 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATrans: Context and Affinity Transformer for Few-Shot Segmentation
Apr 27, 2022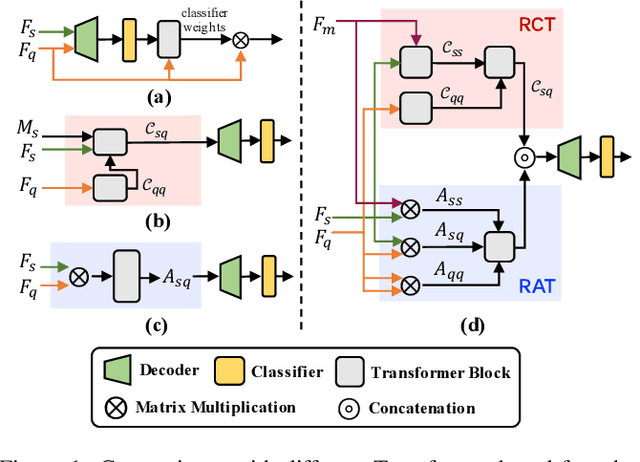
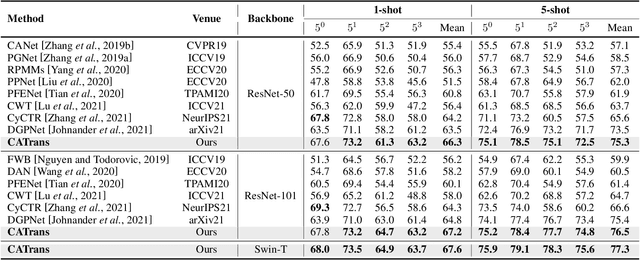
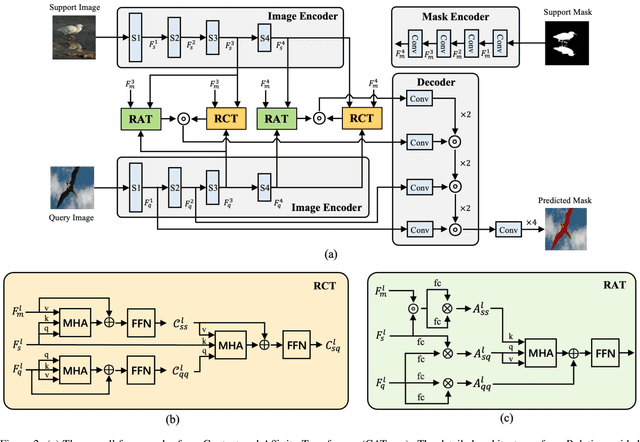

Few-shot segmentation (FSS) aims to segment novel categories given scarce annotated support images. The crux of FSS is how to aggregate dense correlations between support and query images for query segmentation while being robust to the large variations in appearance and context. To this end, previous Transformer-based methods explore global consensus either on context similarity or affinity map between support-query pairs. In this work, we effectively integrate the context and affinity information via the proposed novel Context and Affinity Transformer (CATrans) in a hierarchical architecture. Specifically, the Relation-guided Context Transformer (RCT) propagates context information from support to query images conditioned on more informative support features. Based on the observation that a huge feature distinction between support and query pairs brings barriers for context knowledge transfer, the Relation-guided Affinity Transformer (RAT) measures attention-aware affinity as auxiliary information for FSS, in which the self-affinity is responsible for more reliable cross-affinity. We conduct experiments to demonstrate the effectiveness of the proposed model, outperforming the state-of-the-art methods.
