 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Neural Machine Translation
Sep 30, 2018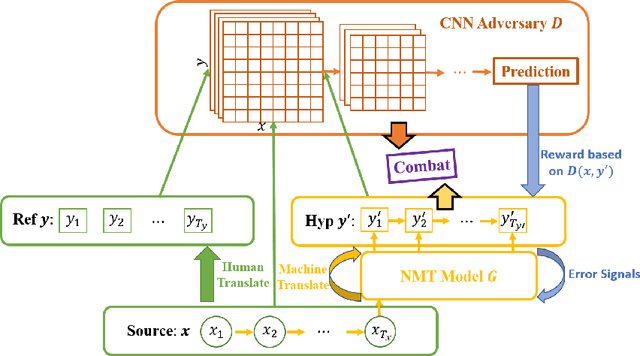
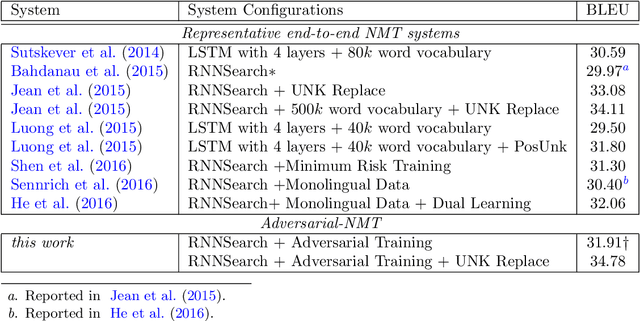
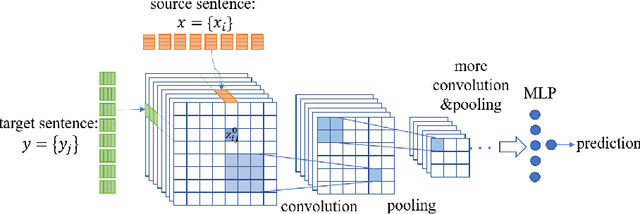
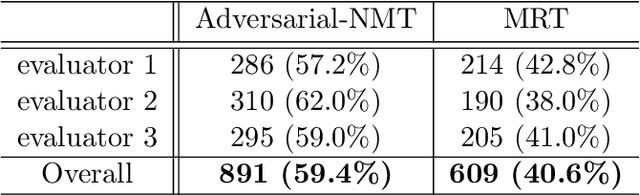
In this paper, we study a new learning paradigm for Neural Machine Translation (NMT). Instead of maximizing the likelihood of the human translation as in previous works, we minimize the distinction between human translation and the translation given by an NMT model. To achieve this goal, inspired by the recent success of generative adversarial networks (GANs), we employ an adversarial training architecture and name it as Adversarial-NMT. In Adversarial-NMT, the training of the NMT model is assisted by an adversary, which is an elaborately designed Convolutional Neural Network (CNN). The goal of the adversary is to differentiate the translation result generated by the NMT model from that by human. The goal of the NMT model is to produce high quality translations so as to cheat the adversary. A policy gradient method is leveraged to co-train the NMT model and the adversary. Experimental results on English$\rightarrow$French and German$\rightarrow$English translation tasks show that Adversarial-NMT can achieve significantly better translation quality than several strong baselines.
