 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization: A Survey
Mar 31, 2021



Generalization to out-of-distribution (OOD) data is a capability natural to humans yet challenging for machines to reproduce. This is because most statistical learning algorithms strongly rely on the i.i.d.~assumption on source/target data, while in practice domain shift between source and target is common. Domain generalization (DG) aims to achieve OOD generalization by using only source data for model learning. Since first introduced in 2011, research in DG has made great progresses. In particular, intensive research in this topic has led to a broad spectrum of methodologies, e.g., those based on domain alignment, meta-learning, data augmentation, or ensemble learning, just to name a few; and has covered various applications such as object recognition, segmentation, action recognition, and person re-identification. In this paper, for the first time, a comprehensive literature review is provided to summarize the developments in DG in the past decade. Specifically, we first cover the background by formally defining DG and relating it to other research fields like domain adaptation and transfer learning. Second, we conduct a thorough review into existing methods and present a categorization based on their methodologies and motivations. Finally, we conclude this survey with insights and discussions on future research directions.
Cloud2Curve: Generation and Vectorization of Parametric Sketches
Mar 29, 2021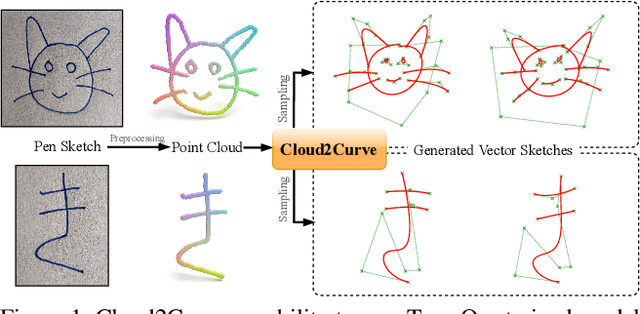
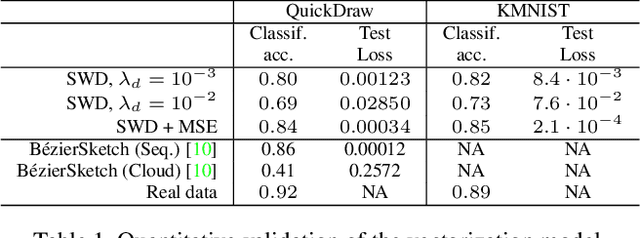
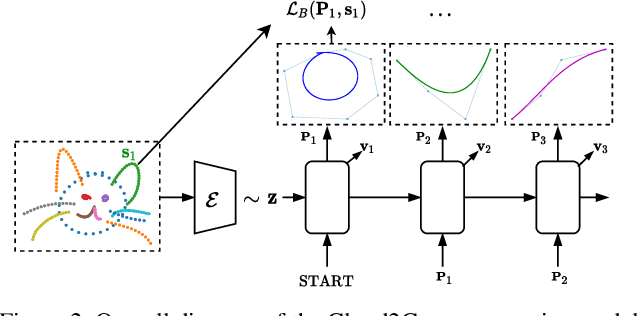
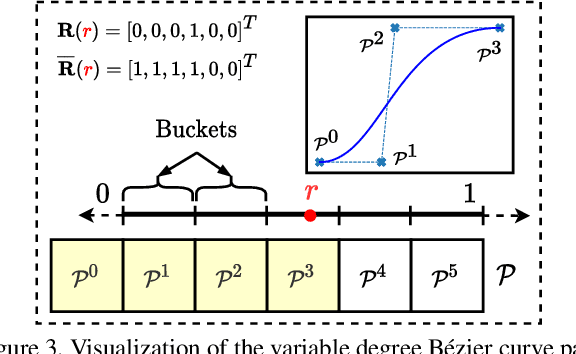
Analysis of human sketches in deep learning has advanced immensely through the use of waypoint-sequences rather than raster-graphic representations. We further aim to model sketches as a sequence of low-dimensional parametric curves. To this end, we propose an inverse graphics framework capable of approximating a raster or waypoint based stroke encoded as a point-cloud with a variable-degree B\'ezier curve. Building on this module, we present Cloud2Curve, a generative model for scalable high-resolution vector sketches that can be trained end-to-end using point-cloud data alone. As a consequence, our model is also capable of deterministic vectorization which can map novel raster or waypoint based sketches to their corresponding high-resolution scalable B\'ezier equivalent. We evaluate the generation and vectorization capabilities of our model on Quick, Draw! and K-MNIST datasets.
