 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTing Wang
Reasoning over Multi-view Knowledge Graphs
Sep 27, 2022
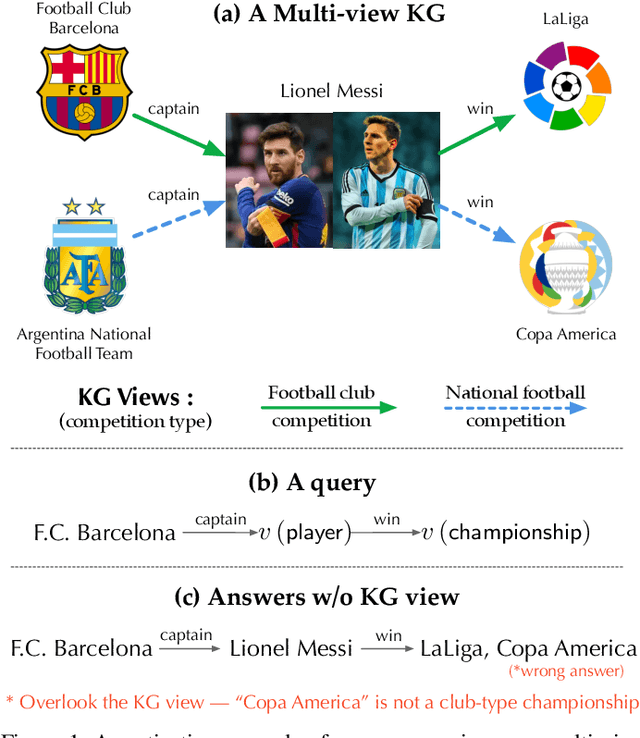
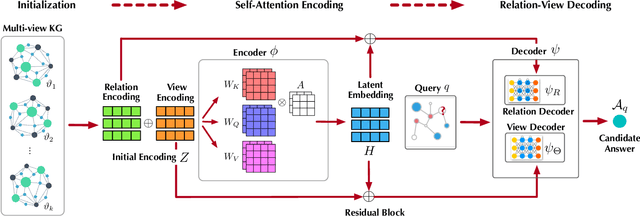
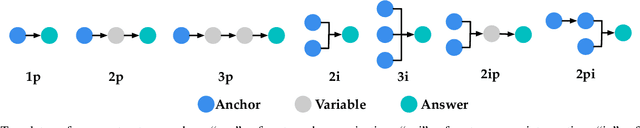
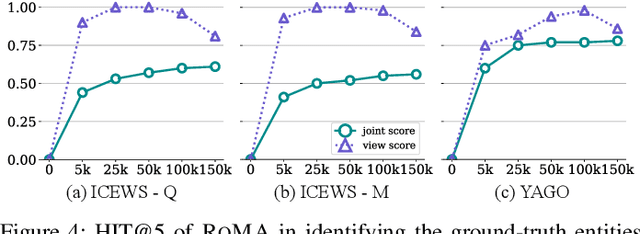
Recently, knowledge representation learning (KRL) is emerging as the state-of-the-art approach to process queries over knowledge graphs (KGs), wherein KG entities and the query are embedded into a latent space such that entities that answer the query are embedded close to the query. Yet, despite the intensive research on KRL, most existing studies either focus on homogenous KGs or assume KG completion tasks (i.e., inference of missing facts), while answering complex logical queries over KGs with multiple aspects (multi-view KGs) remains an open challenge. To bridge this gap, in this paper, we present ROMA, a novel KRL framework for answering logical queries over multi-view KGs. Compared with the prior work, ROMA departs in major aspects. (i) It models a multi-view KG as a set of overlaying sub-KGs, each corresponding to one view, which subsumes many types of KGs studied in the literature (e.g., temporal KGs). (ii) It supports complex logical queries with varying relation and view constraints (e.g., with complex topology and/or from multiple views); (iii) It scales up to KGs of large sizes (e.g., millions of facts) and fine-granular views (e.g., dozens of views); (iv) It generalizes to query structures and KG views that are unobserved during training. Extensive empirical evaluation on real-world KGs shows that \system significantly outperforms alternative methods.
