 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore BiLSTM-CRF-Based Models for Open Relation Extraction
Apr 26, 2021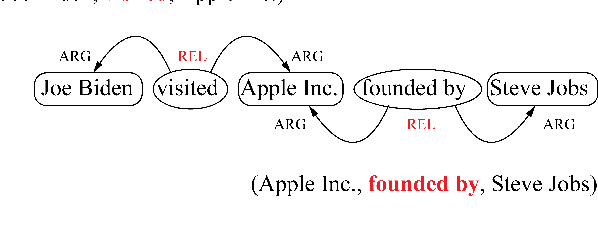
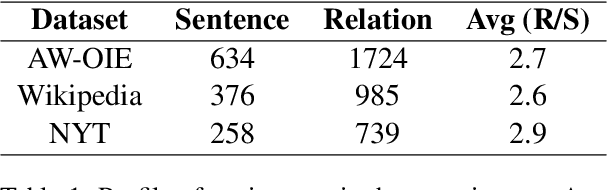
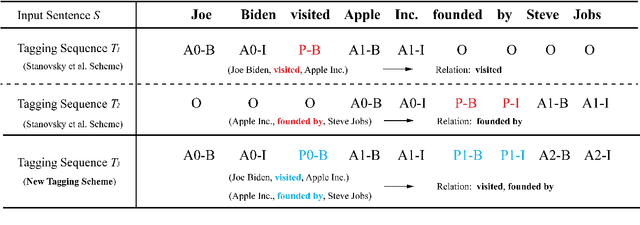

Extracting multiple relations from text sentences is still a challenge for current Open Relation Extraction (Open RE) tasks. In this paper, we develop several Open RE models based on the bidirectional LSTM-CRF (BiLSTM-CRF) neural network and different contextualized word embedding methods. We also propose a new tagging scheme to solve overlapping problems and enhance models' performance. From the evaluation results and comparisons between models, we select the best combination of tagging scheme, word embedder, and BiLSTM-CRF network to achieve an Open RE model with a remarkable extracting ability on multiple-relation sentences.
Learning to Continually Learn Rapidly from Few and Noisy Data
Mar 06, 2021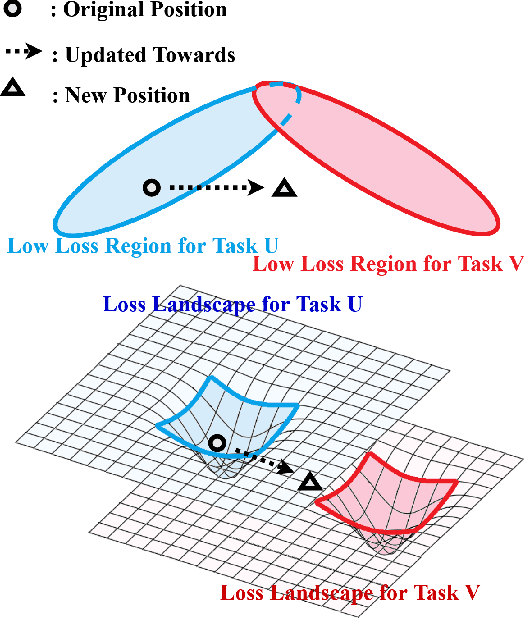
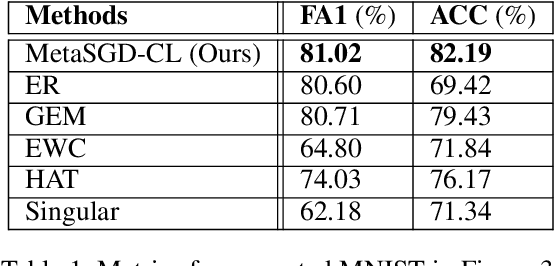
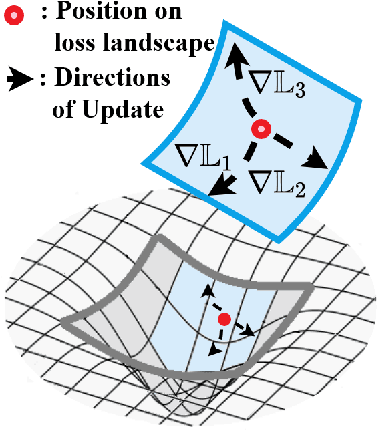
Neural networks suffer from catastrophic forgetting and are unable to sequentially learn new tasks without guaranteed stationarity in data distribution. Continual learning could be achieved via replay -- by concurrently training externally stored old data while learning a new task. However, replay becomes less effective when each past task is allocated with less memory. To overcome this difficulty, we supplemented replay mechanics with meta-learning for rapid knowledge acquisition. By employing a meta-learner, which \textit{learns a learning rate per parameter per past task}, we found that base learners produced strong results when less memory was available. Additionally, our approach inherited several meta-learning advantages for continual learning: it demonstrated strong robustness to continually learn under the presence of noises and yielded base learners to higher accuracy in less updates.
