 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs
Oct 31, 2025Evaluating the abilities of large language models (LLMs) for tasks that require long-term memory and thus long-context reasoning, for example in conversational settings, is hampered by the existing benchmarks, which often lack narrative coherence, cover narrow domains, and only test simple recall-oriented tasks. This paper introduces a comprehensive solution to these challenges. First, we present a novel framework for automatically generating long (up to 10M tokens), coherent, and topically diverse conversations, accompanied by probing questions targeting a wide range of memory abilities. From this, we construct BEAM, a new benchmark comprising 100 conversations and 2,000 validated questions. Second, to enhance model performance, we propose LIGHT-a framework inspired by human cognition that equips LLMs with three complementary memory systems: a long-term episodic memory, a short-term working memory, and a scratchpad for accumulating salient facts. Our experiments on BEAM reveal that even LLMs with 1M token context windows (with and without retrieval-augmentation) struggle as dialogues lengthen. In contrast, LIGHT consistently improves performance across various models, achieving an average improvement of 3.5%-12.69% over the strongest baselines, depending on the backbone LLM. An ablation study further confirms the contribution of each memory component.
Not What the Doctor Ordered: Surveying LLM-based De-identification and Quantifying Clinical Information Loss
Sep 17, 2025De-identification in the healthcare setting is an application of NLP where automated algorithms are used to remove personally identifying information of patients (and, sometimes, providers). With the recent rise of generative large language models (LLMs), there has been a corresponding rise in the number of papers that apply LLMs to de-identification. Although these approaches often report near-perfect results, significant challenges concerning reproducibility and utility of the research papers persist. This paper identifies three key limitations in the current literature: inconsistent reporting metrics hindering direct comparisons, the inadequacy of traditional classification metrics in capturing errors which LLMs may be more prone to (i.e., altering clinically relevant information), and lack of manual validation of automated metrics which aim to quantify these errors. To address these issues, we first present a survey of LLM-based de-identification research, highlighting the heterogeneity in reporting standards. Second, we evaluated a diverse set of models to quantify the extent of inappropriate removal of clinical information. Next, we conduct a manual validation of an existing evaluation metric to measure the removal of clinical information, employing clinical experts to assess their efficacy. We highlight poor performance and describe the inherent limitations of such metrics in identifying clinically significant changes. Lastly, we propose a novel methodology for the detection of clinically relevant information removal.
SemEval Task 1: Semantic Textual Relatedness for African and Asian Languages
Apr 04, 2024



We present the first shared task on Semantic Textual Relatedness (STR). While earlier shared tasks primarily focused on semantic similarity, we instead investigate the broader phenomenon of semantic relatedness across 14 languages: Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by the relatively limited availability of NLP resources. Each instance in the datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. Participating systems were asked to rank sentence pairs by their closeness in meaning (i.e., their degree of semantic relatedness) in the 14 languages in three main tracks: (a) supervised, (b) unsupervised, and (c) crosslingual. The task attracted 163 participants. We received 70 submissions in total (across all tasks) from 51 different teams, and 38 system description papers. We report on the best-performing systems as well as the most common and the most effective approaches for the three different tracks.
Citation Amnesia: NLP and Other Academic Fields Are in a Citation Age Recession
Feb 19, 2024This study examines the tendency to cite older work across 20 fields of study over 43 years (1980--2023). We put NLP's propensity to cite older work in the context of these 20 other fields to analyze whether NLP shows similar temporal citation patterns to these other fields over time or whether differences can be observed. Our analysis, based on a dataset of approximately 240 million papers, reveals a broader scientific trend: many fields have markedly declined in citing older works (e.g., psychology, computer science). We term this decline a 'citation age recession', analogous to how economists define periods of reduced economic activity. The trend is strongest in NLP and ML research (-12.8% and -5.5% in citation age from previous peaks). Our results suggest that citing more recent works is not directly driven by the growth in publication rates (-3.4% across fields; -5.2% in humanities; -5.5% in formal sciences) -- even when controlling for an increase in the volume of papers. Our findings raise questions about the scientific community's engagement with past literature, particularly for NLP, and the potential consequences of neglecting older but relevant research. The data and a demo showcasing our results are publicly available.
SemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.
Collaboration or Corporate Capture? Quantifying NLP's Reliance on Industry Artifacts and Contributions
Dec 06, 2023The advent of transformers, higher computational budgets, and big data has engendered remarkable progress in Natural Language Processing (NLP). Impressive performance of industry pre-trained models has garnered public attention in recent years and made news headlines. That these are industry models is noteworthy. Rarely, if ever, are academic institutes producing exciting new NLP models. Using these models is critical for competing on NLP benchmarks and correspondingly to stay relevant in NLP research. We surveyed 100 papers published at EMNLP 2022 to determine whether this phenomenon constitutes a reliance on industry for NLP publications. We find that there is indeed a substantial reliance. Citations of industry artifacts and contributions across categories is at least three times greater than industry publication rates per year. Quantifying this reliance does not settle how we ought to interpret the results. We discuss two possible perspectives in our discussion: 1) Is collaboration with industry still collaboration in the absence of an alternative? Or 2) has free NLP inquiry been captured by the motivations and research direction of private corporations?
Benchmarking bias: Expanding clinical AI model card to incorporate bias reporting of social and non-social factors
Nov 21, 2023
Clinical AI model reporting cards should be expanded to incorporate a broad bias reporting of both social and non-social factors. Non-social factors consider the role of other factors, such as disease dependent, anatomic, or instrument factors on AI model bias, which are essential to ensure safe deployment.
We are Who We Cite: Bridges of Influence Between Natural Language Processing and Other Academic Fields
Oct 23, 2023Natural Language Processing (NLP) is poised to substantially influence the world. However, significant progress comes hand-in-hand with substantial risks. Addressing them requires broad engagement with various fields of study. Yet, little empirical work examines the state of such engagement (past or current). In this paper, we quantify the degree of influence between 23 fields of study and NLP (on each other). We analyzed ~77k NLP papers, ~3.1m citations from NLP papers to other papers, and ~1.8m citations from other papers to NLP papers. We show that, unlike most fields, the cross-field engagement of NLP, measured by our proposed Citation Field Diversity Index (CFDI), has declined from 0.58 in 1980 to 0.31 in 2022 (an all-time low). In addition, we find that NLP has grown more insular -- citing increasingly more NLP papers and having fewer papers that act as bridges between fields. NLP citations are dominated by computer science; Less than 8% of NLP citations are to linguistics, and less than 3% are to math and psychology. These findings underscore NLP's urgent need to reflect on its engagement with various fields.
The Elephant in the Room: Analyzing the Presence of Big Tech in Natural Language Processing Research
May 09, 2023



Recent advances in deep learning methods for natural language processing (NLP) have created new business opportunities and made NLP research critical for industry development. As one of the big players in the field of NLP, together with governments and universities, it is important to track the influence of industry on research. In this study, we seek to quantify and characterize industry presence in the NLP community over time. Using a corpus with comprehensive metadata of 78,187 NLP publications and 701 resumes of NLP publication authors, we explore the industry presence in the field since the early 90s. We find that industry presence among NLP authors has been steady before a steep increase over the past five years (180% growth from 2017 to 2022). A few companies account for most of the publications and provide funding to academic researchers through grants and internships. Our study shows that the presence and impact of the industry on natural language processing research are significant and fast-growing. This work calls for increased transparency of industry influence in the field.