Multi-Document Scientific Summarization from a Knowledge Graph-Centric View
Sep 09, 2022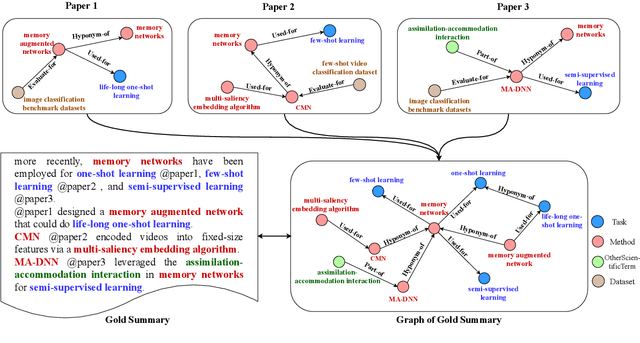
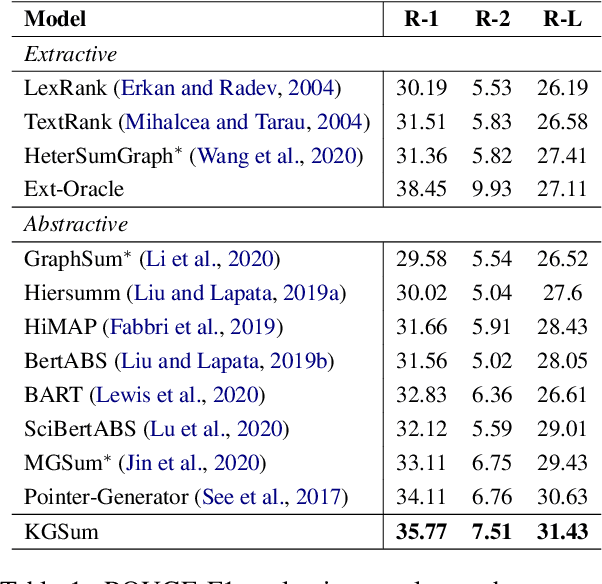
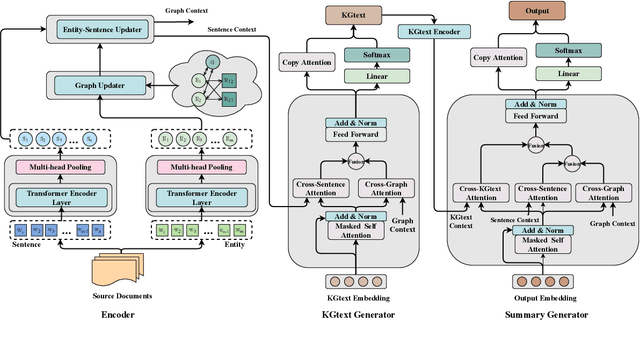
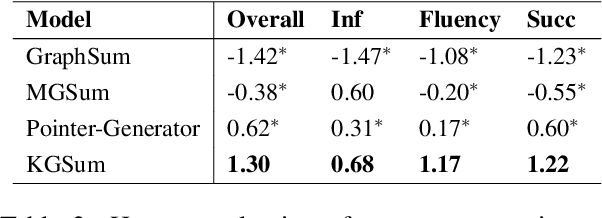
Multi-Document Scientific Summarization (MDSS) aims to produce coherent and concise summaries for clusters of topic-relevant scientific papers. This task requires precise understanding of paper content and accurate modeling of cross-paper relationships. Knowledge graphs convey compact and interpretable structured information for documents, which makes them ideal for content modeling and relationship modeling. In this paper, we present KGSum, an MDSS model centred on knowledge graphs during both the encoding and decoding process. Specifically, in the encoding process, two graph-based modules are proposed to incorporate knowledge graph information into paper encoding, while in the decoding process, we propose a two-stage decoder by first generating knowledge graph information of summary in the form of descriptive sentences, followed by generating the final summary. Empirical results show that the proposed architecture brings substantial improvements over baselines on the Multi-Xscience dataset.
