 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Compositional Visual Coherence for Complementary Recommendations
Jun 08, 2020
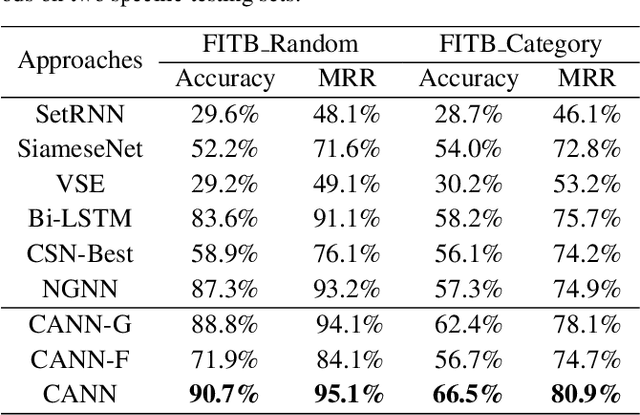
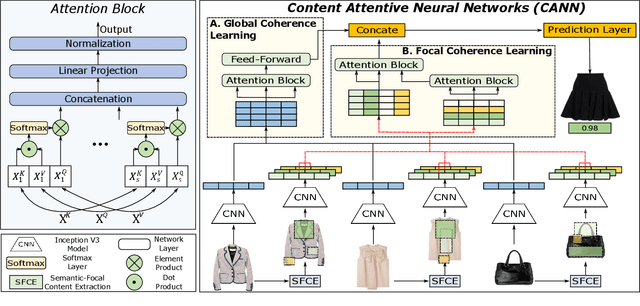
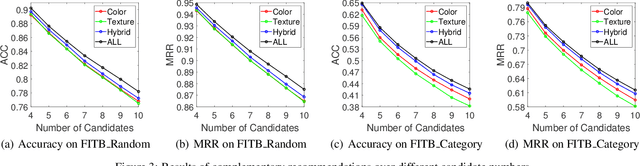
Complementary recommendations, which aim at providing users product suggestions that are supplementary and compatible with their obtained items, have become a hot topic in both academia and industry in recent years. %However, it is challenging due to its complexity and subjectivity. Existing work mainly focused on modeling the co-purchased relations between two items, but the compositional associations of item collections are largely unexplored. Actually, when a user chooses the complementary items for the purchased products, it is intuitive that she will consider the visual semantic coherence (such as color collocations, texture compatibilities) in addition to global impressions. Towards this end, in this paper, we propose a novel Content Attentive Neural Network (CANN) to model the comprehensive compositional coherence on both global contents and semantic contents. Specifically, we first propose a \textit{Global Coherence Learning} (GCL) module based on multi-heads attention to model the global compositional coherence. Then, we generate the semantic-focal representations from different semantic regions and design a \textit{Focal Coherence Learning} (FCL) module to learn the focal compositional coherence from different semantic-focal representations. Finally, we optimize the CANN in a novel compositional optimization strategy. Extensive experiments on the large-scale real-world data clearly demonstrate the effectiveness of CANN compared with several state-of-the-art methods.
Robust Visual Object Tracking with Two-Stream Residual Convolutional Networks
May 13, 2020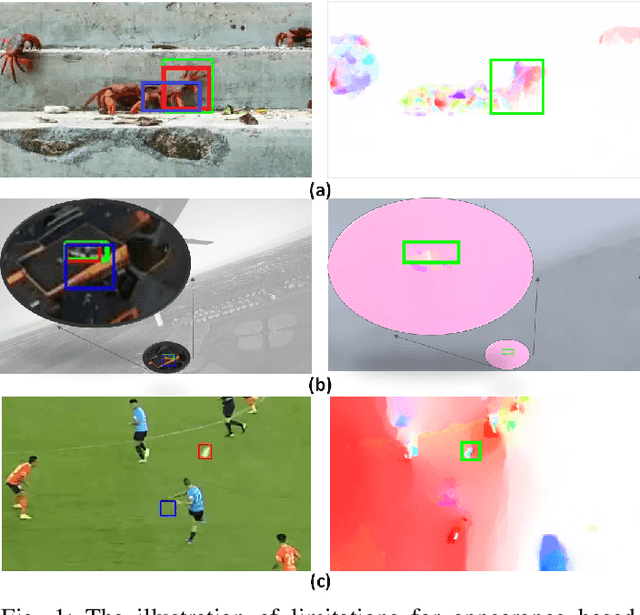
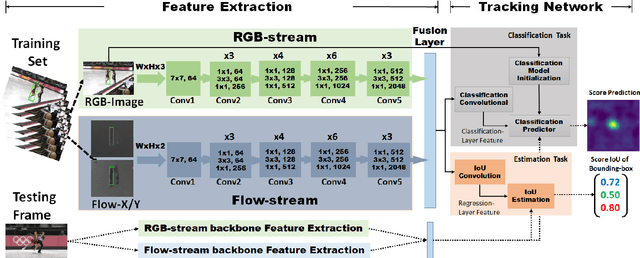

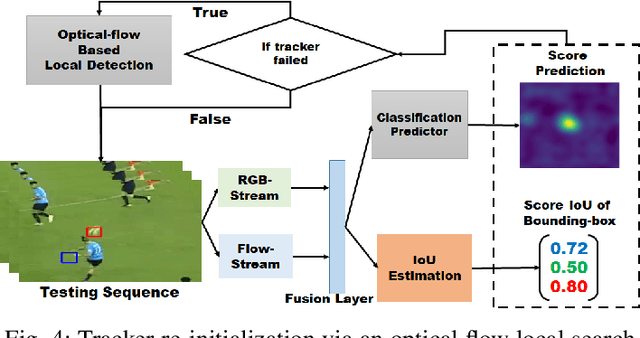
