 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble-Compression: A New Method for Parallel Training of Deep Neural Networks
Jul 18, 2017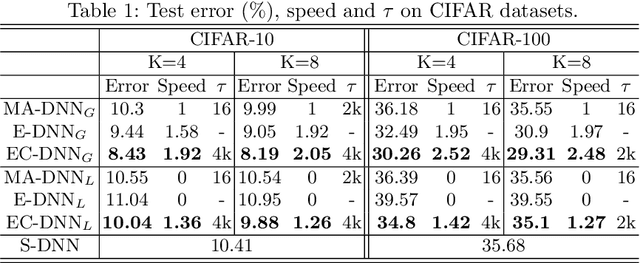
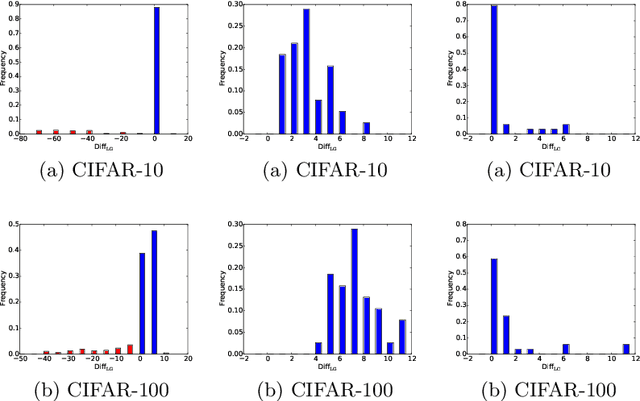
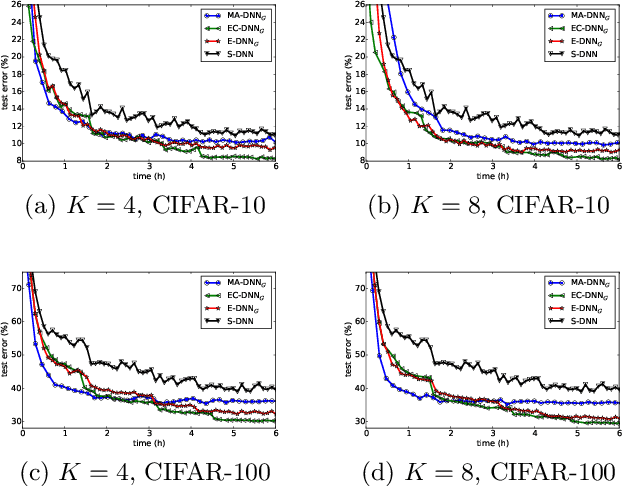
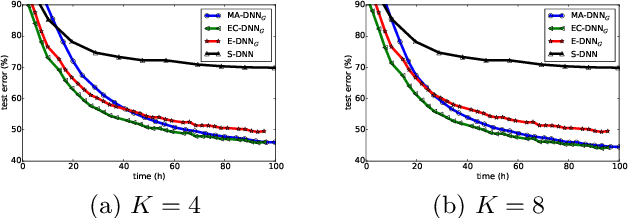
Parallelization framework has become a necessity to speed up the training of deep neural networks (DNN) recently. Such framework typically employs the Model Average approach, denoted as MA-DNN, in which parallel workers conduct respective training based on their own local data while the parameters of local models are periodically communicated and averaged to obtain a global model which serves as the new start of local models. However, since DNN is a highly non-convex model, averaging parameters cannot ensure that such global model can perform better than those local models. To tackle this problem, we introduce a new parallel training framework called Ensemble-Compression, denoted as EC-DNN. In this framework, we propose to aggregate the local models by ensemble, i.e., averaging the outputs of local models instead of the parameters. As most of prevalent loss functions are convex to the output of DNN, the performance of ensemble-based global model is guaranteed to be at least as good as the average performance of local models. However, a big challenge lies in the explosion of model size since each round of ensemble can give rise to multiple times size increment. Thus, we carry out model compression after each ensemble, specialized by a distillation based method in this paper, to reduce the size of the global model to be the same as the local ones. Our experimental results demonstrate the prominent advantage of EC-DNN over MA-DNN in terms of both accuracy and speedup.