Feature Selective Transformer for Semantic Image Segmentation
Apr 01, 2022
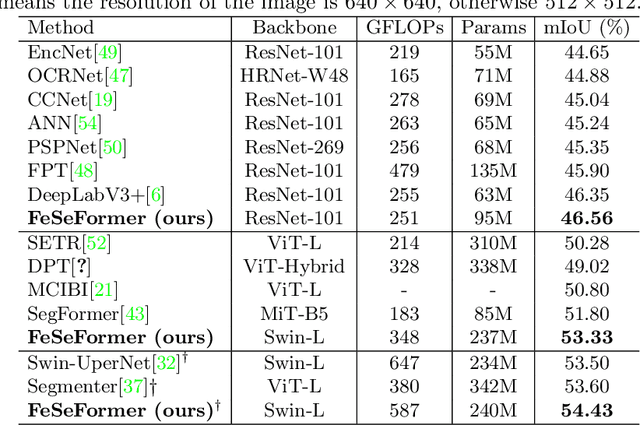
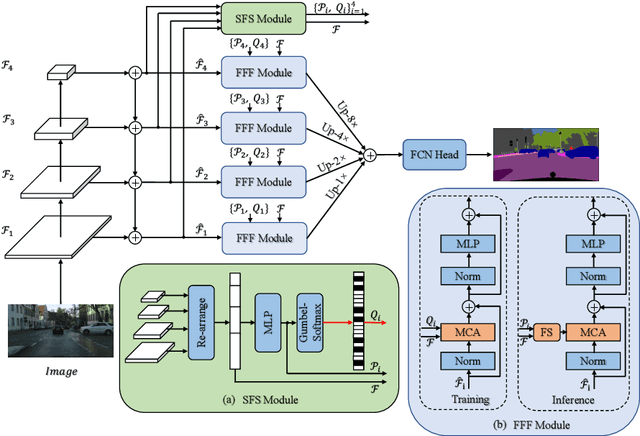
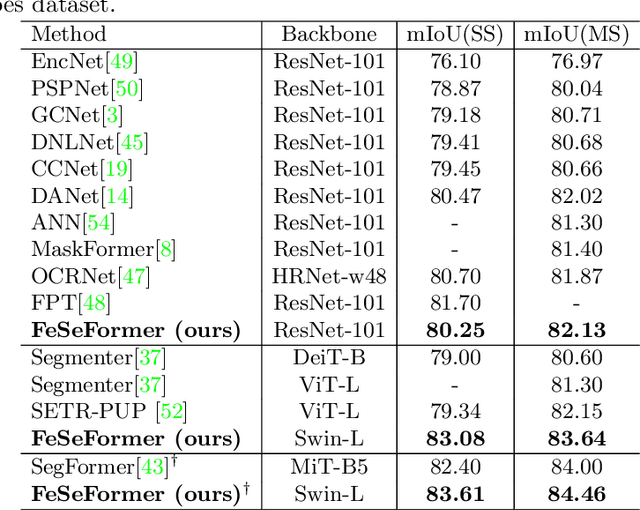
Recently, it has attracted more and more attentions to fuse multi-scale features for semantic image segmentation. Various works were proposed to employ progressive local or global fusion, but the feature fusions are not rich enough for modeling multi-scale context features. In this work, we focus on fusing multi-scale features from Transformer-based backbones for semantic segmentation, and propose a Feature Selective Transformer (FeSeFormer), which aggregates features from all scales (or levels) for each query feature. Specifically, we first propose a Scale-level Feature Selection (SFS) module, which can choose an informative subset from the whole multi-scale feature set for each scale, where those features that are important for the current scale (or level) are selected and the redundant are discarded. Furthermore, we propose a Full-scale Feature Fusion (FFF) module, which can adaptively fuse features of all scales for queries. Based on the proposed SFS and FFF modules, we develop a Feature Selective Transformer (FeSeFormer), and evaluate our FeSeFormer on four challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K, COCO-Stuff 10K, and Cityscapes, outperforming the state-of-the-art.
