 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFun with Flags: Robust Principal Directions via Flag Manifolds
Jan 08, 2024Principal component analysis (PCA), along with its extensions to manifolds and outlier contaminated data, have been indispensable in computer vision and machine learning. In this work, we present a unifying formalism for PCA and its variants, and introduce a framework based on the flags of linear subspaces, \ie a hierarchy of nested linear subspaces of increasing dimension, which not only allows for a common implementation but also yields novel variants, not explored previously. We begin by generalizing traditional PCA methods that either maximize variance or minimize reconstruction error. We expand these interpretations to develop a wide array of new dimensionality reduction algorithms by accounting for outliers and the data manifold. To devise a common computational approach, we recast robust and dual forms of PCA as optimization problems on flag manifolds. We then integrate tangent space approximations of principal geodesic analysis (tangent-PCA) into this flag-based framework, creating novel robust and dual geodesic PCA variations. The remarkable flexibility offered by the 'flagification' introduced here enables even more algorithmic variants identified by specific flag types. Last but not least, we propose an effective convergent solver for these flag-formulations employing the Stiefel manifold. Our empirical results on both real-world and synthetic scenarios, demonstrate the superiority of our novel algorithms, especially in terms of robustness to outliers on manifolds.
Combinatorial Complexes: Bridging the Gap Between Cell Complexes and Hypergraphs
Dec 15, 2023

Graph-based signal processing techniques have become essential for handling data in non-Euclidean spaces. However, there is a growing awareness that these graph models might need to be expanded into `higher-order' domains to effectively represent the complex relations found in high-dimensional data. Such higher-order domains are typically modeled either as hypergraphs, or as simplicial, cubical or other cell complexes. In this context, cell complexes are often seen as a subclass of hypergraphs with additional algebraic structure that can be exploited, e.g., to develop a spectral theory. In this article, we promote an alternative perspective. We argue that hypergraphs and cell complexes emphasize \emph{different} types of relations, which may have different utility depending on the application context. Whereas hypergraphs are effective in modeling set-type, multi-body relations between entities, cell complexes provide an effective means to model hierarchical, interior-to-boundary type relations. We discuss the relative advantages of these two choices and elaborate on the previously introduced concept of a combinatorial complex that enables co-existing set-type and hierarchical relations. Finally, we provide a brief numerical experiment to demonstrate that this modelling flexibility can be advantageous in learning tasks.
SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark
Oct 31, 2023



In this paper, we present SignAvatars, the first large-scale multi-prompt 3D sign language (SL) motion dataset designed to bridge the communication gap for hearing-impaired individuals. While there has been an exponentially growing number of research regarding digital communication, the majority of existing communication technologies primarily cater to spoken or written languages, instead of SL, the essential communication method for hearing-impaired communities. Existing SL datasets, dictionaries, and sign language production (SLP) methods are typically limited to 2D as the annotating 3D models and avatars for SL is usually an entirely manual and labor-intensive process conducted by SL experts, often resulting in unnatural avatars. In response to these challenges, we compile and curate the SignAvatars dataset, which comprises 70,000 videos from 153 signers, totaling 8.34 million frames, covering both isolated signs and continuous, co-articulated signs, with multiple prompts including HamNoSys, spoken language, and words. To yield 3D holistic annotations, including meshes and biomechanically-valid poses of body, hands, and face, as well as 2D and 3D keypoints, we introduce an automated annotation pipeline operating on our large corpus of SL videos. SignAvatars facilitates various tasks such as 3D sign language recognition (SLR) and the novel 3D SL production (SLP) from diverse inputs like text scripts, individual words, and HamNoSys notation. Hence, to evaluate the potential of SignAvatars, we further propose a unified benchmark of 3D SL holistic motion production. We believe that this work is a significant step forward towards bringing the digital world to the hearing-impaired communities. Our project page is at https://signavatars.github.io/
Projected Stochastic Gradient Descent with Quantum Annealed Binary Gradients
Oct 23, 2023