The current deep learning based visual tracking approaches have been very successful by learning the target classification and/or estimation model from a large amount of supervised training data in offline mode. However, most of them can still fail in tracking objects due to some more challenging issues such as dense distractor objects, confusing background, motion blurs, and so on. Inspired by the human "visual tracking" capability which leverages motion cues to distinguish the target from the background, we propose a Two-Stream Residual Convolutional Network (TS-RCN) for visual tracking, which successfully exploits both appearance and motion features for model update. Our TS-RCN can be integrated with existing deep learning based visual trackers. To further improve the tracking performance, we adopt a "wider" residual network ResNeXt as its feature extraction backbone. To the best of our knowledge, TS-RCN is the first end-to-end trainable two-stream visual tracking system, which makes full use of both appearance and motion features of the target. We have extensively evaluated the TS-RCN on most widely used benchmark datasets including VOT2018, VOT2019, and GOT-10K. The experiment results have successfully demonstrated that our two-stream model can greatly outperform the appearance based tracker, and it also achieves state-of-the-art performance. The tracking system can run at up to 38.1 FPS.
VehicleNet: Learning Robust Visual Representation for Vehicle Re-identification
Apr 14, 2020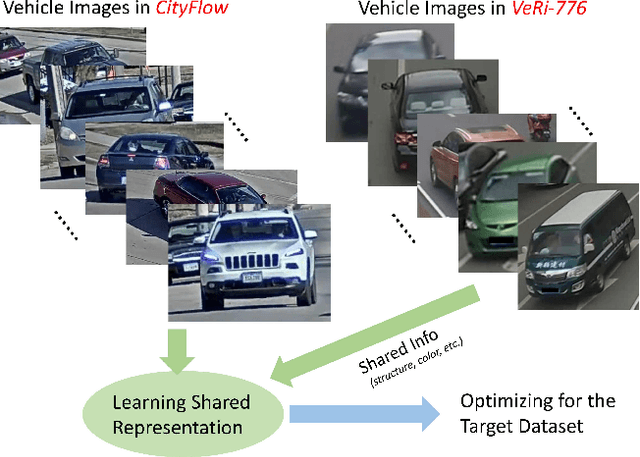
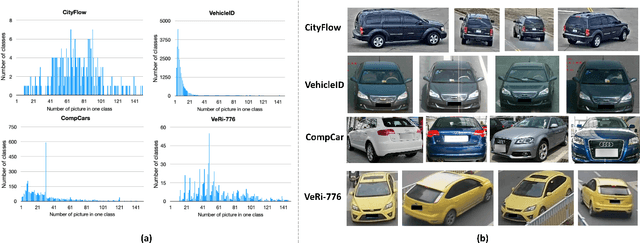
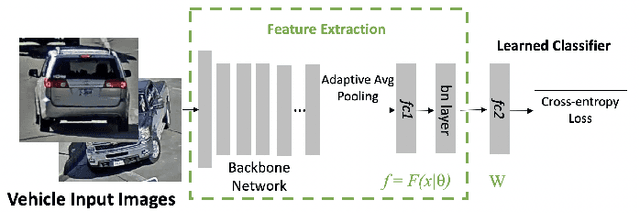
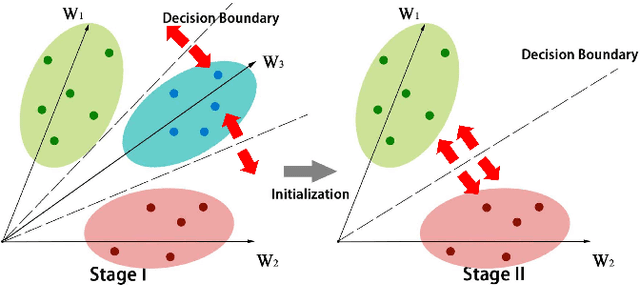
One fundamental challenge of vehicle re-identification (re-id) is to learn robust and discriminative visual representation, given the significant intra-class vehicle variations across different camera views. As the existing vehicle datasets are limited in terms of training images and viewpoints, we propose to build a unique large-scale vehicle dataset (called VehicleNet) by harnessing four public vehicle datasets, and design a simple yet