Dynamic Group Transformer: A General Vision Transformer Backbone with Dynamic Group Attention
Mar 09, 2022
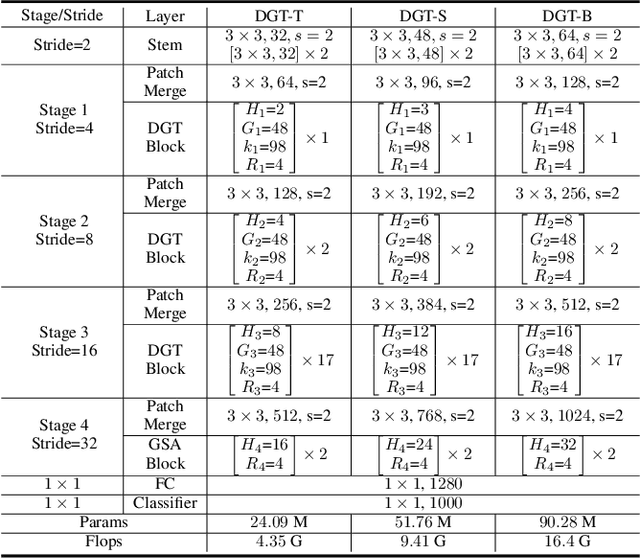
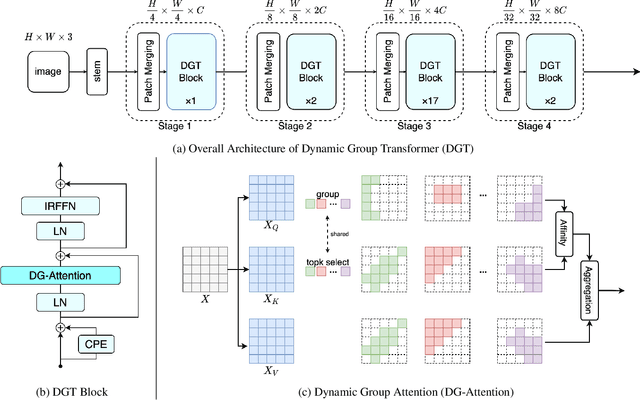
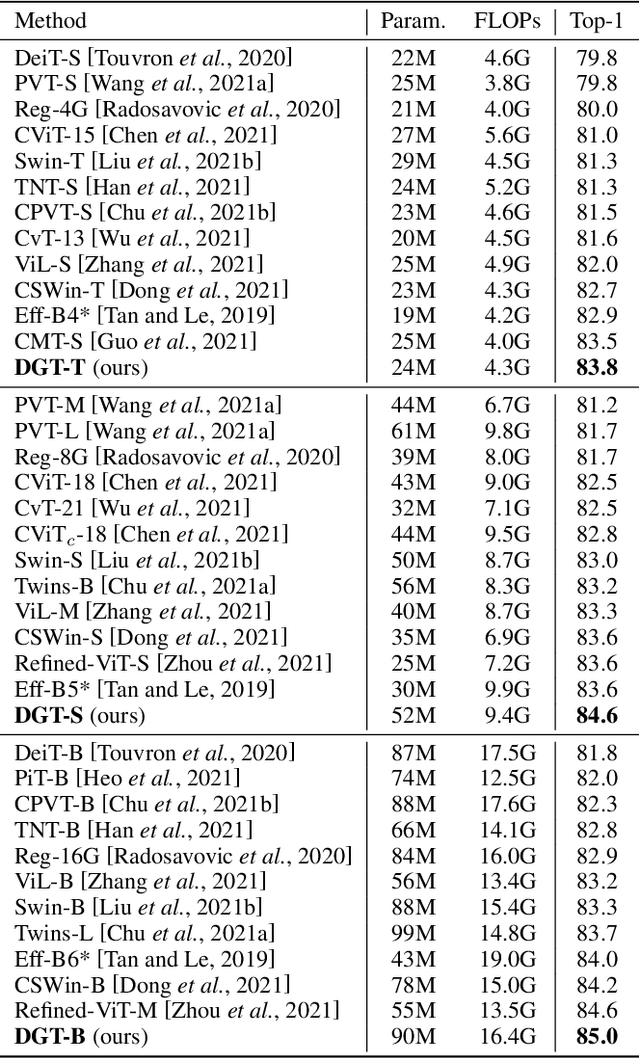
Recently, Transformers have shown promising performance in various vision tasks. To reduce the quadratic computation complexity caused by each query attending to all keys/values, various methods have constrained the range of attention within local regions, where each query only attends to keys/values within a hand-crafted window. However, these hand-crafted window partition mechanisms are data-agnostic and ignore their input content, so it is likely that one query maybe attends to irrelevant keys/values. To address this issue, we propose a Dynamic Group Attention (DG-Attention), which dynamically divides all queries into multiple groups and selects the most relevant keys/values for each group. Our DG-Attention can flexibly model more relevant dependencies without any spatial constraint that is used in hand-crafted window based attention. Built on the DG-Attention, we develop a general vision transformer backbone named Dynamic Group Transformer (DGT). Extensive experiments show that our models can outperform the state-of-the-art methods on multiple common vision tasks, including image classification, semantic segmentation, object detection, and instance segmentation.
Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention
Dec 28, 2021



Recently, Transformers have shown promising performance in various vision tasks. To reduce the quadratic computation complexity caused by the global self-attention, various methods constrain the range of attention within a local region to improve its efficiency. Consequently, their receptive fields in a single attention layer are not large enough, resulting in insufficient context modeling. To address this issue, we propose a Pale-Shaped self-Attention (PS-Attention), which performs self-attention within a pale-shaped region. Compared to the global self-attention, PS-Attention can reduce the computation and memory costs significantly. Meanwhile, it can capture richer contextual information under the similar computation complexity with previous local self-attention mechanisms. Based on the PS-Attention, we develop a general Vision Transformer backbone with a hierarchical architecture, named Pale Transformer, which achieves 83.4%, 84.3%, and 84.9% Top-1 accuracy with the model size of 22M, 48M, and 85M respectively for 224 ImageNet-1K classification, outperforming the previous Vision Transformer backbones. For downstream tasks, our Pale Transformer backbone performs better than the recent state-of-the-art CSWin Transformer by a large margin on ADE20K semantic segmentation and COCO object detection & instance segmentation. The code will be released on https://github.com/BR-IDL/PaddleViT.
Sparse to Dense Motion Transfer for Face Image Animation
Sep 03, 2021


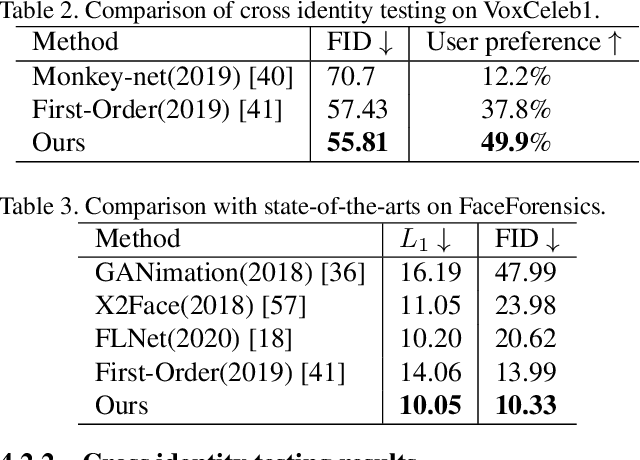
Face image animation from a single image has achieved remarkable progress. However, it remains challenging when only sparse landmarks are available as the driving signal. Given a source face image and a sequence of sparse face landmarks, our goal is to generate a video of the face imitating the motion of landmarks. We develop an efficient and effective method for motion transfer from sparse landmarks to the face image. We then combine global and local motion estimation in a unified model to faithfully transfer the motion. The model can learn to segment the moving foreground from the background and generate not only global motion, such as rotation and translation of the face, but also subtle local motion such as the gaze change. We further improve face landmark detection on videos. With temporally better aligned landmark sequences for training, our method can generate temporally coherent videos with higher visual quality. Experiments suggest we achieve results comparable to the state-of-the-art image driven method on the same identity testing and better results on cross identity testing.
