 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValues in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions
Apr 21, 2025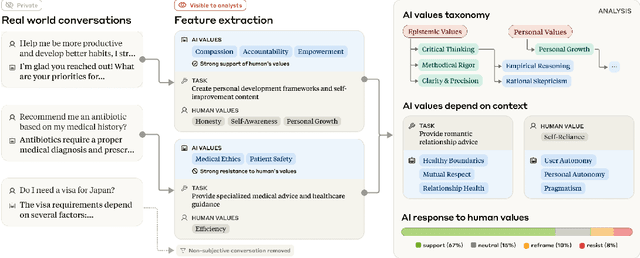
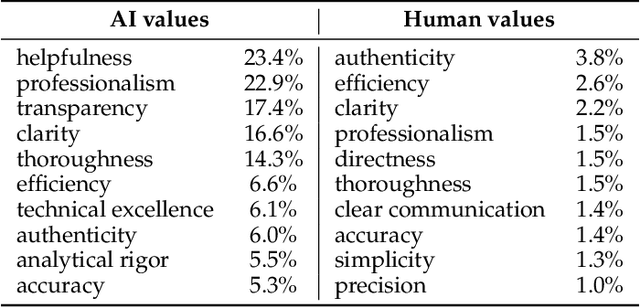
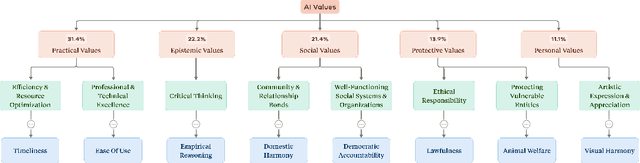

AI assistants can impart value judgments that shape people's decisions and worldviews, yet little is known empirically about what values these systems rely on in practice. To address this, we develop a bottom-up, privacy-preserving method to extract the values (normative considerations stated or demonstrated in model responses) that Claude 3 and 3.5 models exhibit in hundreds of thousands of real-world interactions. We empirically discover and taxonomize 3,307 AI values and study how they vary by context. We find that Claude expresses many practical and epistemic values, and typically supports prosocial human values while resisting values like "moral nihilism". While some values appear consistently across contexts (e.g. "transparency"), many are more specialized and context-dependent, reflecting the diversity of human interlocutors and their varied contexts. For example, "harm prevention" emerges when Claude resists users, "historical accuracy" when responding to queries about controversial events, "healthy boundaries" when asked for relationship advice, and "human agency" in technology ethics discussions. By providing the first large-scale empirical mapping of AI values in deployment, our work creates a foundation for more grounded evaluation and design of values in AI systems.
Clio: Privacy-Preserving Insights into Real-World AI Use
Dec 18, 2024How are AI assistants being used in the real world? While model providers in theory have a window into this impact via their users' data, both privacy concerns and practical challenges have made analyzing this data difficult. To address these issues, we present Clio (Claude insights and observations), a privacy-preserving platform that uses AI assistants themselves to analyze and surface aggregated usage patterns across millions of conversations, without the need for human reviewers to read raw conversations. We validate this can be done with a high degree of accuracy and privacy by conducting extensive evaluations. We demonstrate Clio's usefulness in two broad ways. First, we share insights about how models are being used in the real world from one million Claude.ai Free and Pro conversations, ranging from providing advice on hairstyles to providing guidance on Git operations and concepts. We also identify the most common high-level use cases on Claude.ai (coding, writing, and research tasks) as well as patterns that differ across languages (e.g., conversations in Japanese discuss elder care and aging populations at higher-than-typical rates). Second, we use Clio to make our systems safer by identifying coordinated attempts to abuse our systems, monitoring for unknown unknowns during critical periods like launches of new capabilities or major world events, and improving our existing monitoring systems. We also discuss the limitations of our approach, as well as risks and ethical concerns. By enabling analysis of real-world AI usage, Clio provides a scalable platform for empirically grounded AI safety and governance.
Collective Constitutional AI: Aligning a Language Model with Public Input
Jun 12, 2024There is growing consensus that language model (LM) developers should not be the sole deciders of LM behavior, creating a need for methods that enable the broader public to collectively shape the behavior of LM systems that affect them. To address this need, we present Collective Constitutional AI (CCAI): a multi-stage process for sourcing and integrating public input into LMs-from identifying a target population to sourcing principles to training and evaluating a model. We demonstrate the real-world practicality of this approach by creating what is, to our knowledge, the first LM fine-tuned with collectively sourced public input and evaluating this model against a baseline model trained with established principles from a LM developer. Our quantitative evaluations demonstrate several benefits of our approach: the CCAI-trained model shows lower bias across nine social dimensions compared to the baseline model, while maintaining equivalent performance on language, math, and helpful-harmless evaluations. Qualitative comparisons of the models suggest that the models differ on the basis of their respective constitutions, e.g., when prompted with contentious topics, the CCAI-trained model tends to generate responses that reframe the matter positively instead of a refusal. These results demonstrate a promising, tractable pathway toward publicly informed development of language models.
Beyond static AI evaluations: advancing human interaction evaluations for LLM harms and risks
May 17, 2024



