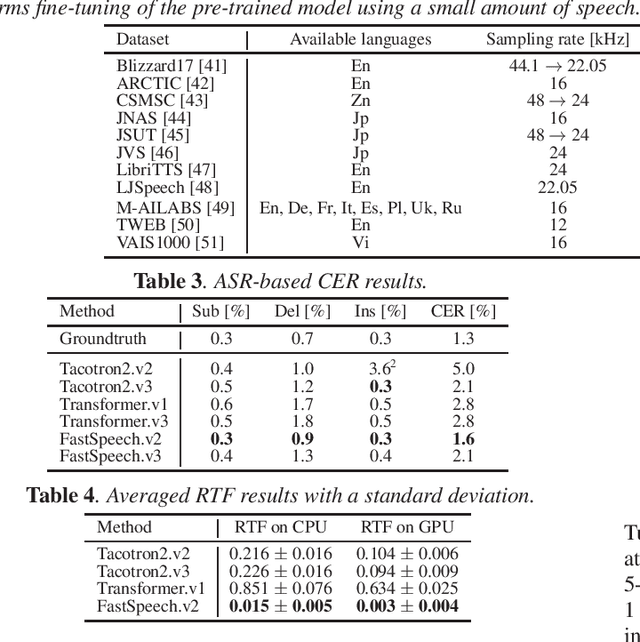
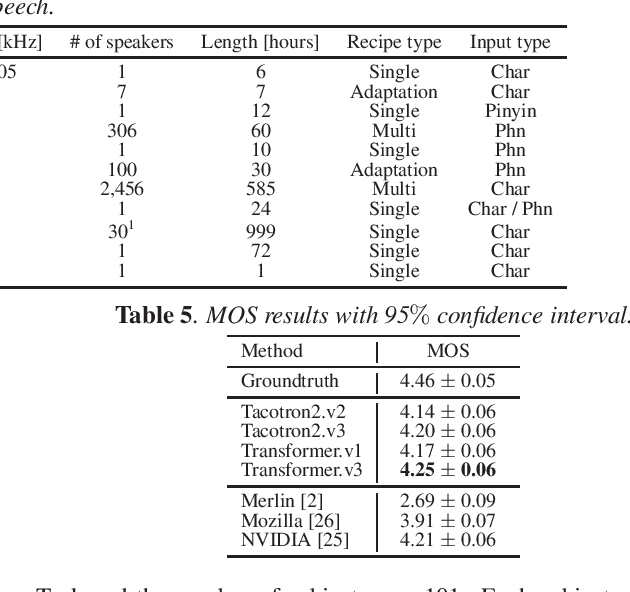
This paper introduces a new end-to-end text-to-speech (E2E-TTS) toolkit named ESPnet-TTS, which is an extension of the open-source speech processing toolkit ESPnet. The toolkit supports state-of-the-art E2E-TTS models, including Tacotron~2, Transformer TTS, and FastSpeech, and also provides recipes inspired by the Kaldi automatic speech recognition (ASR) toolkit. The recipes are based on the design unified with the ESPnet ASR recipe, providing high reproducibility. The toolkit also provides pre-trained models and samples of all of the recipes so that users can use it as a baseline. Furthermore, the unified design enables the integration of ASR functions with TTS, e.g., ASR-based objective evaluation and semi-supervised learning with both ASR and TTS models. This paper describes the design of the toolkit and experimental evaluation in comparison with other toolkits. The experimental results show that our best model outperforms other toolkits, resulting in a mean opinion score (MOS) of 4.25 on the LJSpeech dataset. The toolkit is available on GitHub.