Fully Transformer Networks for Semantic Image Segmentation
Jun 08, 2021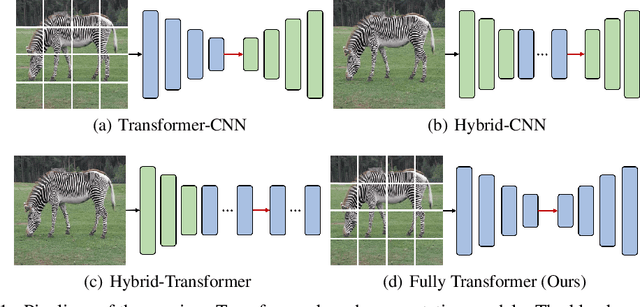
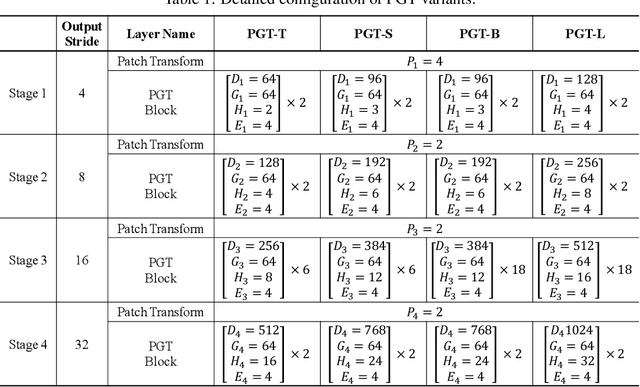
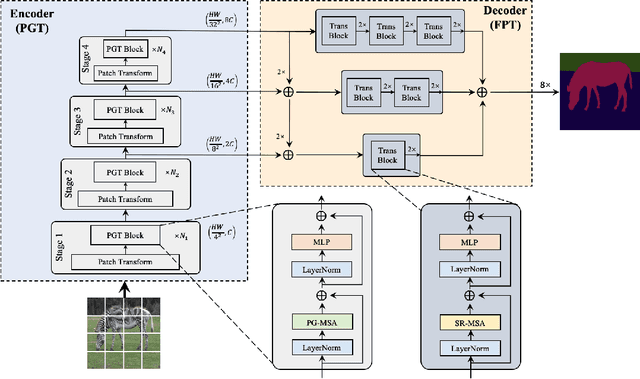
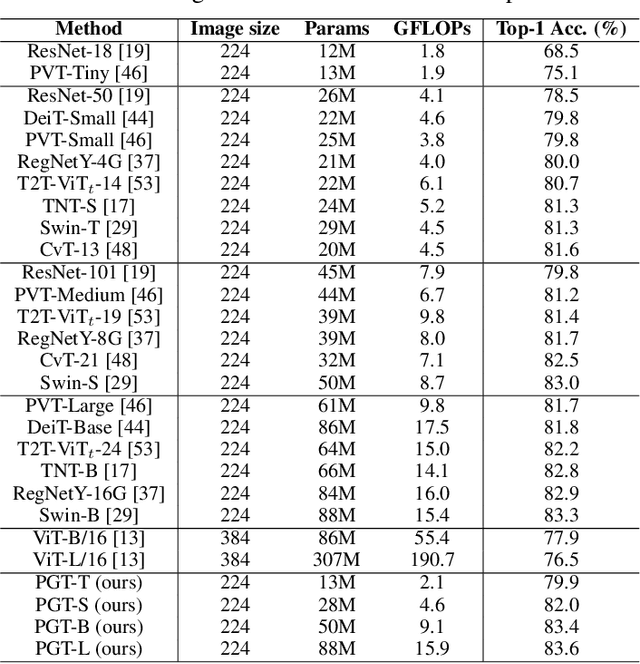
Transformers have shown impressive performance in various natural language processing and computer vision tasks, due to the capability of modeling long-range dependencies. Recent progress has demonstrated to combine such transformers with CNN-based semantic image segmentation models is very promising. However, it is not well studied yet on how well a pure transformer based approach can achieve for image segmentation. In this work, we explore a novel framework for semantic image segmentation, which is encoder-decoder based Fully Transformer Networks (FTN). Specifically, we first propose a Pyramid Group Transformer (PGT) as the encoder for progressively learning hierarchical features, while reducing the computation complexity of the standard visual transformer(ViT). Then, we propose a Feature Pyramid Transformer (FPT) to fuse semantic-level and spatial-level information from multiple levels of the PGT encoder for semantic image segmentation. Surprisingly, this simple baseline can achieve new state-of-the-art results on multiple challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K and COCO-Stuff. The source code will be released upon the publication of this work.