Dual Supervised Learning
Jul 03, 2017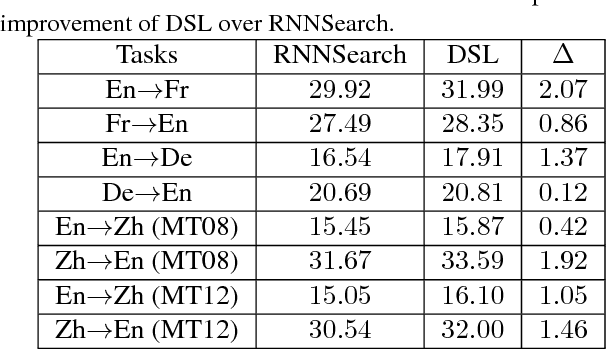
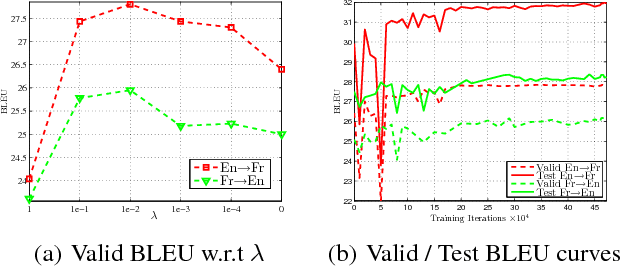


Many supervised learning tasks are emerged in dual forms, e.g., English-to-French translation vs. French-to-English translation, speech recognition vs. text to speech, and image classification vs. image generation. Two dual tasks have intrinsic connections with each other due to the probabilistic correlation between their models. This connection is, however, not effectively utilized today, since people usually train the models of two dual tasks separately and independently. In this work, we propose training the models of two dual tasks simultaneously, and explicitly exploiting the probabilistic correlation between them to regularize the training process. For ease of reference, we call the proposed approach \emph{dual supervised learning}. We demonstrate that dual supervised learning can improve the practical performances of both tasks, for various applications including machine translation, image processing, and sentiment analysis.
Word-Entity Duet Representations for Document Ranking
Jun 20, 2017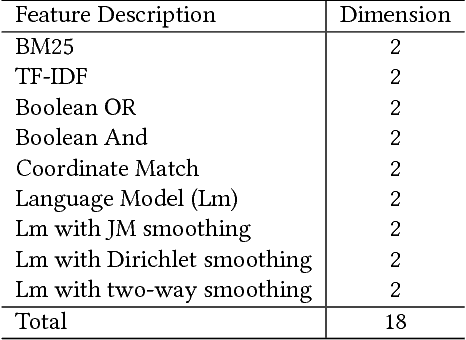
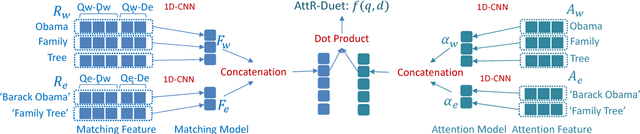

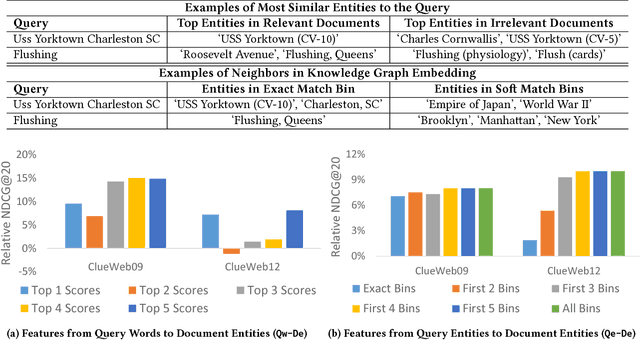
This paper presents a word-entity duet framework for utilizing knowledge bases in ad-hoc retrieval. In this work, the query and documents are modeled by word-based representations and entity-based representations. Ranking features are generated by the interactions between the two representations, incorporating information from the word space, the entity space, and the cross-space connections through the knowledge graph. To handle the uncertainties from the automatically constructed entity representations, an attention-based ranking model AttR-Duet is developed. With back-propagation from ranking labels, the model learns simultaneously how to demote noisy entities and how to rank documents with the word-entity duet. Evaluation results on TREC Web Track ad-hoc task demonstrate that all of the four-way interactions in the duet are useful, the attention mechanism successfully steers the model away from noisy entities, and together they significantly outperform both word-based and entity-based learning to rank systems.
