 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPnet2-TTS: Extending the Edge of TTS Research
Oct 15, 2021

This paper describes ESPnet2-TTS, an end-to-end text-to-speech (E2E-TTS) toolkit. ESPnet2-TTS extends our earlier version, ESPnet-TTS, by adding many new features, including: on-the-fly flexible pre-processing, joint training with neural vocoders, and state-of-the-art TTS models with extensions like full-band E2E text-to-waveform modeling, which simplify the training pipeline and further enhance TTS performance. The unified design of our recipes enables users to quickly reproduce state-of-the-art E2E-TTS results. We also provide many pre-trained models in a unified Python interface for inference, offering a quick means for users to generate baseline samples and build demos. Experimental evaluations with English and Japanese corpora demonstrate that our provided models synthesize utterances comparable to ground-truth ones, achieving state-of-the-art TTS performance. The toolkit is available online at https://github.com/espnet/espnet.
S3PRL-VC: Open-source Voice Conversion Framework with Self-supervised Speech Representations
Oct 12, 2021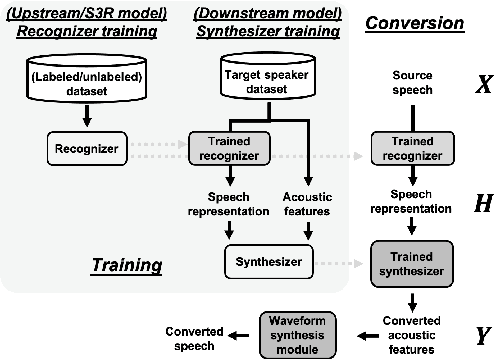
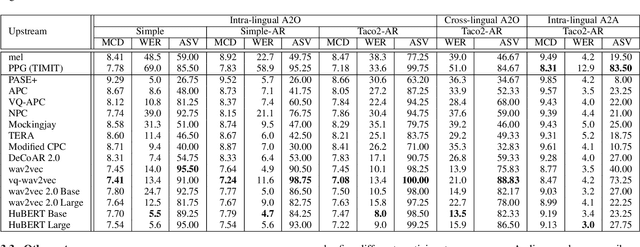
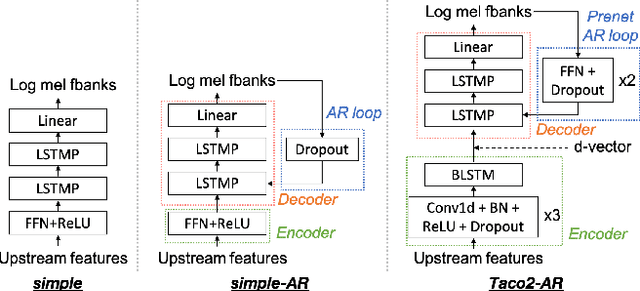
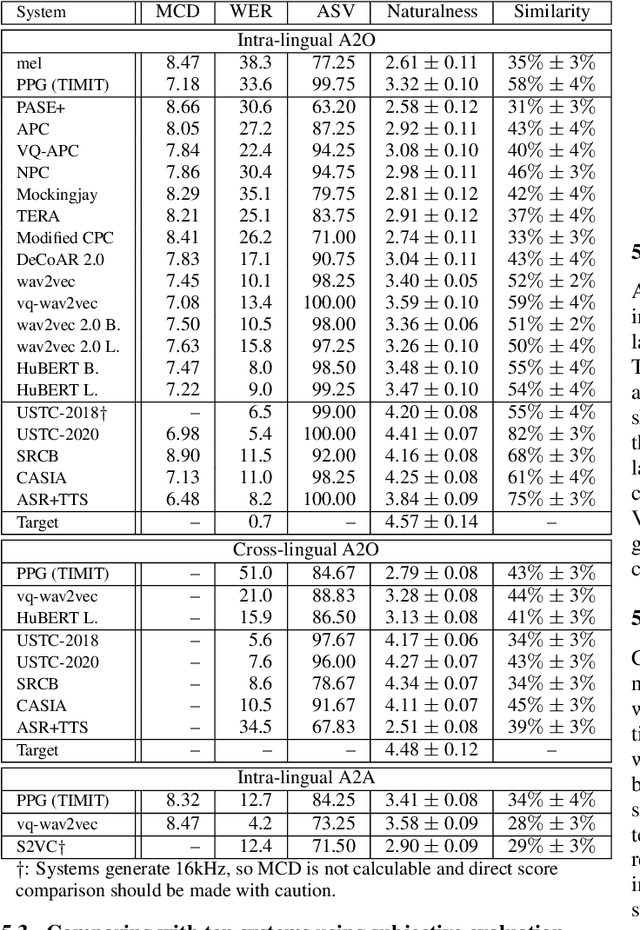
This paper introduces S3PRL-VC, an open-source voice conversion (VC) framework based on the S3PRL toolkit. In the context of recognition-synthesis VC, self-supervised speech representation (S3R) is valuable in its potential to replace the expensive supervised representation adopted by state-of-the-art VC systems. Moreover, we claim that VC is a good probing task for S3R analysis. In this work, we provide a series of in-depth analyses by benchmarking on the two tasks in