Finite Sample Analysis of the GTD Policy Evaluation Algorithms in Markov Setting
Sep 21, 2018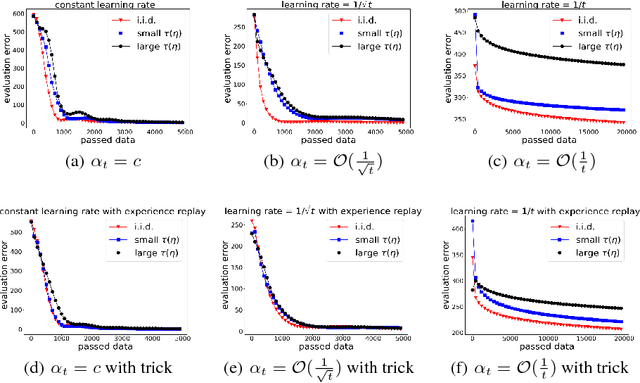
In reinforcement learning (RL) , one of the key components is policy evaluation, which aims to estimate the value function (i.e., expected long-term accumulated reward) of a policy. With a good policy evaluation method, the RL algorithms will estimate the value function more accurately and find a better policy. When the state space is large or continuous \emph{Gradient-based Temporal Difference(GTD)} policy evaluation algorithms with linear function approximation are widely used. Considering that the collection of the evaluation data is both time and reward consuming, a clear understanding of the finite sample performance of the policy evaluation algorithms is very important to reinforcement learning. Under the assumption that data are i.i.d. generated, previous work provided the finite sample analysis of the GTD algorithms with constant step size by converting them into convex-concave saddle point problems. However, it is well-known that, the data are generated from Markov processes rather than i.i.d. in RL problems.. In this paper, in the realistic Markov setting, we derive the finite sample bounds for the general convex-concave saddle point problems, and hence for the GTD algorithms. We have the following discussions based on our bounds. (1) With variants of step size, GTD algorithms converge. (2) The convergence rate is determined by the step size, with the mixing time of the Markov process as the coefficient. The faster the Markov processes mix, the faster the convergence. (3) We explain that the experience replay trick is effective by improving the mixing property of the Markov process. To the best of our knowledge, our analysis is the first to provide finite sample bounds for the GTD algorithms in Markov setting.
Target Transfer Q-Learning and Its Convergence Analysis
Sep 21, 2018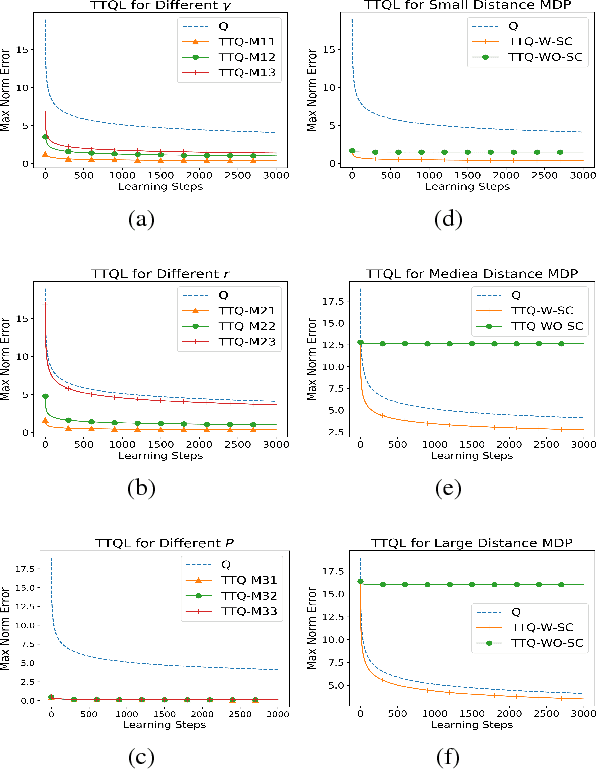
Q-learning is one of the most popular methods in Reinforcement Learning (RL). Transfer Learning aims to utilize the learned knowledge from source tasks to help new tasks to improve the sample complexity of the new tasks. Considering that data collection in RL is both more time and cost consuming and Q-learning converges slowly comparing to supervised learning, different kinds of transfer RL algorithms are designed. However, most of them are heuristic with no theoretical guarantee of the convergence rate. Therefore, it is important for us to clearly understand when and how will transfer learning help RL method and provide the theoretical guarantee for the improvement of the sample complexity. In this paper, we propose to transfer the Q-function learned in the source task to the target of the Q-learning in the new task when certain safe conditions are satisfied. We call this new transfer Q-learning method target transfer Q-Learning. The safe conditions are necessary to avoid the harm to the new tasks and thus ensure the convergence of the algorithm. We study the convergence rate of the target transfer Q-learning. We prove that if the two tasks are similar with respect to the MDPs, the optimal Q-functions in the source and new RL tasks are similar which means the error of the transferred target Q-function in new MDP is small. Also, the convergence rate analysis shows that the target transfer Q-Learning will converge faster than Q-learning if the error of the transferred target Q-function is smaller than the current Q-function in the new task. Based on our theoretical results, we design the safe condition as the Bellman error of the transferred target Q-function is less than the current Q-function. Our experiments are consistent with our theoretical founding and verified the effectiveness of our proposed target transfer Q-learning method.