"Is your explanation stable?": A Robustness Evaluation Framework for Feature Attribution
Sep 05, 2022
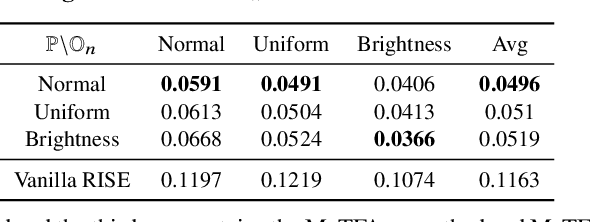
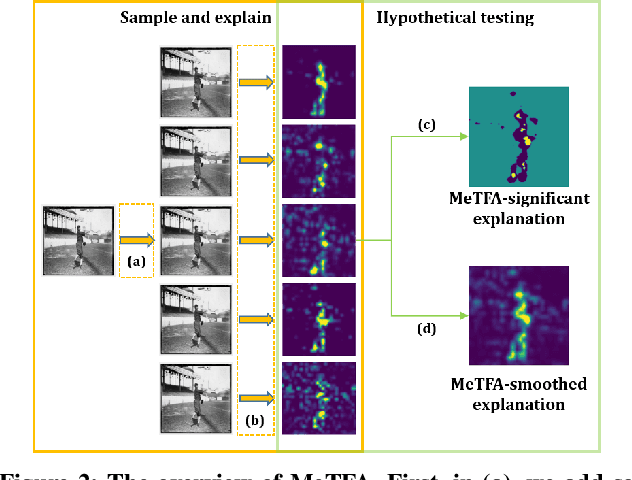
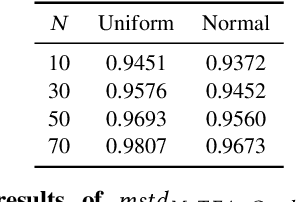
Understanding the decision process of neural networks is hard. One vital method for explanation is to attribute its decision to pivotal features. Although many algorithms are proposed, most of them solely improve the faithfulness to the model. However, the real environment contains many random noises, which may leads to great fluctuations in the explanations. More seriously, recent works show that explanation algorithms are vulnerable to adversarial attacks. All of these make the explanation hard to trust in real scenarios. To bridge this gap, we propose a model-agnostic method \emph{Median Test for Feature Attribution} (MeTFA) to quantify the uncertainty and increase the stability of explanation algorithms with theoretical guarantees. MeTFA has the following two functions: (1) examine whether one feature is significantly important or unimportant and generate a MeTFA-significant map to visualize the results; (2) compute the confidence interval of a feature attribution score and generate a MeTFA-smoothed map to increase the stability of the explanation. Experiments show that MeTFA improves the visual quality of explanations and significantly reduces the instability while maintaining the faithfulness. To quantitatively evaluate the faithfulness of an explanation under different noise settings, we further propose several robust faithfulness metrics. Experiment results show that the MeTFA-smoothed explanation can significantly increase the robust faithfulness. In addition, we use two scenarios to show MeTFA's potential in the applications. First, when applied to the SOTA explanation method to locate context bias for semantic segmentation models, MeTFA-significant explanations use far smaller regions to maintain 99\%+ faithfulness. Second, when tested with different explanation-oriented attacks, MeTFA can help defend vanilla, as well as adaptive, adversarial attacks against explanations.
