 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Invariant Specifications for Human-Swarm Systems
Dec 12, 2022



We present a method for controlling a swarm using its spectral decomposition -- that is, by describing the set of trajectories of a swarm in terms of a spatial distribution throughout the operational domain -- guaranteeing scale invariance with respect to the number of agents both for computation and for the operator tasked with controlling the swarm. We use ergodic control, decentralized across the network, for implementation. In the DARPA OFFSET program field setting, we test this interface design for the operator using the STOMP interface -- the same interface used by Raytheon BBN throughout the duration of the OFFSET program. In these tests, we demonstrate that our approach is scale-invariant -- the user specification does not depend on the number of agents; it is persistent -- the specification remains active until the user specifies a new command; and it is real-time -- the user can interact with and interrupt the swarm at any time. Moreover, we show that the spectral/ergodic specification of swarm behavior degrades gracefully as the number of agents goes down, enabling the operator to maintain the same approach as agents become disabled or are added to the network. We demonstrate the scale-invariance and dynamic response of our system in a field relevant simulator on a variety of tactical scenarios with up to 50 agents. We also demonstrate the dynamic response of our system in the field with a smaller team of agents. Lastly, we make the code for our system available.
Scale-Invariant Fast Functional Registration
Sep 26, 2022
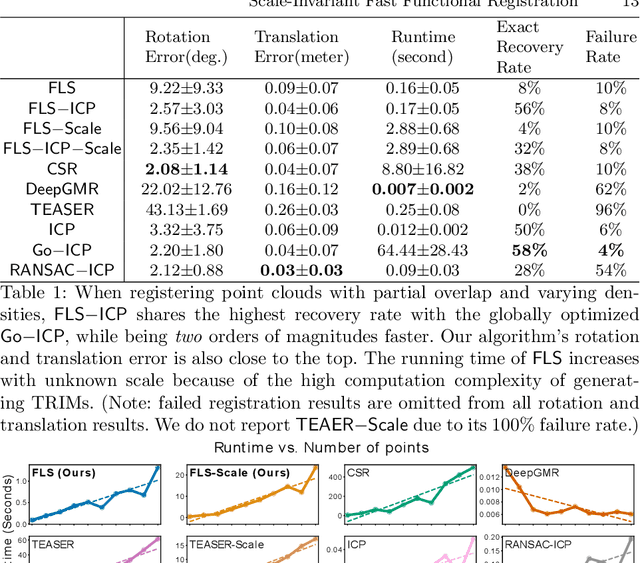
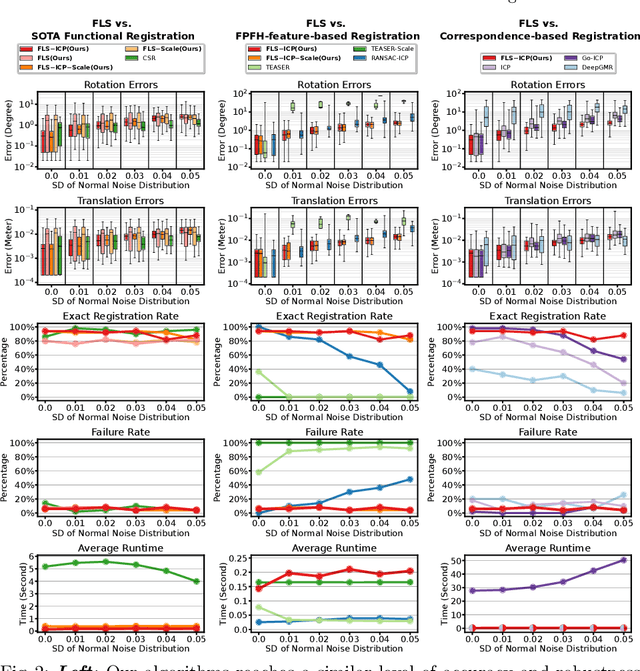
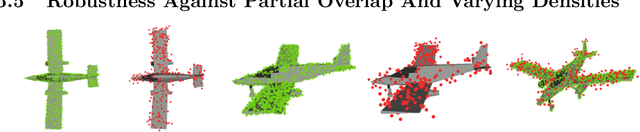
Functional registration algorithms represent point clouds as functions (e.g. spacial occupancy field) avoiding unreliable correspondence estimation in conventional least-squares registration algorithms. However, existing functional registration algorithms are computationally expensive. Furthermore, the capability of registration with unknown scale is necessary in tasks such as CAD model-based object localization, yet no such support exists in functional registration. In this work, we propose a scale-invariant, linear time complexity functional registration algorithm. We achieve linear time complexity through an efficient approximation of L2-distance between functions using orthonormal basis functions. The use of orthonormal basis functions leads to a formulation that is compatible with least-squares registration. Benefited from the least-square formulation, we use the theory of translation-rotation-invariant measurement to decouple scale estimation and therefore achieve scale-invariant registration. We evaluate the proposed algorithm, named FLS (functional least-squares), on standard 3D registration benchmarks, showing FLS is an order of magnitude faster than state-of-the-art functional registration algorithm without compromising accuracy and robustness. FLS also outperforms state-of-the-art correspondence-based least-squares registration algorithm on accuracy and robustness, with known and unknown scale. Finally, we demonstrate applying FLS to register point clouds with varying densities and partial overlaps, point clouds from different objects within the same category, and point clouds from real world objects with noisy RGB-D measurements.