Capacity Control of ReLU Neural Networks by Basis-path Norm
Sep 19, 2018
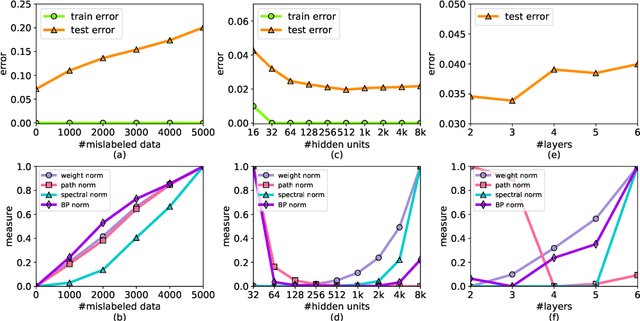
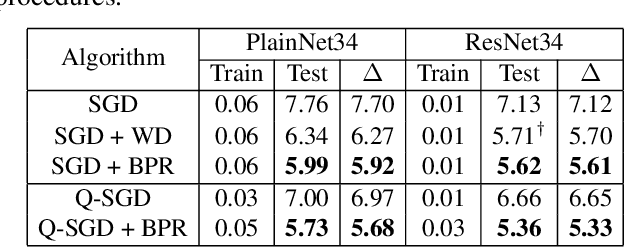
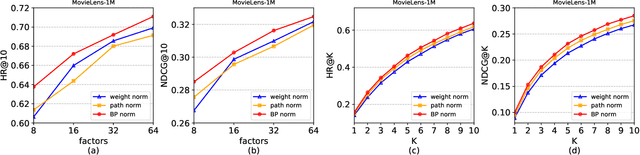
Recently, path norm was proposed as a new capacity measure for neural networks with Rectified Linear Unit (ReLU) activation function, which takes the rescaling-invariant property of ReLU into account. It has been shown that the generalization error bound in terms of the path norm explains the empirical generalization behaviors of the ReLU neural networks better than that of other capacity measures. Moreover, optimization algorithms which take path norm as the regularization term to the loss function, like Path-SGD, have been shown to achieve better generalization performance. However, the path norm counts the values of all paths, and hence the capacity measure based on path norm could be improperly influenced by the dependency among different paths. It is also known that each path of a ReLU network can be represented by a small group of linearly independent basis paths with multiplication and division operation, which indicates that the generalization behavior of the network only depends on only a few basis paths. Motivated by this, we propose a new norm \emph{Basis-path Norm} based on a group of linearly independent paths to measure the capacity of neural networks more accurately. We establish a generalization error bound based on this basis path norm, and show it explains the generalization behaviors of ReLU networks more accurately than previous capacity measures via extensive experiments. In addition, we develop optimization algorithms which minimize the empirical risk regularized by the basis-path norm. Our experiments on benchmark datasets demonstrate that the proposed regularization method achieves clearly better performance on the test set than the previous regularization approaches.