VCC2020, namely intra-/cross-lingual any-to-one (A2O) VC, as well as an any-to-any (A2A) setting. We also provide comparisons between not only different S3Rs but also top systems in VCC2020 with supervised representations. Systematic objective and subjective evaluation were conducted, and we show that S3R is comparable with VCC2020 top systems in the A2O setting in terms of similarity, and achieves state-of-the-art in S3R-based A2A VC. We believe the extensive analysis, as well as the toolkit itself, contribute to not only the S3R community but also the VC community. The codebase is now open-sourced.
On Prosody Modeling for ASR+TTS based Voice Conversion
Jul 20, 2021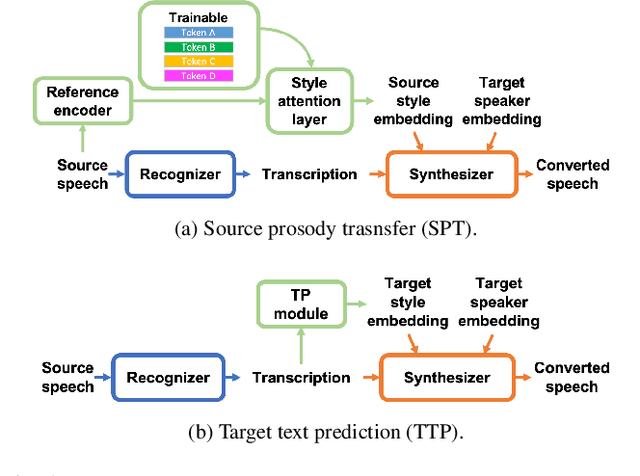

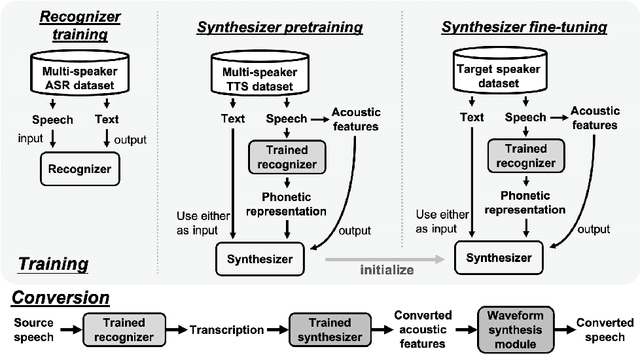

In voice conversion (VC), an approach showing promising results in the latest voice conversion challenge (VCC) 2020 is to first use an automatic speech recognition (ASR) model to transcribe the source speech into the underlying linguistic contents; these are then used as input by a text-to-speech (TTS) system to generate the converted speech. Such a paradigm, referred to as ASR+TTS, overlooks the modeling of prosody, which plays an important role in speech naturalness and conversion similarity. Although some researchers have considered transferring prosodic clues from the source speech, there arises a speaker mismatch during training and conversion. To address this issue, in this work, we propose to directly predict prosody from the linguistic representation in a target-speaker-dependent manner, referred to as target text prediction (TTP). We evaluate both methods on the VCC2020 benchmark and consider different linguistic representations. The results demonstrate the effectiveness of TTP in both objective and subjective evaluations.
