 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainably Safe Reinforcement Learning
Jun 03, 2026Trust in a decision-making system requires both safety guarantees and the ability to interpret and understand its behavior. This is particularly important for learned systems, whose decision-making processes are often highly opaque. Shielding is a prominent model-based technique for enforcing safety in reinforcement learning. However, because shields are automatically synthesized using rigorous formal methods, their decisions are often similarly difficult for humans to interpret. Recently, decision trees became customary to represent controllers and policies. However, since shields are inherently non-deterministic, their decision tree representations become too large to be explainable in practice. To address this challenge, we propose a novel approach for explainable safe RL that enhances trust by providing human-interpretable explanations of the shield's decisions. Our method represents the shielding policy as a hierarchy of decision trees, offering top-down, case-based explanations. At design time, we use a world model to analyze the safety risks of executing actions in given states. Based on this analysis, we construct both the shield and a high-level decision tree that classifies states into risk categories (safe, critical, dangerous, unsafe), explaining why a situation may be safety-critical. At runtime, we generate localized decision trees that explain which actions are allowed and why others are deemed unsafe. Our method facilitates explainability of the safety aspect in safe-by-shielding reinforcement learning, requires no additional information beyond what is already used for shielding, incurs minimal overhead, and integrates readily into existing shielded RL pipelines. In our experiments, we compute explanations using decision trees that are several orders of magnitude smaller than the original shield.
Logic of Fuzzy Paths
Apr 27, 2026We introduce a new family of temporal logics intended for specifications in motion planning (MP). It builds upon the signal temporal logic (STL), which is a linear-time logic over real-valued signals that possess quantitative semantics and thus became popular in the areas of cyber-physical systems, robotics, and specifically robot MP. However, in contrast to STL, the proposed logic works with paths as first-class citizens, separating the concerns of geometry and of logic. This in turn leads to simpler and more understandable formulae, and a more refined notion of satisfaction being able to reflect also preferences over behaviours. Technically, the logic is built on fuzzy, time-varying signal constraints. As a consequence of this expressivity, it is (i) more usable for human-given specifications in MP and (ii) more amenable to learning specifications from demonstrations than other logics. The former is important for the traditional style of verification in robot MP; the latter is becoming recognized as crucial for mining data-given tasks and controller synthesis in human-aware MP. We expose the advantages of our proposed logic on examples and show the versatility and flexibility of the framework on a number of scenarios. Finally, we give a learning algorithm with a prototype implementation and discuss the possibilities of model checking and monitoring.
SemML 2.0: Synthesizing Controllers for LTL
Apr 27, 2026Synthesizing a reactive system from specifications given in linear temporal logic (LTL) is a classical problem, finding its applications in safety-critical systems design. These systems are typically represented using either Mealy machines or AIGER circuits. We present the second version of SemML, which outperforms all state-of-the-art tools for finding either solution. Aside from implementing the classical automata-theoretic approach, our tool utilizes partial exploration and machine-learning guidance for obtaining solutions efficiently, and numerous heuristics and improvements of classic algorithms for extracting small representations of these solutions. We evaluate our tool against the existing state-of-the-art tools (in particular Strix, LtlSynt, and the previous version of SemML) on the dataset of the synthesis competition SYNTCOMP. We show that we solve significantly more instances and do so much faster than other tools, while maintaining state-of-the-art solution quality.
Gaussian-Based and Outside-the-Box Runtime Monitoring Join Forces
Oct 08, 2024Since neural networks can make wrong predictions even with high confidence, monitoring their behavior at runtime is important, especially in safety-critical domains like autonomous driving. In this paper, we combine ideas from previous monitoring approaches based on observing the activation values of hidden neurons. In particular, we combine the Gaussian-based approach, which observes whether the current value of each monitored neuron is similar to typical values observed during training, and the Outside-the-Box monitor, which creates clusters of the acceptable activation values, and, thus, considers the correlations of the neurons' values. Our experiments evaluate the achieved improvement.
stl2vec: Semantic and Interpretable Vector Representation of Temporal Logic
May 23, 2024



Integrating symbolic knowledge and data-driven learning algorithms is a longstanding challenge in Artificial Intelligence. Despite the recognized importance of this task, a notable gap exists due to the discreteness of symbolic representations and the continuous nature of machine-learning computations. One of the desired bridges between these two worlds would be to define semantically grounded vector representation (feature embedding) of logic formulae, thus enabling to perform continuous learning and optimization in the semantic space of formulae. We tackle this goal for knowledge expressed in Signal Temporal Logic (STL) and devise a method to compute continuous embeddings of formulae with several desirable properties: the embedding (i) is finite-dimensional, (ii) faithfully reflects the semantics of the formulae, (iii) does not require any learning but instead is defined from basic principles, (iv) is interpretable. Another significant contribution lies in demonstrating the efficacy of the approach in two tasks: learning model checking, where we predict the probability of requirements being satisfied in stochastic processes; and integrating the embeddings into a neuro-symbolic framework, to constrain the output of a deep-learning generative model to comply to a given logical specification.
Learning Algorithms for Verification of Markov Decision Processes
Mar 20, 2024