Confidence Matters: Inspecting Backdoors in Deep Neural Networks via Distribution Transfer
Aug 13, 2022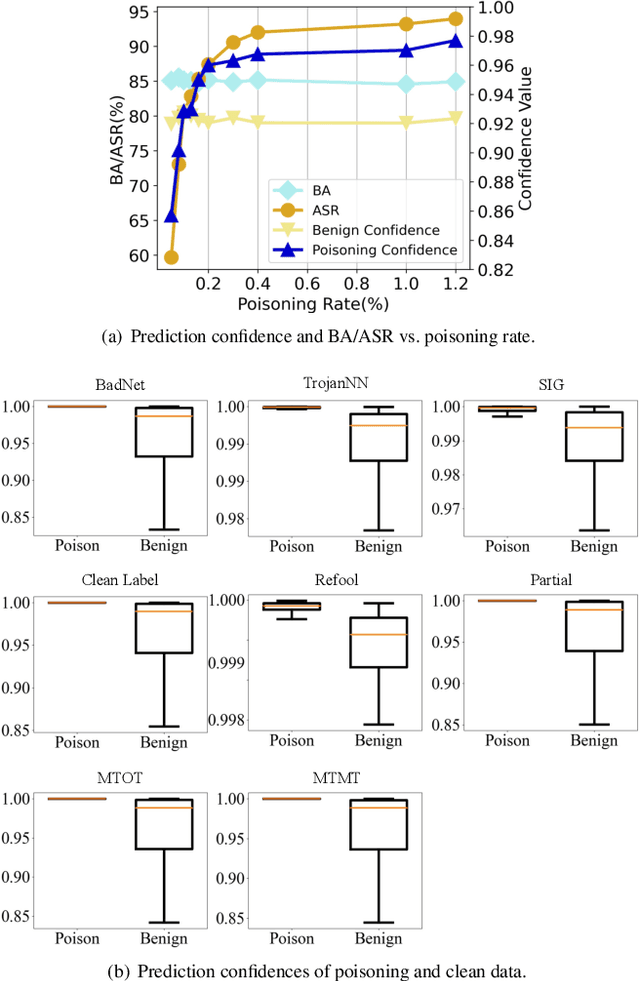
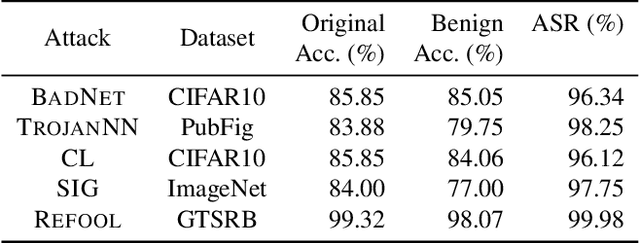
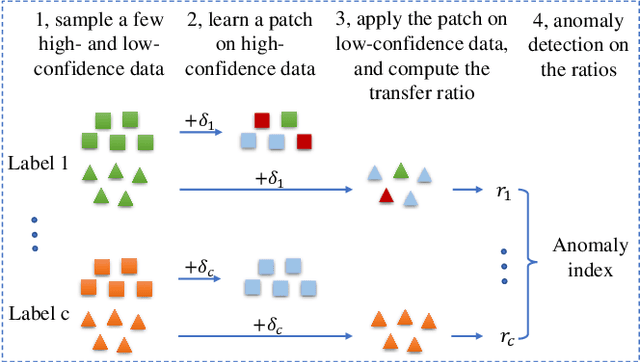

Backdoor attacks have been shown to be a serious security threat against deep learning models, and detecting whether a given model has been backdoored becomes a crucial task. Existing defenses are mainly built upon the observation that the backdoor trigger is usually of small size or affects the activation of only a few neurons. However, the above observations are violated in many cases especially for advanced backdoor attacks, hindering the performance and applicability of the existing defenses. In this paper, we propose a backdoor defense DTInspector built upon a new observation. That is, an effective backdoor attack usually requires high prediction confidence on the poisoned training samples, so as to ensure that the trained model exhibits the targeted behavior with a high probability. Based on this observation, DTInspector first learns a patch that could change the predictions of most high-confidence data, and then decides the existence of backdoor by checking the ratio of prediction changes after applying the learned patch on the low-confidence data. Extensive evaluations on five backdoor attacks, four datasets, and three advanced attacking types demonstrate the effectiveness of the proposed defense.
