 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignals: Trajectory Sampling and Triage for Agentic Interactions
Apr 01, 2026Agentic applications based on large language models increasingly rely on multi-step interaction loops involving planning, action execution, and environment feedback. While such systems are now deployed at scale, improving them post-deployment remains challenging. Agent trajectories are voluminous and non-deterministic, and reviewing each one, whether through human review or auxiliary LLMs, is slow and cost-prohibitive. We propose a lightweight, signal-based framework for triaging agentic interaction trajectories. Our approach computes cheap, broadly applicable signals from live interactions and attaches them as structured attributes for trajectory triage, identifying interactions likely to be informative without affecting online agent behavior. We organize signals into a coarse-grained taxonomy spanning interaction (misalignment, stagnation, disengagement, satisfaction), execution (failure, loop), and environment (exhaustion), designed for computation without model calls. In a controlled annotation study on $τ$-bench, a widely used benchmark for tool-augmented agent evaluation, we show that signal-based sampling achieves an 82\% informativeness rate compared to 74\% for heuristic filtering and 54\% for random sampling, with a 1.52x efficiency gain per informative trajectory. The advantage is robust across reward strata and task domains, confirming that signals provide genuine per-trajectory informativeness gains rather than merely oversampling obvious failures. These results show that lightweight signals can serve as practical sampling infrastructure for agentic systems, and suggest a path toward preference data construction and post-deployment optimization.
LLM Reasoning Engine: Specialized Training for Enhanced Mathematical Reasoning
Dec 28, 2024Large Language Models (LLMs) have shown remarkable performance in various natural language processing tasks but face challenges in mathematical reasoning, where complex problem-solving requires both linguistic understanding and mathematical reasoning skills. Existing approaches to address this challenge often rely on ensemble methods and suffer from the problem of data scarcity in target domains. In this work, we present a novel method to enhance LLMs' capabilities in mathematical reasoning tasks. Motivated by the need to bridge this gap, our approach incorporates a question paraphrase strategy, which aims at diversifying the linguistic forms of mathematical questions to improve generalization. Additionally, specialized training objectives are employed to guide the model's learning process, focusing on enhancing its understanding of mathematical concepts and reasoning processes. We conduct experiments on four datasets using different LLMs, and demonstrate the effectiveness of our approach in improving LLMs' performance on mathematical reasoning tasks. Our findings underscore the significance of our methodology in the advancement of large language models and its potential implications for real-world applications that require mathematical reasoning abilities.
Context-aware Adversarial Attack on Named Entity Recognition
Sep 16, 2023



In recent years, large pre-trained language models (PLMs) have achieved remarkable performance on many natural language processing benchmarks. Despite their success, prior studies have shown that PLMs are vulnerable to attacks from adversarial examples. In this work, we focus on the named entity recognition task and study context-aware adversarial attack methods to examine the model's robustness. Specifically, we propose perturbing the most informative words for recognizing entities to create adversarial examples and investigate different candidate replacement methods to generate natural and plausible adversarial examples. Experiments and analyses show that our methods are more effective in deceiving the model into making wrong predictions than strong baselines.
Predictions of photophysical properties of phosphorescent platinum(II) complexes based on ensemble machine learning approach
Jan 08, 2023Phosphorescent metal complexes have been under intense investigations as emissive dopants for energy efficient organic light emitting diodes (OLEDs). Among them, cyclometalated Pt(II) complexes are widespread triplet emitters with color-tunable emissions. To render their practical applications as OLED emitters, it is in great need to develop Pt(II) complexes with high radiative decay rate constant ($k_r$) and photoluminescence (PL) quantum yield. Thus, an efficient and accurate prediction tool is highly desirable. Here, we develop a general protocol for accurate predictions of emission wavelength, radiative decay rate constant, and PL quantum yield for phosphorescent Pt(II) emitters based on the combination of first-principles quantum mechanical method, machine learning (ML) and experimental calibration. A new dataset concerning phosphorescent Pt(II) emitters is constructed, with more than two hundred samples collected from the literature. Features containing pertinent electronic properties of the complexes are chosen. Our results demonstrate that ensemble learning models combined with stacking-based approaches exhibit the best performance, where the values of squared correlation coefficients ($R^2$), mean absolute error (MAE), and root mean square error (RMSE) are 0.96, 7.21 nm and 13.00 nm for emission wavelength prediction, and 0.81, 0.11 and 0.15 for PL quantum yield prediction. For radiative decay rate constant ($k_r$), the obtained value of $R^2$ is 0.67 while MAE and RMSE are 0.21 and 0.25 (both in log scale), respectively. The accuracy of the protocol is further confirmed using 24 recently reported Pt(II) complexes, which demonstrates its reliability for a broad palette of Pt(II) emitters.We expect this protocol will become a valuable tool, accelerating the rational design of novel OLED materials with desired properties.
