 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn ASR-free Fluency Scoring Approach with Self-Supervised Learning
Mar 13, 2023



A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
Leveraging phone-level linguistic-acoustic similarity for utterance-level pronunciation scoring
Mar 13, 2023



Recent studies on pronunciation scoring have explored the effect of introducing phone embeddings as reference pronunciation, but mostly in an implicit manner, i.e., addition or concatenation of reference phone embedding and actual pronunciation of the target phone as the phone-level pronunciation quality representation. In this paper, we propose to use linguistic-acoustic similarity to explicitly measure the deviation of non-native production from its native reference for pronunciation assessment. Specifically, the deviation is first estimated by the cosine similarity between reference phone embedding and corresponding acoustic embedding. Next, a phone-level Goodness of pronunciation (GOP) pre-training stage is introduced to guide this similarity-based learning for better initialization of the aforementioned two embeddings. Finally, a transformer-based hierarchical pronunciation scorer is used to map a sequence of phone embeddings, acoustic embeddings along with their similarity measures to predict the final utterance-level score. Experimental results on the non-native databases suggest that the proposed system significantly outperforms the baselines, where the acoustic and phone embeddings are simply added or concatenated. A further examination shows that the phone embeddings learned in the proposed approach are able to capture linguistic-acoustic attributes of native pronunciation as reference.
Covariance Regularization for Probabilistic Linear Discriminant Analysis
Dec 06, 2022Probabilistic linear discriminant analysis (PLDA) is commonly used in speaker verification systems to score the similarity of speaker embeddings. Recent studies improved the performance of PLDA in domain-matched conditions by diagonalizing its covariance. We suspect such brutal pruning approach could eliminate its capacity in modeling dimension correlation of speaker embeddings, leading to inadequate performance with domain adaptation. This paper explores two alternative covariance regularization approaches, namely, interpolated PLDA and sparse PLDA, to tackle the problem. The interpolated PLDA incorporates the prior knowledge from cosine scoring to interpolate the covariance of PLDA. The sparse PLDA introduces a sparsity penalty to update the covariance. Experimental results demonstrate that both approaches outperform diagonal regularization noticeably with domain adaptation. In addition, in-domain data can be significantly reduced when training sparse PLDA for domain adaptation.
Label-free Knowledge Distillation with Contrastive Loss for Light-weight Speaker Recognition
Dec 06, 2022Very deep models for speaker recognition (SR) have demonstrated remarkable performance improvement in recent research. However, it is impractical to deploy these models for on-device applications with constrained computational resources. On the other hand, light-weight models are highly desired in practice despite their sub-optimal performance. This research aims to improve light-weight SR models through large-scale label-free knowledge distillation (KD). Existing KD approaches for SR typically require speaker labels to learn task-specific knowledge, due to the inefficiency of conventional loss for distillation. To address the inefficiency problem and achieve label-free KD, we propose to employ the contrastive loss from self-supervised learning for distillation. Extensive experiments are conducted on a collection of public speech datasets from diverse sources. Results on light-weight SR models show that the proposed approach of label-free KD with contrastive loss consistently outperforms both conventional distillation methods and self-supervised learning methods by a significant margin.
Model Compression for DNN-Based Text-Independent Speaker Verification Using Weight Quantization
Nov 14, 2022



DNN-based models achieve high performance in the speaker verification (SV) task with substantial computation costs. The model size is an essential concern in applying models on resource-constrained devices, while model compression for SV models has not been studied extensively in previous works. Weight quantization is exploited to compress DNN-based speaker embedding extraction models in this paper. Uniform and Powers-of-Two quantization are utilized in the experiments. The results on VoxCeleb show that the weight quantization can decrease the size of ECAPA-TDNN and ResNet by 4 times with insignificant performance decline. The quantized 4-bit ResNet achieves similar performance to the original model with an 8 times smaller size. We empirically show that the performance of ECAPA-TDNN is more sensitive than ResNet to quantization due to the difference in weight distribution. The experiments on CN-Celeb also demonstrate that quantized models are robust for SV in the language mismatch scenario.