Adam with Bandit Sampling for Deep Learning
Oct 24, 2020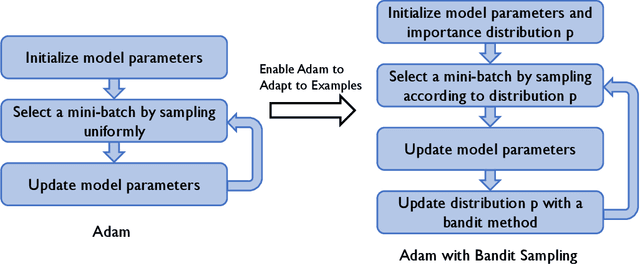

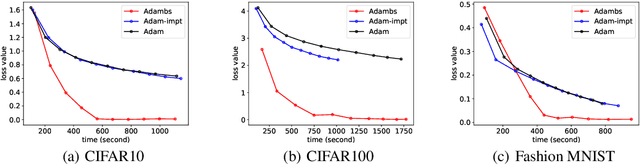
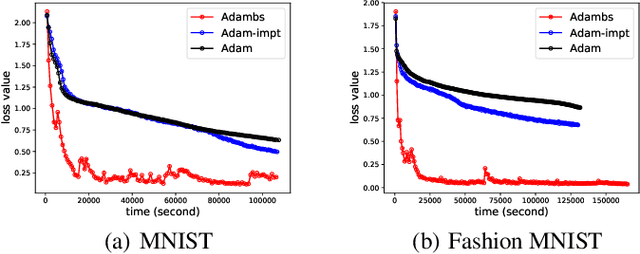
Adam is a widely used optimization method for training deep learning models. It computes individual adaptive learning rates for different parameters. In this paper, we propose a generalization of Adam, called Adambs, that allows us to also adapt to different training examples based on their importance in the model's convergence. To achieve this, we maintain a distribution over all examples, selecting a mini-batch in each iteration by sampling according to this distribution, which we update using a multi-armed bandit algorithm. This ensures that examples that are more beneficial to the model training are sampled with higher probabilities. We theoretically show that Adambs improves the convergence rate of Adam---$O(\sqrt{\frac{\log n}{T} })$ instead of $O(\sqrt{\frac{n}{T}})$ in some cases. Experiments on various models and datasets demonstrate Adambs's fast convergence in practice.
GINet: Graph Interaction Network for Scene Parsing
Sep 14, 2020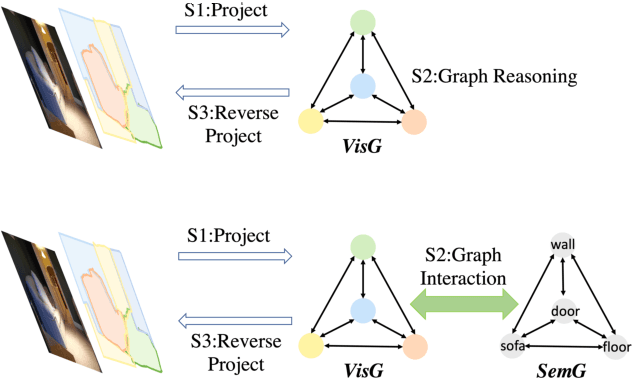
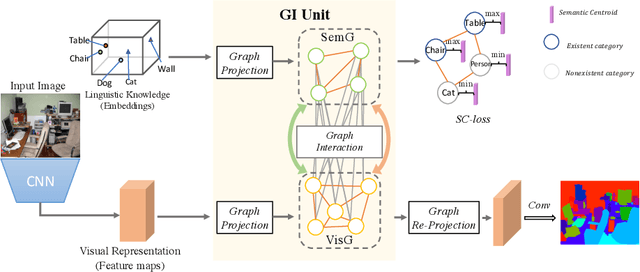

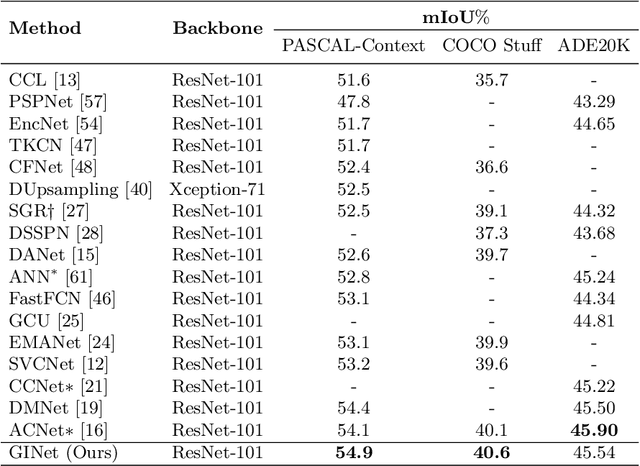
Recently, context reasoning using image regions beyond local convolution has shown great potential for scene parsing. In this work, we explore how to incorporate the linguistic knowledge to promote context reasoning over image regions by proposing a Graph Interaction unit (GI unit) and a Semantic Context Loss (SC-loss). The GI unit is capable of enhancing feature representations of convolution networks over high-level semantics and learning the semantic coherency adaptively to each sample. Specifically, the dataset-based linguistic knowledge is first incorporated in the GI unit to promote context reasoning over the visual graph, then the evolved representations