effective two-stage progressive approach to learning more robust visual representation from VehicleNet. The first stage of our approach is to learn the generic representation for all domains (i.e., source vehicle datasets) by training with the conventional classification loss. This stage relaxes the full alignment between the training and testing domains, as it is agnostic to the target vehicle domain. The second stage is to fine-tune the trained model purely based on the target vehicle set, by minimizing the distribution discrepancy between our VehicleNet and any target domain. We discuss our proposed multi-source dataset VehicleNet and evaluate the effectiveness of the two-stage progressive representation learning through extensive experiments. We achieve the state-of-art accuracy of 86.07% mAP on the private test set of AICity Challenge, and competitive results on two other public vehicle re-id datasets, i.e., VeRi-776 and VehicleID. We hope this new VehicleNet dataset and the learned robust representations can pave the way for vehicle re-id in the real-world environments.
Look-into-Object: Self-supervised Structure Modeling for Object Recognition
Mar 31, 2020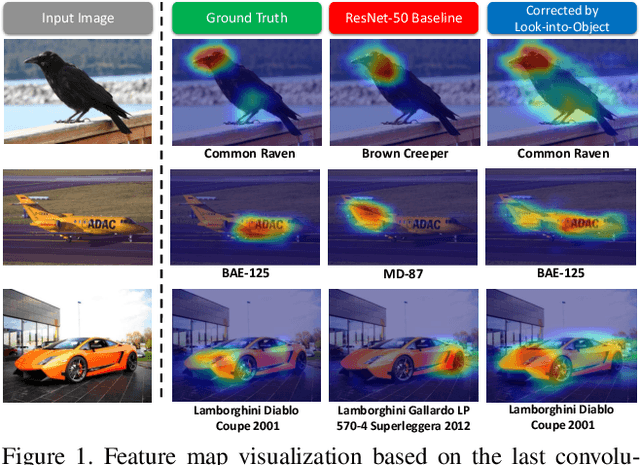
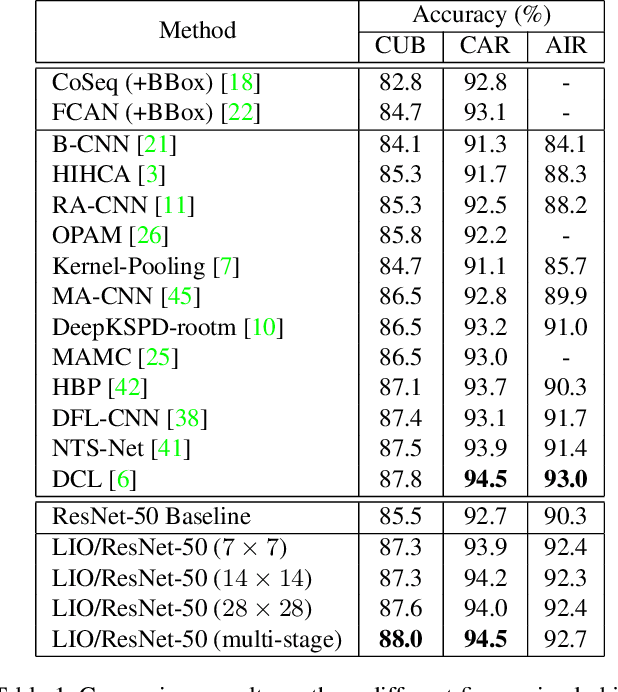
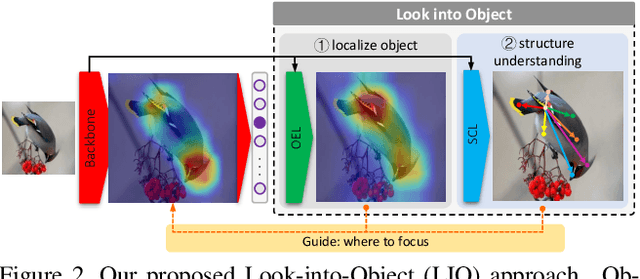

Most object recognition approaches predominantly focus on learning discriminative visual patterns while overlooking the holistic object structure. Though important, structure modeling usually requires significant manual annotations and therefore is labor-intensive. In this paper, we propose to "look into object" (explicitly yet intrinsically model the object structure) through incorporating self-supervisions into the traditional framework. We show the recognition backbone can be substantially enhanced for more robust representation learning, without any cost of extra annotation and inference speed. Specifically, we first propose an object-extent learning module for localizing the object according to the visual patterns shared