More Photos are All You Need: Semi-Supervised Learning for Fine-Grained Sketch Based Image Retrieval
Mar 25, 2021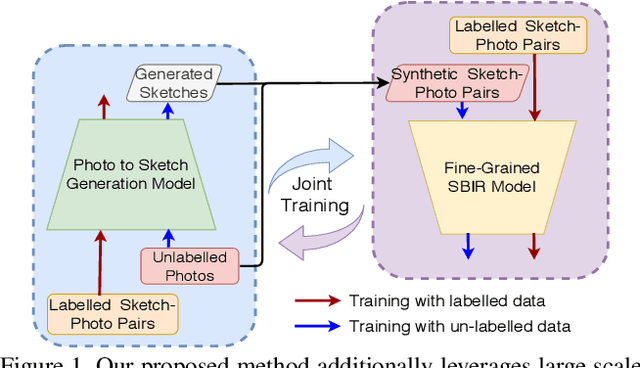
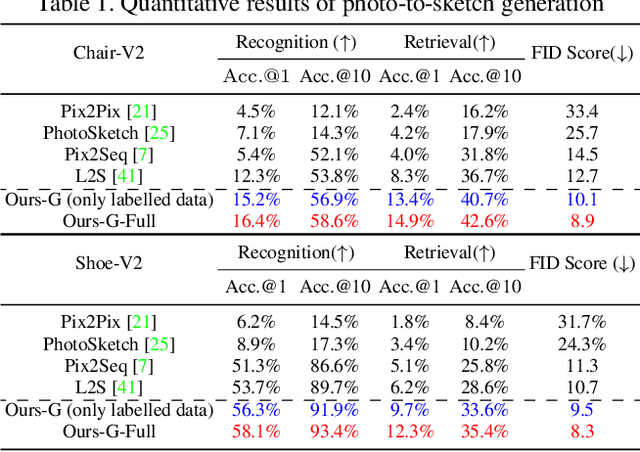
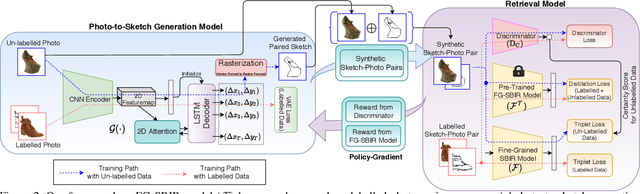
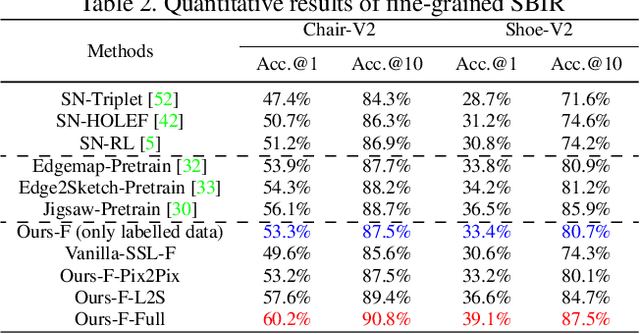
A fundamental challenge faced by existing Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) models is the data scarcity -- model performances are largely bottlenecked by the lack of sketch-photo pairs. Whilst the number of photos can be easily scaled, each corresponding sketch still needs to be individually produced. In this paper, we aim to mitigate such an upper-bound on sketch data, and study whether unlabelled photos alone (of which they are many) can be cultivated for performances gain. In particular, we introduce a novel semi-supervised framework for cross-modal retrieval that can additionally leverage large-scale unlabelled photos to account for data scarcity. At the centre of our semi-supervision design is a sequential photo-to-sketch generation model that aims to generate paired sketches for unlabelled photos. Importantly, we further introduce a discriminator guided mechanism to guide against unfaithful generation, together with a distillation loss based regularizer to provide tolerance against noisy training samples. Last but not least, we treat generation and retrieval as two conjugate problems, where a joint learning procedure is devised for each module to mutually benefit from each other. Extensive experiments show that our semi-supervised model yields significant performance boost over the state-of-the-art supervised alternatives, as well as existing methods that can exploit unlabelled photos for FG-SBIR.
Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting
Mar 25, 2021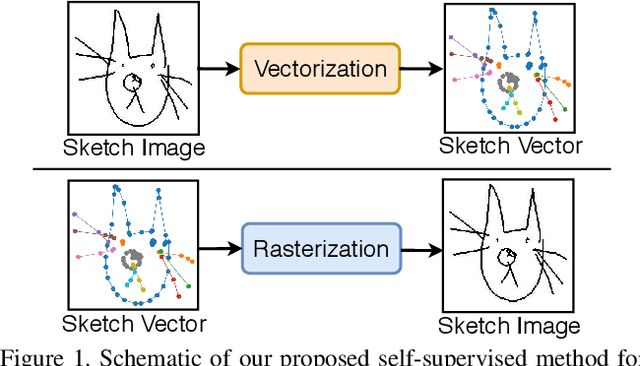
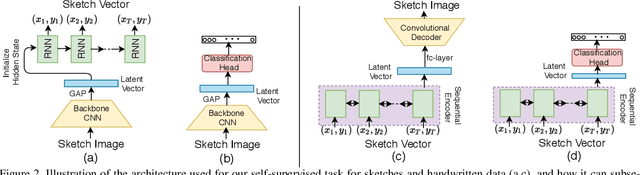
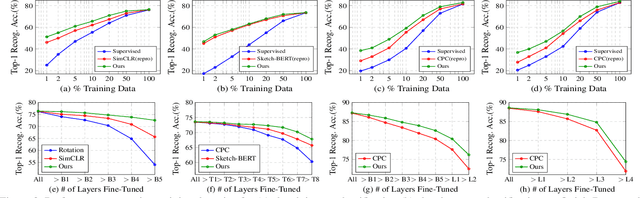
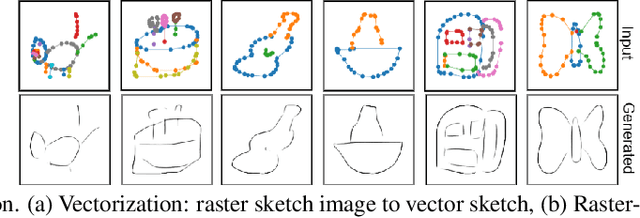
Self-supervised learning has gained prominence due to its efficacy at learning powerful representations from unlabelled data that achieve excellent performance on many challenging downstream tasks. However supervision-free pre-text tasks are challenging to design and usually modality specific. Although there is a rich literature of self-supervised methods for either spatial (such as images) or temporal data (sound or text) modalities, a common pre-text task that benefits both modalities is largely missing. In this paper, we are interested in defining a self-supervised pre-text task for sketches and handwriting data. This data is uniquely characterised by its existence in dual modalities of rasterized images and vector coordinate sequences. We address and exploit this dual representation by proposing two novel cross-modal translation pre-text tasks for self-supervised feature learning: Vectorization and Rasterization. Vectorization learns to map image space to vector coordinates and rasterization maps vector coordinates to image space. We show that the our learned encoder modules benefit both raster-based and vector-based downstream approaches to analysing hand-drawn data. Empirical evidence shows that our novel pre-text tasks surpass existing single and multi-modal self-supervision methods.