Style Transfer as Data Augmentation: A Case Study on Named Entity Recognition
Oct 14, 2022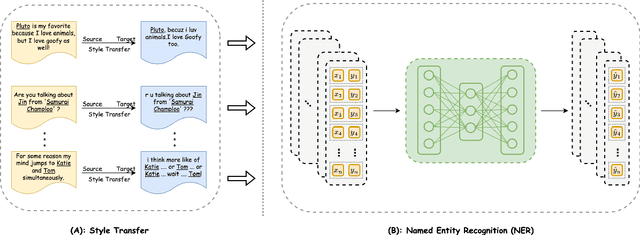
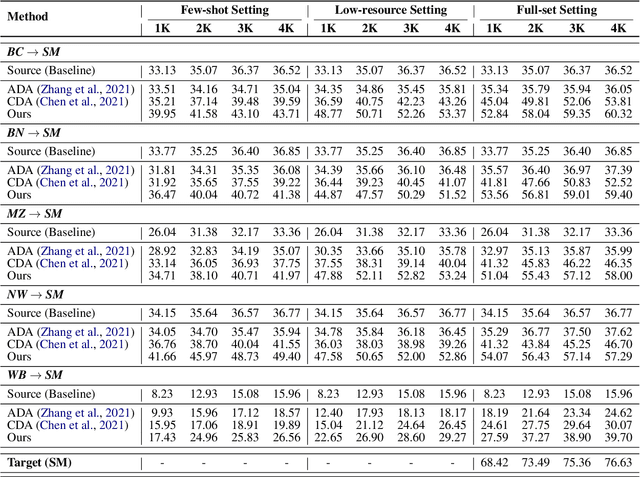
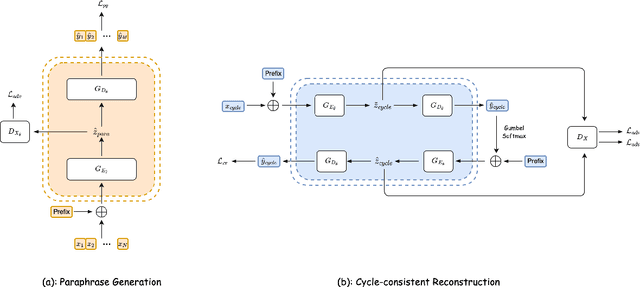
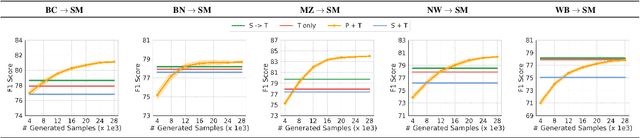
In this work, we take the named entity recognition task in the English language as a case study and explore style transfer as a data augmentation method to increase the size and diversity of training data in low-resource scenarios. We propose a new method to effectively transform the text from a high-resource domain to a low-resource domain by changing its style-related attributes to generate synthetic data for training. Moreover, we design a constrained decoding algorithm along with a set of key ingredients for data selection to guarantee the generation of valid and coherent data. Experiments and analysis on five different domain pairs under different data regimes demonstrate that our approach can significantly improve results compared to current state-of-the-art data augmentation methods. Our approach is a practical solution to data scarcity, and we expect it to be applicable to other NLP tasks.
