 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning is More Robust to Dataset Imbalance
Oct 11, 2021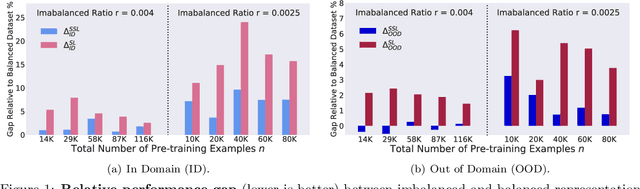
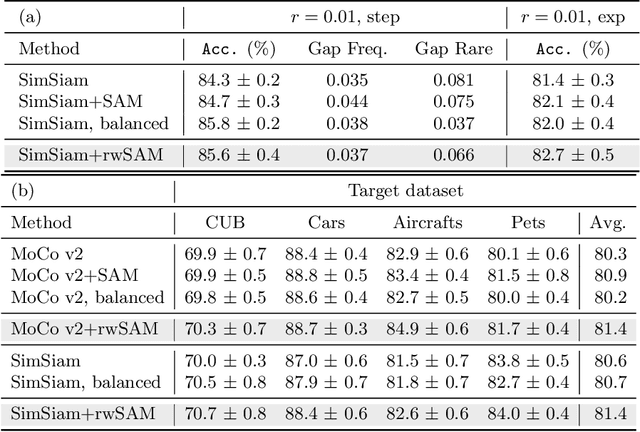
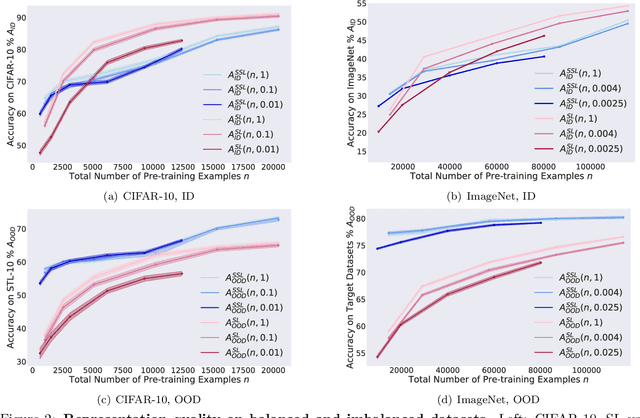
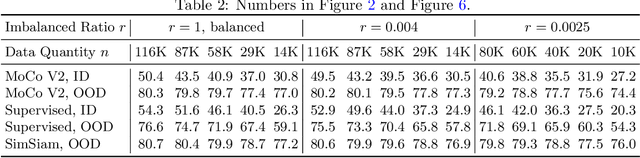
Self-supervised learning (SSL) is a scalable way to learn general visual representations since it learns without labels. However, large-scale unlabeled datasets in the wild often have long-tailed label distributions, where we know little about the behavior of SSL. In this work, we systematically investigate self-supervised learning under dataset imbalance. First, we find out via extensive experiments that off-the-shelf self-supervised representations are already more robust to class imbalance than supervised representations. The performance gap between balanced and imbalanced pre-training with SSL is significantly smaller than the gap with supervised learning, across sample sizes, for both in-domain and, especially, out-of-domain evaluation. Second, towards understanding the robustness of SSL, we hypothesize that SSL learns richer features from frequent data: it may learn label-irrelevant-but-transferable features that help classify the rare classes and downstream tasks. In contrast, supervised learning has no incentive to learn features irrelevant to the labels from frequent examples. We validate this hypothesis with semi-synthetic experiments and theoretical analyses on a simplified setting. Third, inspired by the theoretical insights, we devise a re-weighted regularization technique that consistently improves the SSL representation quality on imbalanced datasets with several evaluation criteria, closing the small gap between balanced and imbalanced datasets with the same number of examples.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Learning Barrier Certificates: Towards Safe Reinforcement Learning with Zero Training-time Violations
Aug 04, 2021
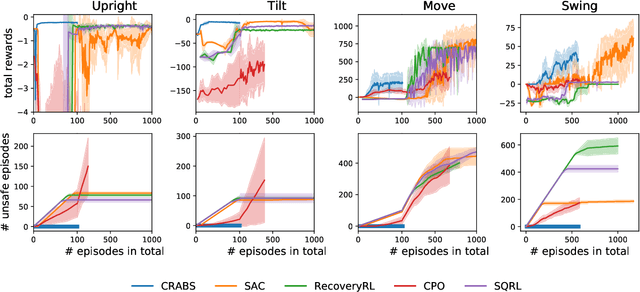
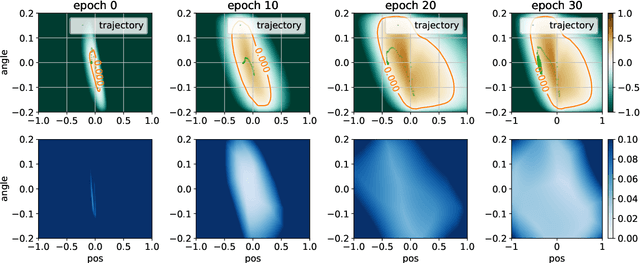
Training-time safety violations have been a major concern when we deploy reinforcement learning algorithms in the real world. This paper explores the possibility of safe RL algorithms with zero training-time safety violations in the challenging setting where we are only given a safe but trivial-reward initial policy without any prior knowledge of the dynamics model and additional offline data. We propose an algorithm, Co-trained Barrier Certificate for Safe RL (CRABS), which iteratively learns barrier certificates, dynamics models, and policies. The barrier certificates, learned via adversarial training, ensure the policy's safety assuming calibrated learned dynamics model. We also add a regularization term to encourage larger certified regions to enable better exploration. Empirical simulations show that zero safety violations are already challenging for a suite of simple environments with only 2-4 dimensional state space, especially if high-reward policies have to visit regions near the safety boundary. Prior methods require hundreds of violations to achieve decent rewards on these tasks, whereas our proposed algorithms incur zero violations.