among the instances in the same category. We then design a spatial context learning module for modeling the internal structures of the object, through predicting the relative positions within the extent. These two modules can be easily plugged into any backbone networks during training and detached at inference time. Extensive experiments show that our look-into-object approach (LIO) achieves large performance gain on a number of benchmarks, including generic object recognition (ImageNet) and fine-grained object recognition tasks (CUB, Cars, Aircraft). We also show that this learning paradigm is highly generalizable to other tasks such as object detection and segmentation (MS COCO). Project page: https://github.com/JDAI-CV/LIO.
X-Linear Attention Networks for Image Captioning
Mar 31, 2020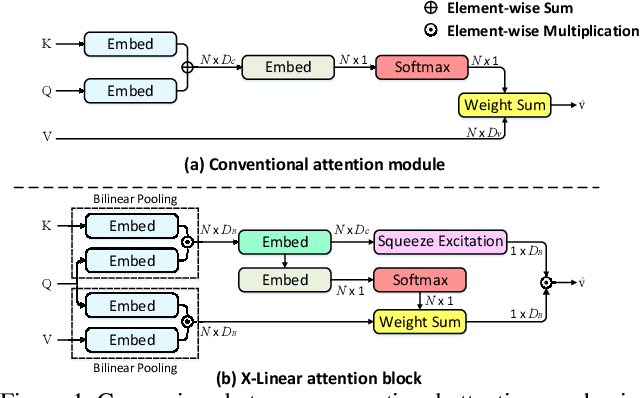
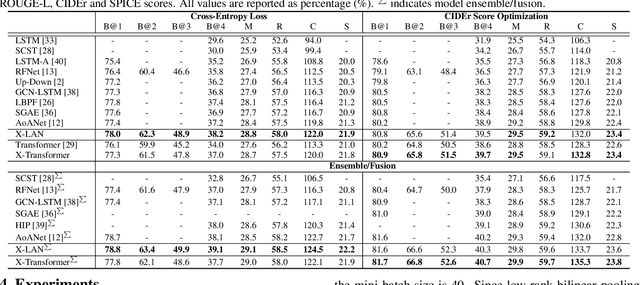
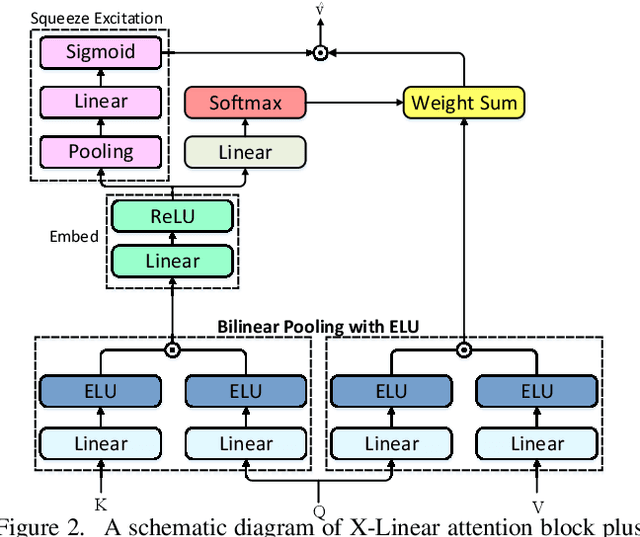
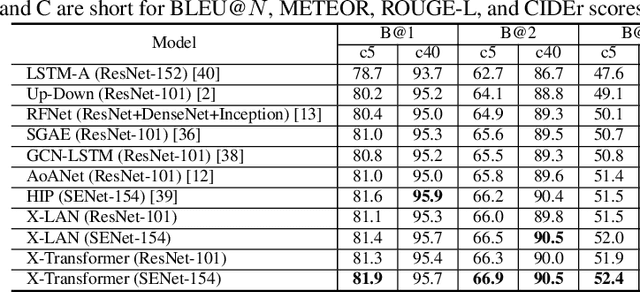
Recent progress on fine-grained visual recognition and visual question answering has featured Bilinear Pooling, which effectively models the 2$^{nd}$ order interactions across multi-modal inputs. Nevertheless, there has not been evidence in support of building such interactions concurrently with attention mechanism for image captioning. In this paper, we introduce a unified attention block -- X-Linear attention block, that fully employs bilinear pooling to selectively capitalize on visual information or perform multi-modal reasoning. Technically, X-Linear attention block simultaneously exploits both the spatial and channel-wise bilinear attention distributions to capture the 2$^{nd}$ order interactions between the input single-modal or multi-modal features. Higher and even infinity order feature interactions are readily modeled through stacking multiple X-Linear attention blocks and equipping the block with Exponential Linear Unit (ELU) in a parameter-free fashion, respectively. Furthermore, we present X-Linear Attention Networks (dubbed as X-LAN) that novelly