Context-Aware Layout to Image Generation with Enhanced Object Appearance
Mar 22, 2021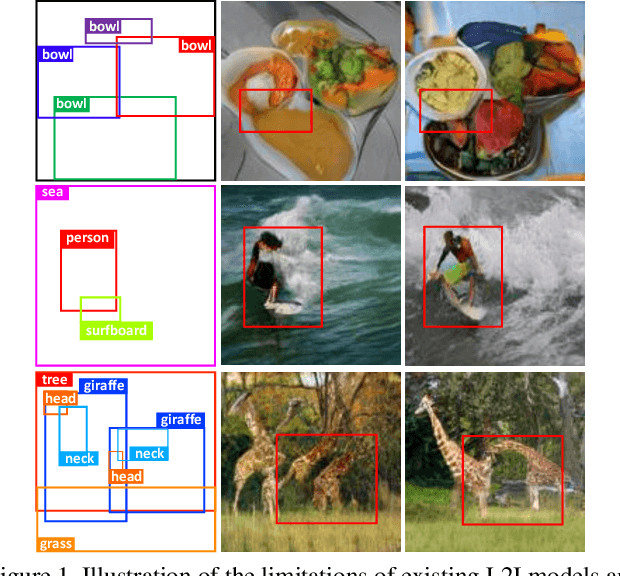
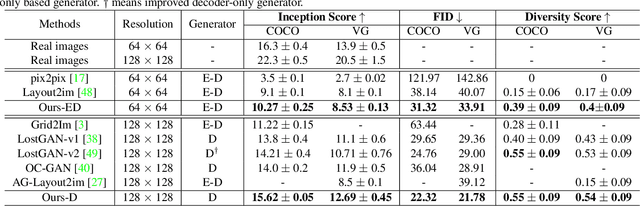
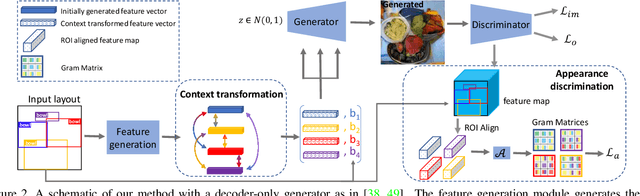

A layout to image (L2I) generation model aims to generate a complicated image containing multiple objects (things) against natural background (stuff), conditioned on a given layout. Built upon the recent advances in generative adversarial networks (GANs), existing L2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) the object-to-object as well as object-to-stuff relations are often broken and (2) each object's appearance is typically distorted lacking the key defining characteristics associated with the object class. We argue that these are caused by the lack of context-aware object and stuff feature encoding in their generators, and location-sensitive appearance representation in their discriminators. To address these limitations, two new modules are proposed in this work. First, a context-aware feature transformation module is introduced in the generator to ensure that the generated feature encoding of either object or stuff is aware of other co-existing objects/stuff in the scene. Second, instead of feeding location-insensitive image features to the discriminator, we use the Gram matrix computed from the feature maps of the generated object images to preserve location-sensitive information, resulting in much enhanced object appearance. Extensive experiments show that the proposed method achieves state-of-the-art performance on the COCO-Thing-Stuff and Visual Genome benchmarks.
