 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Instructed Visual Descriptions for Zero-Shot Video Question Answering
Feb 16, 2024We present Q-ViD, a simple approach for video question answering (video QA), that unlike prior methods, which are based on complex architectures, computationally expensive pipelines or use closed models like GPTs, Q-ViD relies on a single instruction-aware open vision-language model (InstructBLIP) to tackle videoQA using frame descriptions. Specifically, we create captioning instruction prompts that rely on the target questions about the videos and leverage InstructBLIP to obtain video frame captions that are useful to the task at hand. Subsequently, we form descriptions of the whole video using the question-dependent frame captions, and feed that information, along with a question-answering prompt, to a large language model (LLM). The LLM is our reasoning module, and performs the final step of multiple-choice QA. Our simple Q-ViD framework achieves competitive or even higher performances than current state of the art models on a diverse range of videoQA benchmarks, including NExT-QA, STAR, How2QA, TVQA and IntentQA.
SemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.
OATS: Opinion Aspect Target Sentiment Quadruple Extraction Dataset for Aspect-Based Sentiment Analysis
Sep 23, 2023



Aspect-based sentiment Analysis (ABSA) delves into understanding sentiments specific to distinct elements within textual content. It aims to analyze user-generated reviews to determine a) the target entity being reviewed, b) the high-level aspect to which it belongs, c) the sentiment words used to express the opinion, and d) the sentiment expressed toward the targets and the aspects. While various benchmark datasets have fostered advancements in ABSA, they often come with domain limitations and data granularity challenges. Addressing these, we introduce the OATS dataset, which encompasses three fresh domains and consists of 20,000 sentence-level quadruples and 13,000 review-level tuples. Our initiative seeks to bridge specific observed gaps: the recurrent focus on familiar domains like restaurants and laptops, limited data for intricate quadruple extraction tasks, and an occasional oversight of the synergy between sentence and review-level sentiments. Moreover, to elucidate OATS's potential and shed light on various ABSA subtasks that OATS can solve, we conducted in-domain and cross-domain experiments, establishing initial baselines. We hope the OATS dataset augments current resources, paving the way for an encompassing exploration of ABSA.
Positive and Risky Message Assessment for Music Products
Sep 18, 2023



In this work, we propose a novel research problem: assessing positive and risky messages from music products. We first establish a benchmark for multi-angle multi-level music content assessment and then present an effective multi-task prediction model with ordinality-enforcement to solve this problem. Our result shows the proposed method not only significantly outperforms strong task-specific counterparts but can concurrently evaluate multiple aspects.
Context-aware Adversarial Attack on Named Entity Recognition
Sep 16, 2023



In recent years, large pre-trained language models (PLMs) have achieved remarkable performance on many natural language processing benchmarks. Despite their success, prior studies have shown that PLMs are vulnerable to attacks from adversarial examples. In this work, we focus on the named entity recognition task and study context-aware adversarial attack methods to examine the model's robustness. Specifically, we propose perturbing the most informative words for recognizing entities to create adversarial examples and investigate different candidate replacement methods to generate natural and plausible adversarial examples. Experiments and analyses show that our methods are more effective in deceiving the model into making wrong predictions than strong baselines.
Overview of GUA-SPA at IberLEF 2023: Guarani-Spanish Code Switching Analysis
Sep 12, 2023


We present the first shared task for detecting and analyzing code-switching in Guarani and Spanish, GUA-SPA at IberLEF 2023. The challenge consisted of three tasks: identifying the language of a token, NER, and a novel task of classifying the way a Spanish span is used in the code-switched context. We annotated a corpus of 1500 texts extracted from news articles and tweets, around 25 thousand tokens, with the information for the tasks. Three teams took part in the evaluation phase, obtaining in general good results for Task 1, and more mixed results for Tasks 2 and 3.
SafeWebUH at SemEval-2023 Task 11: Learning Annotator Disagreement in Derogatory Text: Comparison of Direct Training vs Aggregation
May 01, 2023

Subjectivity and difference of opinion are key social phenomena, and it is crucial to take these into account in the annotation and detection process of derogatory textual content. In this paper, we use four datasets provided by SemEval-2023 Task 11 and fine-tune a BERT model to capture the disagreement in the annotation. We find individual annotator modeling and aggregation lowers the Cross-Entropy score by an average of 0.21, compared to the direct training on the soft labels. Our findings further demonstrate that annotator metadata contributes to the average 0.029 reduction in the Cross-Entropy score.
Distillation of encoder-decoder transformers for sequence labelling
Feb 10, 2023