A Comparative Study on Transformer vs RNN in Speech Applications
Sep 28, 2019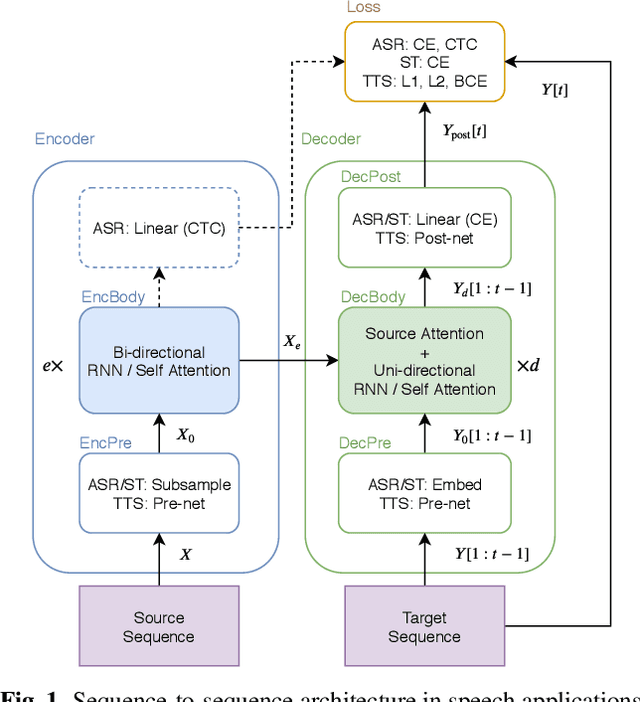
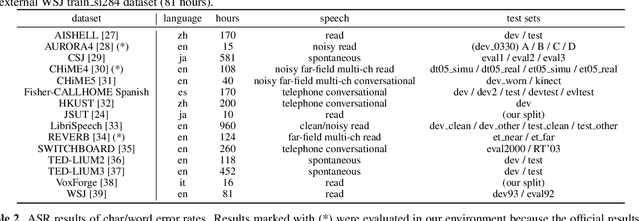
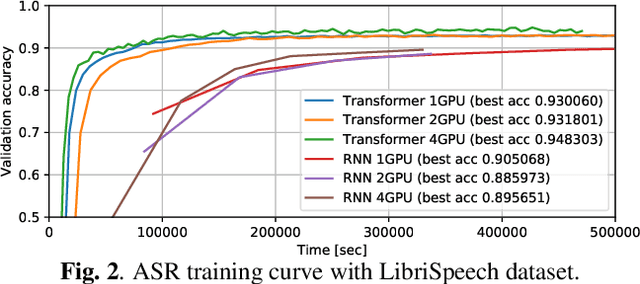
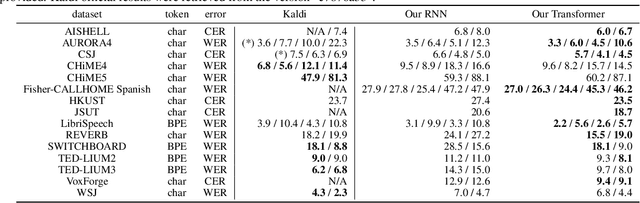
Sequence-to-sequence models have been widely used in end-to-end speech processing, for example, automatic speech recognition (ASR), speech translation (ST), and text-to-speech (TTS). This paper focuses on an emergent sequence-to-sequence model called Transformer, which achieves state-of-the-art performance in neural machine translation and other natural language processing applications. We undertook intensive studies in which we experimentally compared and analyzed Transformer and conventional recurrent neural networks (RNN) in a total of 15 ASR, one multilingual ASR, one ST, and two TTS benchmarks. Our experiments revealed various training tips and significant performance benefits obtained with Transformer for each task including the surprising superiority of Transformer in 13/15 ASR benchmarks in comparison with RNN. We are preparing to release Kaldi-style reproducible recipes using open source and publicly available datasets for all the ASR, ST, and TTS tasks for the community to succeed our exciting outcomes.