Asynchronous Stochastic Gradient Descent with Delay Compensation
Jun 14, 2017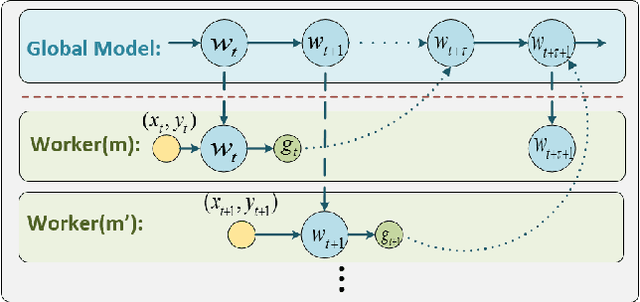
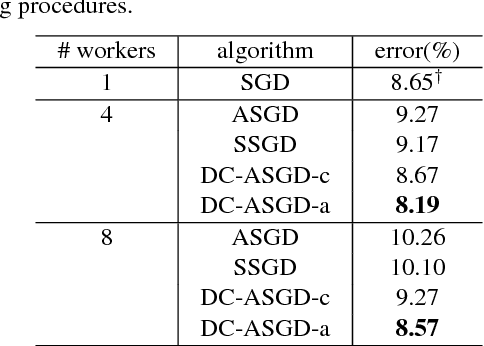
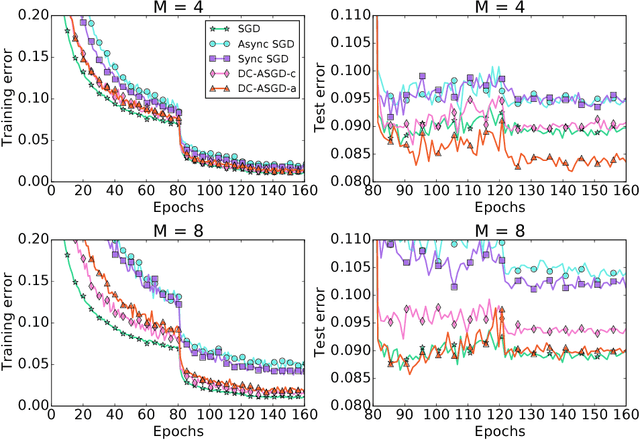
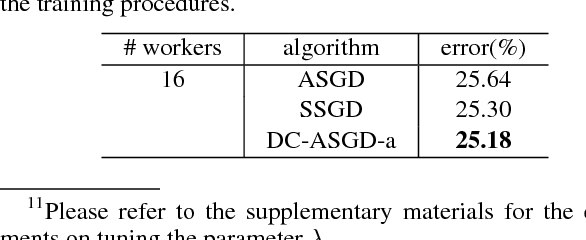
With the fast development of deep learning, it has become common to learn big neural networks using massive training data. Asynchronous Stochastic Gradient Descent (ASGD) is widely adopted to fulfill this task for its efficiency, which is, however, known to suffer from the problem of delayed gradients. That is, when a local worker adds its gradient to the global model, the global model may have been updated by other workers and this gradient becomes "delayed". We propose a novel technology to compensate this delay, so as to make the optimization behavior of ASGD closer to that of sequential SGD. This is achieved by leveraging Taylor expansion of the gradient function and efficient approximation to the Hessian matrix of the loss function. We call the new algorithm Delay Compensated ASGD (DC-ASGD). We evaluated the proposed algorithm on CIFAR-10 and ImageNet datasets, and the experimental results demonstrate that DC-ASGD outperforms both synchronous SGD and asynchronous SGD, and nearly approaches the performance of sequential SGD.