CALCS 2021 Shared Task: Machine Translation for Code-Switched Data
Feb 19, 2022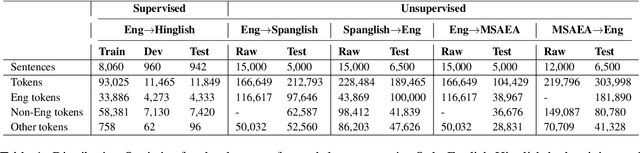
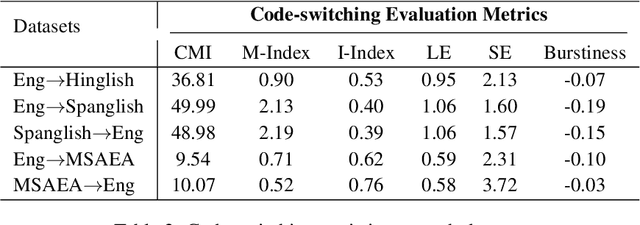

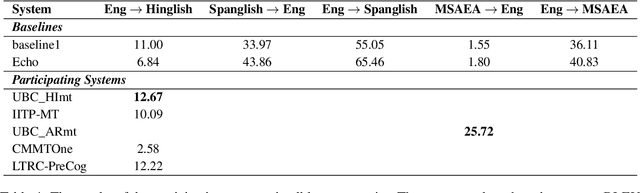
To date, efforts in the code-switching literature have focused for the most part on language identification, POS, NER, and syntactic parsing. In this paper, we address machine translation for code-switched social media data. We create a community shared task. We provide two modalities for participation: supervised and unsupervised. For the supervised setting, participants are challenged to translate English into Hindi-English (Eng-Hinglish) in a single direction. For the unsupervised setting, we provide the following language pairs: English and Spanish-English (Eng-Spanglish), and English and Modern Standard Arabic-Egyptian Arabic (Eng-MSAEA) in both directions. We share insights and challenges in curating the "into" code-switching language evaluation data. Further, we provide baselines for all language pairs in the shared task. The leaderboard for the shared task comprises 12 individual system submissions corresponding to 5 different teams. The best performance achieved is 12.67% BLEU score for English to Hinglish and 25.72% BLEU score for MSAEA to English.
A Simple Approach to Jointly Rank Passages and Select Relevant Sentences in the OBQA Context
Sep 22, 2021
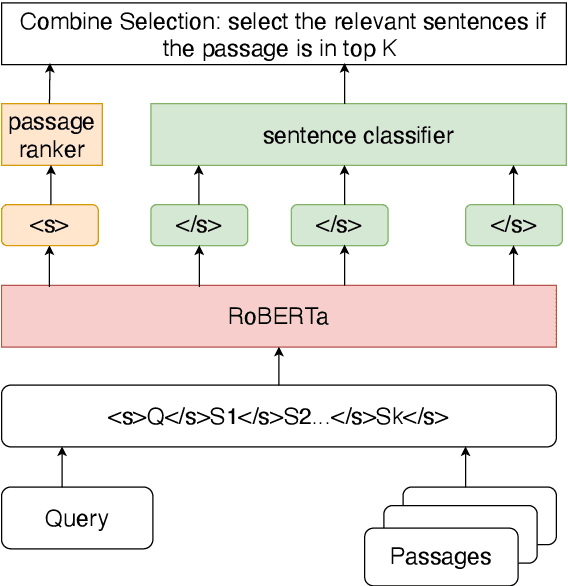
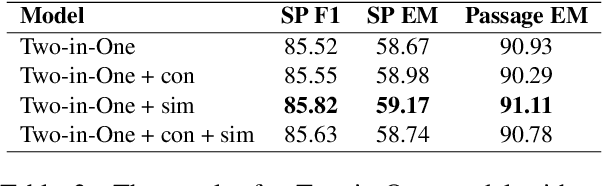
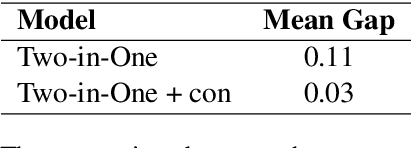
In the open question answering (OBQA) task, how to select the relevant information from a large corpus is a crucial problem for reasoning and inference. Some datasets (e.g, HotpotQA) mainly focus on testing the model's reasoning ability at the sentence level. To overcome this challenge, many existing frameworks use a deep learning model to select relevant passages and then answer each question by matching a sentence in the corresponding passage. However, such frameworks require long inference time and fail to take advantage of the relationship between passages and sentences. In this work, we present a simple yet effective framework to address these problems by jointly ranking passages and selecting sentences. We propose consistency and similarity constraints to promote the correlation and interaction between passage ranking and sentence selection. In our experiments, we demonstrate that our framework can achieve competitive results and outperform the baseline by 28\% in terms of exact matching of relevant sentences on the HotpotQA dataset.