Anomalous Sound Detection Using a Binary Classification Model and Class Centroids
Jun 11, 2021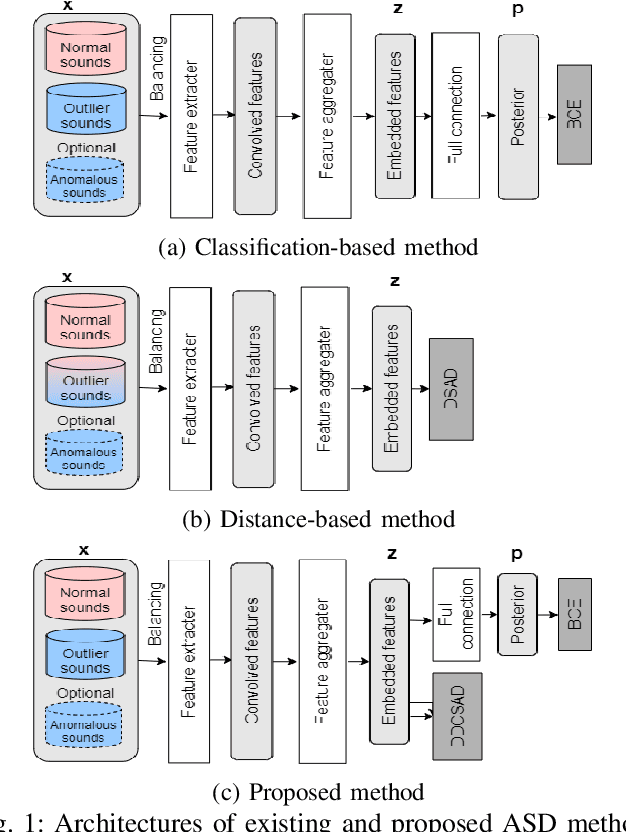

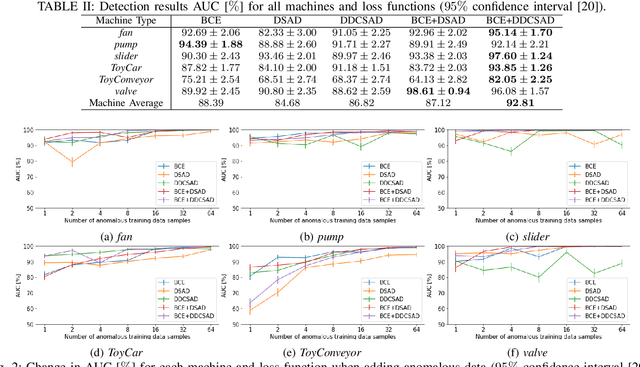
An anomalous sound detection system to detect unknown anomalous sounds usually needs to be built using only normal sound data. Moreover, it is desirable to improve the system by effectively using a small amount of anomalous sound data, which will be accumulated through the system's operation. As one of the methods to meet these requirements, we focus on a binary classification model that is developed by using not only normal data but also outlier data in the other domains as pseudo-anomalous sound data, which can be easily updated by using anomalous data. In this paper, we implement a new loss function based on metric learning to learn the distance relationship from each class centroid in feature space for the binary classification model. The proposed multi-task learning of the binary classification and the metric learning makes it possible to build the feature space where the within-class variance is minimized and the between-class variance is maximized while keeping normal and anomalous classes linearly separable. We also investigate the effectiveness of additionally using anomalous sound data for further improving the binary classification model. Our results showed that multi-task learning using binary classification and metric learning to consider the distance from each class centroid in the feature space is effective, and performance can be significantly improved by using even a small amount of anomalous data during training.