* 20 pages, 5 figures
Reinforcement Learning for Learning Rate Control
May 31, 2017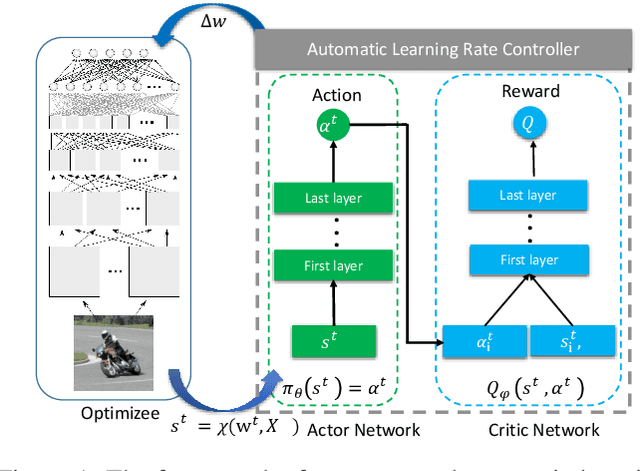
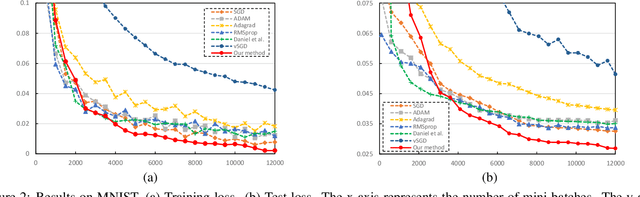
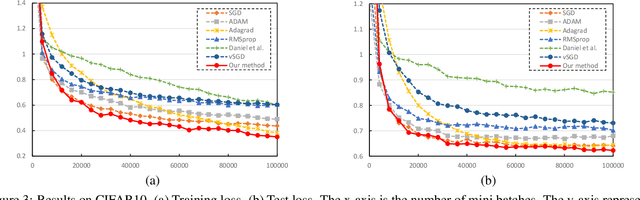
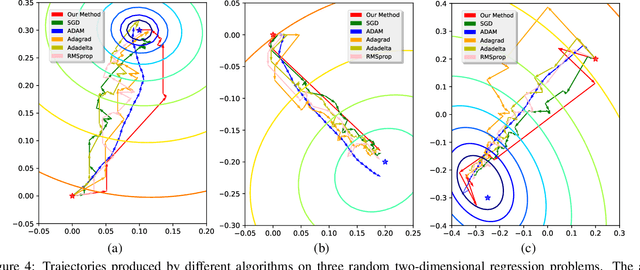
Stochastic gradient descent (SGD), which updates the model parameters by adding a local gradient times a learning rate at each step, is widely used in model training of machine learning algorithms such as neural networks. It is observed that the models trained by SGD are sensitive to learning rates and good learning rates are problem specific. We propose an algorithm to automatically learn learning rates using neural network based actor-critic methods from deep reinforcement learning (RL).In particular, we train a policy network called actor to decide the learning rate at each step during training, and a value network called critic to give feedback about quality of the decision (e.g., the goodness of the learning rate outputted by the actor) that the actor made. The introduction of auxiliary actor and critic networks helps the main network achieve better performance. Experiments on different datasets and network architectures show that our approach leads to better convergence of SGD than human-designed competitors.
