 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPPH: A Vision-Based Operator for Measuring Body Movements for Personal Healthcare
Aug 18, 2024



Vision-based motion estimation methods show promise in accurately and unobtrusively estimating human body motion for healthcare purposes. However, these methods are not specifically designed for healthcare purposes and face challenges in real-world applications. Human pose estimation methods often lack the accuracy needed for detecting fine-grained, subtle body movements, while optical flow-based methods struggle with poor lighting conditions and unseen real-world data. These issues result in human body motion estimation errors, particularly during critical medical situations where the body is motionless, such as during unconsciousness. To address these challenges and improve the accuracy of human body motion estimation for healthcare purposes, we propose the OPPH operator designed to enhance current vision-based motion estimation methods. This operator, which considers human body movement and noise properties, functions as a multi-stage filter. Results tested on two real-world and one synthetic human motion dataset demonstrate that the operator effectively removes real-world noise, significantly enhances the detection of motionless states, maintains the accuracy of estimating active body movements, and maintains long-term body movement trends. This method could be beneficial for analyzing both critical medical events and chronic medical conditions.
Unobtrusive Monitoring of Physical Weakness: A Simulated Approach
Jun 14, 2024Aging and chronic conditions affect older adults' daily lives, making early detection of developing health issues crucial. Weakness, common in many conditions, alters physical movements and daily activities subtly. However, detecting such changes can be challenging due to their subtle and gradual nature. To address this, we employ a non-intrusive camera sensor to monitor individuals' daily sitting and relaxing activities for signs of weakness. We simulate weakness in healthy subjects by having them perform physical exercise and observing the behavioral changes in their daily activities before and after workouts. The proposed system captures fine-grained features related to body motion, inactivity, and environmental context in real-time while prioritizing privacy. A Bayesian Network is used to model the relationships between features, activities, and health conditions. We aim to identify specific features and activities that indicate such changes and determine the most suitable time scale for observing the change. Results show 0.97 accuracy in distinguishing simulated weakness at the daily level. Fine-grained behavioral features, including non-dominant upper body motion speed and scale, and inactivity distribution, along with a 300-second window, are found most effective. However, individual-specific models are recommended as no universal set of optimal features and activities was identified across all participants.
Click to Grasp: Zero-Shot Precise Manipulation via Visual Diffusion Descriptors
Mar 21, 2024Precise manipulation that is generalizable across scenes and objects remains a persistent challenge in robotics. Current approaches for this task heavily depend on having a significant number of training instances to handle objects with pronounced visual and/or geometric part ambiguities. Our work explores the grounding of fine-grained part descriptors for precise manipulation in a zero-shot setting by utilizing web-trained text-to-image diffusion-based generative models. We tackle the problem by framing it as a dense semantic part correspondence task. Our model returns a gripper pose for manipulating a specific part, using as reference a user-defined click from a source image of a visually different instance of the same object. We require no manual grasping demonstrations as we leverage the intrinsic object geometry and features. Practical experiments in a real-world tabletop scenario validate the efficacy of our approach, demonstrating its potential for advancing semantic-aware robotics manipulation. Web page: https://tsagkas.github.io/click2grasp
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Generating robotic elliptical excisions with human-like tool-tissue interactions
Sep 21, 2023



In surgery, the application of appropriate force levels is critical for the success and safety of a given procedure. While many studies are focused on measuring in situ forces, little attention has been devoted to relating these observed forces to surgical techniques. Answering questions like "Can certain changes to a surgical technique result in lower forces and increased safety margins?" could lead to improved surgical practice, and importantly, patient outcomes. However, such studies would require a large number of trials and professional surgeons, which is generally impractical to arrange. Instead, we show how robots can learn several variations of a surgical technique from a smaller number of surgical demonstrations and interpolate learnt behaviour via a parameterised skill model. This enables a large number of trials to be performed by a robotic system and the analysis of surgical techniques and their downstream effects on tissue. Here, we introduce a parameterised model of the elliptical excision skill and apply a Bayesian optimisation scheme to optimise the excision behaviour with respect to expert ratings, as well as individual characteristics of excision forces. Results show that the proposed framework can successfully align the generated robot behaviour with subjects across varying levels of proficiency in terms of excision forces.
Comparison of Pedestrian Prediction Models from Trajectory and Appearance Data for Autonomous Driving
May 25, 2023