Non-autoregressive sequence-to-sequence voice conversion
Apr 14, 2021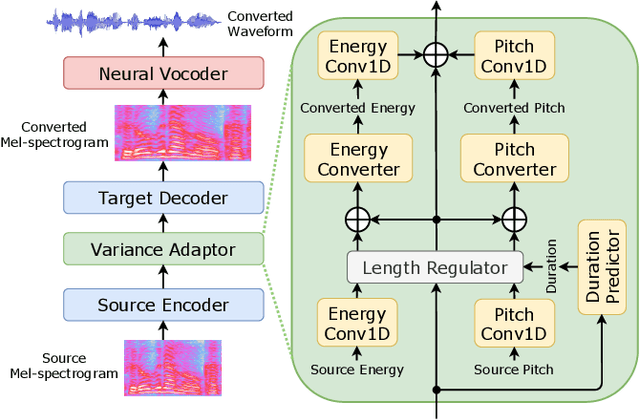
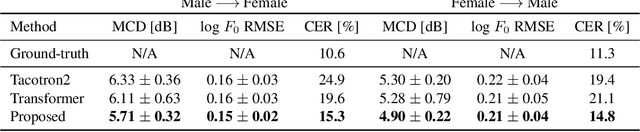
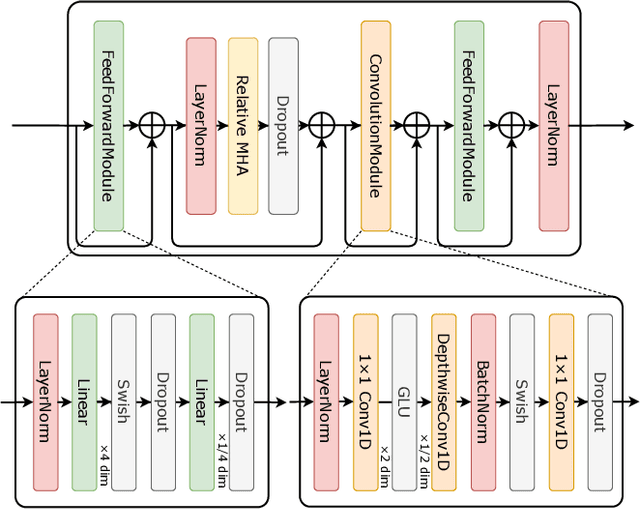

This paper proposes a novel voice conversion (VC) method based on non-autoregressive sequence-to-sequence (NAR-S2S) models. Inspired by the great success of NAR-S2S models such as FastSpeech in text-to-speech (TTS), we extend the FastSpeech2 model for the VC problem. We introduce the convolution-augmented Transformer (Conformer) instead of the Transformer, making it possible to capture both local and global context information from the input sequence. Furthermore, we extend variance predictors to variance converters to explicitly convert the source speaker's prosody components such as pitch and energy into the target speaker. The experimental evaluation with the Japanese speaker dataset, which consists of male and female speakers of 1,000 utterances, demonstrates that the proposed model enables us to perform more stable, faster, and better conversion than autoregressive S2S (AR-S2S) models such as Tacotron2 and Transformer.