* Accepted at ASRU 2019
Non-Parallel Voice Conversion with Cyclic Variational Autoencoder
Jul 24, 2019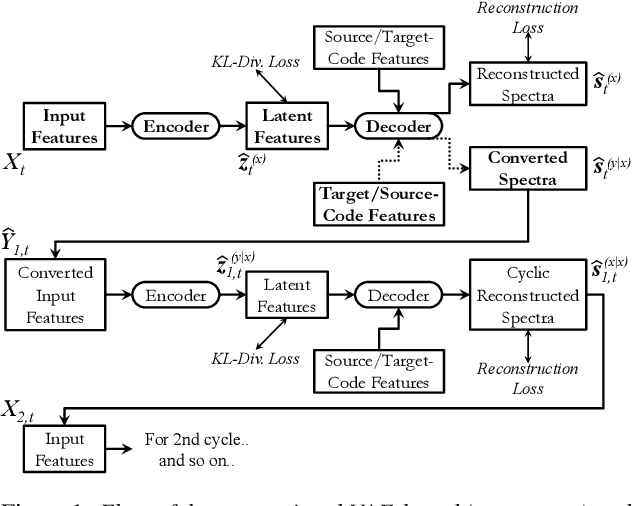
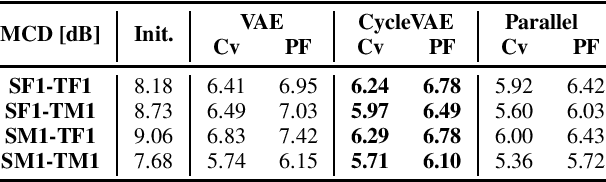
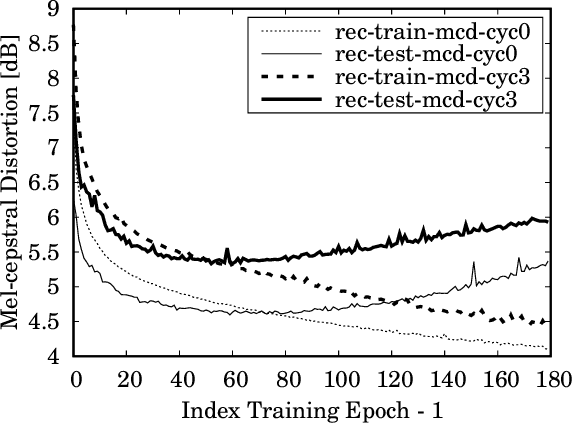
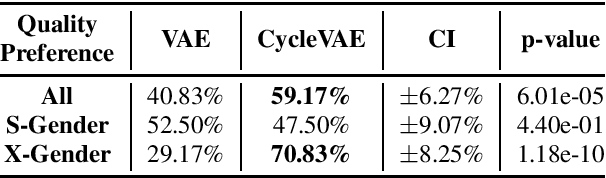
In this paper, we present a novel technique for a non-parallel voice conversion (VC) with the use of cyclic variational autoencoder (CycleVAE)-based spectral modeling. In a variational autoencoder(VAE) framework, a latent space, usually with a Gaussian prior, is used to encode a set of input features. In a VAE-based VC, the encoded latent features are fed into a decoder, along with speaker-coding features, to generate estimated spectra with either the original speaker identity (reconstructed) or another speaker identity (converted). Due to the non-parallel modeling condition, the converted spectra can not be directly optimized, which heavily degrades the performance of a VAE-based VC. In this work, to overcome this problem, we propose to use CycleVAE-based spectral model that indirectly optimizes the conversion flow by recycling the converted features back into the system to obtain corresponding cyclic reconstructed spectra that can be directly optimized. The cyclic flow can be continued by using the cyclic reconstructed features as input for the next cycle. The experimental results demonstrate the effectiveness of the proposed CycleVAE-based VC, which yields higher accuracy of converted spectra, generates latent features with higher correlation degree, and significantly improves the quality and conversion accuracy of the converted speech.