Driven by encouraging results on a wide range of tasks, the field of NLP is experiencing an accelerated race to develop bigger language models. This race for bigger models has also underscored the need to continue the pursuit of practical distillation approaches that can leverage the knowledge acquired by these big models in a compute-efficient manner. Having this goal in mind, we build on recent work to propose a hallucination-free framework for sequence tagging that is especially suited for distillation. We show empirical results of new state-of-the-art performance across multiple sequence labelling datasets and validate the usefulness of this framework for distilling a large model in a few-shot learning scenario.
The Decades Progress on Code-Switching Research in NLP: A Systematic Survey on Trends and Challenges
Dec 19, 2022



Code-Switching, a common phenomenon in written text and conversation, has been studied over decades by the natural language processing (NLP) research community. Initially, code-switching is intensively explored by leveraging linguistic theories and, currently, more machine-learning oriented approaches to develop models. We introduce a comprehensive systematic survey on code-switching research in natural language processing to understand the progress of the past decades and conceptualize the challenges and tasks on the code-switching topic. Finally, we summarize the trends and findings and conclude with a discussion for future direction and open questions for further investigation.
Style Transfer as Data Augmentation: A Case Study on Named Entity Recognition
Oct 14, 2022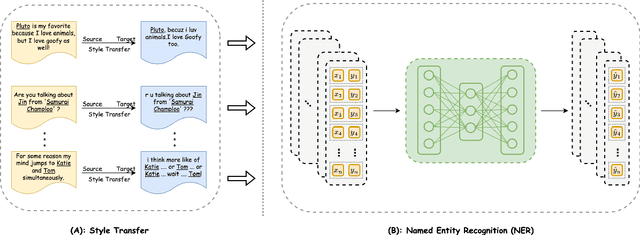
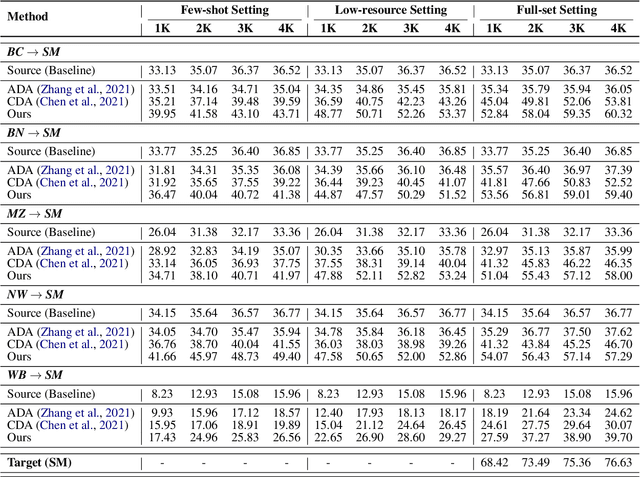
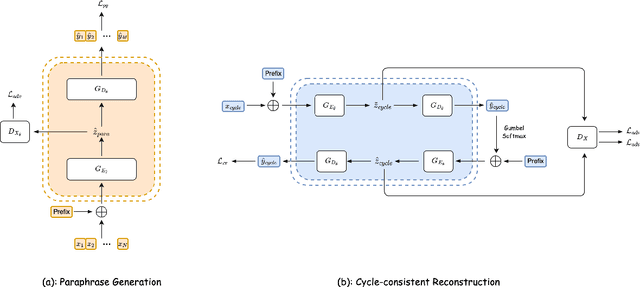
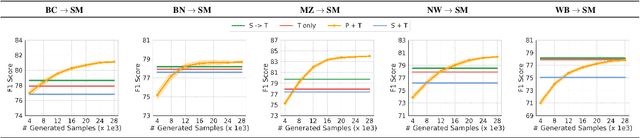
In this work, we take the named entity recognition task in the English language as a case study and explore style transfer as a data augmentation method to increase the size and diversity of training data in low-resource scenarios. We propose a new method to effectively transform the text from a high-resource domain to a low-resource domain by changing its style-related attributes to generate synthetic data for training. Moreover, we design a constrained decoding algorithm along with a set of key ingredients for data selection to guarantee the generation of valid and coherent data. Experiments and analysis on five different domain pairs under different data regimes demonstrate that our approach can significantly improve results compared to current state-of-the-art data augmentation methods. Our approach is a practical solution to data scarcity, and we expect it to be applicable to other NLP tasks.