* 17 pages
Majorization Minimization Methods for Distributed Pose Graph Optimization
Aug 03, 2021
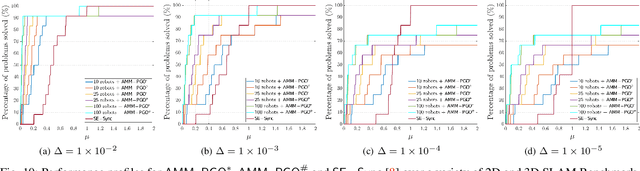
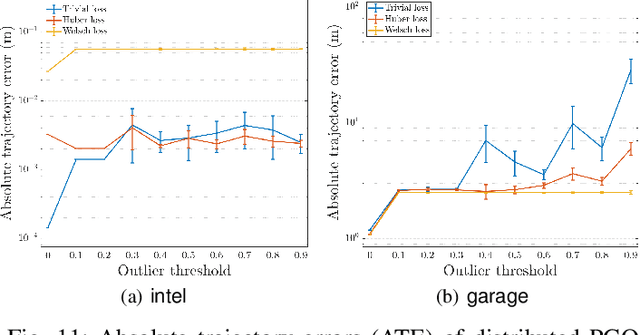

We consider the problem of distributed pose graph optimization (PGO) that has important applications in multi-robot simultaneous localization and mapping (SLAM). We propose the majorization minimization (MM) method for distributed PGO ($\mathsf{MM\!\!-\!\!PGO}$) that applies to a broad class of robust loss kernels. The $\mathsf{MM\!\!-\!\!PGO}$ method is guaranteed to converge to first-order critical points under mild conditions. Furthermore, noting that the $\mathsf{MM\!\!-\!\!PGO}$ method is reminiscent of proximal methods, we leverage Nesterov's method and adopt adaptive restarts to accelerate convergence. The resulting accelerated MM methods for distributed PGO -- both with a master node in the network ($\mathsf{AMM\!\!-\!\!PGO}^*$) and without ($\mathsf{AMM\!\!-\!\!PGO}^{\#}$) -- have faster convergence in contrast to the $\mathsf{MM\!\!-\!\!PGO}$ method without sacrificing theoretical guarantees. In particular, the $\mathsf{AMM\!\!-\!\!PGO}^{\#}$ method, which needs no master node and is fully decentralized, features a novel adaptive restart scheme and has a rate of convergence comparable to that of the $\mathsf{AMM\!\!-\!\!PGO}^*$ method using a master node to aggregate information from all the other nodes. The efficacy of this work is validated through extensive applications to 2D and 3D SLAM benchmark datasets and comprehensive comparisons against existing state-of-the-art methods, indicating that our MM methods converge faster and result in better solutions to distributed PGO.