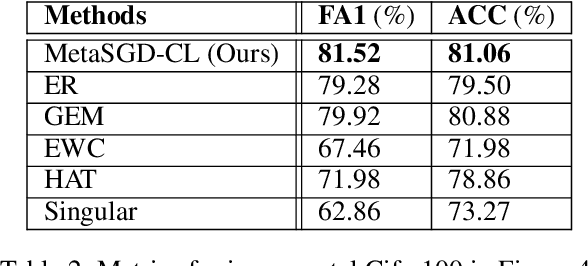
MTL2L: A Context Aware Neural Optimiser
Jul 18, 2020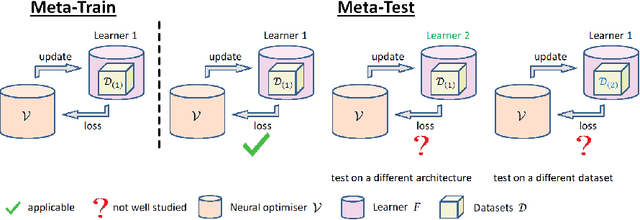

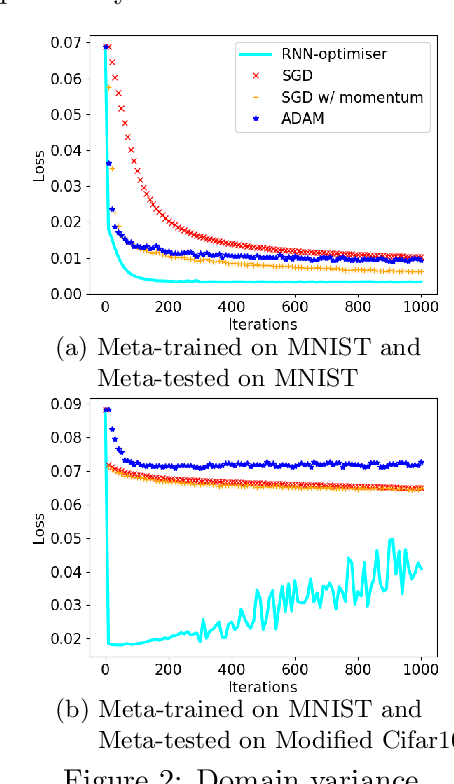
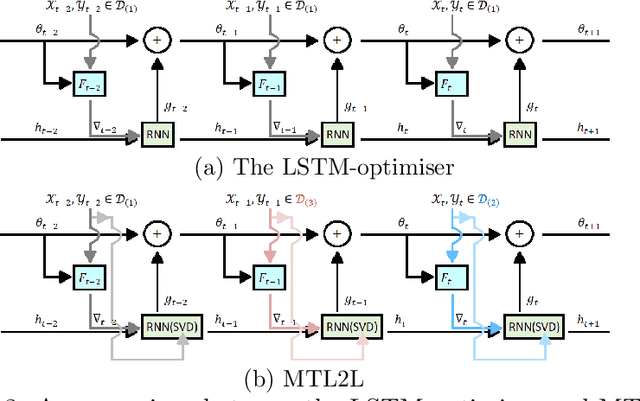
Learning to learn (L2L) trains a meta-learner to assist the learning of a task-specific base learner. Previously, it was shown that a meta-learner could learn the direct rules to update learner parameters; and that the learnt neural optimiser updated learners more rapidly than handcrafted gradient-descent methods. However, we demonstrate that previous neural optimisers were limited to update learners on one designated dataset. In order to address input-domain heterogeneity, we introduce Multi-Task Learning to Learn (MTL2L), a context aware neural optimiser which self-modifies its optimisation rules based on input data. We show that MTL2L is capable of updating learners to classify on data of an unseen input-domain at the meta-testing phase.
