 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Multi-Talker ASR with Token-Level Serialized Output Training
Feb 05, 2022
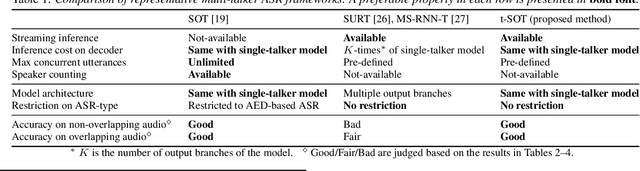
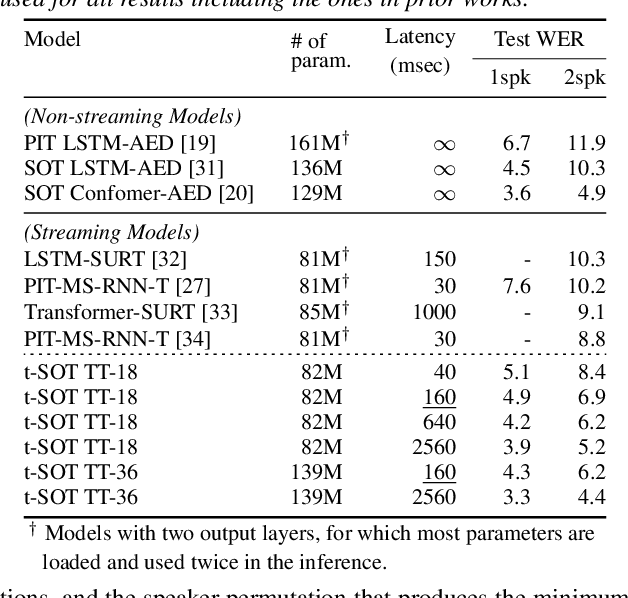
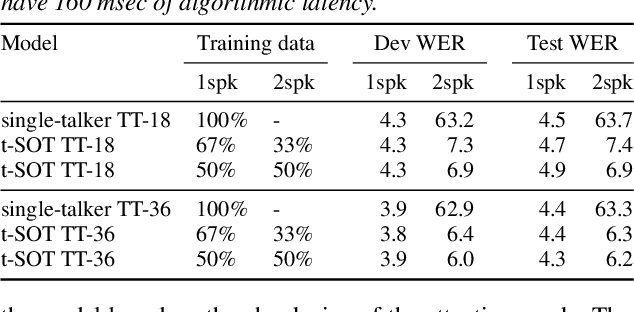
This paper proposes a token-level serialized output training (t-SOT), a novel framework for streaming multi-talker automatic speech recognition (ASR). Unlike existing streaming multi-talker ASR models using multiple output layers, the t-SOT model has only a single output layer that generates recognition tokens (e.g., words, subwords) of multiple speakers in chronological order based on their emission times. A special token that indicates the change of "virtual" output channels is introduced to keep track of the overlapping utterances. Compared to the prior streaming multi-talker ASR models, the t-SOT model has the advantages of less inference cost and a simpler model architecture. Moreover, in our experiments with LibriSpeechMix and LibriCSS datasets, the t-SOT-based transformer transducer model achieves the state-of-the-art word error rates by a significant margin to the prior results. For non-overlapping speech, the t-SOT model is on par with a single-talker ASR model in terms of both accuracy and computational cost, opening the door for deploying one model for both single- and multi-talker scenarios.