Move Beyond Trajectories: Distribution Space Coupling for Crowd Navigation
Jun 25, 2021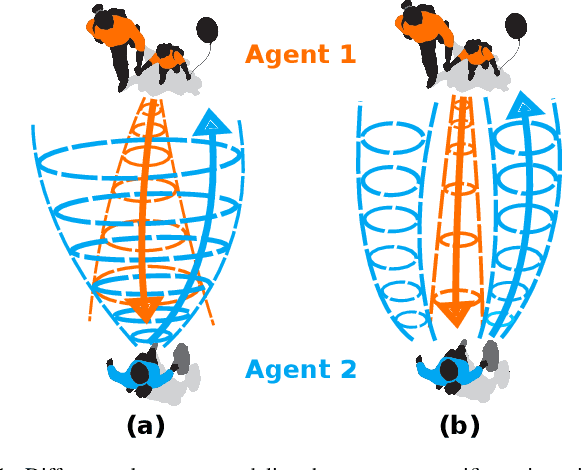
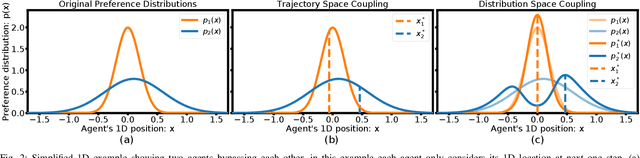
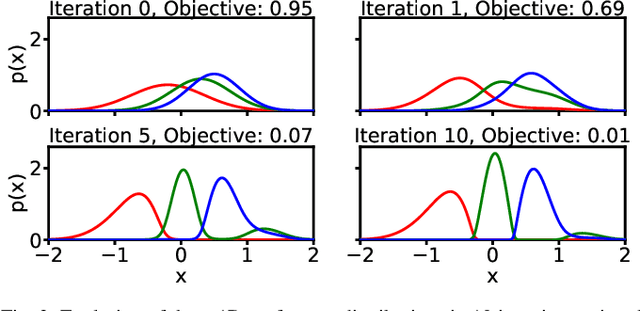
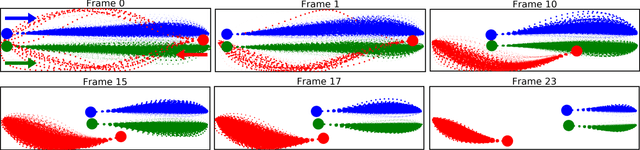
Cooperatively avoiding collision is a critical functionality for robots navigating in dense human crowds, failure of which could lead to either overaggressive or overcautious behavior. A necessary condition for cooperative collision avoidance is to couple the prediction of the agents' trajectories with the planning of the robot's trajectory. However, it is unclear that trajectory based cooperative collision avoidance captures the correct agent attributes. In this work we migrate from trajectory based coupling to a formalism that couples agent preference distributions. In particular, we show that preference distributions (probability density functions representing agents' intentions) can capture higher order statistics of agent behaviors, such as willingness to cooperate. Thus, coupling in distribution space exploits more information about inter-agent cooperation than coupling in trajectory space. We thus introduce a general objective for coupled prediction and planning in distribution space, and propose an iterative best response optimization method based on variational analysis with guaranteed sufficient decrease. Based on this analysis, we develop a sampling-based motion planning framework called DistNav that runs in real time on a laptop CPU. We evaluate our approach on challenging scenarios from both real world datasets and simulation environments, and benchmark against a wide variety of model based and machine learning based approaches. The safety and efficiency statistics of our approach outperform all other models. Finally, we find that DistNav is competitive with human safety and efficiency performance.