integrates X-Linear attention block(s) into image encoder and sentence decoder of image captioning model to leverage higher order intra- and inter-modal interactions. The experiments on COCO benchmark demonstrate that our X-LAN obtains to-date the best published CIDEr performance of 132.0% on COCO Karpathy test split. When further endowing Transformer with X-Linear attention blocks, CIDEr is boosted up to 132.8%. Source code is available at \url{https://github.com/Panda-Peter/image-captioning}.
Long Short-Term Relation Networks for Video Action Detection
Mar 31, 2020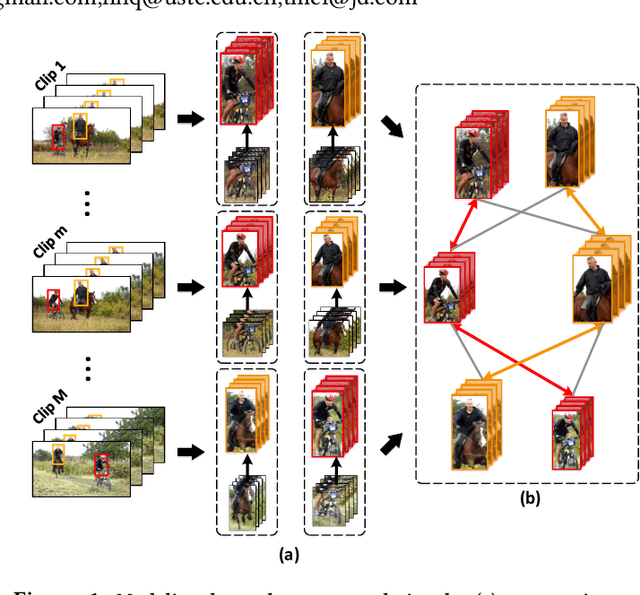
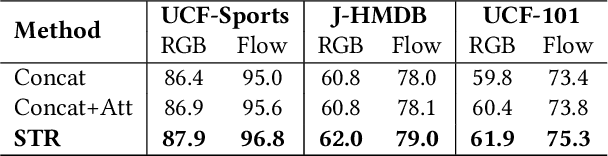
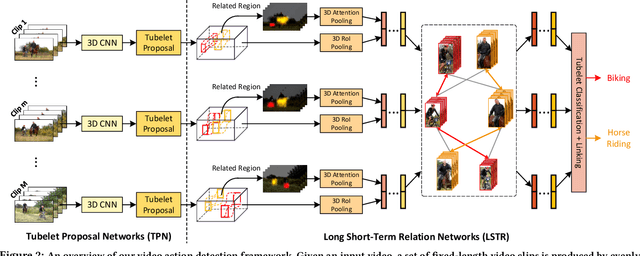
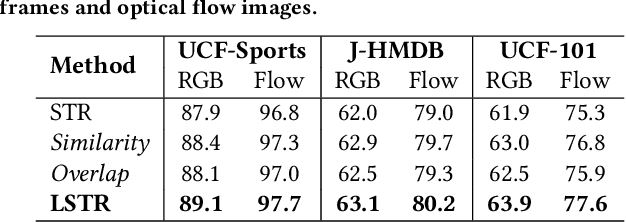
It has been well recognized that modeling human-object or object-object relations would be helpful for detection task. Nevertheless, the problem is not trivial especially when exploring the interactions between human actor, object and scene (collectively as human-context) to boost video action detectors. The difficulty originates from the aspect that reliable relations in a video should depend on not only short-term human-context relation in the present clip but also the temporal dynamics distilled over a long-range span of the video. This motivates us to capture both short-term and long-term relations in a video. In this paper, we present a new Long Short-Term Relation Networks, dubbed as LSTR, that novelly aggregates and propagates relation to augment features for video action detection. Technically, Region Proposal Networks (RPN) is remoulded to first produce 3D bounding boxes, i.e., tubelets, in each video clip. LSTR then models short-term human-context interactions within each clip through spatio-temporal attention mechanism and reasons long-term temporal dynamics across video clips via Graph Convolutional Networks (GCN) in a cascaded manner. Extensive experiments are conducted on four benchmark datasets, and superior results are reported when comparing to state-of-the-art methods.