Lightme: Analysing Language in Internet Support Groups for Mental Health
Jul 03, 2020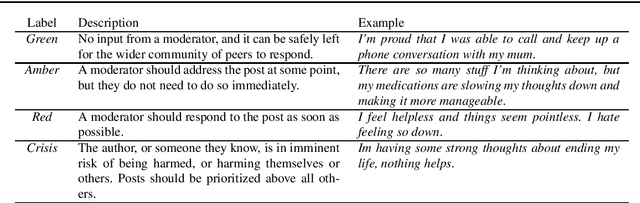
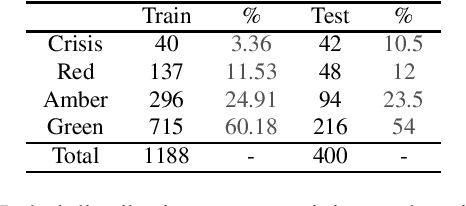
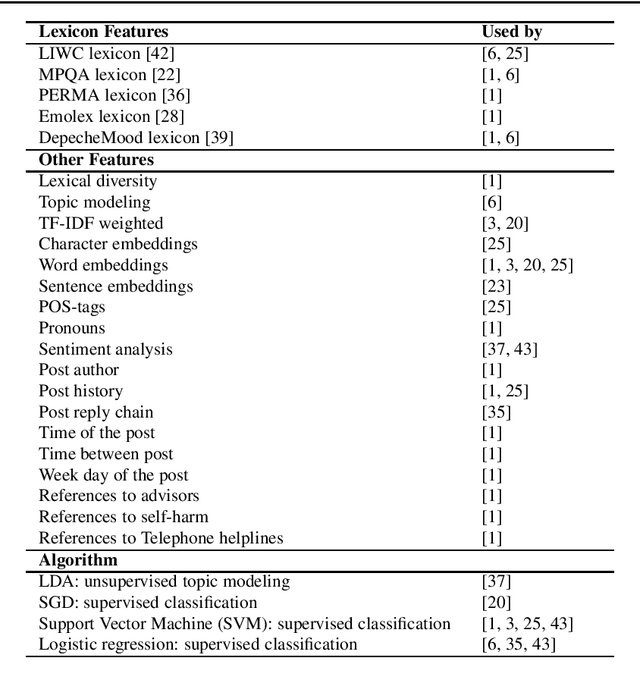
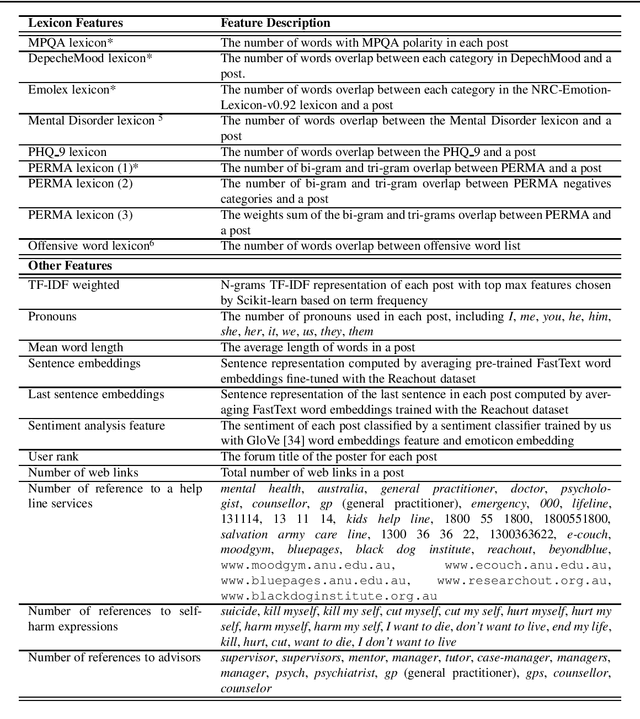
Background: Assisting moderators to triage harmful posts in Internet Support Groups is relevant to ensure its safe use. Automated text classification methods analysing the language expressed in posts of online forums is a promising solution. Methods: Natural Language Processing and Machine Learning technologies were used to build a triage post classifier using a dataset from Reachout mental health forum for young people. Results: When comparing with the state-of-the-art, a solution mainly based on features from lexical resources, received the best classification performance for the crisis posts (52%), which is the most severe class. Six salient linguistic characteristics were found when analysing the crisis post; 1) posts expressing hopelessness, 2) short posts expressing concise negative emotional responses, 3) long posts expressing variations of emotions, 4) posts expressing dissatisfaction with available health services, 5) posts utilising storytelling, and 6) posts expressing users seeking advice from peers during a crisis. Conclusion: It is possible to build a competitive triage classifier using features derived only from the textual content of the post. Further research needs to be done in order to translate our quantitative and qualitative findings into features, as it may improve overall performance.