* 12 pages
Revitalizing Optimization for 3D Human Pose and Shape Estimation: A Sparse Constrained Formulation
May 28, 2021
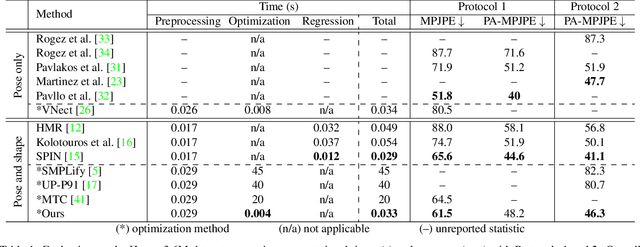

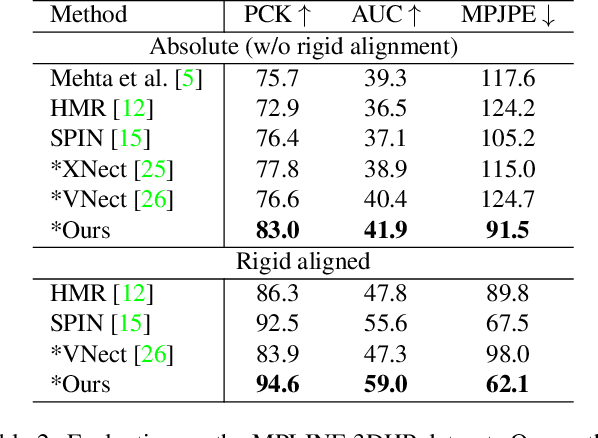
We propose a novel sparse constrained formulation and from it derive a real-time optimization method for 3D human pose and shape estimation. Our optimization method is orders of magnitude faster (avg. 4 ms convergence) than existing optimization methods, while being mathematically equivalent to their dense unconstrained formulation. We achieve this by exploiting the underlying sparsity and constraints of our formulation to efficiently compute the Gauss-Newton direction. We show that this computation scales linearly with the number of joints of a complex 3D human model, in contrast to prior work where it scales cubically due to their dense unconstrained formulation. Based on our optimization method, we present a real-time motion capture framework that estimates 3D human poses and shapes from a single image at over 30 FPS. In benchmarks against state-of-the-art methods on multiple public datasets, our frame-work outperforms other optimization methods and achieves competitive accuracy against regression methods.
Ergodic imitation: Learning from what to do and what not to do
Mar 31, 2021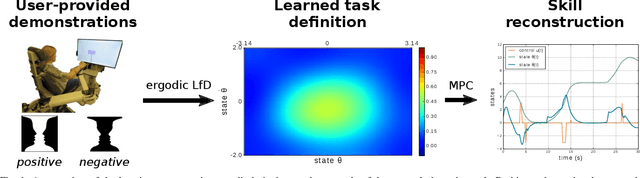
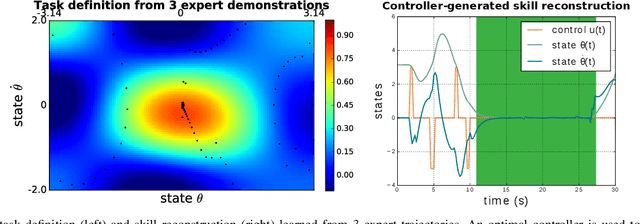
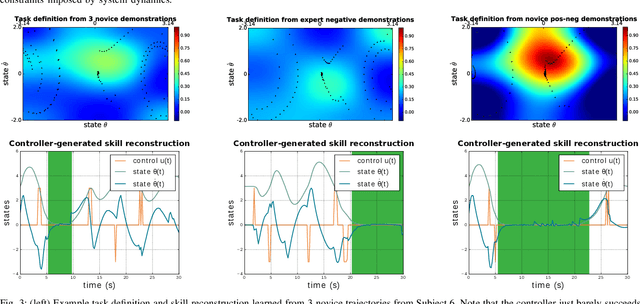
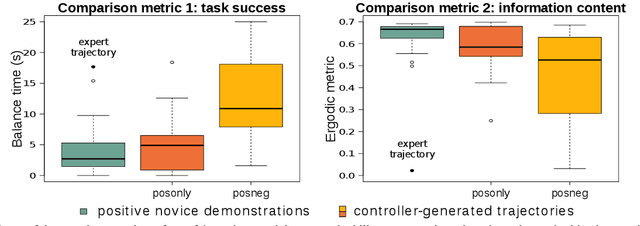
With growing access to versatile robotics, it is beneficial for end users to be able to teach robots tasks without needing to code a control policy. One possibility is to teach the robot through successful task executions. However, near-optimal demonstrations of a task can be difficult to provide and even successful demonstrations can fail to capture task aspects key to robust skill replication. Here, we propose a learning from demonstration (LfD) approach that enables learning of robust task definitions without the need for near-optimal demonstrations. We present a novel algorithmic framework for learning tasks based on the ergodic metric -- a measure of information content in motion. Moreover, we make use of negative demonstrations -- demonstrations of what not to do -- and show that they can help compensate for imperfect demonstrations, reduce the number of demonstrations needed, and highlight crucial task elements improving robot performance. In a proof-of-concept example of cart-pole inversion, we show that negative demonstrations alone can be sufficient to successfully learn and recreate a skill. Through a human subject study with 24 participants, we show that consistently more information about a task can be captured from combined positive and negative (posneg) demonstrations than from the same amount of just positive demonstrations. Finally, we demonstrate our learning approach on simulated tasks of target reaching and table cleaning with a 7-DoF Franka arm. Our results point towards a future with robust, data-efficient LfD for novice users.