Adaptive Semantic-Visual Tree for Hierarchical Embeddings
Mar 08, 2020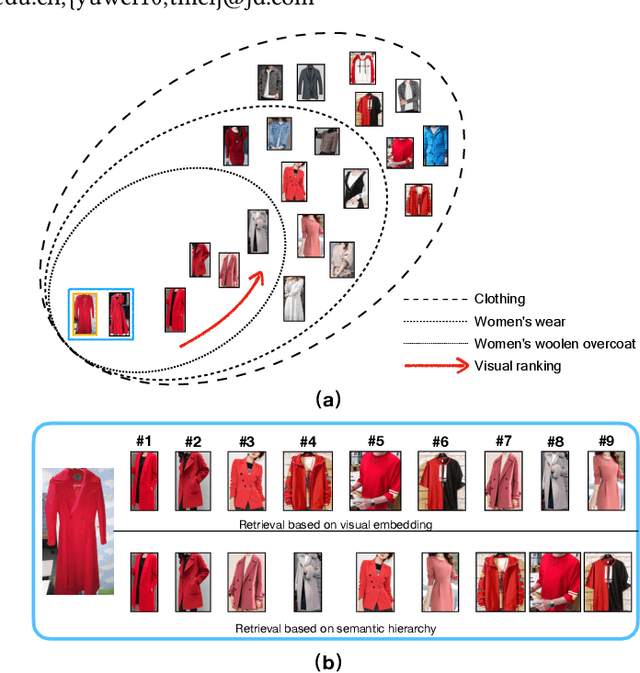
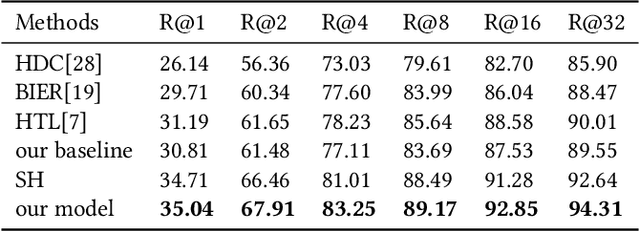

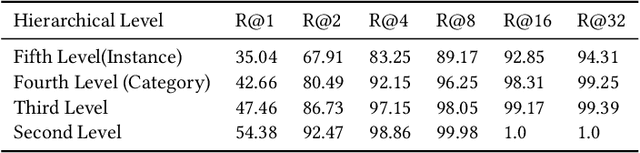
Merchandise categories inherently form a semantic hierarchy with different levels of concept abstraction, especially for fine-grained categories. This hierarchy encodes rich correlations among various categories across different levels, which can effectively regularize the semantic space and thus make predictions less ambiguous. However, previous studies of fine-grained image retrieval primarily focus on semantic similarities or visual similarities. In a real application, merely using visual similarity may not satisfy the need of consumers to search merchandise with real-life images, e.g., given a red coat as a query image, we might get a red suit in recall results only based on visual similarity since they are visually similar. But the users actually want a coat rather than suit even the coat is with different color or texture attributes. We introduce this new problem based on photoshopping in real practice. That's why semantic information are integrated to regularize the margins to make "semantic" prior to "visual". To solve this new problem, we propose a hierarchical adaptive semantic-visual tree (ASVT) to depict the architecture of merchandise categories, which evaluates semantic similarities between different semantic levels and visual similarities within the same semantic class simultaneously. The semantic information satisfies the demand of consumers for similar merchandise with the query while the visual information optimizes the correlations within the semantic class. At each level, we set different margins based on the semantic hierarchy and incorporate them as prior information to learn a fine-grained feature embedding. To evaluate our framework, we propose a new dataset named JDProduct, with hierarchical labels collected from actual image queries and official merchandise images on an online shopping application. Extensive experimental results on the public CARS196 and CUB-
Down to the Last Detail: Virtual Try-on with Detail Carving
Jan 03, 2020
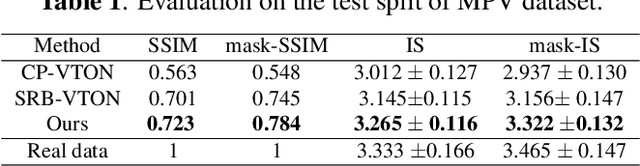
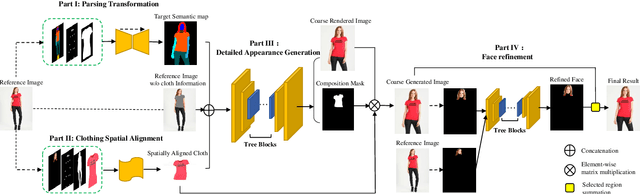
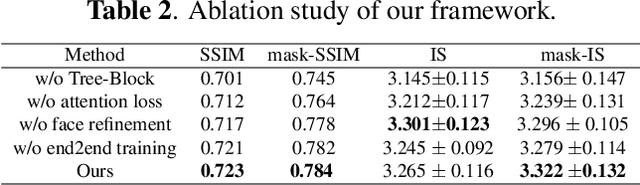