FRAGE: Frequency-Agnostic Word Representation
Sep 18, 2018
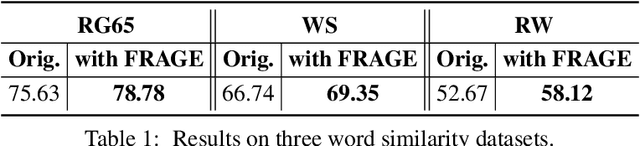
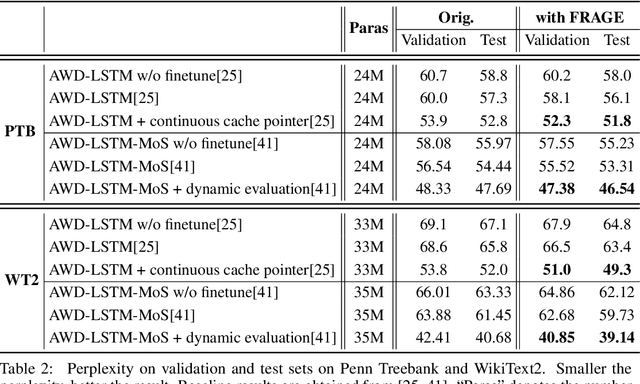
Continuous word representation (aka word embedding) is a basic building block in many neural network-based models used in natural language processing tasks. Although it is widely accepted that words with similar semantics should be close to each other in the embedding space, we find that word embeddings learned in several tasks are biased towards word frequency: the embeddings of high-frequency and low-frequency words lie in different subregions of the embedding space, and the embedding of a rare word and a popular word can be far from each other even if they are semantically similar. This makes learned word embeddings ineffective, especially for rare words, and consequently limits the performance of these neural network models. In this paper, we develop a neat, simple yet effective way to learn \emph{FRequency-AGnostic word Embedding} (FRAGE) using adversarial training. We conducted comprehensive studies on ten datasets across four natural language processing tasks, including word similarity, language modeling, machine translation and text classification. Results show that with FRAGE, we achieve higher performance than the baselines in all tasks.
Beyond Error Propagation in Neural Machine Translation: Characteristics of Language Also Matter
Sep 11, 2018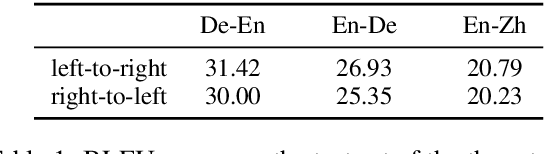
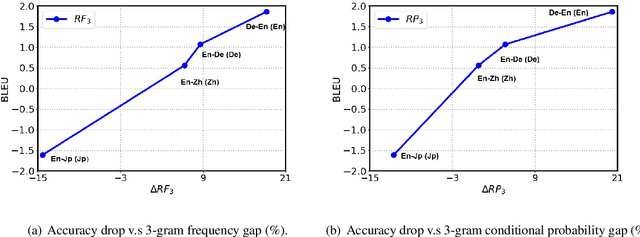
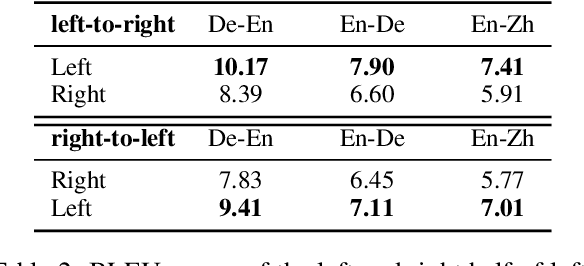
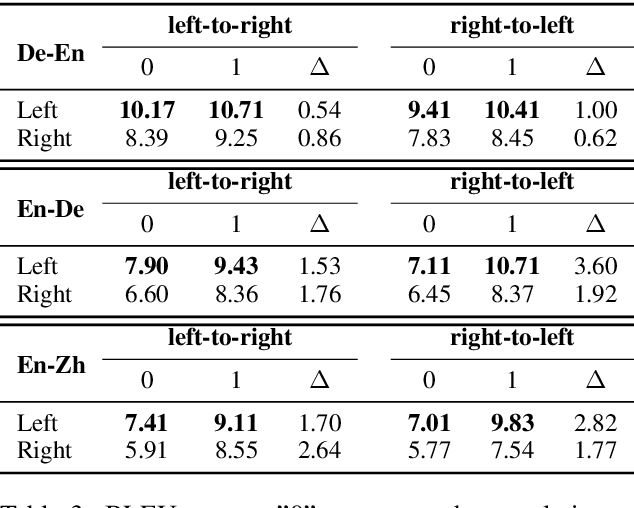
Neural machine translation usually adopts autoregressive models and suffers from exposure bias as well as the consequent error propagation problem. Many previous works have discussed the relationship between error propagation and the \emph{accuracy drop} (i.e., the left part of the translated sentence is often better than its right part in left-to-right decoding models) problem. In this paper, we conduct a series of analyses to deeply understand this problem and get several interesting findings. (1) The role of error propagation on accuracy drop is overstated in the literature, although it indeed contributes to the accuracy drop problem. (2) Characteristics of a language play a more important role in causing the accuracy drop: the left part of the translation result in a right-branching language (e.g., English) is more likely to be more accurate than its right part, while the right part is more accurate for a left-branching language (e.g., Japanese). Our discoveries are confirmed on different model structures including Transformer and RNN, and in other sequence generation tasks such as text summarization.