Convolution-Based Channel-Frequency Attention for Text-Independent Speaker Verification
Oct 31, 2022



Deep convolutional neural networks (CNNs) have been applied to extracting speaker embeddings with significant success in speaker verification. Incorporating the attention mechanism has shown to be effective in improving the model performance. This paper presents an efficient two-dimensional convolution-based attention module, namely C2D-Att. The interaction between the convolution channel and frequency is involved in the attention calculation by lightweight convolution layers. This requires only a small number of parameters. Fine-grained attention weights are produced to represent channel and frequency-specific information. The weights are imposed on the input features to improve the representation ability for speaker modeling. The C2D-Att is integrated into a modified version of ResNet for speaker embedding extraction. Experiments are conducted on VoxCeleb datasets. The results show that C2DAtt is effective in generating discriminative attention maps and outperforms other attention methods. The proposed model shows robust performance with different scales of model size and achieves state-of-the-art results.
iEmoTTS: Toward Robust Cross-Speaker Emotion Transfer and Control for Speech Synthesis based on Disentanglement between Prosody and Timbre
Jun 29, 2022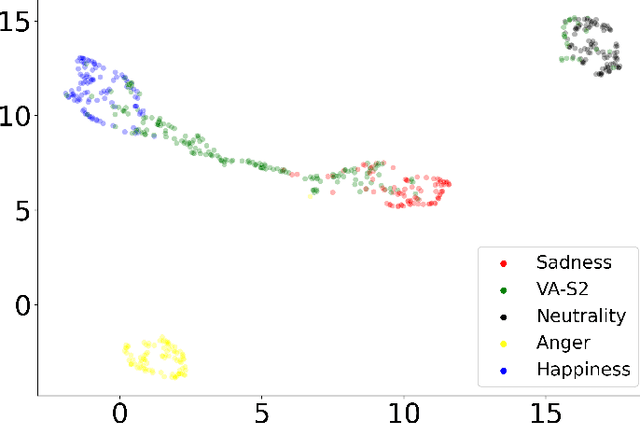
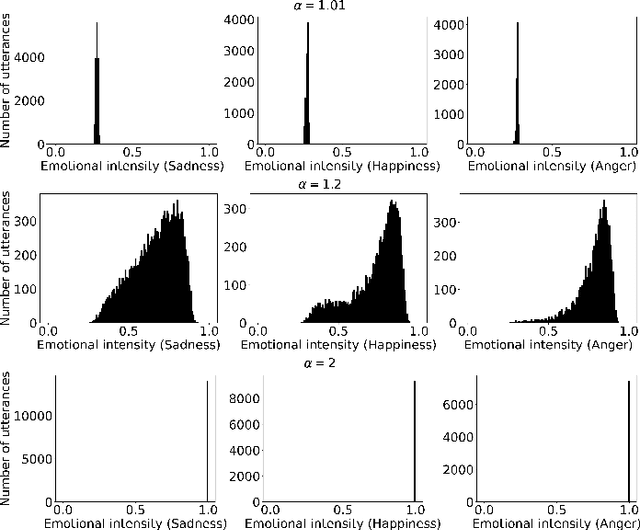
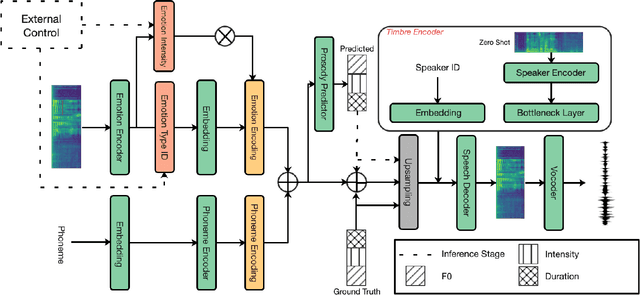
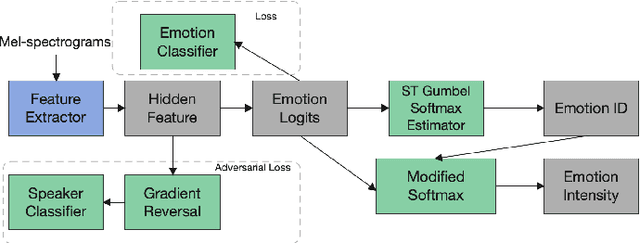
The capability of generating speech with specific type of emotion is desired for many applications of human-computer interaction. Cross-speaker emotion transfer is a common approach to generating emotional speech when speech with emotion labels from target speakers is not available for model training. This paper presents a novel cross-speaker emotion transfer system, named iEmoTTS. The system is composed of an emotion encoder, a prosody predictor, and a timbre encoder. The emotion encoder extracts the identity of emotion type as well as the respective emotion intensity from the mel-spectrogram of input speech. The emotion intensity is measured by the posterior probability that the input utterance carries that emotion. The prosody predictor is used to provide prosodic features for emotion transfer. The timber encoder provides timbre-related information for the system. Unlike many other studies which focus on disentangling speaker and style factors of speech, the iEmoTTS is designed to achieve cross-speaker