Virtual try-on under arbitrary poses has attracted lots of research attention due to its huge potential applications. However, existing methods can hardly preserve the details in clothing texture and facial identity (face, hair) while fitting novel clothes and poses onto a person. In this paper, we propose a novel multi-stage framework to synthesize person images, where rich details in salient regions can be well preserved. Specifically, a multi-stage framework is proposed to decompose the generation into spatial alignment followed by a coarse-to-fine generation. To better preserve the details in salient areas such as clothing and facial areas, we propose a Tree-Block (tree dilated fusion block) to harness multi-scale features in the generator networks. With end-to-end training of multiple stages, the whole framework can be jointly optimized for results with significantly better visual fidelity and richer details. Extensive experiments on standard datasets demonstrate that our proposed framework achieves the state-of-the-art performance, especially in preserving the visual details in clothing texture and facial identity. Our implementation will be publicly available soon.
Theme-Matters: Fashion Compatibility Learning via Theme Attention
Dec 26, 2019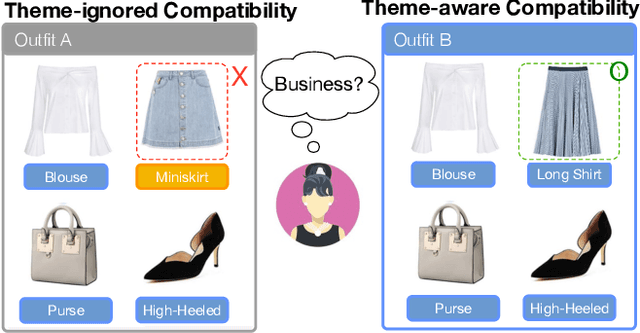
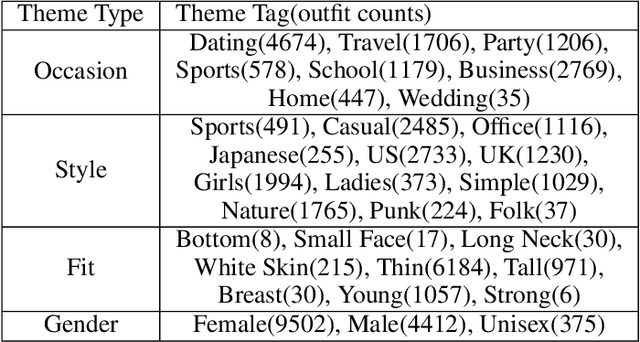
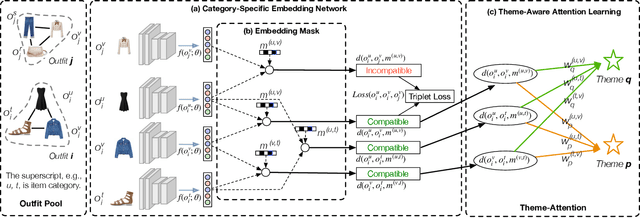
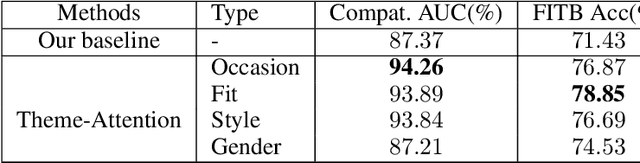
Fashion compatibility learning is important to many fashion markets such as outfit composition and online fashion recommendation. Unlike previous work, we argue that fashion compatibility is not only a visual appearance compatible problem but also a theme-matters problem. An outfit, which consists of a set of fashion items (e.g., shirt, suit, shoes, etc.), is considered to be compatible for a "dating" event, yet maybe not for a "business" occasion. In this paper, we aim at solving the fashion compatibility problem given specific themes. To this end, we built the first real-world theme-aware fashion dataset comprising 14K around outfits labeled with 32 themes. In this dataset, there are more than 40K fashion items labeled with 152 fine-grained categories. We also propose an attention model learning fashion compatibility given a specific theme. It starts with a category-specific subspace learning, which projects