Data Augmentation for Cross-Domain Named Entity Recognition
Sep 04, 2021
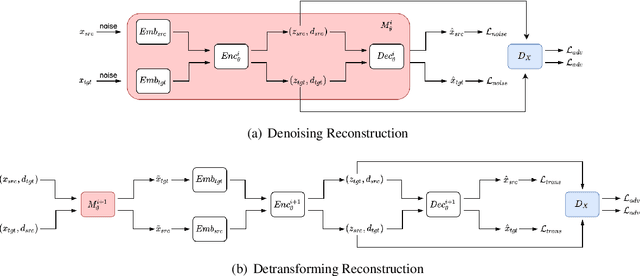
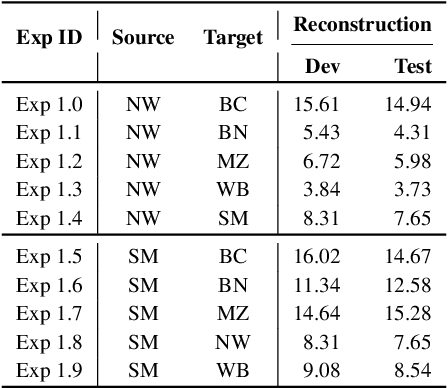
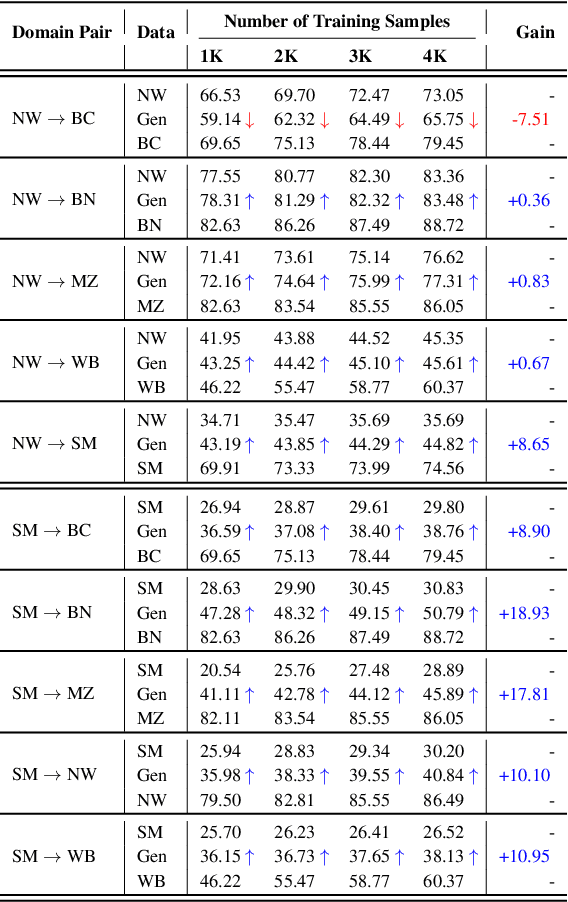
Current work in named entity recognition (NER) shows that data augmentation techniques can produce more robust models. However, most existing techniques focus on augmenting in-domain data in low-resource scenarios where annotated data is quite limited. In contrast, we study cross-domain data augmentation for the NER task. We investigate the possibility of leveraging data from high-resource domains by projecting it into the low-resource domains. Specifically, we propose a novel neural architecture to transform the data representation from a high-resource to a low-resource domain by learning the patterns (e.g. style, noise, abbreviations, etc.) in the text that differentiate them and a shared feature space where both domains are aligned. We experiment with diverse datasets and show that transforming the data to the low-resource domain representation achieves significant improvements over only using data from high-resource domains.