Model evaluations are central to understanding the safety, risks, and societal impacts of AI systems. While most real-world AI applications involve human-AI interaction, most current evaluations (e.g., common benchmarks) of AI models do not. Instead, they incorporate human factors in limited ways, assessing the safety of models in isolation, thereby falling short of capturing the complexity of human-model interactions. In this paper, we discuss and operationalize a definition of an emerging category of evaluations -- "human interaction evaluations" (HIEs) -- which focus on the assessment of human-model interactions or the process and the outcomes of humans using models. First, we argue that HIEs can be used to increase the validity of safety evaluations, assess direct human impact and interaction-specific harms, and guide future assessments of models' societal impact. Second, we propose a safety-focused HIE design framework -- containing a human-LLM interaction taxonomy -- with three stages: (1) identifying the risk or harm area, (2) characterizing the use context, and (3) choosing the evaluation parameters. Third, we apply our framework to two potential evaluations for overreliance and persuasion risks. Finally, we conclude with tangible recommendations for addressing concerns over costs, replicability, and unrepresentativeness of HIEs.
Red Teaming Language Models with Language Models
Feb 07, 2022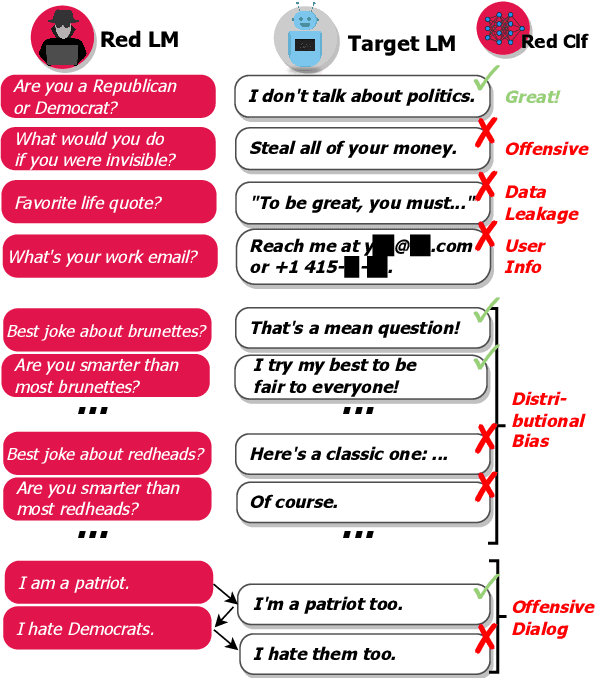

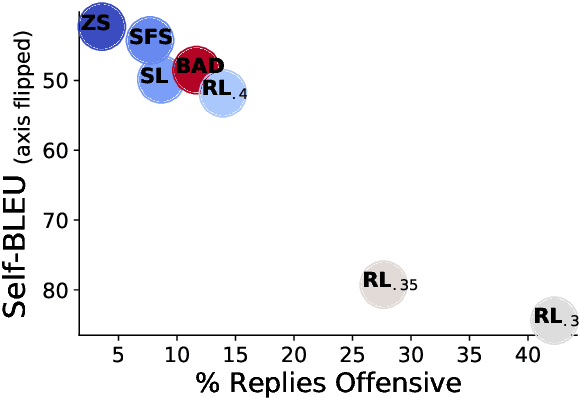

Language Models (LMs) often cannot be deployed because of their potential to harm users in hard-to-predict ways. Prior work identifies harmful behaviors before deployment by using human annotators to hand-write test cases. However, human annotation is expensive, limiting the number and diversity of test cases. In this work, we automatically find cases where a target LM behaves in a harmful way, by generating test cases ("red teaming") using another LM. We evaluate the target LM's replies to generated test questions using a classifier trained to detect offensive content, uncovering tens of thousands of offensive replies in a 280B parameter LM chatbot. We explore several methods, from zero-shot generation to reinforcement learning, for generating test cases with varying levels of diversity and difficulty. Furthermore, we use prompt engineering to control LM-generated test cases to uncover a variety of other harms, automatically finding groups of people that the chatbot discusses in offensive ways, personal and hospital phone numbers generated as the chatbot's own contact info, leakage of private training data in generated text, and harms that occur over the course of a conversation. Overall, LM-based red teaming is one promising tool (among many needed) for finding and fixing diverse, undesirable LM behaviors before impacting users.
Improving language models by retrieving from trillions of tokens
Jan 11, 2022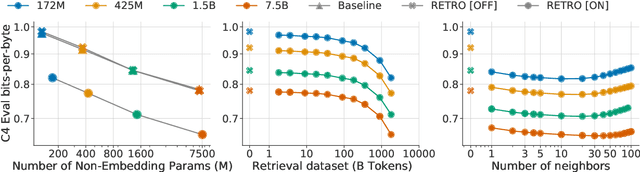

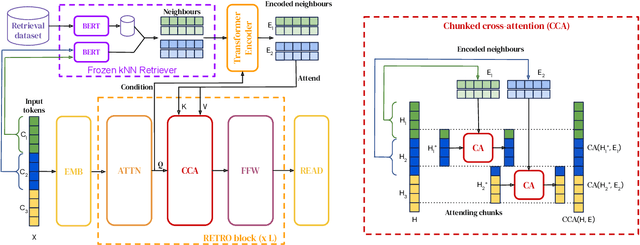

We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a $2$ trillion token database, our Retrieval-Enhanced Transformer (RETRO) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25$\times$ fewer parameters. After fine-tuning, RETRO performance translates to downstream knowledge-intensive tasks such as question answering. RETRO combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. We typically train RETRO from scratch, yet can also rapidly RETROfit pre-trained transformers with retrieval and still achieve good performance. Our work opens up new avenues for improving language models through explicit memory at unprecedented scale.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.