compatible outfit items in certain categories to be close in the subspace. Thanks to strong connections between fashion themes and categories, we then build a theme-attention model over the category-specific embedding space. This model associates themes with the pairwise compatibility with attention, and thus compute the outfit-wise compatibility. To the best of our knowledge, this is the first attempt to estimate outfit compatibility conditional on a theme. We conduct extensive qualitative and quantitative experiments on our new dataset. Our method outperforms the state-of-the-art approaches.
Vision and Language: from Visual Perception to Content Creation
Dec 26, 2019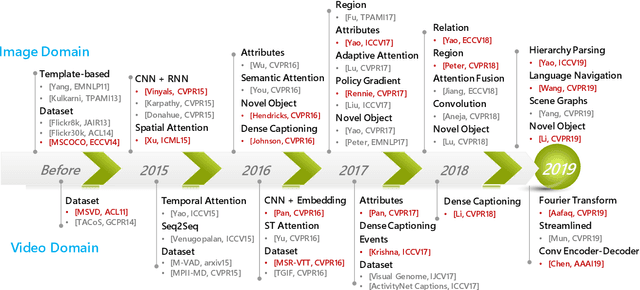
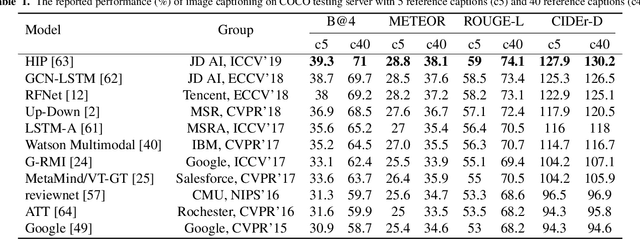
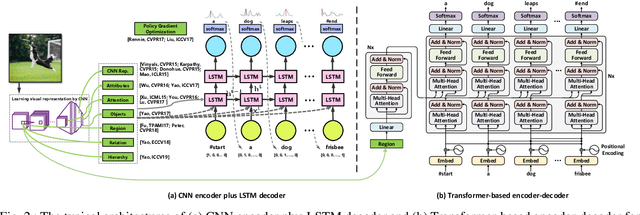

Vision and language are two fundamental capabilities of human intelligence. Humans routinely perform tasks through the interactions between vision and language, supporting the uniquely human capacity to talk about what they see or hallucinate a picture on a natural-language description. The valid question of how language interacts with vision motivates us researchers to expand the horizons of computer vision area. In particular, "vision to language" is probably one of the most popular topics in the past five years, with a significant growth in both volume of publications and extensive applications, e.g., captioning, visual question answering, visual dialog, language navigation, etc. Such tasks boost visual perception with more comprehensive understanding and diverse linguistic representations. Going beyond the progresses made in "vision to language," language can also contribute to vision understanding and offer new possibilities of visual content creation, i.e., "language to vision." The process performs as a prism through which to create visual content conditioning on the language inputs. This paper reviews the recent advances along these two dimensions: "vision to language" and "language to vision." More concretely, the former mainly focuses on the development of image/video captioning, as well as typical encoder-decoder structures and benchmarks, while the latter summarizes the technologies of visual content creation. The real-world deployment or services of vision and language are elaborated as well.