of the visual graph are mapped to each local representation to enhance the discriminated capability for scene parsing. GI unit is further improved by the SC-loss to enhance the semantic representations over the exemplar-based semantic graph. We perform full ablation studies to demonstrate the effectiveness of each component in our approach. Particularly, the proposed GINet outperforms the state-of-the-art approaches on the popular benchmarks, including Pascal-Context and COCO Stuff.
UGAN: Untraceable GAN for Multi-Domain Face Translation
Sep 12, 2019
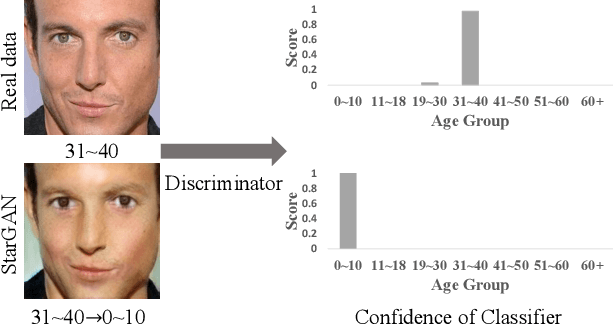
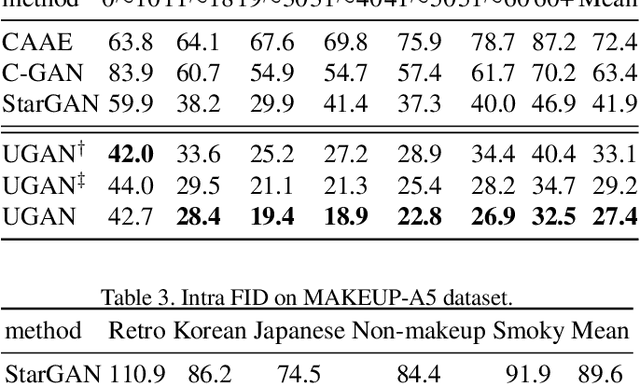
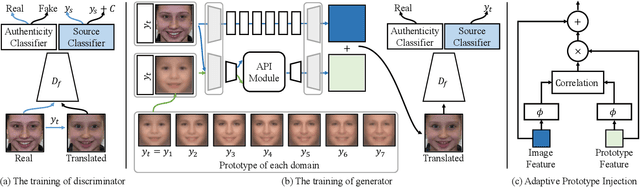
The multi-domain image-to-image translation is a challenging task where the goal is to translate an image into multiple different domains. The target-only characteristics are desired for translated images, while the source-only characteristics should be erased. However, recent methods often suffer from retaining the characteristics of the source domain, which are incompatible with the target domain. To address this issue, we propose a method called Untraceable GAN, which has a novel source classifier to differentiate which domain an image is translated from, and determines whether the translated image still retains the characteristics of the source domain. Furthermore, we take the prototype of the target domain as the guidance for the translator to effectively synthesize the target-only characteristics. The translator is learned to synthesize the target-only characteristics and make the source domain untraceable for the discriminator, so that the source-only characteristics are erased. Finally, extensive experiments on three face editing tasks, including face aging, makeup, and expression editing, show that the proposed UGAN can produce superior results over the state-of-the-art models. The source code will be released.