Statistically Meaningful Approximation: a Case Study on Approximating Turing Machines with Transformers
Jul 28, 2021A common lens to theoretically study neural net architectures is to analyze the functions they can approximate. However, the constructions from approximation theory often have unrealistic aspects, for example, reliance on infinite precision to memorize target function values, which make these results potentially less meaningful. To address these issues, this work proposes a formal definition of statistically meaningful approximation which requires the approximating network to exhibit good statistical learnability. We present case studies on statistically meaningful approximation for two classes of functions: boolean circuits and Turing machines. We show that overparameterized feedforward neural nets can statistically meaningfully approximate boolean circuits with sample complexity depending only polynomially on the circuit size, not the size of the approximating network. In addition, we show that transformers can statistically meaningfully approximate Turing machines with computation time bounded by $T$, requiring sample complexity polynomial in the alphabet size, state space size, and $\log (T)$. Our analysis introduces new tools for generalization bounds that provide much tighter sample complexity guarantees than the typical VC-dimension or norm-based bounds, which may be of independent interest.
Calibrating Predictions to Decisions: A Novel Approach to Multi-Class Calibration
Jul 12, 2021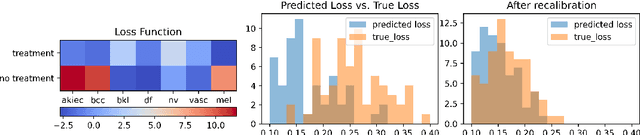


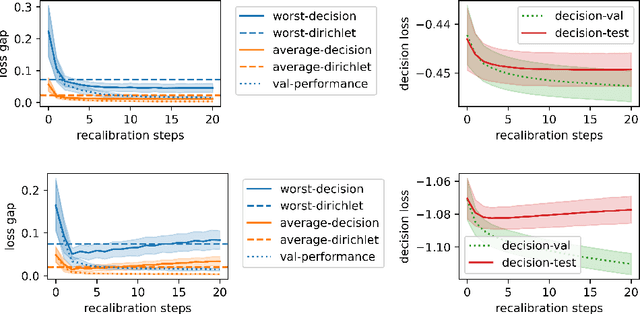
When facing uncertainty, decision-makers want predictions they can trust. A machine learning provider can convey confidence to decision-makers by guaranteeing their predictions are distribution calibrated -- amongst the inputs that receive a predicted class probabilities vector $q$, the actual distribution over classes is $q$. For multi-class prediction problems, however, achieving distribution calibration tends to be infeasible, requiring sample complexity exponential in the number of classes $C$. In this work, we introduce a new notion -- \emph{decision calibration} -- that requires the predicted distribution and true distribution to be ``indistinguishable'' to a set of downstream decision-makers. When all possible decision makers are under consideration, decision calibration is the same as distribution calibration. However, when we only consider decision makers choosing between a bounded number of actions (e.g. polynomial in $C$), our main result shows that decisions calibration becomes feasible -- we design a recalibration algorithm that requires sample complexity polynomial in the number of actions and the number of classes. We validate our recalibration algorithm empirically: compared to existing methods, decision calibration improves decision-making on skin lesion and ImageNet classification with modern neural network predictors.