Learning What Data to Learn
Feb 28, 2017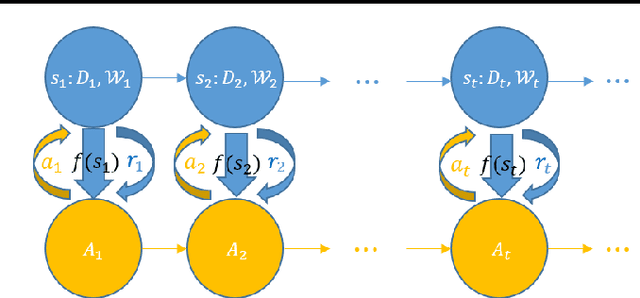
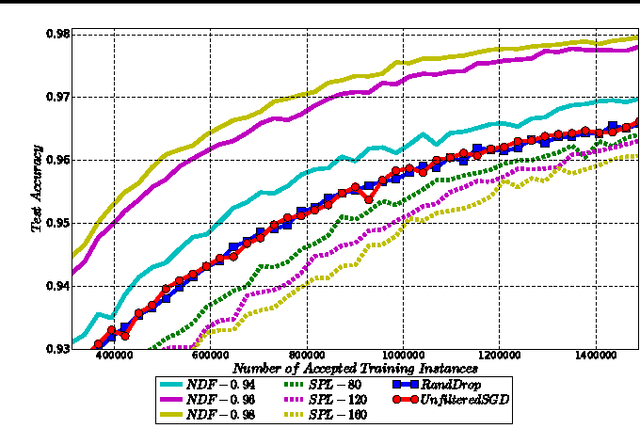
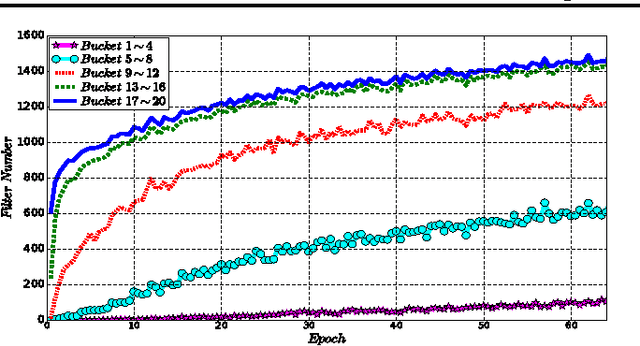
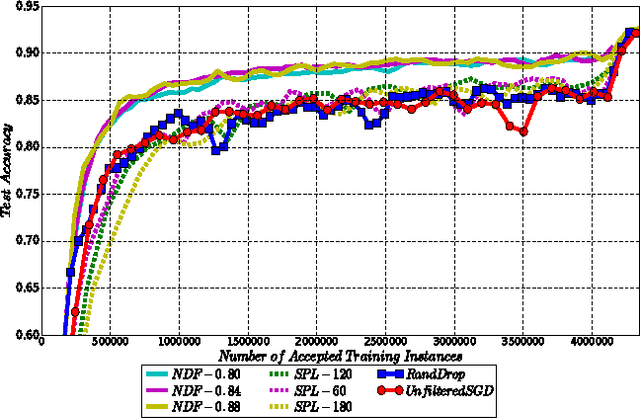
Machine learning is essentially the sciences of playing with data. An adaptive data selection strategy, enabling to dynamically choose different data at various training stages, can reach a more effective model in a more efficient way. In this paper, we propose a deep reinforcement learning framework, which we call \emph{\textbf{N}eural \textbf{D}ata \textbf{F}ilter} (\textbf{NDF}), to explore automatic and adaptive data selection in the training process. In particular, NDF takes advantage of a deep neural network to adaptively select and filter important data instances from a sequential stream of training data, such that the future accumulative reward (e.g., the convergence speed) is maximized. In contrast to previous studies in data selection that is mainly based on heuristic strategies, NDF is quite generic and thus can be widely suitable for many machine learning tasks. Taking neural network training with stochastic gradient descent (SGD) as an example, comprehensive experiments with respect to various neural network modeling (e.g., multi-layer perceptron networks, convolutional neural networks and recurrent neural networks) and several applications (e.g., image classification and text understanding) demonstrate that NDF powered SGD can achieve comparable accuracy with standard SGD process by using less data and fewer iterations.
Randomized Mechanisms for Selling Reserved Instances in Cloud
Nov 22, 2016Selling reserved instances (or virtual machines) is a basic service in cloud computing. In this paper, we consider a more flexible pricing model for instance reservation, in which a customer can propose the time length and number of resources of her request, while in today's industry, customers can only choose from several predefined reservation packages. Under this model, we design randomized mechanisms for customers coming online to optimize social welfare and providers' revenue. We first consider a simple case, where the requests from the customers do not vary too much in terms of both length and value density. We design a randomized mechanism that achieves a competitive ratio $\frac{1}{42}$ for both \emph{social welfare} and \emph{revenue}, which is a improvement as there is usually no revenue guarantee in previous works such as \cite{azar2015ec,wang2015selling}. This ratio can be improved up to $\frac{1}{11}$ when we impose a realistic constraint on the maximum number of resources used by each request. On the hardness side, we show an upper bound $\frac{1}{3}$ on competitive ratio for any randomized mechanism. We then extend our mechanism to the general case and achieve a competitive ratio $\frac{1}{42\log k\log T}$ for both social welfare and revenue, where $T$ is the ratio of the maximum request length to the minimum request length and $k$ is the ratio of the maximum request value density to the minimum request value density. This result outperforms the previous upper bound $\frac{1}{CkT}$ for deterministic mechanisms \cite{wang2015selling}. We also prove an upper bound $\frac{2}{\log 8kT}$ for any randomized mechanism. All the mechanisms we provide are in a greedy style. They are truthful and easy to be integrated into practical cloud systems.