Named Entity Recognition for Novel Types by Transfer Learning
Oct 31, 2016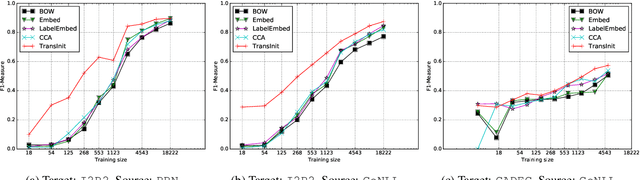
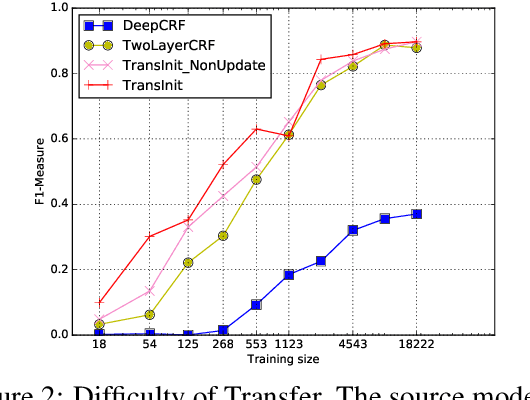
In named entity recognition, we often don't have a large in-domain training corpus or a knowledge base with adequate coverage to train a model directly. In this paper, we propose a method where, given training data in a related domain with similar (but not identical) named entity (NE) types and a small amount of in-domain training data, we use transfer learning to learn a domain-specific NE model. That is, the novelty in the task setup is that we assume not just domain mismatch, but also label mismatch.
Big Data Small Data, In Domain Out-of Domain, Known Word Unknown Word: The Impact of Word Representation on Sequence Labelling Tasks
May 20, 2015
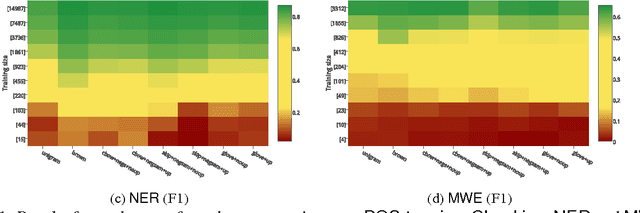

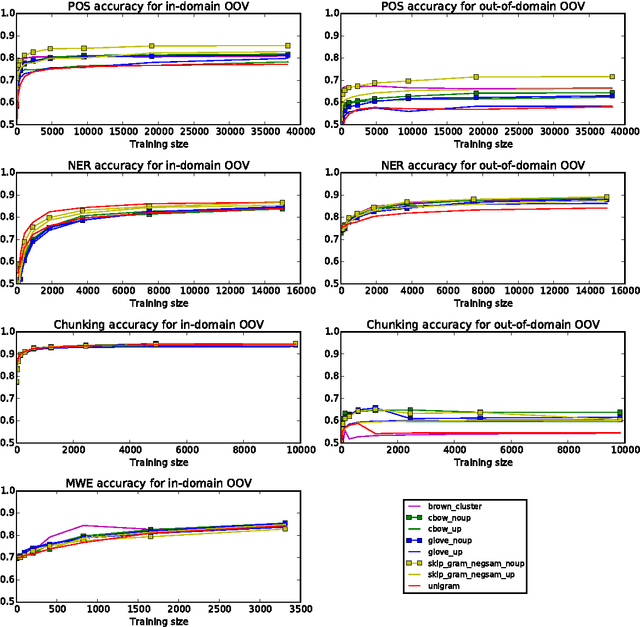
Word embeddings -- distributed word representations that can be learned from unlabelled data -- have been shown to have high utility in many natural language processing applications. In this paper, we perform an extrinsic evaluation of five popular word embedding methods in the context of four sequence labelling tasks: POS-tagging, syntactic chunking, NER and MWE identification. A particular focus of the paper is analysing the effects of task-based updating of word representations. We show that when using word embeddings as features, as few as several hundred training instances are sufficient to achieve competitive results, and that word embeddings lead to improvements over OOV words and out of domain. Perhaps more surprisingly, our results indicate there is little difference between the different word embedding methods, and that simple Brown clusters are often competitive with word embeddings across all tasks we consider.