Iterative Feature Matching: Toward Provable Domain Generalization with Logarithmic Environments
Jun 18, 2021

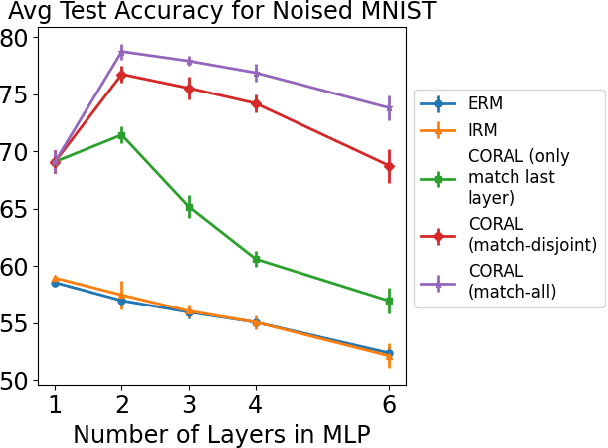
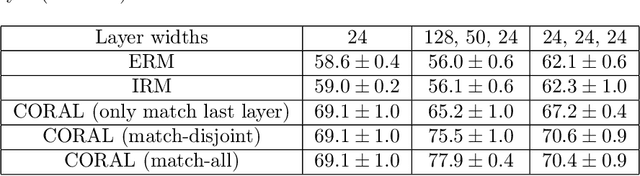
Domain generalization aims at performing well on unseen test environments with data from a limited number of training environments. Despite a proliferation of proposal algorithms for this task, assessing their performance, both theoretically and empirically is still very challenging. Moreover, recent approaches such as Invariant Risk Minimization (IRM) require a prohibitively large number of training environments - linear in the dimension of the spurious feature space $d_s$ - even on simple data models like the one proposed by [Rosenfeld et al., 2021]. Under a variant of this model, we show that both ERM and IRM cannot generalize with $o(d_s)$ environments. We then present a new algorithm based on performing iterative feature matching that is guaranteed with high probability to yield a predictor that generalizes after seeing only $O(\log{d_s})$ environments.
Why Do Pretrained Language Models Help in Downstream Tasks? An Analysis of Head and Prompt Tuning
Jun 17, 2021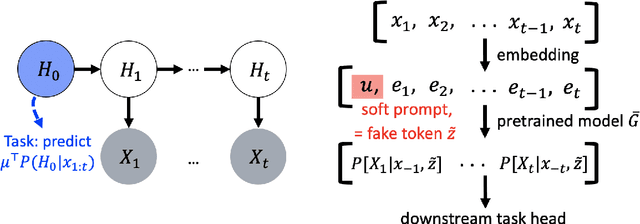
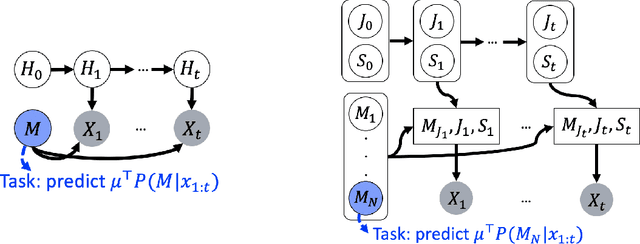
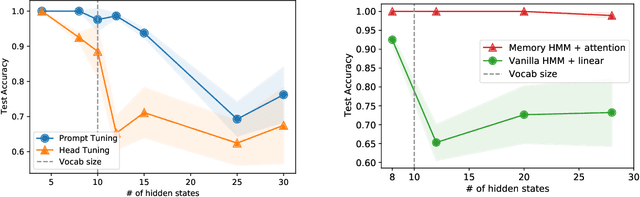
Pretrained language models have achieved state-of-the-art performance when adapted to a downstream NLP task. However, theoretical analysis of these models is scarce and challenging since the pretraining and downstream tasks can be very different. We propose an analysis framework that links the pretraining and downstream tasks with an underlying latent variable generative model of text -- the downstream classifier must recover a function of the posterior distribution over the latent variables. We analyze head tuning (learning a classifier on top of the frozen pretrained model) and prompt tuning in this setting. The generative model in our analysis is either a Hidden Markov Model (HMM) or an HMM augmented with a latent memory component, motivated by long-term dependencies in natural language. We show that 1) under certain non-degeneracy conditions on the HMM, simple classification heads can solve the downstream task, 2) prompt tuning obtains downstream guarantees with weaker non-degeneracy conditions, and 3) our recovery guarantees for the memory-augmented HMM are stronger than for the vanilla HMM because task-relevant information is easier to recover from the long-term memory. Experiments on synthetically generated data from HMMs back our theoretical findings.