* Kalinowska and Prabhakar contributed equally to this work
Generalized Proximal Methods for Pose Graph Optimization
Dec 04, 2020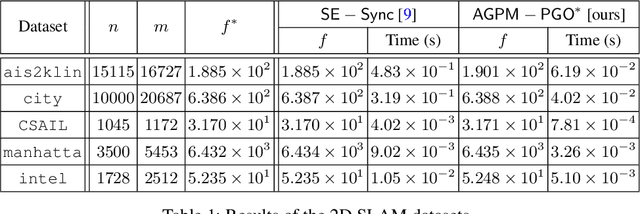
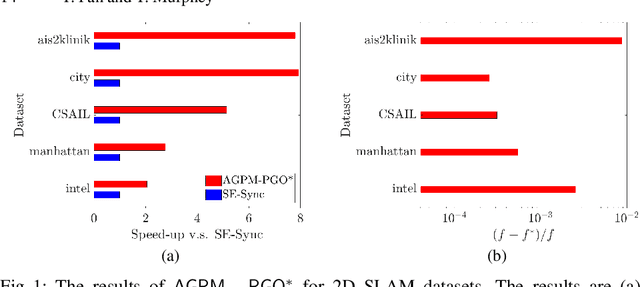
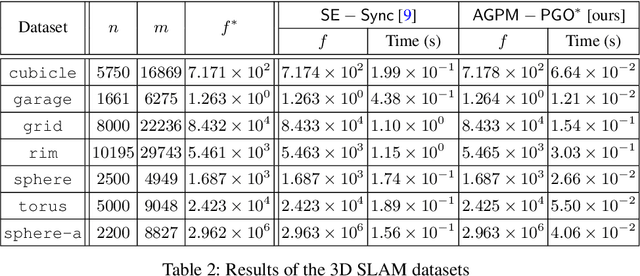
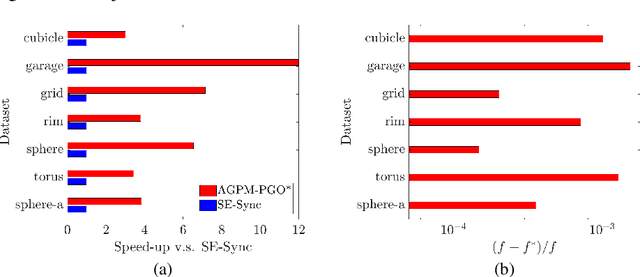
In this paper, we generalize proximal methods that were originally designed for convex optimization on normed vector space to non-convex pose graph optimization (PGO) on special Euclidean groups, and show that our proposed generalized proximal methods for PGO converge to first-order critical points. Furthermore, we propose methods that significantly accelerate the rates of convergence almost without loss of any theoretical guarantees. In addition, our proposed methods can be easily distributed and parallelized with no compromise of efficiency. The efficacy of this work is validated through implementation on simultaneous localization and mapping (SLAM) and distributed 3D sensor network localization, which indicate that our proposed methods are a lot faster than existing techniques to converge to sufficient accuracy for practical use.
* 29 pages
Formalizing and Guaranteeing* Human-Robot Interaction
Jun 30, 2020
Robot capabilities are maturing across domains, from self-driving cars, to bipeds and drones. As a result, robots will soon no longer be confined to safety-controlled industrial settings; instead, they will directly interact with the general public. The growing field of Human-Robot Interaction (HRI) studies various aspects of this scenario - from social norms to joint action to human-robot teams and more. Researchers in HRI have made great strides in developing models, methods, and algorithms for robots acting with and around humans, but these "computational HRI" models and algorithms generally do not come with formal guarantees and constraints on their operation. To enable human-interactive robots to move from the lab to real-world deployments, we must address this gap. This article provides an overview of verification, validation and synthesis techniques used to create demonstrably trustworthy systems, describes several HRI domains that could benefit from such techniques, and provides a roadmap for the challenges and the research needed to create formalized and guaranteed human-robot interaction.