crank: An Open-Source Software for Nonparallel Voice Conversion Based on Vector-Quantized Variational Autoencoder
Mar 04, 2021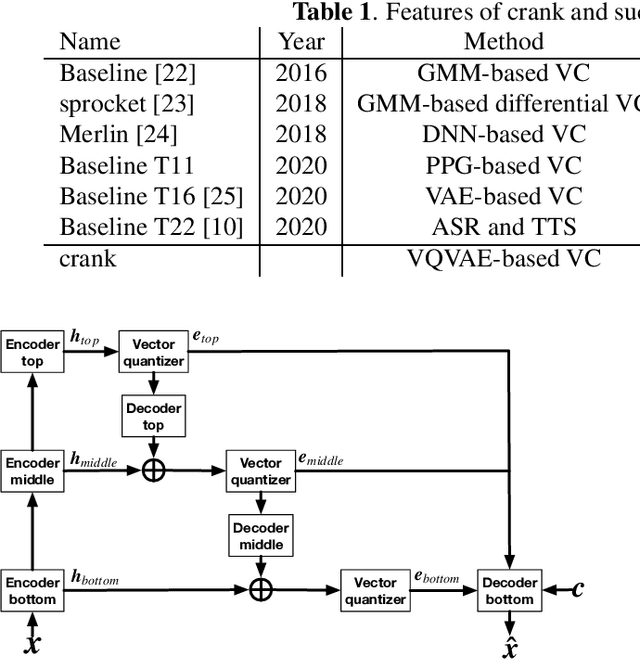
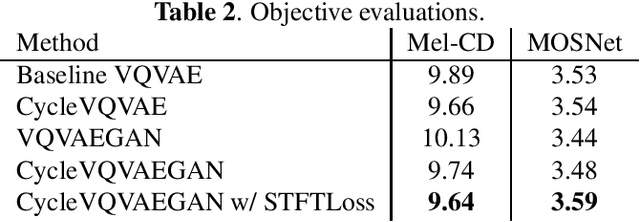
In this paper, we present an open-source software for developing a nonparallel voice conversion (VC) system named crank. Although we have released an open-source VC software based on the Gaussian mixture model named sprocket in the last VC Challenge, it is not straightforward to apply any speech corpus because it is necessary to prepare parallel utterances of source and target speakers to model a statistical conversion function. To address this issue, in this study, we developed a new open-source VC software that enables users to model the conversion function by using only a nonparallel speech corpus. For implementing the VC software, we used a vector-quantized variational autoencoder (VQVAE). To rapidly examine the effectiveness of recent technologies developed in this research field, crank also supports several representative works for autoencoder-based VC methods such as the use of hierarchical architectures, cyclic architectures, generative adversarial networks, speaker adversarial training, and neural vocoders. Moreover, it is possible to automatically estimate objective measures such as mel-cepstrum distortion and pseudo mean opinion score based on MOSNet. In this paper, we describe representative functions developed in crank and make brief comparisons by objective evaluations.
The 2020 ESPnet update: new features, broadened applications, performance improvements, and future plans
Dec 23, 2020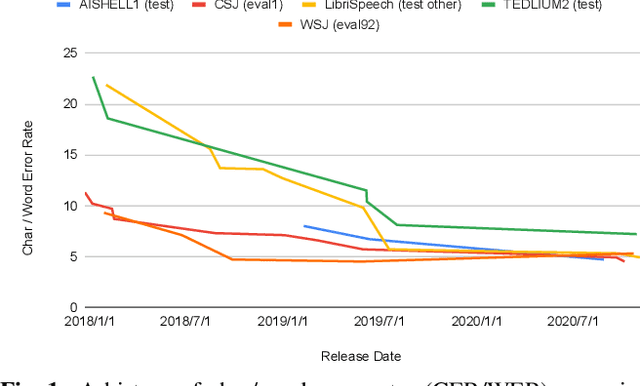

This paper describes the recent development of ESPnet (https://github.com/espnet/espnet), an end-to-end speech processing toolkit. This project was initiated in December 2017 to mainly deal with end-to-end speech recognition experiments based on sequence-to-sequence modeling. The project has grown rapidly and now covers a wide range of speech processing applications. Now ESPnet also includes text to speech (TTS), voice conversation (VC), speech translation (ST), and speech enhancement (SE) with support for beamforming, speech separation, denoising, and dereverberation. All applications are trained in an end-to-end manner, thanks to the generic sequence to sequence modeling properties, and they can be further integrated and jointly optimized. Also, ESPnet provides reproducible all-in-one recipes for these applications with state-of-the-art performance in various benchmarks by incorporating transformer, advanced data augmentation, and conformer. This project aims to provide up-to-date speech processing experience to the community so that researchers in academia and various industry scales can develop their technologies collaboratively.