What Makes Sentences Semantically Related: A Textual Relatedness Dataset and Empirical Study
Oct 10, 2021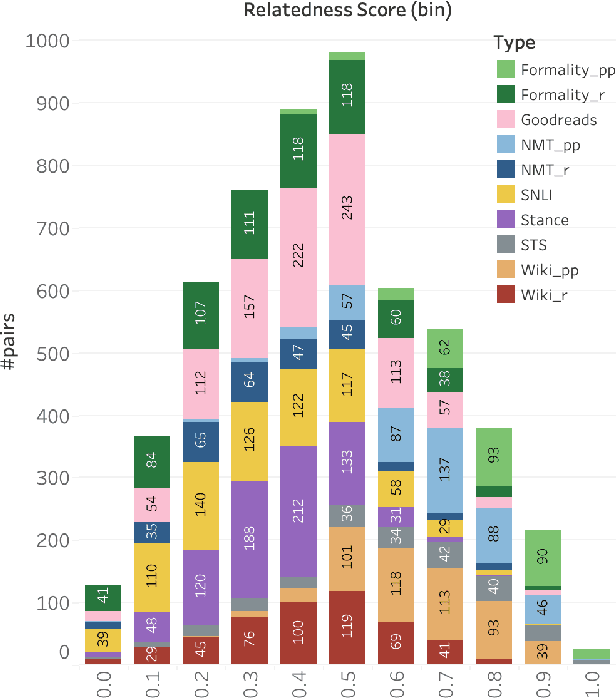
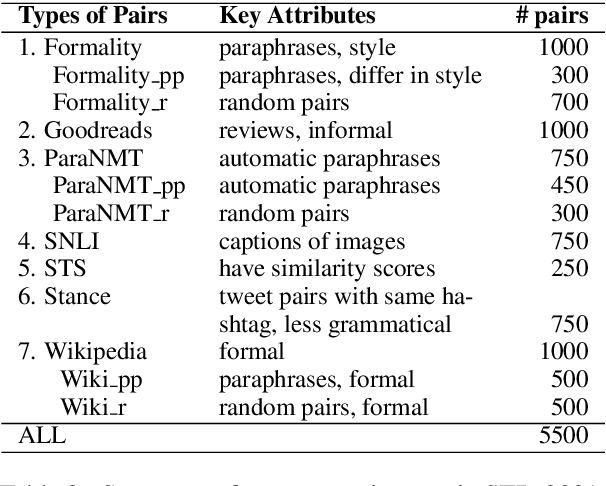
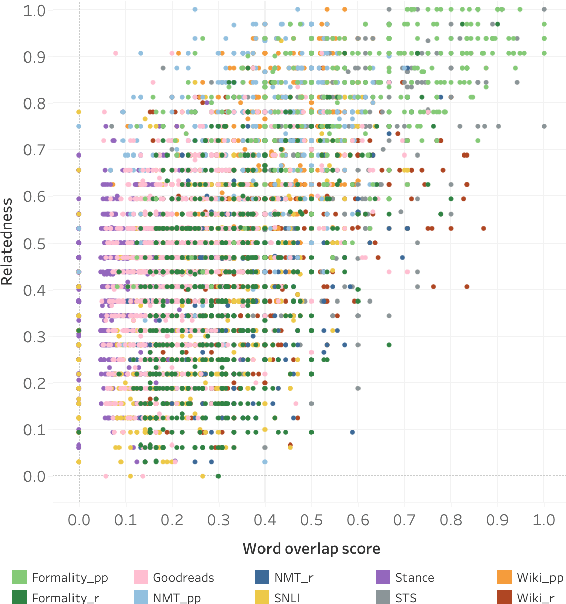

The degree of semantic relatedness (or, closeness in meaning) of two units of language has long been considered fundamental to understanding meaning. Automatically determining relatedness has many applications such as question answering and summarization. However, prior NLP work has largely focused on semantic similarity (a subset of relatedness), because of a lack of relatedness datasets. Here for the first time, we introduce a dataset of semantic relatedness for sentence pairs. This dataset, STR-2021, has 5,500 English sentence pairs manually annotated for semantic relatedness using a comparative annotation framework. We show that the resulting scores have high reliability (repeat annotation correlation of 0.84). We use the dataset to explore a number of questions on what makes two sentences more semantically related. We also evaluate a suite of sentence representation methods on their ability to place pairs that are more related closer to each other in vector space.