We present, QP-SBGD, a novel layer-wise stochastic optimiser tailored towards training neural networks with binary weights, known as binary neural networks (BNNs), on quantum hardware. BNNs reduce the computational requirements and energy consumption of deep learning models with minimal loss in accuracy. However, training them in practice remains to be an open challenge. Most known BNN-optimisers either rely on projected updates or binarise weights post-training. Instead, QP-SBGD approximately maps the gradient onto binary variables, by solving a quadratic constrained binary optimisation. Under practically reasonable assumptions, we show that this update rule converges with a rate of $\mathcal{O}(1 / \sqrt{T})$. Moreover, we show how the $\mathcal{NP}$-hard projection can be effectively executed on an adiabatic quantum annealer, harnessing recent advancements in quantum computation. We also introduce a projected version of this update rule and prove that if a fixed point exists in the binary variable space, the modified updates will converge to it. Last but not least, our algorithm is implemented layer-wise, making it suitable to train larger networks on resource-limited quantum hardware. Through extensive evaluations, we show that QP-SBGD outperforms or is on par with competitive and well-established baselines such as BinaryConnect, signSGD and ProxQuant when optimising the Rosenbrock function, training BNNs as well as binary graph neural networks.
Variational Inference for SDEs Driven by Fractional Noise
Oct 19, 2023



We present a novel variational framework for performing inference in (neural) stochastic differential equations (SDEs) driven by Markov-approximate fractional Brownian motion (fBM). SDEs offer a versatile tool for modeling real-world continuous-time dynamic systems with inherent noise and randomness. Combining SDEs with the powerful inference capabilities of variational methods, enables the learning of representative function distributions through stochastic gradient descent. However, conventional SDEs typically assume the underlying noise to follow a Brownian motion (BM), which hinders their ability to capture long-term dependencies. In contrast, fractional Brownian motion (fBM) extends BM to encompass non-Markovian dynamics, but existing methods for inferring fBM parameters are either computationally demanding or statistically inefficient. In this paper, building upon the Markov approximation of fBM, we derive the evidence lower bound essential for efficient variational inference of posterior path measures, drawing from the well-established field of stochastic analysis. Additionally, we provide a closed-form expression to determine optimal approximation coefficients. Furthermore, we propose the use of neural networks to learn the drift, diffusion and control terms within our variational posterior, leading to the variational training of neural-SDEs. In this framework, we also optimize the Hurst index, governing the nature of our fractional noise. Beyond validation on synthetic data, we contribute a novel architecture for variational latent video prediction,-an approach that, to the best of our knowledge, enables the first variational neural-SDE application to video perception.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023

This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
VidStyleODE: Disentangled Video Editing via StyleGAN and NeuralODEs
Apr 12, 2023