The ability to anticipate pedestrian motion changes is a critical capability for autonomous vehicles. In urban environments, pedestrians may enter the road area and create a high risk for driving, and it is important to identify these cases. Typical predictors use the trajectory history to predict future motion, however in cases of motion initiation, motion in the trajectory may only be clearly visible after a delay, which can result in the pedestrian has entered the road area before an accurate prediction can be made. Appearance data includes useful information such as changes of gait, which are early indicators of motion changes, and can inform trajectory prediction. This work presents a comparative evaluation of trajectory-only and appearance-based methods for pedestrian prediction, and introduces a new dataset experiment for prediction using appearance. We create two trajectory and image datasets based on the combination of image and trajectory sequences from the popular NuScenes dataset, and examine prediction of trajectories using observed appearance to influence futures. This shows some advantages over trajectory prediction alone, although problems with the dataset prevent advantages of appearance-based models from being shown. We describe methods for improving the dataset and experiment to allow benefits of appearance-based models to be captured.
Interactive Acquisition of Fine-grained Visual Concepts by Exploiting Semantics of Generic Characterizations in Discourse
May 05, 2023Interactive Task Learning (ITL) concerns learning about unforeseen domain concepts via natural interactions with human users. The learner faces a number of significant constraints: learning should be online, incremental and few-shot, as it is expected to perform tangible belief updates right after novel words denoting unforeseen concepts are introduced. In this work, we explore a challenging symbol grounding task--discriminating among object classes that look very similar--within the constraints imposed by ITL. We demonstrate empirically that more data-efficient grounding results from exploiting the truth-conditions of the teacher's generic statements (e.g., "Xs have attribute Z.") and their implicatures in context (e.g., as an answer to "How are Xs and Ys different?", one infers Y lacks attribute Z).
DiPA: Diverse and Probabilistically Accurate Interactive Prediction
Oct 12, 2022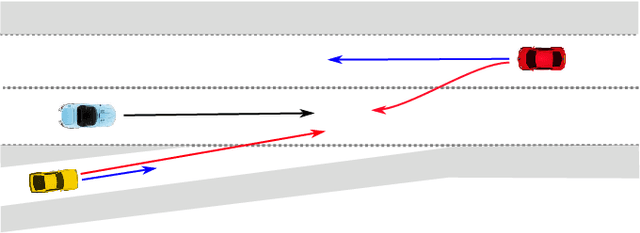
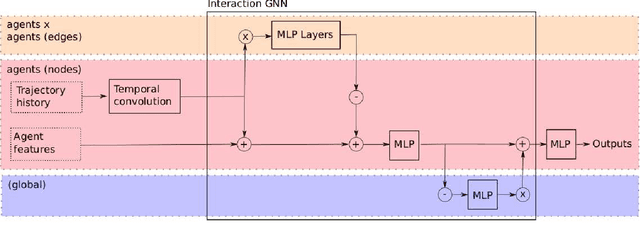

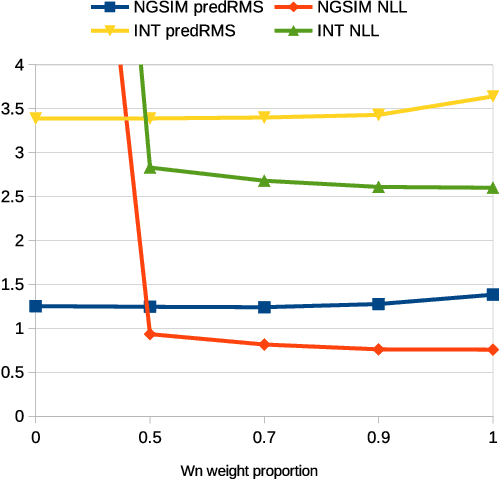
Accurate prediction is important for operating an autonomous vehicle in interactive scenarios. Previous interactive predictors have used closest-mode evaluations, which test if one of a set of predictions covers the ground-truth, but not if additional unlikely predictions are made. The presence of unlikely predictions can interfere with planning, by indicating conflict with the ego plan when it is not likely to occur. Closest-mode evaluations are not sufficient for showing a predictor is useful, an effective predictor also needs to accurately estimate mode probabilities, and to be evaluated using probabilistic measures. These two evaluation approaches, eg. predicted-mode RMS and minADE/FDE, are analogous to precision and recall in binary classification, and there is a challenging trade-off between prediction strategies for each. We present DiPA, a method for producing diverse predictions while also capturing accurate probabilistic estimates. DiPA uses a flexible representation that captures interactions in widely varying road topologies, and uses a novel training regime for a Gaussian Mixture Model that supports diversity of predicted modes, along with accurate spatial distribution and mode probability estimates. DiPA achieves state-of-the-art performance on INTERACTION and NGSIM, and improves over a baseline (MFP) when both closest-mode and probabilistic evaluations are used at the same time.
Testing Rare Downstream Safety Violations via Upstream Adaptive Sampling of Perception Error Models
Sep 27, 2022