We present a general framework for applying learning algorithms and heuristical guidance to the verification of Markov decision processes (MDPs). The primary goal of our techniques is to improve performance by avoiding an exhaustive exploration of the state space, instead focussing on particularly relevant areas of the system, guided by heuristics. Our work builds on the previous results of Br{\'{a}}zdil et al., significantly extending it as well as refining several details and fixing errors. The presented framework focuses on probabilistic reachability, which is a core problem in verification, and is instantiated in two distinct scenarios. The first assumes that full knowledge of the MDP is available, in particular precise transition probabilities. It performs a heuristic-driven partial exploration of the model, yielding precise lower and upper bounds on the required probability. The second tackles the case where we may only sample the MDP without knowing the exact transition dynamics. Here, we obtain probabilistic guarantees, again in terms of both the lower and upper bounds, which provides efficient stopping criteria for the approximation. In particular, the latter is an extension of statistical model-checking (SMC) for unbounded properties in MDPs. In contrast to other related approaches, we do not restrict our attention to time-bounded (finite-horizon) or discounted properties, nor assume any particular structural properties of the MDP.
Syntactic vs Semantic Linear Abstraction and Refinement of Neural Networks
Jul 20, 2023



Abstraction is a key verification technique to improve scalability. However, its use for neural networks is so far extremely limited. Previous approaches for abstracting classification networks replace several neurons with one of them that is similar enough. We can classify the similarity as defined either syntactically (using quantities on the connections between neurons) or semantically (on the activation values of neurons for various inputs). Unfortunately, the previous approaches only achieve moderate reductions, when implemented at all. In this work, we provide a more flexible framework where a neuron can be replaced with a linear combination of other neurons, improving the reduction. We apply this approach both on syntactic and semantic abstractions, and implement and evaluate them experimentally. Further, we introduce a refinement method for our abstractions, allowing for finding a better balance between reduction and precision.
Stopping Criteria for Value Iteration on Stochastic Games with Quantitative Objectives
Apr 19, 2023



A classic solution technique for Markov decision processes (MDP) and stochastic games (SG) is value iteration (VI). Due to its good practical performance, this approximative approach is typically preferred over exact techniques, even though no practical bounds on the imprecision of the result could be given until recently. As a consequence, even the most used model checkers could return arbitrarily wrong results. Over the past decade, different works derived stopping criteria, indicating when the precision reaches the desired level, for various settings, in particular MDP with reachability, total reward, and mean payoff, and SG with reachability. In this paper, we provide the first stopping criteria for VI on SG with total reward and mean payoff, yielding the first anytime algorithms in these settings. To this end, we provide the solution in two flavours: First through a reduction to the MDP case and second directly on SG. The former is simpler and automatically utilizes any advances on MDP. The latter allows for more local computations, heading towards better practical efficiency. Our solution unifies the previously mentioned approaches for MDP and SG and their underlying ideas. To achieve this, we isolate objective-specific subroutines as well as identify objective-independent concepts. These structural concepts, while surprisingly simple, form the very essence of the unified solution.
Algebraically Explainable Controllers: Decision Trees and Support Vector Machines Join Forces
Aug 29, 2022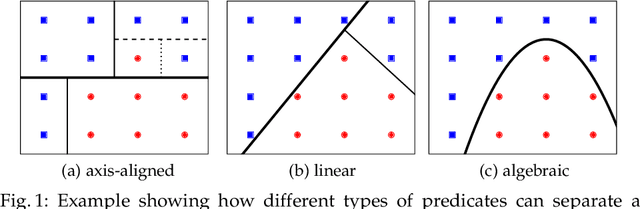
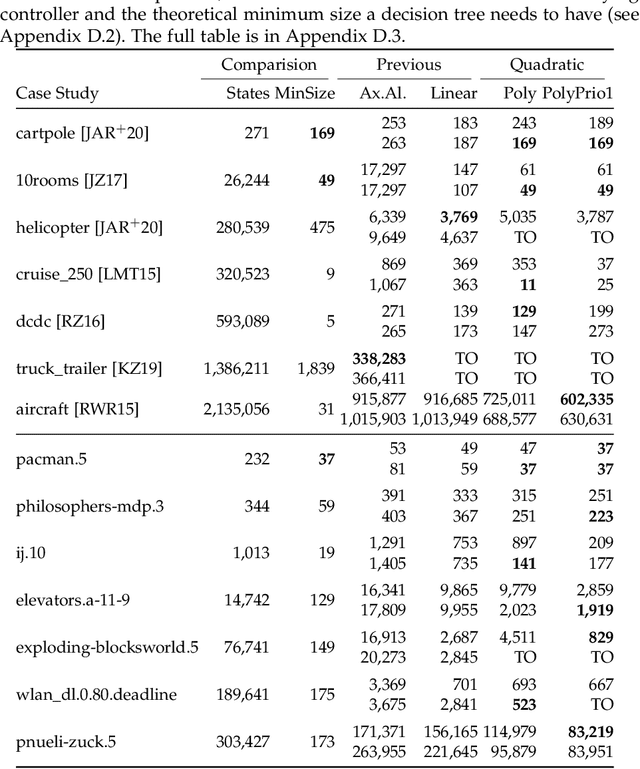
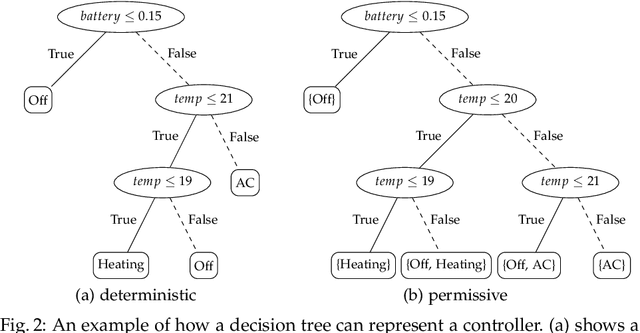