A Communication-Efficient Parallel Algorithm for Decision Tree
Nov 04, 2016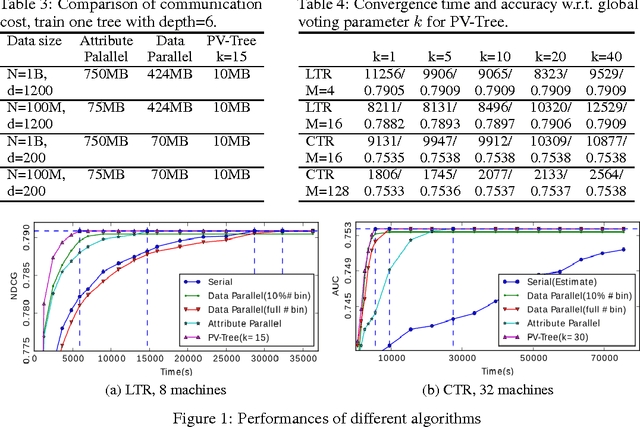

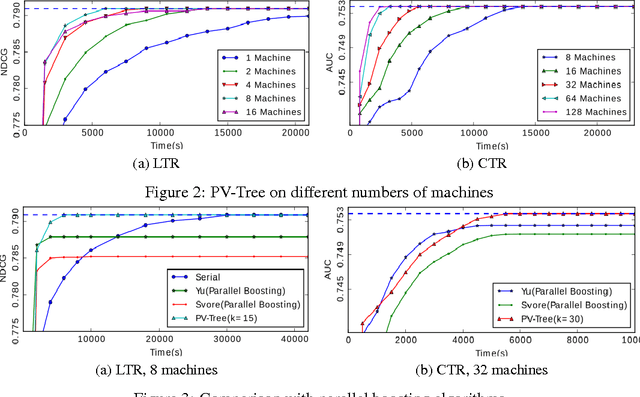
Decision tree (and its extensions such as Gradient Boosting Decision Trees and Random Forest) is a widely used machine learning algorithm, due to its practical effectiveness and model interpretability. With the emergence of big data, there is an increasing need to parallelize the training process of decision tree. However, most existing attempts along this line suffer from high communication costs. In this paper, we propose a new algorithm, called \emph{Parallel Voting Decision Tree (PV-Tree)}, to tackle this challenge. After partitioning the training data onto a number of (e.g., $M$) machines, this algorithm performs both local voting and global voting in each iteration. For local voting, the top-$k$ attributes are selected from each machine according to its local data. Then, globally top-$2k$ attributes are determined by a majority voting among these local candidates. Finally, the full-grained histograms of the globally top-$2k$ attributes are collected from local machines in order to identify the best (most informative) attribute and its split point. PV-Tree can achieve a very low communication cost (independent of the total number of attributes) and thus can scale out very well. Furthermore, theoretical analysis shows that this algorithm can learn a near optimal decision tree, since it can find the best attribute with a large probability. Our experiments on real-world datasets show that PV-Tree significantly outperforms the existing parallel decision tree algorithms in the trade-off between accuracy and efficiency.