Reconfigurable Intelligent Surfaces Empowered Green Wireless Networks with User Admission Control
Jun 16, 2022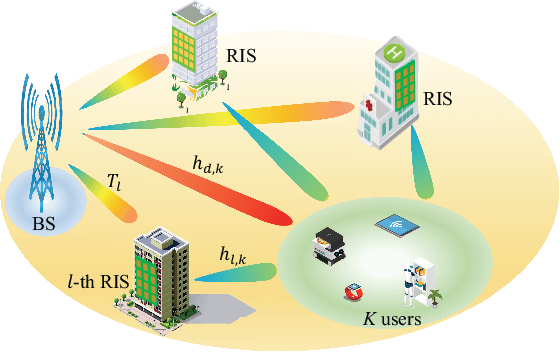
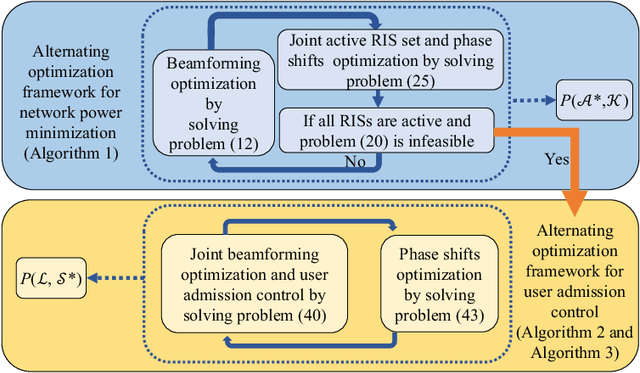
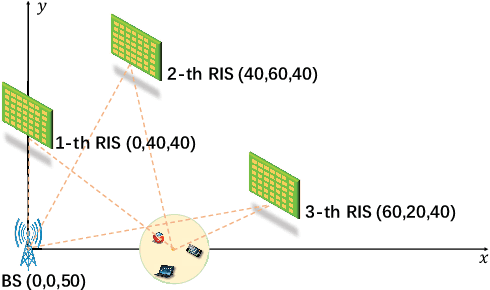
Reconfigurable intelligent surface (RIS) has emerged as a cost-effective and energy-efficient technique for 6G. By adjusting the phase shifts of passive reflecting elements, RIS is capable of suppressing the interference and combining the desired signals constructively at receivers, thereby significantly enhancing the performance of communication In this paper, we consider a green multi-user multi-antenna cellular network, where multiple RISs are deployed to provide energy-efficient communication service to end users. We jointly optimize the phase shifts of RISs, beamforming of the base stations, and the active RIS set with the aim of minimizing the power consumption of the base station (BS) and RISs subject to the quality of service (QoS) constraints of users and the transmit power constraint of the BS. However, the problem is mixed combinatorial and nonconvex, and there is a potential infeasibility issue when the QoS constraints cannot be guaranteed by all users. To deal with the infeasibility issue, we further investigate a user admission control problem to jointly optimize the transmit beamforming, RIS phase shifts, and the admitted user set. A unified alternating optimization (AO) framework is then proposed to solve both the power minimization and user admission control problems. Specifically, we first decompose the original nonconvex problem into several rank-one constrained optimization subproblems via matrix lifting. The proposed AO framework efficiently minimizes the power consumption of wireless networks as well as user admission control when the QoS constraints cannot be guaranteed by all users. Compared with the baseline algorithms, we illustrate that the proposed algorithm can achieve lower power consumption for given QoS constraints. Most importantly, the proposed algorithm successfully addresses the infeasibility issue with a QoS guarantee for active users.