We propose $\textbf{VidStyleODE}$, a spatiotemporally continuous disentangled $\textbf{Vid}$eo representation based upon $\textbf{Style}$GAN and Neural-$\textbf{ODE}$s. Effective traversal of the latent space learned by Generative Adversarial Networks (GANs) has been the basis for recent breakthroughs in image editing. However, the applicability of such advancements to the video domain has been hindered by the difficulty of representing and controlling videos in the latent space of GANs. In particular, videos are composed of content (i.e., appearance) and complex motion components that require a special mechanism to disentangle and control. To achieve this, VidStyleODE encodes the video content in a pre-trained StyleGAN $\mathcal{W}_+$ space and benefits from a latent ODE component to summarize the spatiotemporal dynamics of the input video. Our novel continuous video generation process then combines the two to generate high-quality and temporally consistent videos with varying frame rates. We show that our proposed method enables a variety of applications on real videos: text-guided appearance manipulation, motion manipulation, image animation, and video interpolation and extrapolation. Project website: https://cyberiada.github.io/VidStyleODE
Chordal Averaging on Flag Manifolds and Its Applications
Mar 23, 2023This paper presents a new, provably-convergent algorithm for computing the flag-mean and flag-median of a set of points on a flag manifold under the chordal metric. The flag manifold is a mathematical space consisting of flags, which are sequences of nested subspaces of a vector space that increase in dimension. The flag manifold is a superset of a wide range of known matrix groups, including Stiefel and Grassmanians, making it a general object that is useful in a wide variety computer vision problems. To tackle the challenge of computing first order flag statistics, we first transform the problem into one that involves auxiliary variables constrained to the Stiefel manifold. The Stiefel manifold is a space of orthogonal frames, and leveraging the numerical stability and efficiency of Stiefel-manifold optimization enables us to compute the flag-mean effectively. Through a series of experiments, we show the competence of our method in Grassmann and rotation averaging, as well as principal component analysis.
Disentangling Content and Motion for Text-Based Neural Video Manipulation
Nov 05, 2022Giving machines the ability to imagine possible new objects or scenes from linguistic descriptions and produce their realistic renderings is arguably one of the most challenging problems in computer vision. Recent advances in deep generative models have led to new approaches that give promising results towards this goal. In this paper, we introduce a new method called DiCoMoGAN for manipulating videos with natural language, aiming to perform local and semantic edits on a video clip to alter the appearances of an object of interest. Our GAN architecture allows for better utilization of multiple observations by disentangling content and motion to enable controllable semantic edits. To this end, we introduce two tightly coupled networks: (i) a representation network for constructing a concise understanding of motion dynamics and temporally invariant content, and (ii) a translation network that exploits the extracted latent content representation to actuate the manipulation according to the target description. Our qualitative and quantitative evaluations demonstrate that DiCoMoGAN significantly outperforms existing frame-based methods, producing temporally coherent and semantically more meaningful results.
6D Camera Relocalization in Visually Ambiguous Extreme Environments
Jul 13, 2022
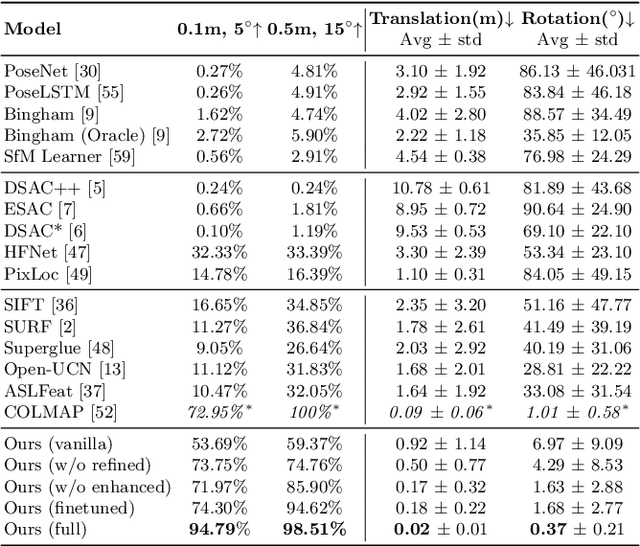
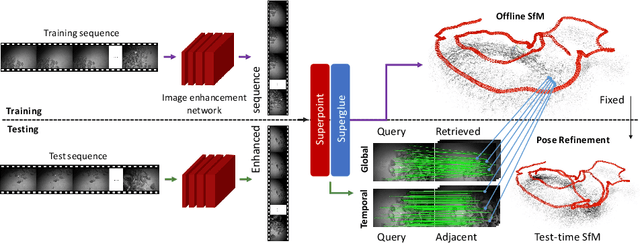
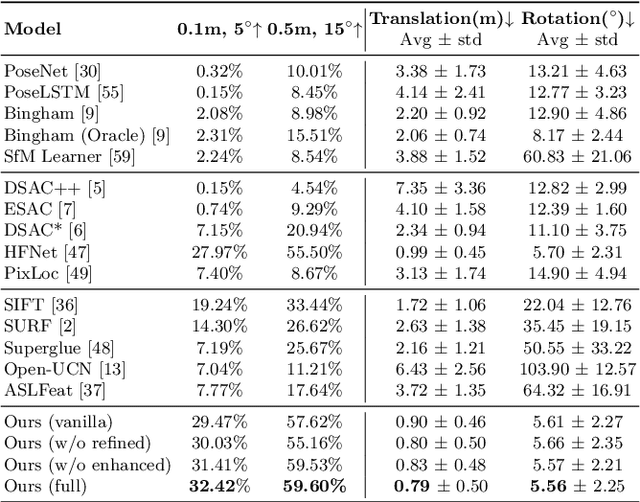
We propose a novel method to reliably estimate the pose of a camera given a sequence of images acquired in extreme environments such as deep seas or extraterrestrial terrains. Data acquired under these challenging conditions are corrupted by textureless surfaces, image degradation, and presence of repetitive and highly ambiguous structures. When naively deployed, the state-of-the-art methods can fail in those scenarios as confirmed by our empirical analysis. In this paper, we attempt to make camera relocalization work in these extreme situations. To this end, we propose: (i) a hierarchical localization system, where we leverage temporal information and (ii) a novel environment-aware image enhancement method to boost the robustness and accuracy. Our extensive experimental results demonstrate superior performance in favor of our method under two extreme settings: localizing an autonomous underwater vehicle and localizing a planetary rover in a Mars-like desert. In addition, our method achieves comparable performance with state-of-the-art methods on the indoor benchmark (7-Scenes dataset) using only 20% training data.