Any-to-One Sequence-to-Sequence Voice Conversion using Self-Supervised Discrete Speech Representations
Oct 23, 2020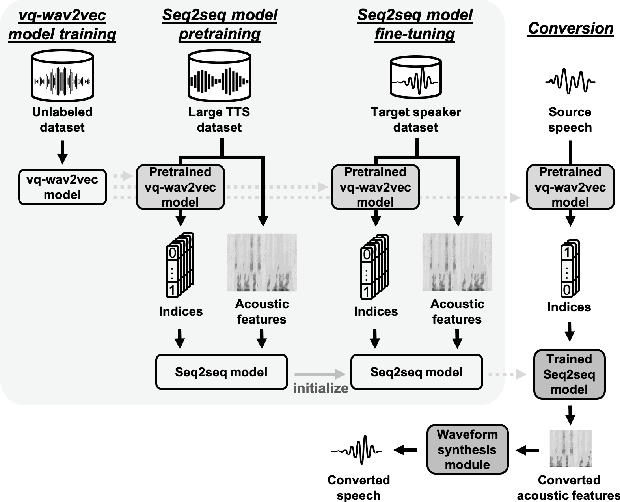
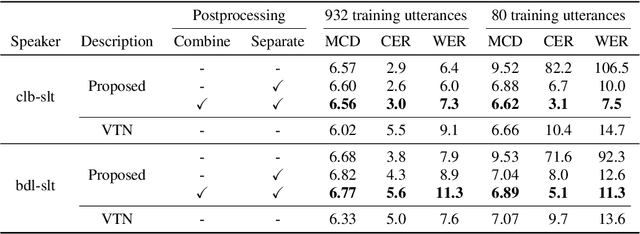
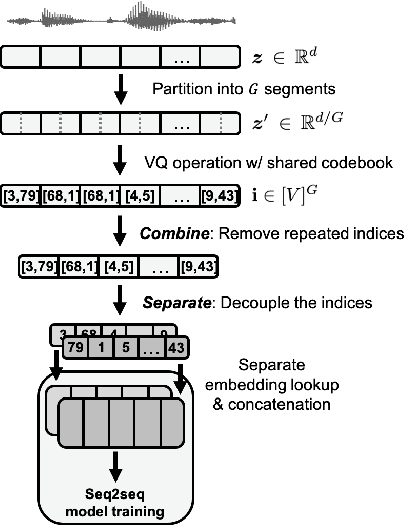
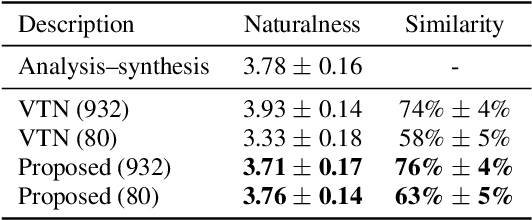
We present a novel approach to any-to-one (A2O) voice conversion (VC) in a sequence-to-sequence (seq2seq) framework. A2O VC aims to convert any speaker, including those unseen during training, to a fixed target speaker. We utilize vq-wav2vec (VQW2V), a discretized self-supervised speech representation that was learned from massive unlabeled data, which is assumed to be speaker-independent and well corresponds to underlying linguistic contents. Given a training dataset of the target speaker, we extract VQW2V and acoustic features to estimate a seq2seq mapping function from the former to the latter. With the help of a pretraining method and a newly designed postprocessing technique, our model can be generalized to only 5 min of data, even outperforming the same model trained with parallel data.