Mitigating Temporal-Drift: A Simple Approach to Keep NER Models Crisp
Apr 20, 2021
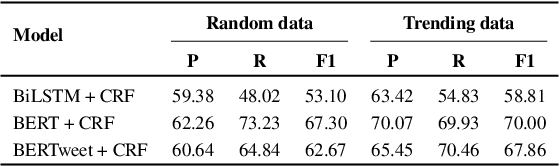
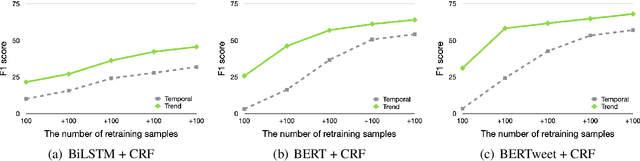
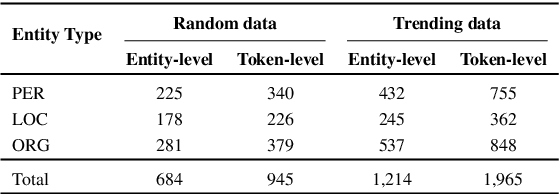
Performance of neural models for named entity recognition degrades over time, becoming stale. This degradation is due to temporal drift, the change in our target variables' statistical properties over time. This issue is especially problematic for social media data, where topics change rapidly. In order to mitigate the problem, data annotation and retraining of models is common. Despite its usefulness, this process is expensive and time-consuming, which motivates new research on efficient model updating. In this paper, we propose an intuitive approach to measure the potential trendiness of tweets and use this metric to select the most informative instances to use for training. We conduct experiments on three state-of-the-art models on the Temporal Twitter Dataset. Our approach shows larger increases in prediction accuracy with less training data than the alternatives, making it an attractive, practical solution.
A Caption Is Worth A Thousand Images: Investigating Image Captions for Multimodal Named Entity Recognition
Oct 23, 2020

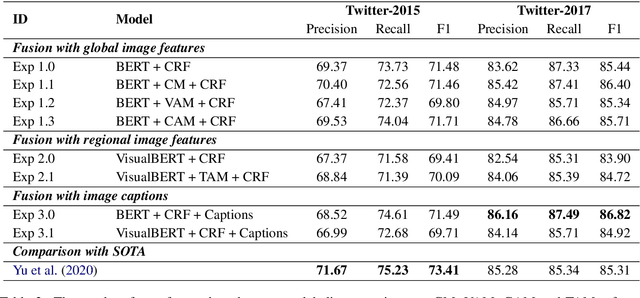
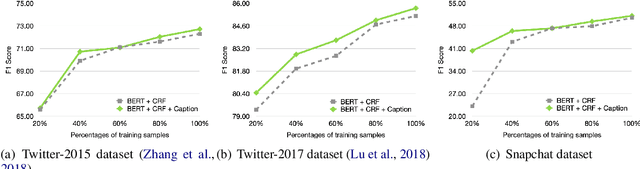
Multimodal named entity recognition (MNER) requires to bridge the gap between language understanding and visual context. Due to advances in natural language processing (NLP) and computer vision (CV), many neural techniques have been proposed to incorporate images into the NER task. In this work, we conduct a detailed analysis of current state-of-the-art fusion techniques for MNER and describe scenarios where adding information from the image does not always result in boosts in performance. We also study the use of captions as a way to enrich the context for MNER. We provide extensive empirical analysis and an ablation study on three datasets from popular social platforms to expose the situations where the approach is beneficial.