Provable Guarantees for Self-Supervised Deep Learning with Spectral Contrastive Loss
Jun 17, 2021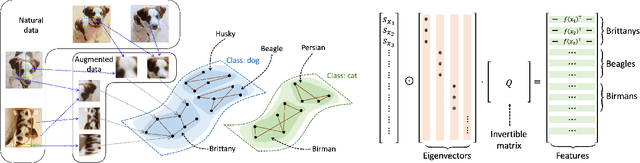
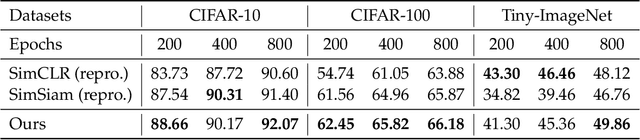
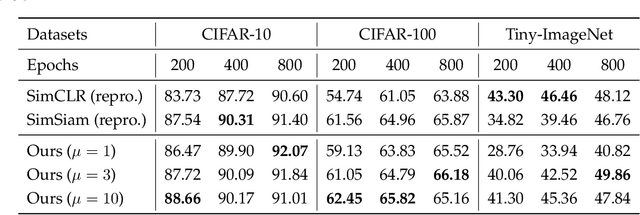
Recent works in self-supervised learning have advanced the state-of-the-art by relying on the contrastive learning paradigm, which learns representations by pushing positive pairs, or similar examples from the same class, closer together while keeping negative pairs far apart. Despite the empirical successes, theoretical foundations are limited -- prior analyses assume conditional independence of the positive pairs given the same class label, but recent empirical applications use heavily correlated positive pairs (i.e., data augmentations of the same image). Our work analyzes contrastive learning without assuming conditional independence of positive pairs using a novel concept of the augmentation graph on data. Edges in this graph connect augmentations of the same data, and ground-truth classes naturally form connected sub-graphs. We propose a loss that performs spectral decomposition on the population augmentation graph and can be succinctly written as a contrastive learning objective on neural net representations. Minimizing this objective leads to features with provable accuracy guarantees under linear probe evaluation. By standard generalization bounds, these accuracy guarantees also hold when minimizing the training contrastive loss. Empirically, the features learned by our objective can match or outperform several strong baselines on benchmark vision datasets. In all, this work provides the first provable analysis for contrastive learning where guarantees for linear probe evaluation can apply to realistic empirical settings.