PickNet: Real-Time Channel Selection for Ad Hoc Microphone Arrays
Jan 24, 2022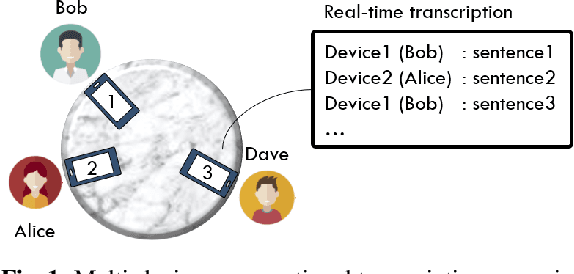
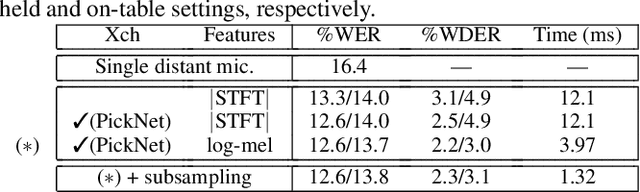
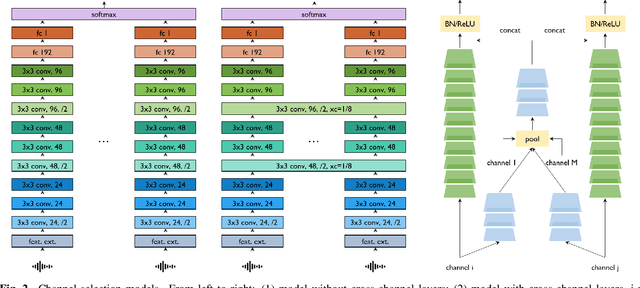
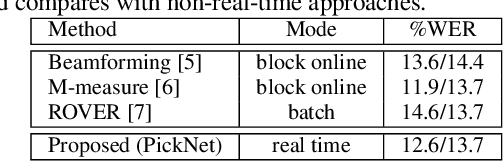
This paper proposes PickNet, a neural network model for real-time channel selection for an ad hoc microphone array consisting of multiple recording devices like cell phones. Assuming at most one person to be vocally active at each time point, PickNet identifies the device that is spatially closest to the active person for each time frame by using a short spectral patch of just hundreds of milliseconds. The model is applied to every time frame, and the short time frame signals from the selected microphones are concatenated across the frames to produce an output signal. As the personal devices are usually held close to their owners, the output signal is expected to have higher signal-to-noise and direct-to-reverberation ratios on average than the input signals. Since PickNet utilizes only limited acoustic context at each time frame, the system using the proposed model works in real time and is robust to changes in acoustic conditions. Speech recognition-based evaluation was carried out by using real conversational recordings obtained with various smartphones. The proposed model yielded significant gains in word error rate with limited computational cost over systems using a block-online beamformer and a single distant microphone.
Separating Long-Form Speech with Group-Wise Permutation Invariant Training
Nov 17, 2021
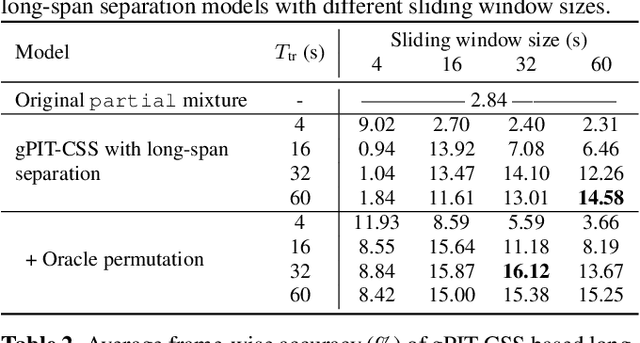
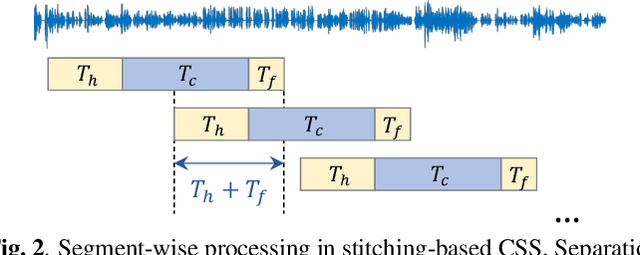
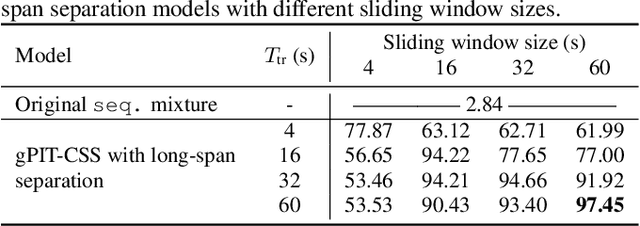
Multi-talker conversational speech processing has drawn many interests for various applications such as meeting transcription. Speech separation is often required to handle overlapped speech that is commonly observed in conversation. Although the original utterancelevel permutation invariant training-based continuous speech separation approach has proven to be effective in various conditions, it lacks the ability to leverage the long-span relationship of utterances and is computationally inefficient due to the highly overlapped sliding windows. To overcome these drawbacks, we propose a novel training scheme named Group-PIT, which allows direct training of the speech separation models on the long-form speech with a low computational cost for label assignment. Two different speech separation approaches with Group-PIT are explored, including direct long-span speech separation and short-span speech separation with long-span tracking. The experiments on the simulated meeting-style data demonstrate the effectiveness of our proposed approaches, especially in dealing with a very long speech input.