The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS
Oct 06, 2020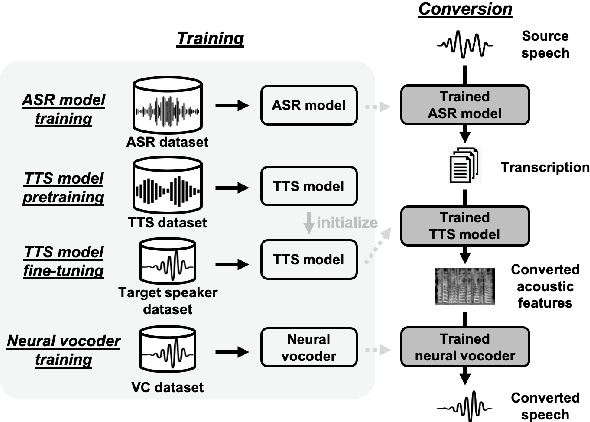
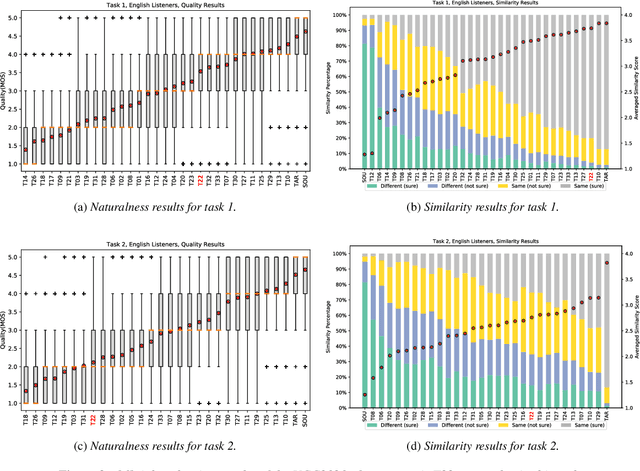
This paper presents the sequence-to-sequence (seq2seq) baseline system for the voice conversion challenge (VCC) 2020. We consider a naive approach for voice conversion (VC), which is to first transcribe the input speech with an automatic speech recognition (ASR) model, followed using the transcriptions to generate the voice of the target with a text-to-speech (TTS) model. We revisit this method under a sequence-to-sequence (seq2seq) framework by utilizing ESPnet, an open-source end-to-end speech processing toolkit, and the many well-configured pretrained models provided by the community. Official evaluation results show that our system comes out top among the participating systems in terms of conversion similarity, demonstrating the promising ability of seq2seq models to convert speaker identity. The implementation is made open-source at: https://github.com/espnet/espnet/tree/master/egs/vcc20.
Pretraining Techniques for Sequence-to-Sequence Voice Conversion
Aug 07, 2020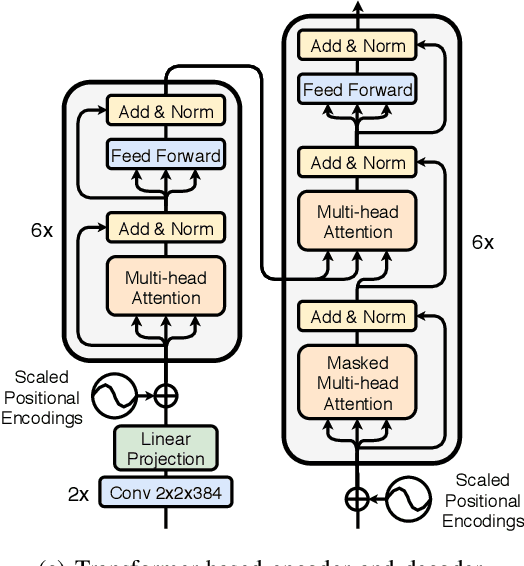