Label Noise SGD Provably Prefers Flat Global Minimizers
Jun 11, 2021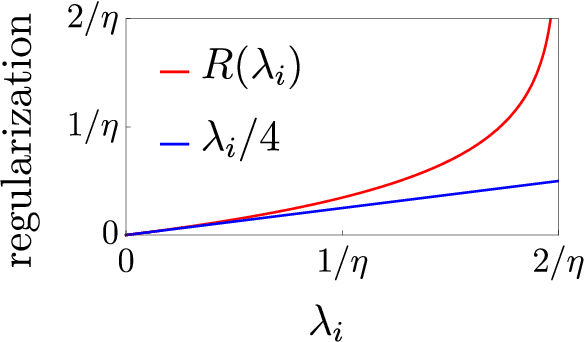


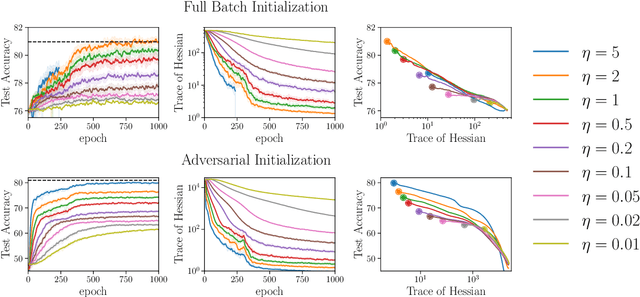
In overparametrized models, the noise in stochastic gradient descent (SGD) implicitly regularizes the optimization trajectory and determines which local minimum SGD converges to. Motivated by empirical studies that demonstrate that training with noisy labels improves generalization, we study the implicit regularization effect of SGD with label noise. We show that SGD with label noise converges to a stationary point of a regularized loss $L(\theta) +\lambda R(\theta)$, where $L(\theta)$ is the training loss, $\lambda$ is an effective regularization parameter depending on the step size, strength of the label noise, and the batch size, and $R(\theta)$ is an explicit regularizer that penalizes sharp minimizers. Our analysis uncovers an additional regularization effect of large learning rates beyond the linear scaling rule that penalizes large eigenvalues of the Hessian more than small ones. We also prove extensions to classification with general loss functions, SGD with momentum, and SGD with general noise covariance, significantly strengthening the prior work of Blanc et al. to global convergence and large learning rates and of HaoChen et al. to general models.
Joint System-Wise Optimization for Pipeline Goal-Oriented Dialog System
Jun 09, 2021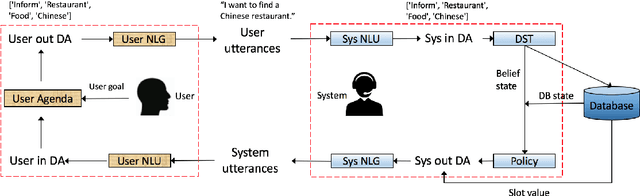
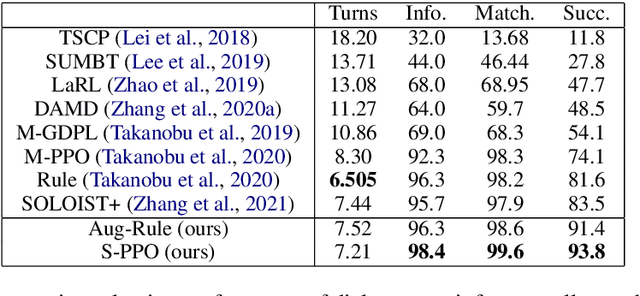
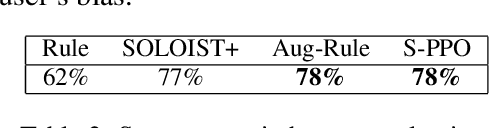
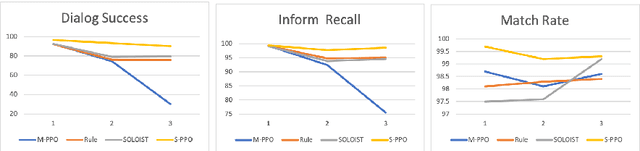
Recent work (Takanobu et al., 2020) proposed the system-wise evaluation on dialog systems and found that improvement on individual components (e.g., NLU, policy) in prior work may not necessarily bring benefit to pipeline systems in system-wise evaluation. To improve the system-wise performance, in this paper, we propose new joint system-wise optimization techniques for the pipeline dialog system. First, we propose a new data augmentation approach which automates the labeling process for NLU training. Second, we propose a novel stochastic policy parameterization with Poisson distribution that enables better exploration and offers a principled way to compute policy gradient. Third, we propose a reward bonus to help policy explore successful dialogs. Our approaches outperform the competitive pipeline systems from Takanobu et al. (2020) by big margins of 12% success rate in automatic system-wise evaluation and of 16% success rate in human evaluation on the standard multi-domain benchmark dataset MultiWOZ 2.1, and also outperform the recent state-of-the-art end-to-end trained model from DSTC9.