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
Oct 29, 2021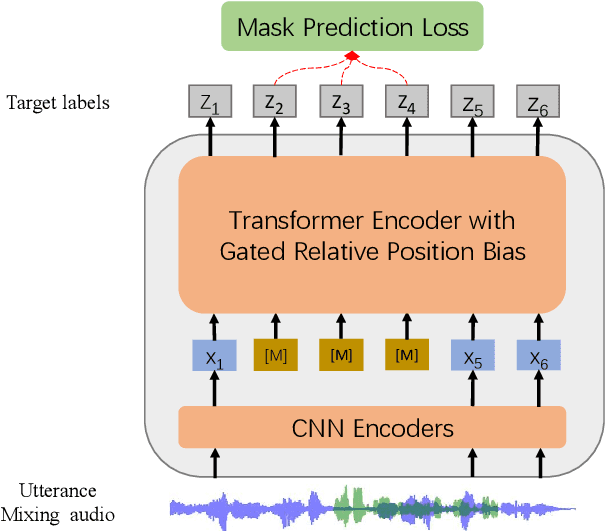
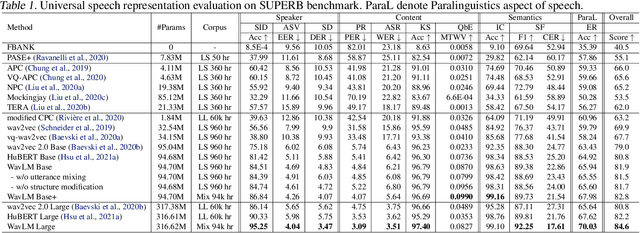
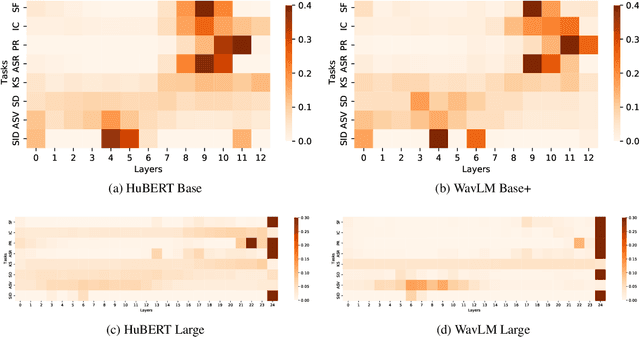
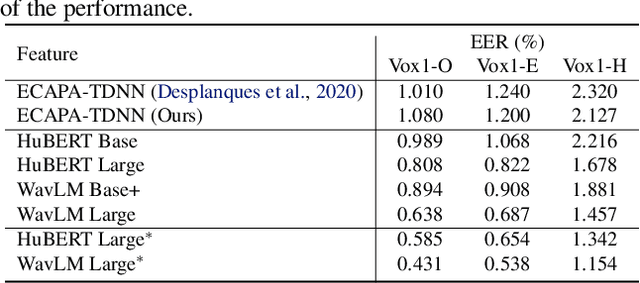
Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks. WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks. The code and pretrained models are available at https://aka.ms/wavlm.