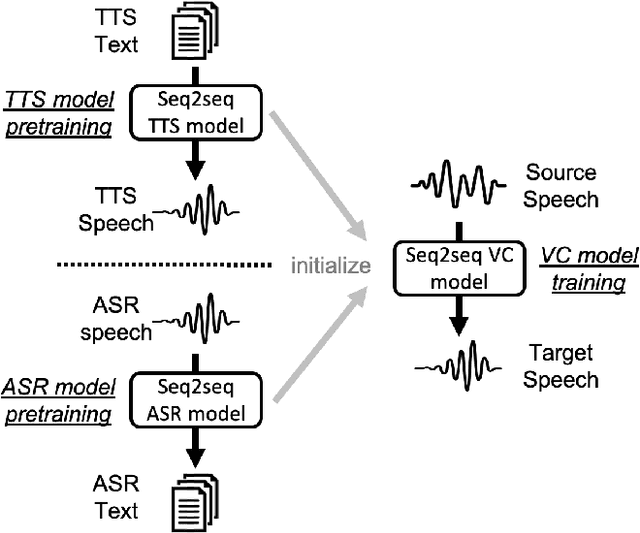
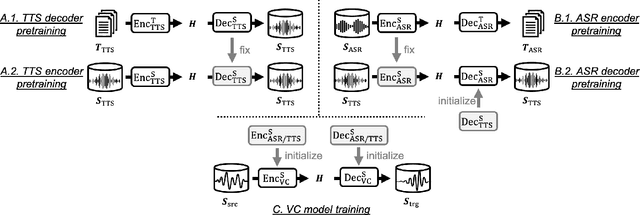
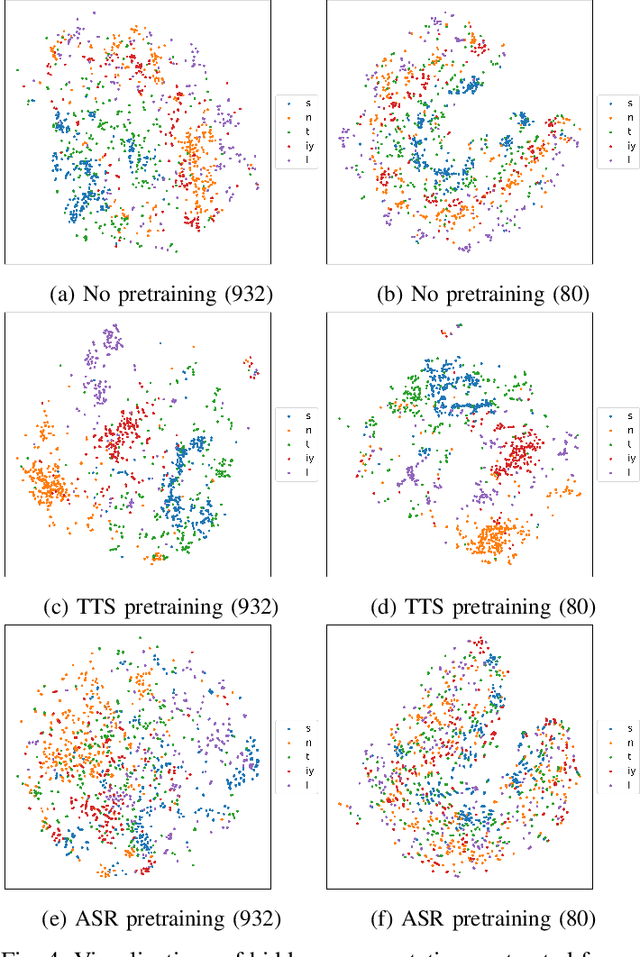
Sequence-to-sequence (seq2seq) voice conversion (VC) models are attractive owing to their ability to convert prosody. Nonetheless, without sufficient data, seq2seq VC models can suffer from unstable training and mispronunciation problems in the converted speech, thus far from practical. To tackle these shortcomings, we propose to transfer knowledge from other speech processing tasks where large-scale corpora are easily available, typically text-to-speech (TTS) and automatic speech recognition (ASR). We argue that VC models initialized with such pretrained ASR or TTS model parameters can generate effective hidden representations for high-fidelity, highly intelligible converted speech. We apply such techniques to recurrent neural network (RNN)-based and Transformer based models, and through systematical experiments, we demonstrate the effectiveness of the pretraining scheme and the superiority of Transformer based models over RNN-based models in terms of intelligibility, naturalness, and similarity.