A Study of Reinforcement Learning for Neural Machine Translation
Aug 27, 2018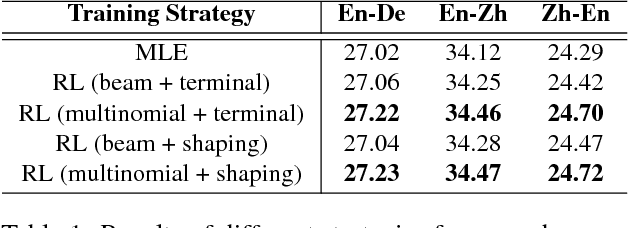
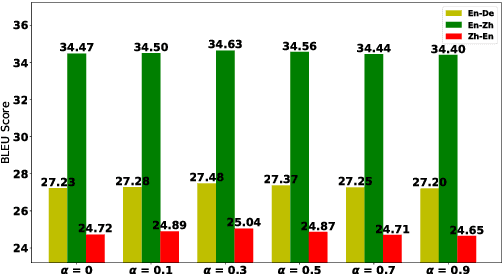

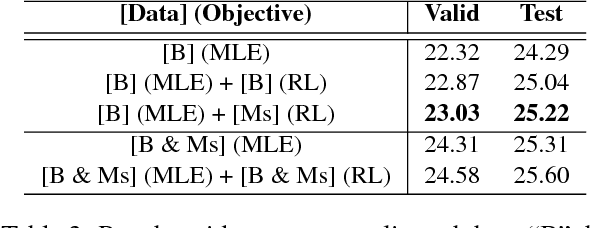
Recent studies have shown that reinforcement learning (RL) is an effective approach for improving the performance of neural machine translation (NMT) system. However, due to its instability, successfully RL training is challenging, especially in real-world systems where deep models and large datasets are leveraged. In this paper, taking several large-scale translation tasks as testbeds, we conduct a systematic study on how to train better NMT models using reinforcement learning. We provide a comprehensive comparison of several important factors (e.g., baseline reward, reward shaping) in RL training. Furthermore, to fill in the gap that it remains unclear whether RL is still beneficial when monolingual data is used, we propose a new method to leverage RL to further boost the performance of NMT systems trained with source/target monolingual data. By integrating all our findings, we obtain competitive results on WMT14 English- German, WMT17 English-Chinese, and WMT17 Chinese-English translation tasks, especially setting a state-of-the-art performance on WMT17 Chinese-English translation task.