Few-shot Action Recognition with Prototype-centered Attentive Learning
Feb 03, 2021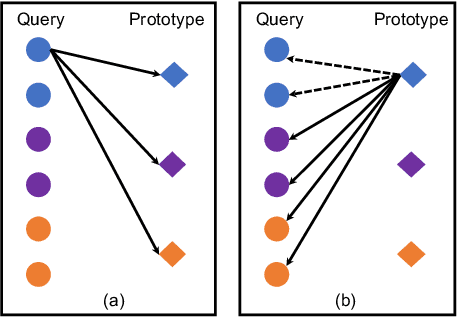
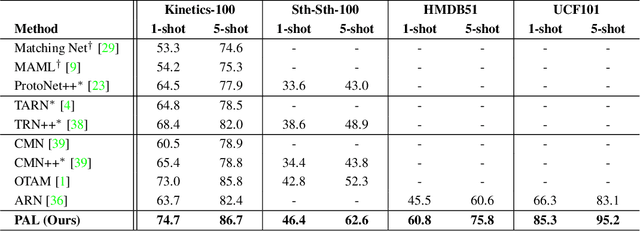
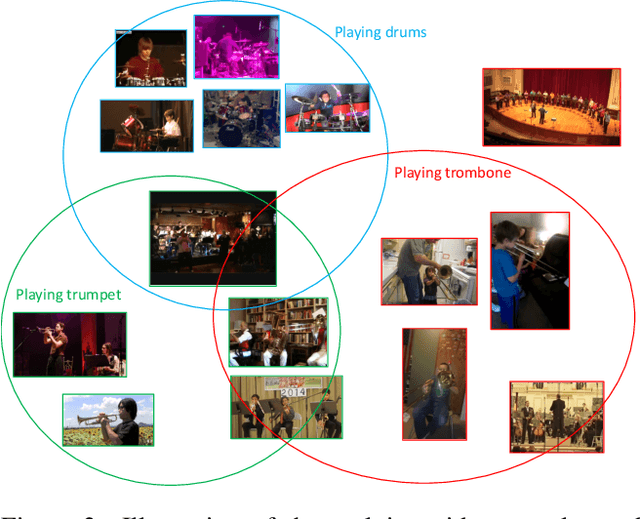
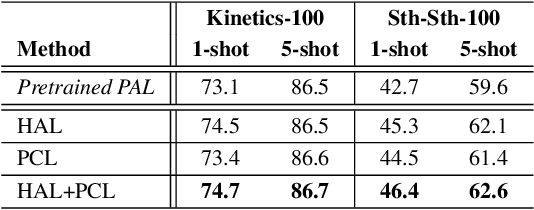
Few-shot action recognition aims to recognize action classes with few training samples. Most existing methods adopt a meta-learning approach with episodic training. In each episode, the few samples in a meta-training task are split into support and query sets. The former is used to build a classifier, which is then evaluated on the latter using a query-centered loss for model updating. There are however two major limitations: lack of data efficiency due to the query-centered only loss design and inability to deal with the support set outlying samples and inter-class distribution overlapping problems. In this paper, we overcome both limitations by proposing a new Prototype-centered Attentive Learning (PAL) model composed of two novel components. First, a prototype-centered contrastive learning loss is introduced to complement the conventional query-centered learning objective, in order to make full use of the limited training samples in each episode. Second, PAL further integrates a hybrid attentive learning mechanism that can minimize the negative impacts of outliers and promote class separation. Extensive experiments on four standard few-shot action benchmarks show that our method clearly outperforms previous state-of-the-art methods, with the improvement particularly significant (10+\%) on the most challenging fine-grained action recognition benchmark.