Improving Noise Robustness of Contrastive Speech Representation Learning with Speech Reconstruction
Oct 28, 2021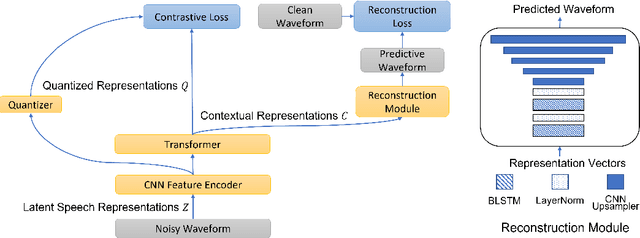
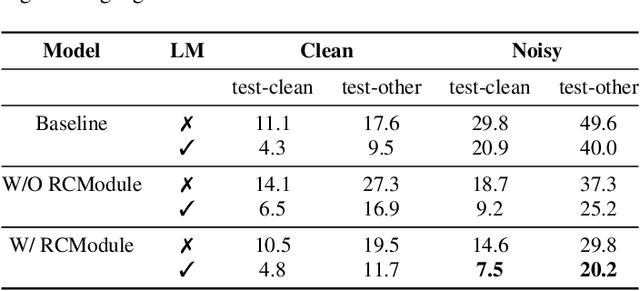
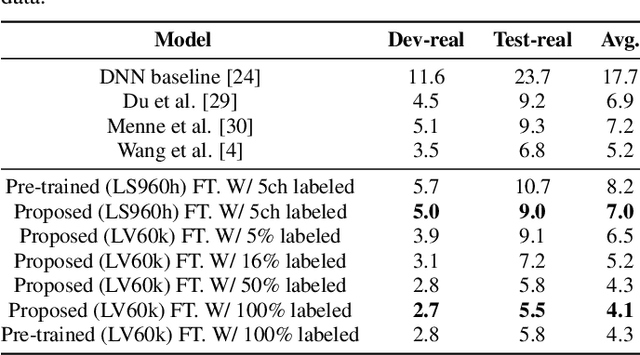
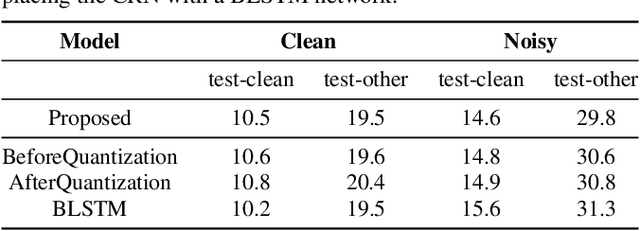
Noise robustness is essential for deploying automatic speech recognition (ASR) systems in real-world environments. One way to reduce the effect of noise interference is to employ a preprocessing module that conducts speech enhancement, and then feed the enhanced speech to an ASR backend. In this work, instead of suppressing background noise with a conventional cascaded pipeline, we employ a noise-robust representation learned by a refined self-supervised framework for noisy speech recognition. We propose to combine a reconstruction module with contrastive learning and perform multi-task continual pre-training on noisy data. The reconstruction module is used for auxiliary learning to improve the noise robustness of the learned representation and thus is not required during inference. Experiments demonstrate the effectiveness of our proposed method. Our model substantially reduces the word error rate (WER) for the synthesized noisy LibriSpeech test sets, and yields around 4.1/7.5% WER reduction on noisy clean/other test sets compared to data augmentation. For the real-world noisy speech from the CHiME-4 challenge (1-channel track), we have obtained the state of the art ASR performance without any denoising front-end. Moreover, we achieve comparable performance to the best supervised approach reported with only 16% of labeled data.