CPL-SLAM: Efficient and Certifiably Correct Planar Graph-Based SLAM Using the Complex Number Representation
Jun 25, 2020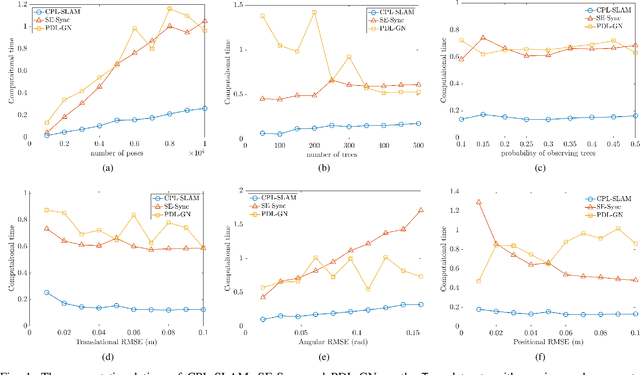
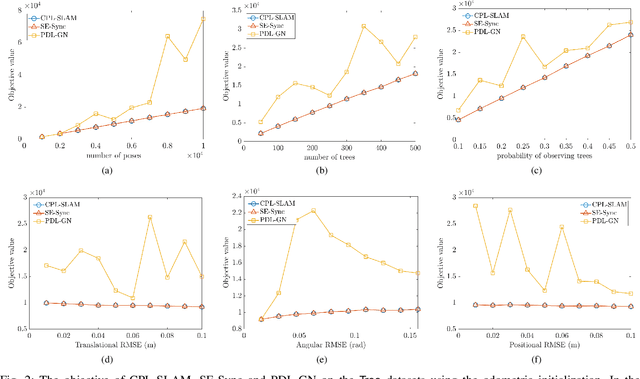
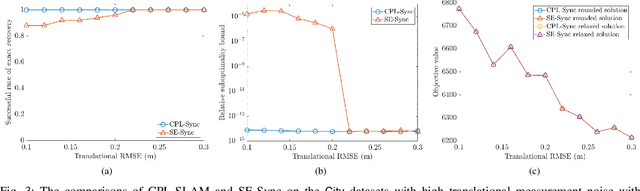
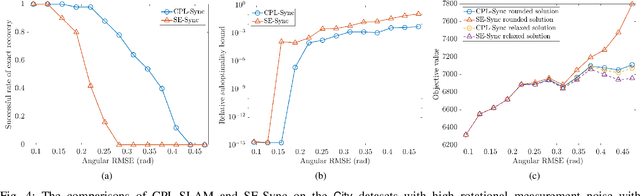
In this paper, we consider the problem of planar graph-based simultaneous localization and mapping (SLAM) that involves both poses of the autonomous agent and positions of observed landmarks. We present CPL-SLAM, an efficient and certifiably correct algorithm to solve planar graph-based SLAM using the complex number representation. We formulate and simplify planar graph-based SLAM as the maximum likelihood estimation (MLE) on the product of unit complex numbers, and relax this nonconvex quadratic complex optimization problem to convex complex semidefinite programming (SDP). Furthermore, we simplify the corresponding complex semidefinite programming to Riemannian staircase optimization (RSO) on the complex oblique manifold that can be solved with the Riemannian trust region (RTR) method. In addition, we prove that the SDP relaxation and RSO simplification are tight as long as the noise magnitude is below a certain threshold. The efficacy of this work is validated through applications of CPL-SLAM and comparisons with existing state-of-the-art methods on planar graph-based SLAM, which indicates that our proposed algorithm is capable of solving planar graph-based SLAM certifiably, and is more efficient in numerical computation and more robust to measurement noise than existing state-of-the-art methods. The C++ code for CPL-SLAM is available at https://github.com/MurpheyLab/CPL-SLAM.