Recently, decision trees (DT) have been used as an explainable representation of controllers (a.k.a. strategies, policies, schedulers). Although they are often very efficient and produce small and understandable controllers for discrete systems, complex continuous dynamics still pose a challenge. In particular, when the relationships between variables take more complex forms, such as polynomials, they cannot be obtained using the available DT learning procedures. In contrast, support vector machines provide a more powerful representation, capable of discovering many such relationships, but not in an explainable form. Therefore, we suggest to combine the two frameworks in order to obtain an understandable representation over richer, domain-relevant algebraic predicates. We demonstrate and evaluate the proposed method experimentally on established benchmarks.
PAC Statistical Model Checking of Mean Payoff in Discrete- and Continuous-Time MDP
Jun 03, 2022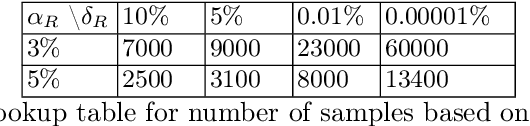
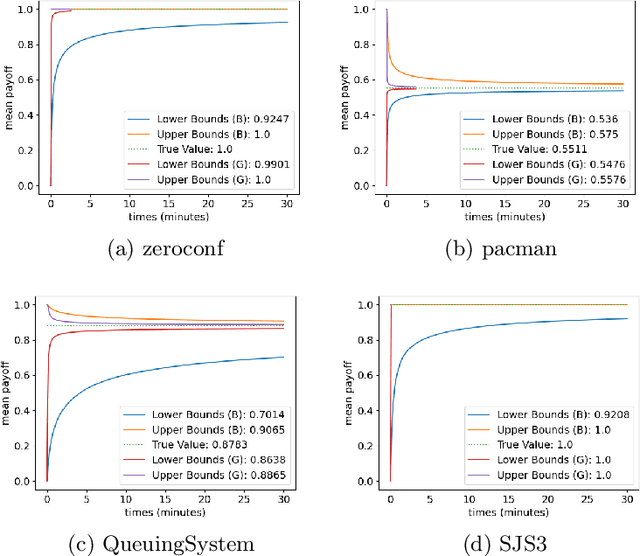
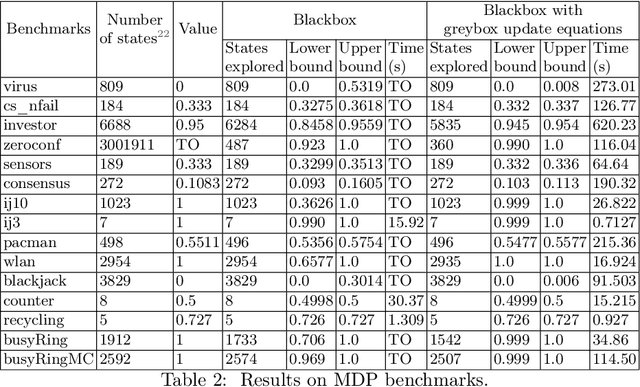
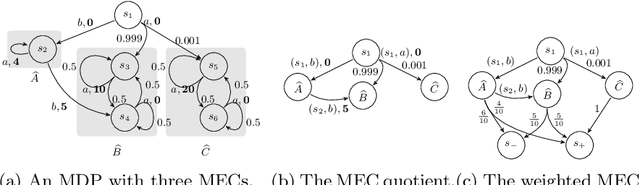
Markov decision processes (MDP) and continuous-time MDP (CTMDP) are the fundamental models for non-deterministic systems with probabilistic uncertainty. Mean payoff (a.k.a. long-run average reward) is one of the most classic objectives considered in their context. We provide the first algorithm to compute mean payoff probably approximately correctly in unknown MDP; further, we extend it to unknown CTMDP. We do not require any knowledge of the state space, only a lower bound on the minimum transition probability, which has been advocated in literature. In addition to providing probably approximately correct (PAC) bounds for our algorithm, we also demonstrate its practical nature by running experiments on standard benchmarks.