Continuous Speech Separation with Recurrent Selective Attention Network
Oct 28, 2021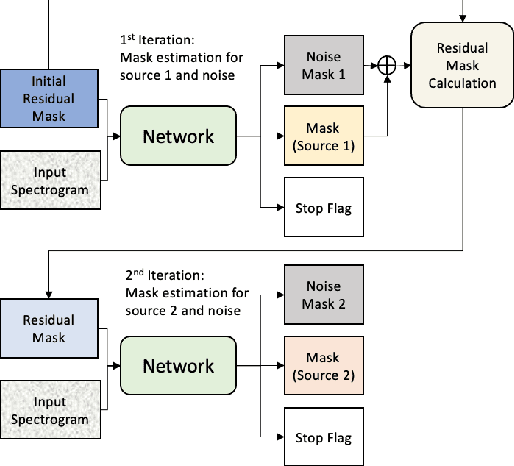
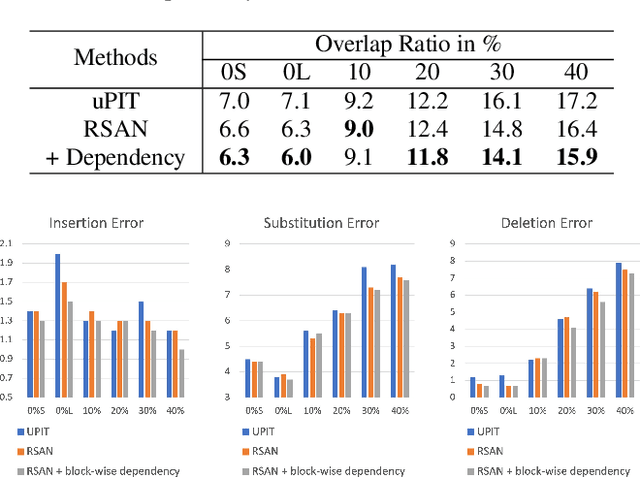
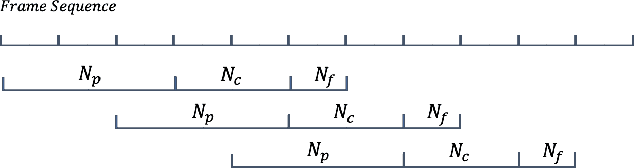
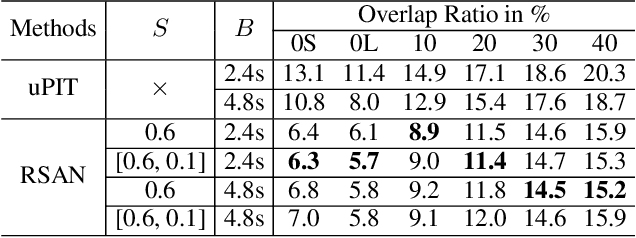
While permutation invariant training (PIT) based continuous speech separation (CSS) significantly improves the conversation transcription accuracy, it often suffers from speech leakages and failures in separation at "hot spot" regions because it has a fixed number of output channels. In this paper, we propose to apply recurrent selective attention network (RSAN) to CSS, which generates a variable number of output channels based on active speaker counting. In addition, we propose a novel block-wise dependency extension of RSAN by introducing dependencies between adjacent processing blocks in the CSS framework. It enables the network to utilize the separation results from the previous blocks to facilitate the current block processing. Experimental results on the LibriCSS dataset show that the RSAN-based CSS (RSAN-CSS) network consistently improves the speech recognition accuracy over PIT-based models. The proposed block-wise dependency modeling further boosts the performance of RSAN-CSS.
VarArray: Array-Geometry-Agnostic Continuous Speech Separation
Oct 26, 2021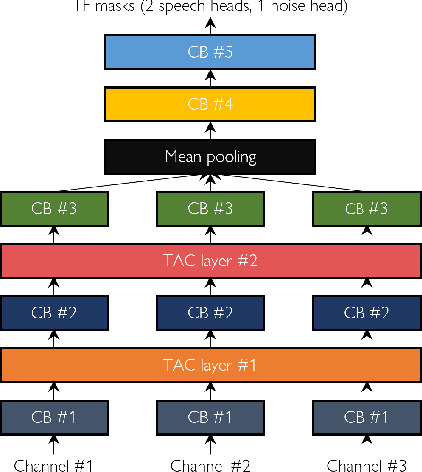
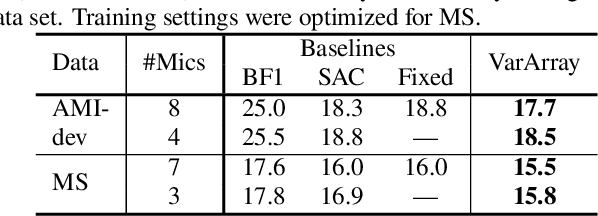
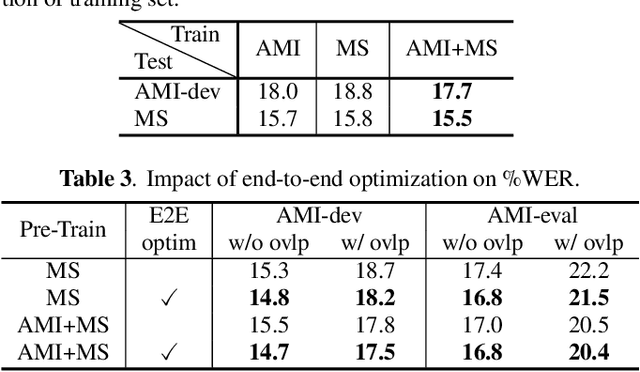
Continuous speech separation using a microphone array was shown to be promising in dealing with the speech overlap problem in natural conversation transcription. This paper proposes VarArray, an array-geometry-agnostic speech separation neural network model. The proposed model is applicable to any number of microphones without retraining while leveraging the nonlinear correlation between the input channels. The proposed method adapts different elements that were proposed before separately, including transform-average-concatenate, conformer speech separation, and inter-channel phase differences, and combines them in an efficient