emotion transfer via disentanglement between prosody and timbre. Prosody is considered as the main carrier of emotion-related speech characteristics and timbre accounts for the essential characteristics for speaker identification. Zero-shot emotion transfer, meaning that speech of target speakers are not seen in model training, is also realized with iEmoTTS. Extensive experiments of subjective evaluation have been carried out. The results demonstrate the effectiveness of iEmoTTS as compared with other recently proposed systems of cross-speaker emotion transfer. It is shown that iEmoTTS can produce speech with designated emotion type and controllable emotion intensity. With appropriate information bottleneck capacity, iEmoTTS is able to effectively transfer emotion information to a new speaker. Audio samples are publicly available\footnote{https://patrick-g-zhang.github.io/iemotts/}.
iExam: A Novel Online Exam Monitoring and Analysis System Based on Face Detection and Recognition
Jun 27, 2022
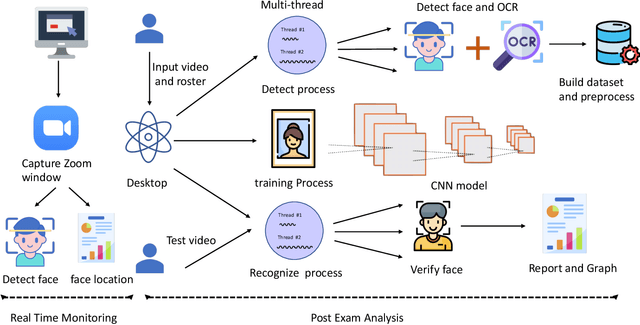
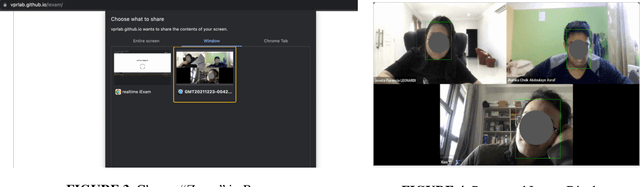

Online exams via video conference software like Zoom have been adopted in many schools due to COVID-19. While it is convenient, it is challenging for teachers to supervise online exams from simultaneously displayed student Zoom windows. In this paper, we propose iExam, an intelligent online exam monitoring and analysis system that can not only use face detection to assist invigilators in real-time student identification, but also be able to detect common abnormal behaviors (including face disappearing, rotating faces, and replacing with a different person during the exams) via a face recognition-based post-exam video analysis. To build such a novel system in its first kind, we overcome three challenges. First, we discover a lightweight approach to capturing exam video streams and analyzing them in real time. Second, we utilize the left-corner names that are displayed on each student's Zoom window and propose an improved OCR (optical character recognition) technique to automatically gather the ground truth for the student faces with dynamic positions. Third, we perform several experimental comparisons and optimizations to efficiently shorten the training and testing time required on teachers' PC. Our evaluation shows that iExam achieves high accuracy, 90.4% for real-time face detection and 98.4% for post-exam face recognition, while maintaining acceptable runtime performance. We have made iExam's source code available at https://github.com/VPRLab/iExam.