Large-Scale Low-Rank Matrix Learning with Nonconvex Regularizers
Jul 23, 2018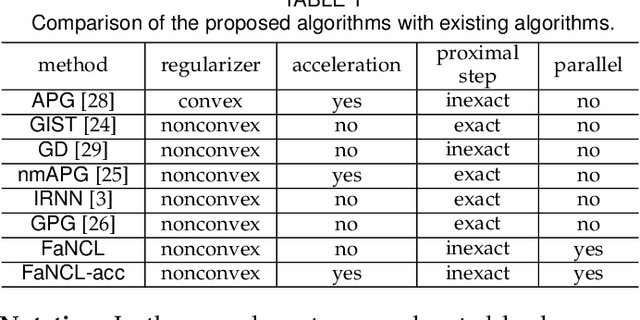
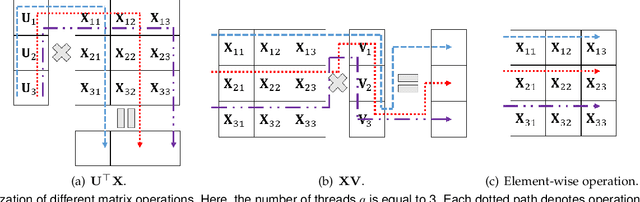

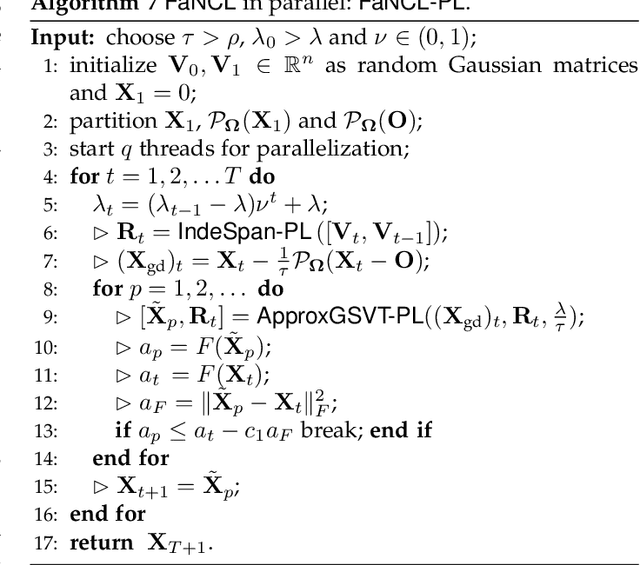
Low-rank modeling has many important applications in computer vision and machine learning. While the matrix rank is often approximated by the convex nuclear norm, the use of nonconvex low-rank regularizers has demonstrated better empirical performance. However, the resulting optimization problem is much more challenging. Recent state-of-the-art requires an expensive full SVD in each iteration. In this paper, we show that for many commonly-used nonconvex low-rank regularizers, a cutoff can be derived to automatically threshold the singular values obtained from the proximal operator. This allows such operator being efficiently approximated by power method. Based on it, we develop a proximal gradient algorithm (and its accelerated variant) with inexact proximal splitting and prove that a convergence rate of O(1/T) where T is the number of iterations is guaranteed. Furthermore, we show the proposed algorithm can be well parallelized, which achieves nearly linear speedup w.r.t the number of threads. Extensive experiments are performed on matrix completion and robust principal component analysis, which shows a significant speedup over the state-of-the-art. Moreover, the matrix solution obtained is more accurate and has a lower rank than that of the nuclear norm regularizer.
Double Path Networks for Sequence to Sequence Learning
Jul 04, 2018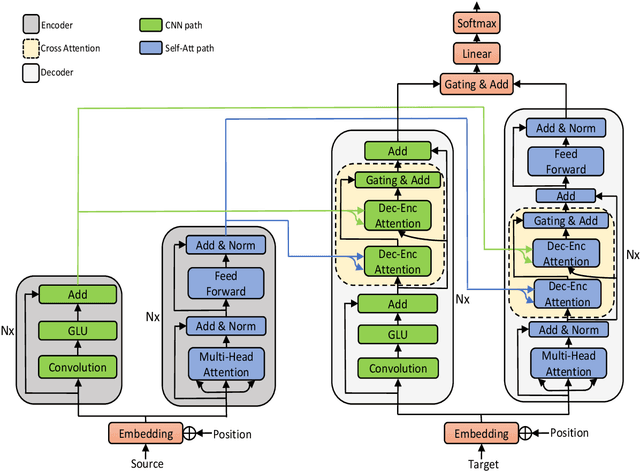
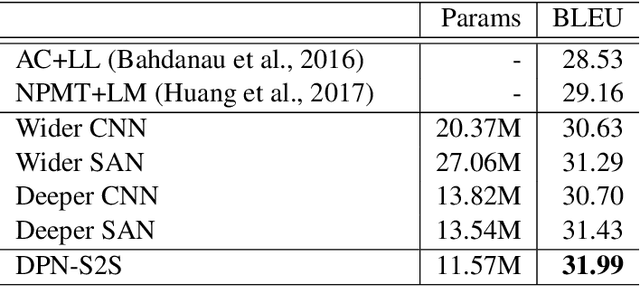
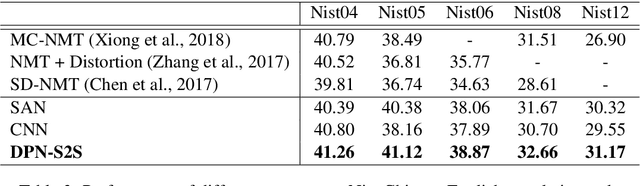

Encoder-decoder based Sequence to Sequence learning (S2S) has made remarkable progress in recent years. Different network architectures have been used in the encoder/decoder. Among them, Convolutional Neural Networks (CNN) and Self Attention Networks (SAN) are the prominent ones. The two architectures achieve similar performances but use very different ways to encode