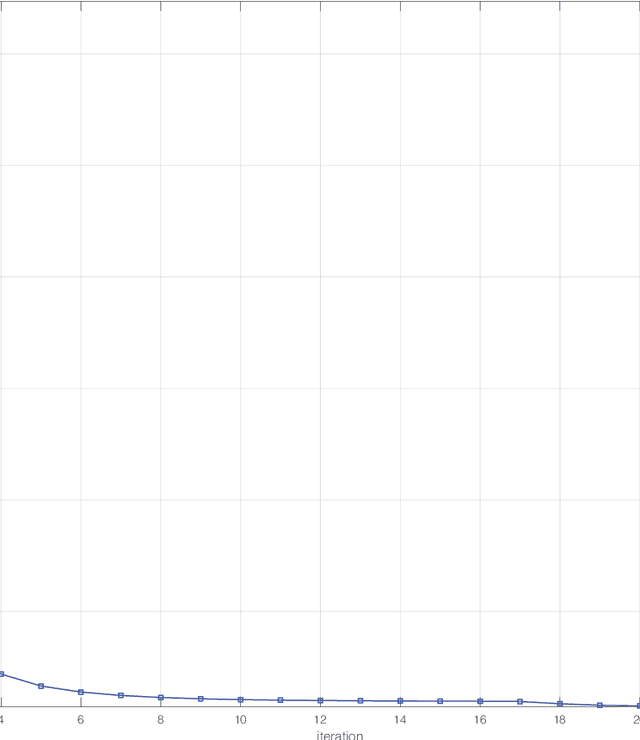
FedEntropy: Efficient Device Grouping for Federated Learning Using Maximum Entropy Judgment
May 24, 2022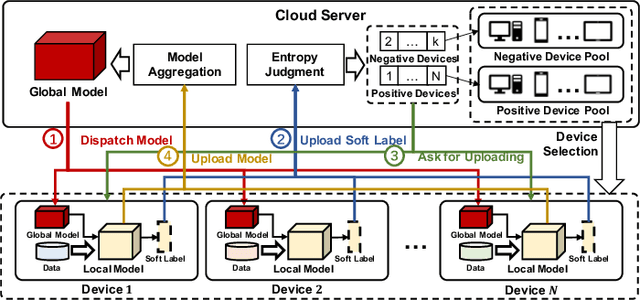
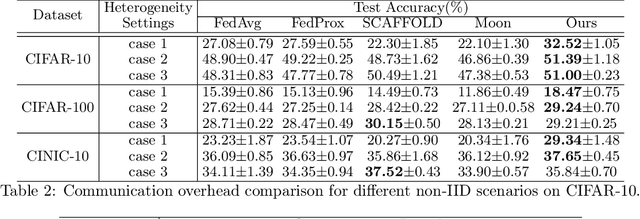
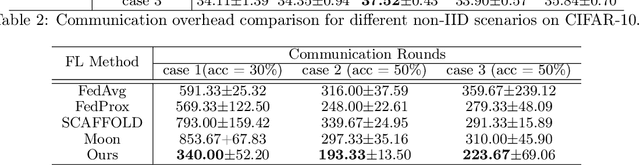
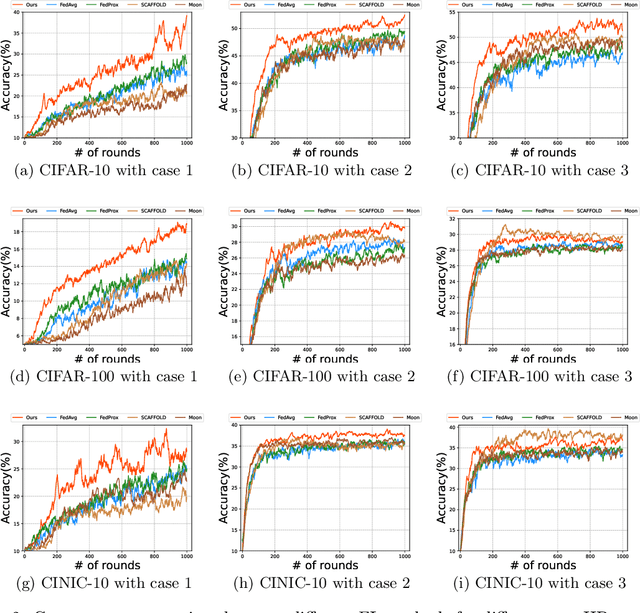
Along with the popularity of Artificial Intelligence (AI) and Internet-of-Things (IoT), Federated Learning (FL) has attracted steadily increasing attentions as a promising distributed machine learning paradigm, which enables the training of a central model on for numerous decentralized devices without exposing their privacy. However, due to the biased data distributions on involved devices, FL inherently suffers from low classification accuracy in non-IID scenarios. Although various device grouping method have been proposed to address this problem, most of them neglect both i) distinct data distribution characteristics of heterogeneous devices, and ii) contributions and hazards of local models, which are extremely important in determining the quality of global model aggregation. In this paper, we present an effective FL method named FedEntropy with a novel dynamic device grouping scheme, which makes full use of the above two factors based on our proposed maximum entropy judgement heuristic.Unlike existing FL methods that directly aggregate local models returned from all the selected devices, in one FL round FedEntropy firstly makes a judgement based on the pre-collected soft labels of selected devices and then only aggregates the local models that can maximize the overall entropy of these soft labels. Without collecting local models that are harmful for aggregation, FedEntropy can effectively improve global model accuracy while reducing the overall communication overhead. Comprehensive experimental results on well-known benchmarks show that, FedEntropy not only outperforms state-of-the-art FL methods in terms of model accuracy and communication overhead, but also can be integrated into them to enhance their classification performance.