Contrastive Prototype Learning with Augmented Embeddings for Few-Shot Learning
Jan 23, 2021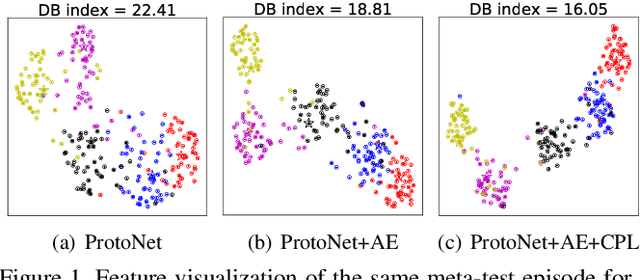
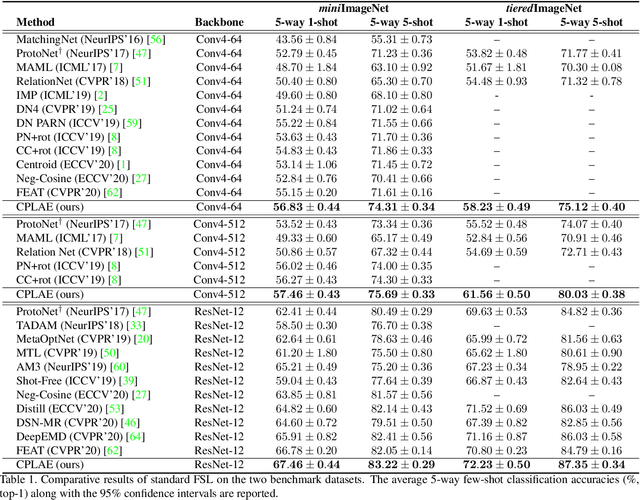
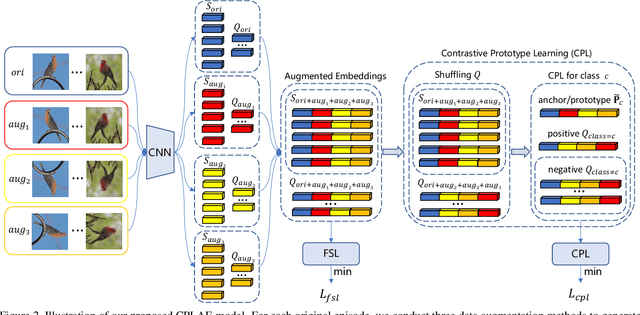

Most recent few-shot learning (FSL) methods are based on meta-learning with episodic training. In each meta-training episode, a discriminative feature embedding and/or classifier are first constructed from a support set in an inner loop, and then evaluated in an outer loop using a query set for model updating. This query set sample centered learning objective is however intrinsically limited in addressing the lack of training data problem in the support set. In this paper, a novel contrastive prototype learning with augmented embeddings (CPLAE) model is proposed to overcome this limitation. First, data augmentations are introduced to both the support and query sets with each sample now being represented as an augmented embedding (AE) composed of concatenated embeddings of both the original and augmented versions. Second, a novel support set class prototype centered contrastive loss is proposed for contrastive prototype learning (CPL). With a class prototype as an anchor, CPL aims to pull the query samples of the same class closer and those of different classes further away. This support set sample centered loss is highly complementary to the existing query centered loss, fully exploiting the limited training data in each episode. Extensive experiments on several benchmarks demonstrate that our proposed CPLAE achieves new state-of-the-art.
Local Black-box Adversarial Attacks: A Query Efficient Approach
Jan 04, 2021

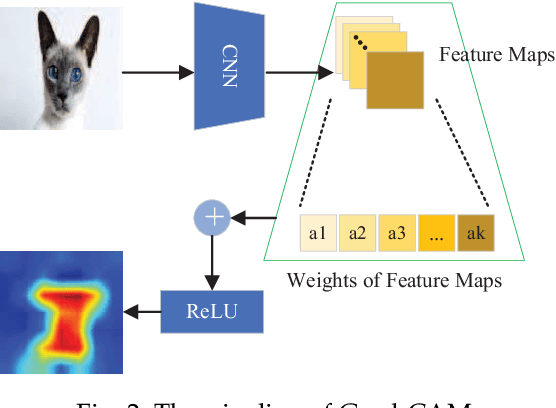

Adversarial attacks have threatened the application of deep neural networks in security-sensitive scenarios. Most existing black-box attacks fool the target model by interacting with it many times and producing global perturbations. However, global perturbations change the smooth and insignificant background, which not only makes the perturbation more easily be perceived but also increases the query overhead. In this paper, we propose a novel framework to perturb the discriminative areas of clean examples only within limited queries in black-box attacks. Our framework is constructed based on two types of transferability. The first one is the transferability of model interpretations. Based on this property, we identify the discriminative areas of a given clean example easily for local perturbations. The second is the transferability of adversarial examples. It helps us to produce a local pre-perturbation for improving query efficiency. After identifying the discriminative areas and pre-perturbing, we generate the final adversarial examples from the pre-perturbed example by querying the targeted model with two kinds of black-box attack techniques, i.e., gradient estimation and random search. We conduct extensive experiments to show that our framework can significantly improve the query efficiency during black-box perturbing with a high attack success rate. Experimental results show that our attacks outperform state-of-the-art black-box attacks under various system settings.