and decode context: CNN use convolutional layers to focus on the local connectivity of the sequence, while SAN uses self-attention layers to focus on global semantics. In this work we propose Double Path Networks for Sequence to Sequence learning (DPN-S2S), which leverage the advantages of both models by using double path information fusion. During the encoding step, we develop a double path architecture to maintain the information coming from different paths with convolutional layers and self-attention layers separately. To effectively use the encoded context, we develop a cross attention module with gating and use it to automatically pick up the information needed during the decoding step. By deeply integrating the two paths with cross attention, both types of information are combined and well exploited. Experiments show that our proposed method can significantly improve the performance of sequence to sequence learning over state-of-the-art systems.
Dense Information Flow for Neural Machine Translation
Jul 02, 2018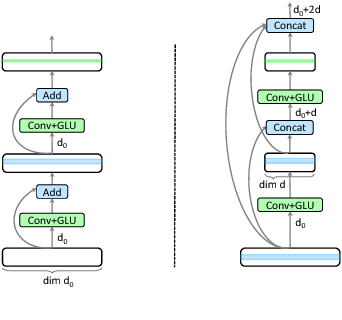
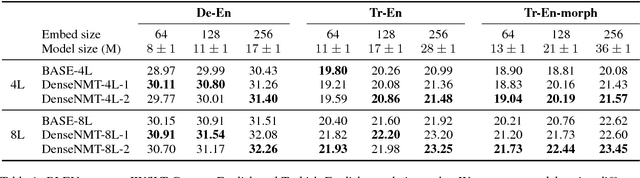
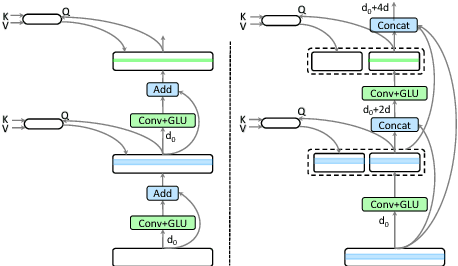
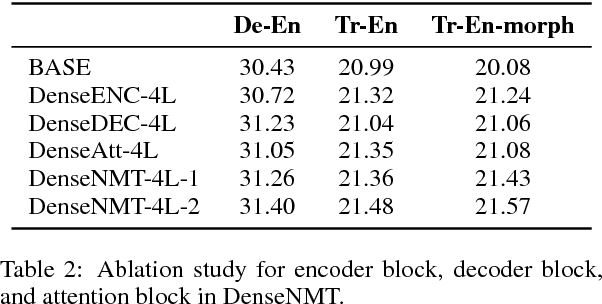
Recently, neural machine translation has achieved remarkable progress by introducing well-designed deep neural networks into its encoder-decoder framework. From the optimization perspective, residual connections are adopted to improve learning performance for both encoder and decoder in most of these deep architectures, and advanced attention connections are applied as well. Inspired by the success of the DenseNet model in computer vision problems, in this paper, we propose a densely connected NMT architecture (DenseNMT) that is able to train more efficiently for NMT. The proposed DenseNMT not only allows dense connection in creating new features for both encoder and decoder, but also uses the dense attention structure to improve attention quality. Our experiments on multiple datasets show that DenseNMT structure is more competitive and efficient.