and cohesive way. Large-scale evaluation was performed with two real meeting transcription tasks by using a fully developed transcription system requiring no prior knowledge such as reference segmentations, which allowed us to measure the impact that the continuous speech separation system could have in realistic settings. The proposed model outperformed a previous approach to array-geometry-agnostic modeling for all of the geometry configurations considered, achieving asclite-based speaker-agnostic word error rates of 17.5% and 20.4% for the AMI development and evaluation sets, respectively, in the end-to-end setting using no ground-truth segmentations.
One model to enhance them all: array geometry agnostic multi-channel personalized speech enhancement
Oct 20, 2021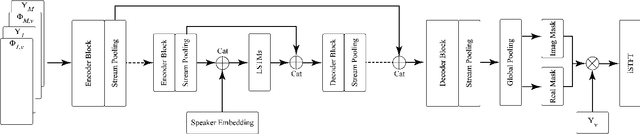
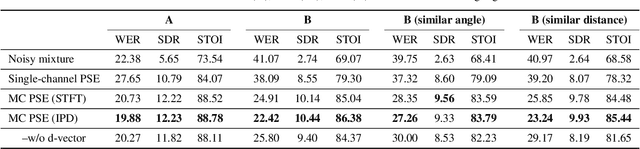
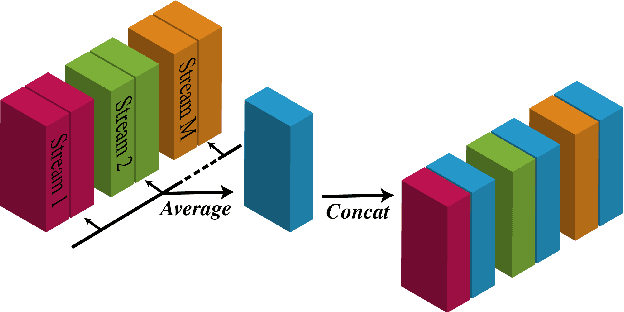
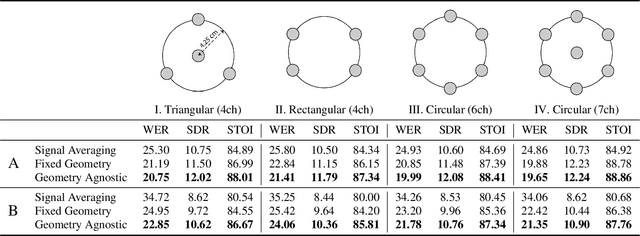
With the recent surge of video conferencing tools usage, providing high-quality speech signals and accurate captions have become essential to conduct day-to-day business or connect with friends and families. Single-channel personalized speech enhancement (PSE) methods show promising results compared with the unconditional speech enhancement (SE) methods in these scenarios due to their ability to remove interfering speech in addition to the environmental noise. In this work, we leverage spatial information afforded by microphone arrays to improve such systems' performance further. We investigate the relative importance of speaker embeddings and spatial features. Moreover, we propose a new causal array-geometry-agnostic multi-channel PSE model, which can generate a high-quality enhanced signal from arbitrary microphone geometry. Experimental results show that the proposed geometry agnostic model outperforms the model trained on a specific microphone array geometry in both speech quality and automatic speech recognition accuracy. We also demonstrate the effectiveness of the proposed approach for unseen array geometries.