Refined WaveNet Vocoder for Variational Autoencoder Based Voice Conversion
Nov 27, 2018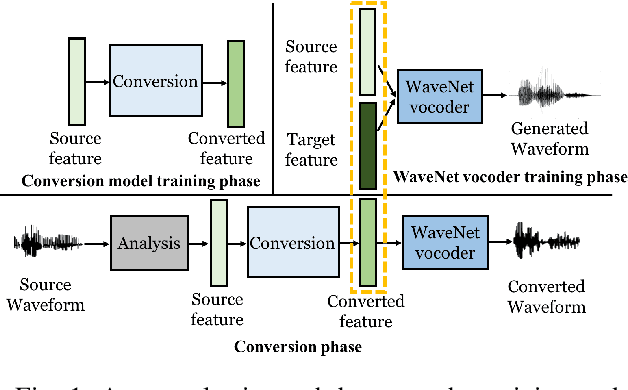
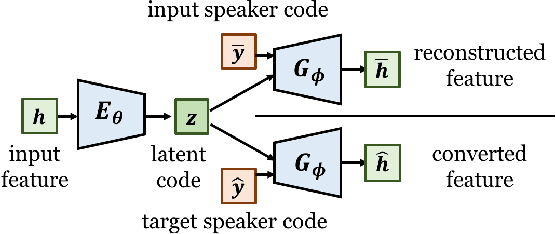
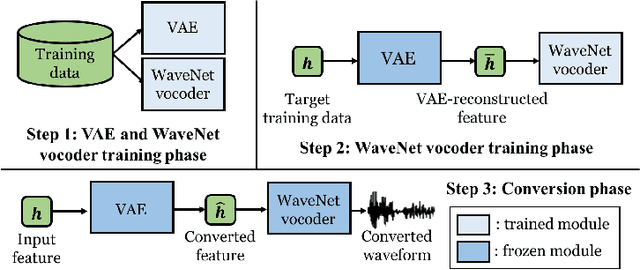
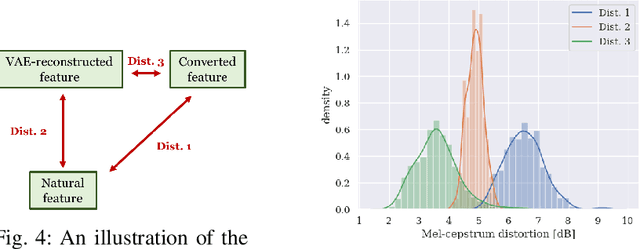
This paper presents a refinement framework of WaveNet vocoders for variational autoencoder (VAE) based voice conversion (VC), which reduces the quality distortion caused by the mismatch between the training data and testing data. Conventional WaveNet vocoders are trained with natural acoustic features but condition on the converted features in the conversion stage for VC, and such mismatch often causes significant quality and similarity degradation. In this work, we take advantage of the particular structure of VAEs to refine WaveNet vocoders with the self-reconstructed features generated by VAE, which are of similar characteristics with the converted features while having the same data length with the target training data. In other words, our proposed method does not require any alignment. Objective and subjective experimental results demonstrate the effectiveness of our proposed framework.
Cycle-consistency training for end-to-end speech recognition
Nov 02, 2018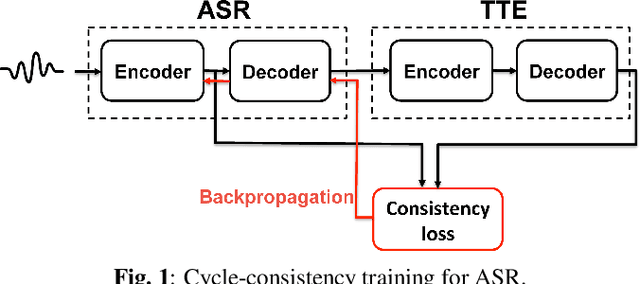
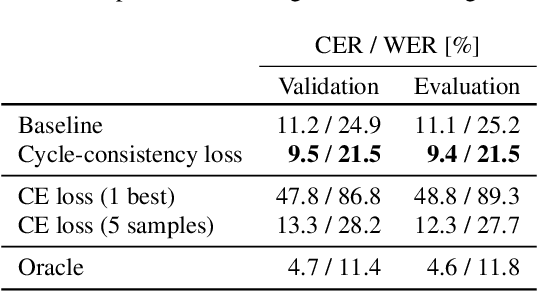
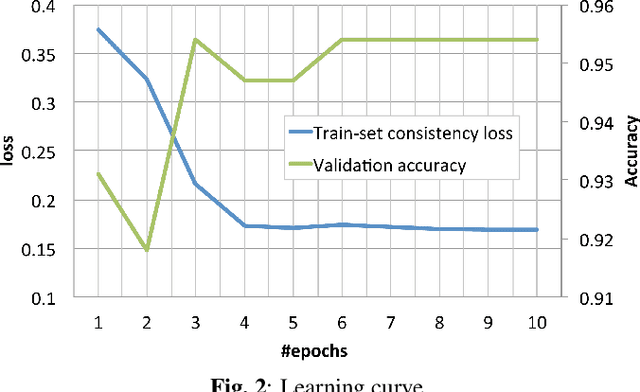

This paper presents a method to train end-to-end automatic speech recognition (ASR) models using unpaired data. Although the end-to-end approach can eliminate the need for expert knowledge such as pronunciation dictionaries to build ASR systems, it still requires a large amount of paired data, i.e., speech utterances and their transcriptions. Cycle-consistency losses have been recently proposed as a way to mitigate the problem of limited paired data. These approaches compose a reverse operation with a given transformation, e.g., text-to-speech (TTS) with ASR, to build a loss that only requires unsupervised data, speech in this example. Applying cycle consistency to ASR models is not trivial since fundamental