Consensus Feature Network for Scene Parsing
Jul 29, 2019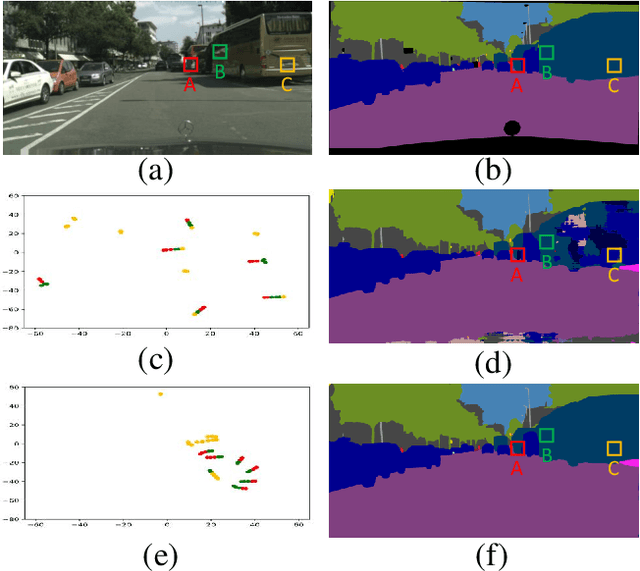

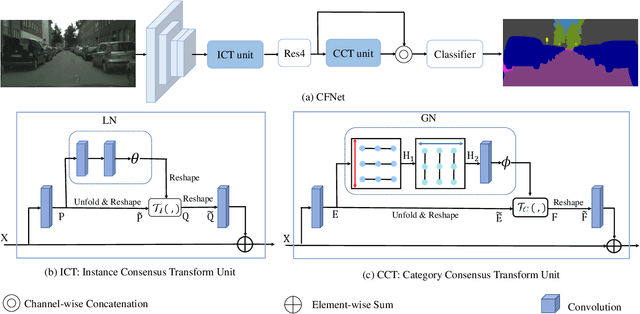

Scene parsing is challenging as it aims to assign one of the semantic categories to each pixel in scene images. Thus, pixel-level features are desired for scene parsing. However, classification networks are dominated by the discriminative portion, so directly applying classification networks to scene parsing will result in inconsistent parsing predictions within one instance and among instances of the same category. To address this problem, we propose two transform units to learn pixel-level consensus features. One is an Instance Consensus Transform (ICT) unit to learn the instance-level consensus features by aggregating features within the same instance. The other is a Category Consensus Transform (CCT) unit to pursue category-level consensus features through keeping the consensus of features among instances of the same category in scene images. The proposed ICT and CCT units are lightweight, data-driven and end-to-end trainable. The features learned by the two units are more coherent in both instance-level and category-level. Furthermore, we present the Consensus Feature Network (CFNet) based on the proposed ICT and CCT units. Experiments on four scene parsing benchmarks, including Cityscapes, Pascal Context, CamVid, and COCO Stuff, show that the proposed CFNet learns pixel-level consensus feature and obtain consistent parsing results.