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Dec 31, 2020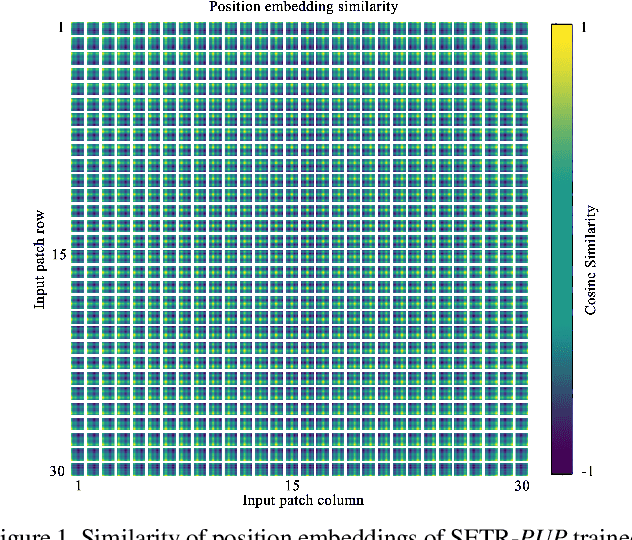



Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first (44.42% mIoU) position in the highly competitive ADE20K test server leaderboard.
Margin-Based Transfer Bounds for Meta Learning with Deep Feature Embedding
Dec 02, 2020
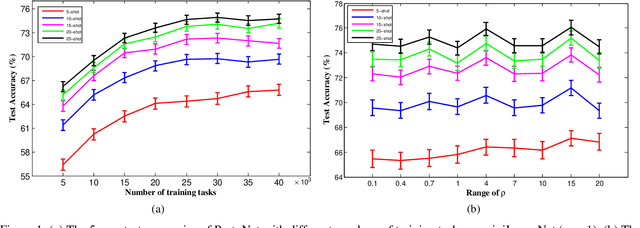

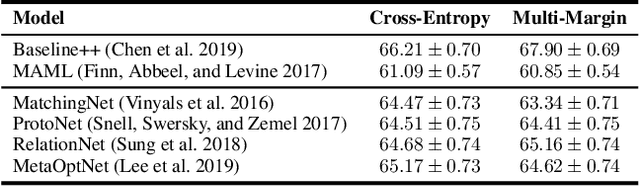
By transferring knowledge learned from seen/previous tasks, meta learning aims to generalize well to unseen/future tasks. Existing meta-learning approaches have shown promising empirical performance on various multiclass classification problems, but few provide theoretical analysis on the classifiers' generalization ability on future tasks. In this paper, under the assumption that all classification tasks are sampled from the same meta-distribution, we leverage margin theory and statistical learning theory to establish three margin-based transfer bounds for meta-learning based multiclass classification (MLMC). These bounds reveal that the expected error of a given classification algorithm for a future task can be estimated with the average empirical error on a finite number of previous tasks, uniformly over a class of preprocessing feature maps/deep neural networks (i.e. deep feature embeddings). To validate these bounds, instead of the commonly-used cross-entropy loss, a multi-margin loss is employed to train a number of representative MLMC models. Experiments on three benchmarks show that these margin-based models still achieve competitive performance, validating the practical value of our margin-based theoretical analysis.