A Comprehensive Survey of Few-shot Learning: Evolution, Applications, Challenges, and Opportunities
May 24, 2022
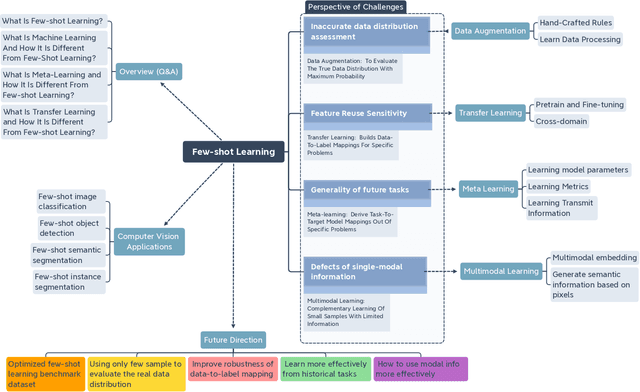
Few-shot learning (FSL) has emerged as an effective learning method and shows great potential. Despite the recent creative works in tackling FSL tasks, learning valid information rapidly from just a few or even zero samples still remains a serious challenge. In this context, we extensively investigated 200+ latest papers on FSL published in the past three years, aiming to present a timely and comprehensive overview of the most recent advances in FSL along with impartial comparisons of the strengths and weaknesses of the existing works. For the sake of avoiding conceptual confusion, we first elaborate and compare a set of similar concepts including few-shot learning, transfer learning, and meta-learning. Furthermore, we propose a novel taxonomy to classify the existing work according to the level of abstraction of knowledge in accordance with the challenges of FSL. To enrich this survey, in each subsection we provide in-depth analysis and insightful discussion about recent advances on these topics. Moreover, taking computer vision as an example, we highlight the important application of FSL, covering various research hotspots. Finally, we conclude the survey with unique insights into the technology evolution trends together with potential future research opportunities in the hope of providing guidance to follow-up research.
Neural Copula: A unified framework for estimating generic high-dimensional Copula functions
May 23, 2022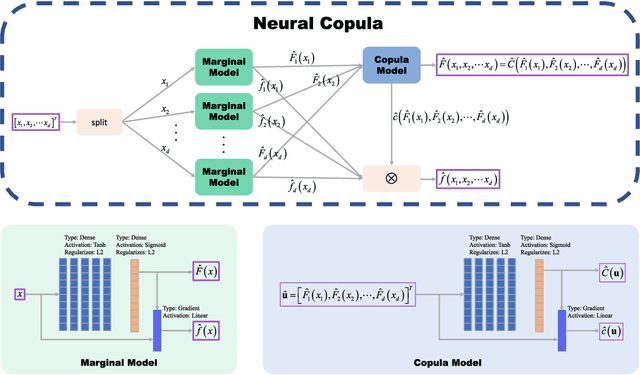

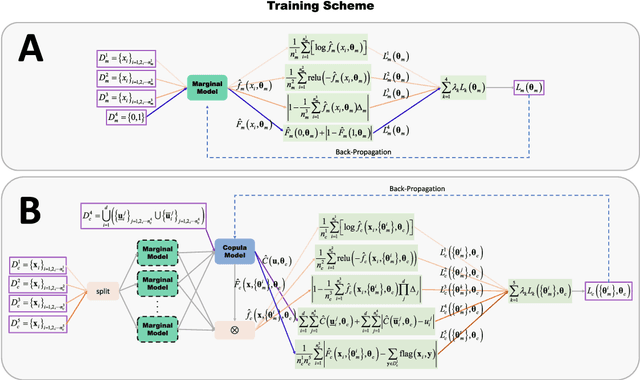

The Copula is widely used to describe the relationship between the marginal distribution and joint distribution of random variables. The estimation of high-dimensional Copula is difficult, and most existing solutions rely either on simplified assumptions or on complicating recursive decompositions. Therefore, people still hope to obtain a generic Copula estimation method with both universality and simplicity. To reach this goal, a novel neural network-based method (named Neural Copula) is proposed in this paper. In this method, a hierarchical unsupervised neural network is constructed to estimate the marginal distribution function and