Personalized Speech Enhancement: New Models and Comprehensive Evaluation
Oct 18, 2021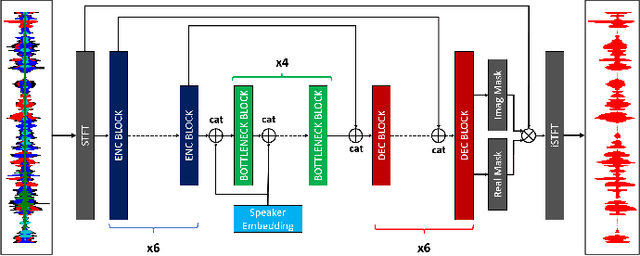


Personalized speech enhancement (PSE) models utilize additional cues, such as speaker embeddings like d-vectors, to remove background noise and interfering speech in real-time and thus improve the speech quality of online video conferencing systems for various acoustic scenarios. In this work, we propose two neural networks for PSE that achieve superior performance to the previously proposed VoiceFilter. In addition, we create test sets that capture a variety of scenarios that users can encounter during video conferencing. Furthermore, we propose a new metric to measure the target speaker over-suppression (TSOS) problem, which was not sufficiently investigated before despite its critical importance in deployment. Besides, we propose multi-task training with a speech recognition back-end. Our results show that the proposed models can yield better speech recognition accuracy, speech intelligibility, and perceptual quality than the baseline models, and the multi-task training can alleviate the TSOS issue in addition to improving the speech recognition accuracy.
All-neural beamformer for continuous speech separation
Oct 13, 2021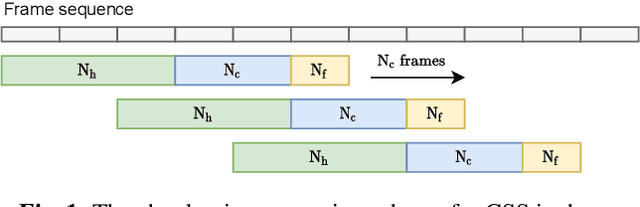
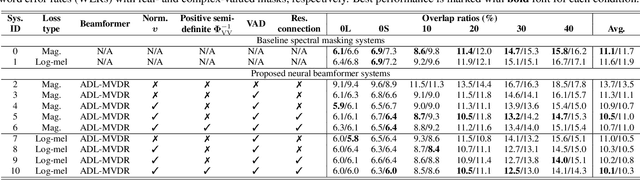

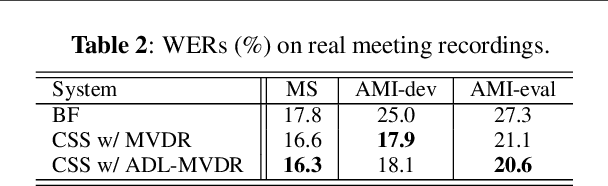
Continuous speech separation (CSS) aims to separate overlapping voices from a continuous influx of conversational audio containing an unknown number of utterances spoken by an unknown number of speakers. A common application scenario is transcribing a meeting conversation recorded by a microphone array. Prior studies explored various deep learning models for time-frequency mask estimation, followed by a minimum variance distortionless response (MVDR) filter to improve the automatic speech recognition (ASR) accuracy. The performance of these methods is fundamentally upper-bounded by MVDR's spatial selectivity. Recently, the all deep learning MVDR (ADL-MVDR) model was proposed for neural beamforming and demonstrated superior performance in a target speech extraction task using pre-segmented input. In this paper, we further adapt ADL-MVDR to the CSS task with several enhancements to enable end-to-end neural beamforming. The proposed system achieves significant word error rate reduction over a baseline spectral masking system on the LibriCSS dataset. Moreover, the proposed neural beamformer is shown to be comparable to a state-of-the-art MVDR-based system in real meeting transcription tasks, including AMI, while showing potentials to further simplify the runtime implementation and reduce the system latency with frame-wise processing.