Dual Learning for Machine Translation
Nov 01, 2016
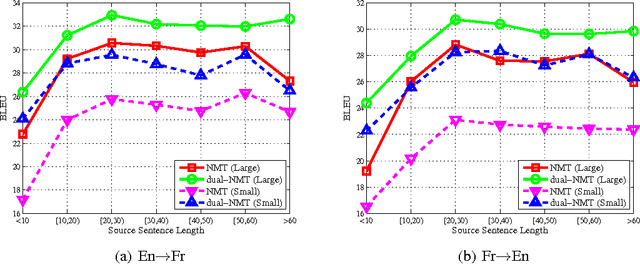

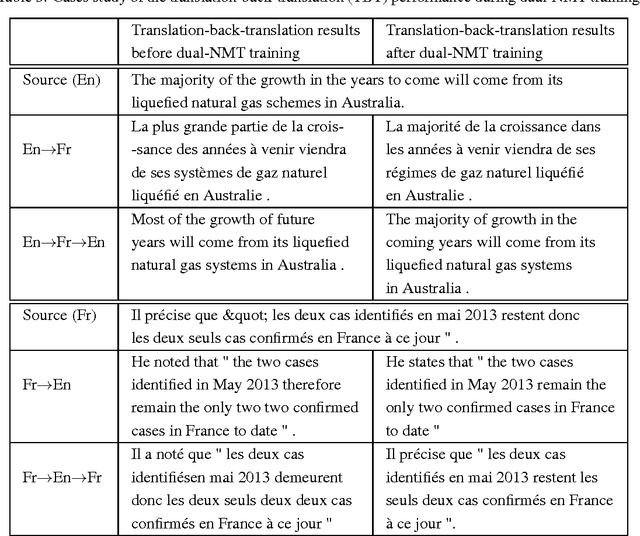
While neural machine translation (NMT) is making good progress in the past two years, tens of millions of bilingual sentence pairs are needed for its training. However, human labeling is very costly. To tackle this training data bottleneck, we develop a dual-learning mechanism, which can enable an NMT system to automatically learn from unlabeled data through a dual-learning game. This mechanism is inspired by the following observation: any machine translation task has a dual task, e.g., English-to-French translation (primal) versus French-to-English translation (dual); the primal and dual tasks can form a closed loop, and generate informative feedback signals to train the translation models, even if without the involvement of a human labeler. In the dual-learning mechanism, we use one agent to represent the model for the primal task and the other agent to represent the model for the dual task, then ask them to teach each other through a reinforcement learning process. Based on the feedback signals generated during this process (e.g., the language-model likelihood of the output of a model, and the reconstruction error of the original sentence after the primal and dual translations), we can iteratively update the two models until convergence (e.g., using the policy gradient methods). We call the corresponding approach to neural machine translation \emph{dual-NMT}. Experiments show that dual-NMT works very well on English$\leftrightarrow$French translation; especially, by learning from monolingual data (with 10% bilingual data for warm start), it achieves a comparable accuracy to NMT trained from the full bilingual data for the French-to-English translation task.
LightRNN: Memory and Computation-Efficient Recurrent Neural Networks
Oct 31, 2016



Recurrent neural networks (RNNs) have achieved state-of-the-art performances in many natural language processing tasks, such as language modeling and machine translation. However, when the vocabulary is large, the RNN model will become very big (e.g., possibly beyond the memory capacity of a GPU device) and its training will become very inefficient. In this work, we propose a novel technique to tackle this challenge. The key idea is to use 2-Component (2C) shared embedding for word representations. We allocate every word in the vocabulary into a table, each row of which is associated with a vector, and each column associated with another vector. Depending on its position in the table, a word is jointly represented by two components: a row vector and a column vector. Since the words in the same row share the row vector and the words in the same column share the column vector, we only need $2 \sqrt{|V|}$ vectors to represent a vocabulary of $|V|$ unique words, which are far less than the $|V|$ vectors required by existing approaches. Based on the 2-Component shared embedding, we design a new RNN algorithm and evaluate it using the language modeling task on several benchmark datasets. The results show that our algorithm significantly reduces the model size and speeds up the training process, without sacrifice of accuracy (it achieves similar, if not better, perplexity as compared to state-of-the-art language models). Remarkably, on the One-Billion-Word benchmark Dataset, our algorithm achieves comparable perplexity to previous language models, whilst reducing the model size by a factor of 40-100, and speeding up the training process by a factor of 2. We name our proposed algorithm \emph{LightRNN} to reflect its very small model size and very high training speed.