the Copula function by solving differential equations. In the training program, various constraints are imposed on both the neural network and its derivatives. The Copula estimated by the proposed method is smooth and has an analytic expression. The effectiveness of the proposed method is evaluated on both real-world datasets and complex numerical simulations. Experimental results show that Neural Copula's fitting quality for complex distributions is much better than classical methods. The relevant code for the experiments is available on GitHub. (We encourage the reader to run the program for a better understanding of the proposed method).
Model-Contrastive Learning for Backdoor Defense
May 17, 2022
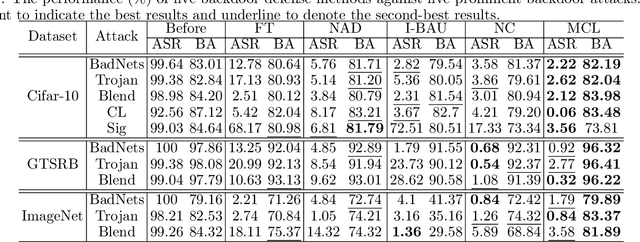
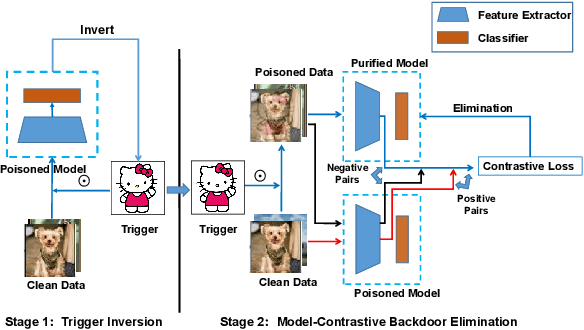
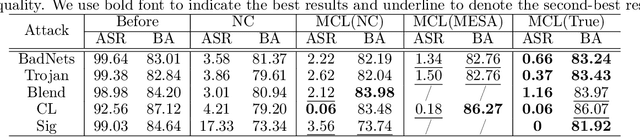
Due to the popularity of Artificial Intelligence (AI) techniques, we are witnessing an increasing number of backdoor injection attacks that are designed to maliciously threaten Deep Neural Networks (DNNs) causing misclassification. Although there exist various defense methods that can effectively erase backdoors from DNNs, they greatly suffer from both high Attack Success Rate (ASR) and a non-negligible loss in Benign Accuracy (BA). Inspired by the observation that a backdoored DNN tends to form a new cluster in its feature spaces for poisoned data, in this paper we propose a novel two-stage backdoor defense method, named MCLDef, based on Model-Contrastive Learning (MCL). In the first stage, our approach performs trigger inversion based on trigger synthesis, where the resultant trigger can be used to generate poisoned data. In the second stage, under the guidance of MCL and our defined positive and negative pairs, MCLDef can purify the backdoored model by pulling the feature representations of poisoned data towards those of their clean data counterparts. Due to the shrunken cluster of poisoned data, the backdoor formed by end-to-end supervised learning is eliminated. Comprehensive experimental results show that, with only 5% of clean data, MCLDef significantly outperforms state-of-the-art defense methods by up to 95.79% reduction in ASR, while in most cases the BA degradation can be controlled within less than 2%. Our code is available at https://github.com/WeCanShow/MCL.