information, such as speaker traits, are lost in the intermediate text bottleneck. To solve this problem, this work presents a loss that is based on the speech encoder state sequence instead of the raw speech signal. This is achieved by training a Text-To-Encoder model and defining a loss based on the encoder reconstruction error. Experimental results on the LibriSpeech corpus show that the proposed cycle-consistency training reduced the word error rate by 14.7% from an initial model trained with 100-hour paired data, using an additional 360 hours of audio data without transcriptions. We also investigate the use of text-only data mainly for language modeling to further improve the performance in the unpaired data training scenario.
Back-Translation-Style Data Augmentation for End-to-End ASR
Jul 28, 2018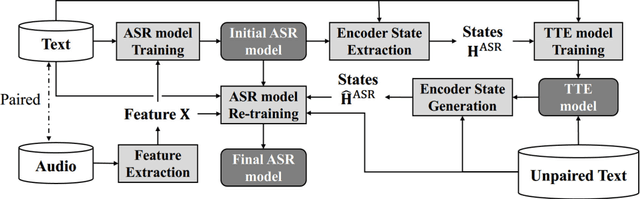
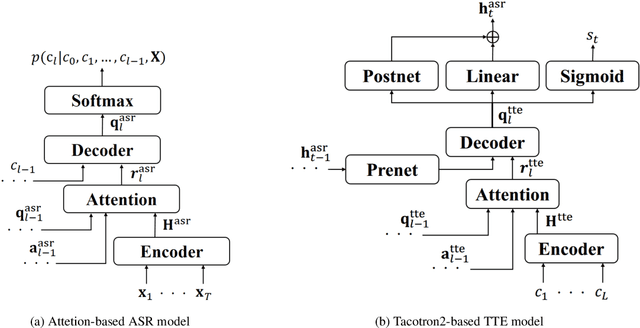
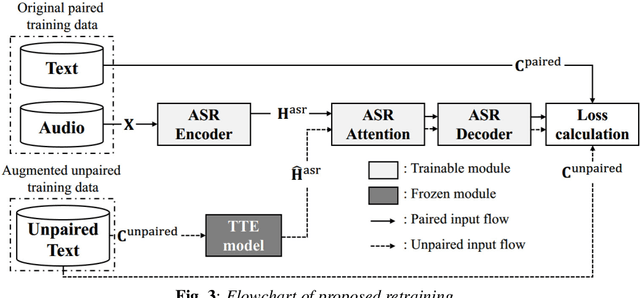
In this paper we propose a novel data augmentation method for attention-based end-to-end automatic speech recognition (E2E-ASR), utilizing a large amount of text which is not paired with speech signals. Inspired by the back-translation technique proposed in the field of machine translation, we build a neural text-to-encoder model which predicts a sequence of hidden states extracted by a pre-trained E2E-ASR encoder from a sequence of characters. By using hidden states as a target instead of acoustic features, it is possible to achieve faster attention learning and reduce computational cost, thanks to sub-sampling in E2E-ASR encoder, also the use of the hidden states can avoid to model speaker dependencies unlike acoustic features. After training, the text-to-encoder model generates the hidden states from a large amount of unpaired text, then E2E-ASR decoder is retrained using the generated hidden states as additional training data. Experimental evaluation using LibriSpeech dataset demonstrates that our proposed method achieves improvement of ASR performance and reduces the number of unknown words without the need for paired data.