Data-driven Koopman Operators for Model-based Shared Control of Human-Machine Systems
Jun 12, 2020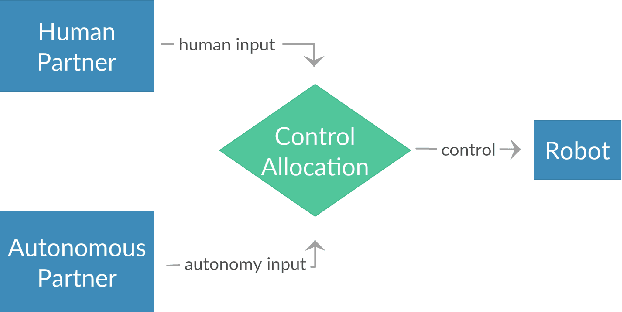
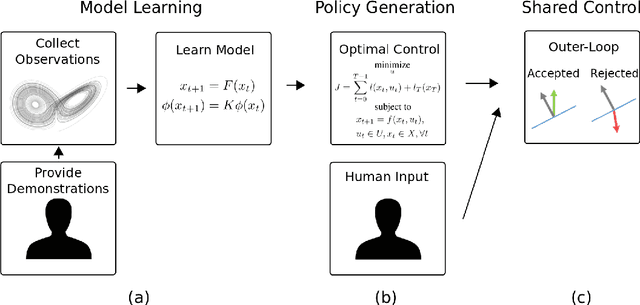
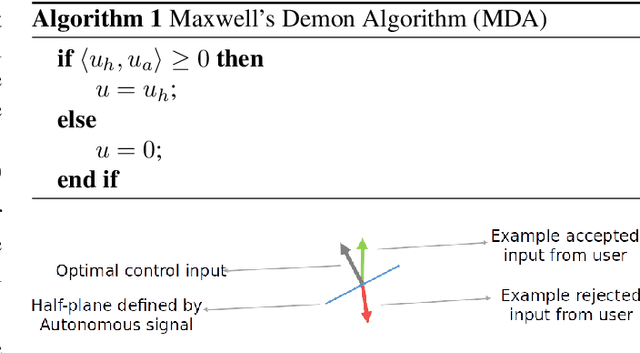
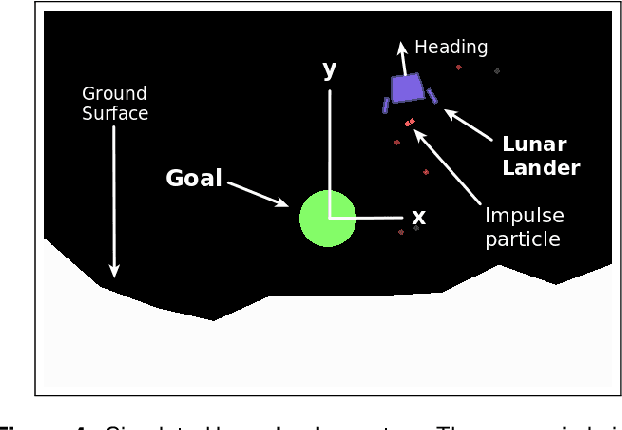
We present a data-driven shared control algorithm that can be used to improve a human operator's control of complex dynamic machines and achieve tasks that would otherwise be challenging, or impossible, for the user on their own. Our method assumes no a priori knowledge of the system dynamics. Instead, both the dynamics and information about the user's interaction are learned from observation through the use of a Koopman operator. Using the learned model, we define an optimization problem to compute the autonomous partner's control policy. Finally, we dynamically allocate control authority to each partner based on a comparison of the user input and the autonomously generated control. We refer to this idea as model-based shared control (MbSC). We evaluate the efficacy of our approach with two human subjects studies consisting of 32 total participants (16 subjects in each study). The first study imposes a linear constraint on the modeling and autonomous policy generation algorithms. The second study explores the more general, nonlinear variant. Overall, we find that model-based shared control significantly improves task and control metrics when compared to a natural learning, or user only, control paradigm. Our experiments suggest that models learned via the Koopman operator generalize across users, indicating that it is not necessary to collect data from each individual user before providing assistance with MbSC. We also demonstrate the data-efficiency of MbSC and consequently, it's usefulness in online learning paradigms. Finally, we find that the nonlinear variant has a greater impact on a user's ability to successfully achieve a defined task than the linear variant.