Transport-Oriented Feature Aggregation for Speaker Embedding Learning
Jun 26, 2022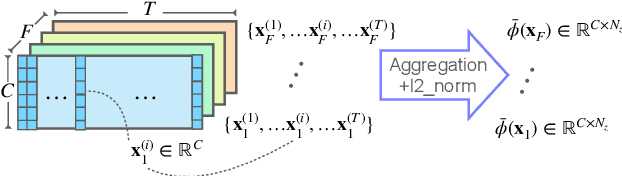

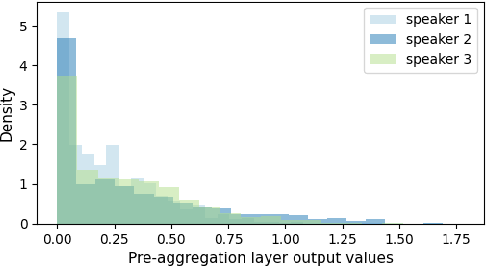
Pooling is needed to aggregate frame-level features into utterance-level representations for speaker modeling. Given the success of statistics-based pooling methods, we hypothesize that speaker characteristics are well represented in the statistical distribution over the pre-aggregation layer's output, and propose to use transport-oriented feature aggregation for deriving speaker embeddings. The aggregated representation encodes the geometric structure of the underlying feature distribution, which is expected to contain valuable speaker-specific information that may not be represented by the commonly used statistical measures like mean and variance. The original transport-oriented feature aggregation is also extended to a weighted-frame version to incorporate the attention mechanism. Experiments on speaker verification with the Voxceleb dataset show improvement over statistics pooling and its attentive variant.
Learnable Frequency Filters for Speech Feature Extraction in Speaker Verification
Jun 15, 2022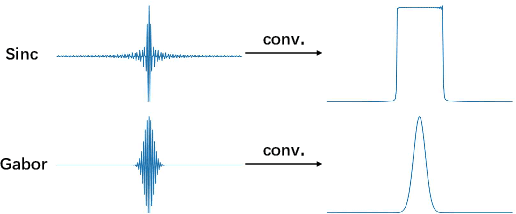
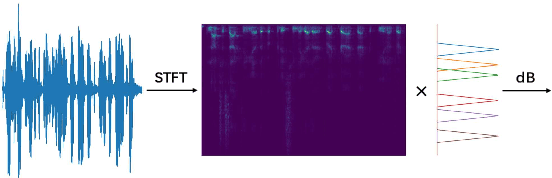
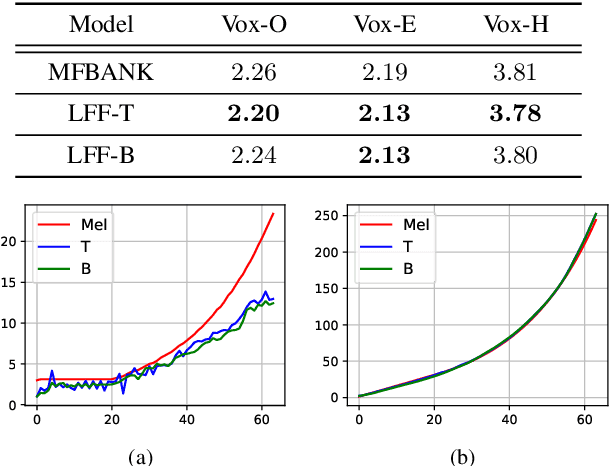
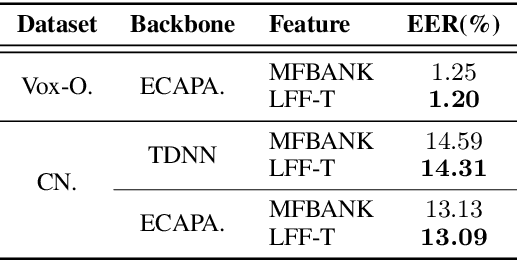
Mel-scale spectrum features are used in various recognition and classification tasks on speech signals. There is no reason to expect that these features are optimal for all different tasks, including speaker verification (SV). This paper describes a learnable front-end feature extraction model. The model comprises a group of filters to transform the Fourier spectrum. Model parameters that define these filters are trained end-to-end and optimized specifically for the task of speaker verification. Compared to the standard Mel-scale filter-bank, the filters' bandwidths and center frequencies are adjustable. Experimental results show that applying the learnable acoustic front-end improves speaker verification performance over conventional Mel-scale spectrum features. Analysis on the learned filter parameters suggests that narrow-band information benefits the SV system performance. The proposed model achieves a good balance between performance and computation cost. In resource-constrained computation settings, the model significantly outperforms CNN-based learnable front-ends. The generalization ability of the proposed model is also demonstrated on different embedding extraction models and datasets.