Testing black-box perceptual-control systems in simulation faces two difficulties. Firstly, perceptual inputs in simulation lack the fidelity of real-world sensor inputs. Secondly, for a reasonably accurate perception system, encountering a rare failure trajectory may require running infeasibly many simulations. This paper combines perception error models -- surrogates for a sensor-based detection system -- with state-dependent adaptive importance sampling. This allows us to efficiently assess the rare failure probabilities for real-world perceptual control systems within simulation. Our experiments with an autonomous braking system equipped with an RGB obstacle-detector show that our method can calculate accurate failure probabilities with an inexpensive number of simulations. Further, we show how choice of safety metric can influence the process of learning proposal distributions capable of reliably sampling high-probability failures.
Learning robotic cutting from demonstration: Non-holonomic DMPs using the Udwadia-Kalaba method
Sep 24, 2022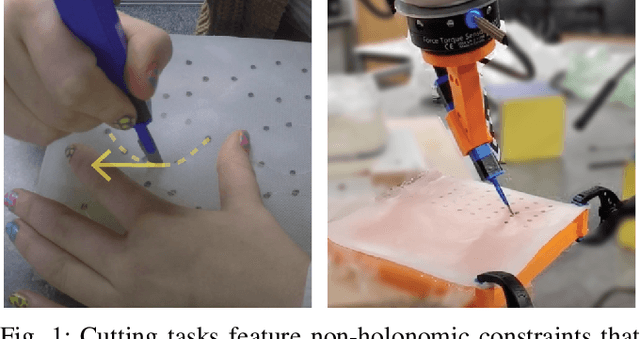

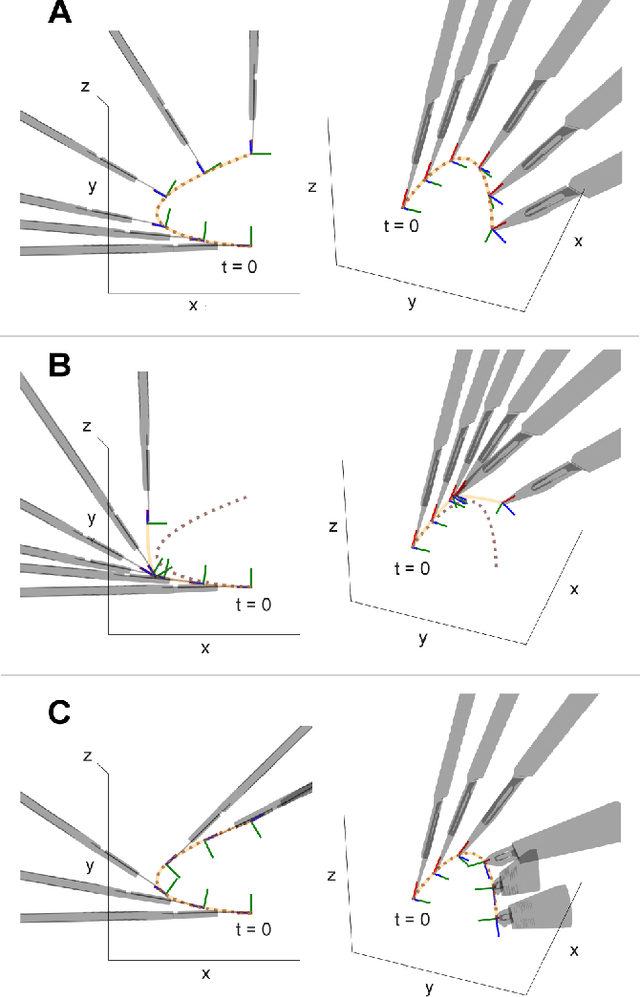

Dynamic Movement Primitives (DMPs) offer great versatility for encoding, generating and adapting complex end-effector trajectories. DMPs are also very well suited to learning manipulation skills from human demonstration. However, the reactive nature of DMPs restricts their applicability for tool use and object manipulation tasks involving non-holonomic constraints, such as scalpel cutting or catheter steering. In this work, we extend the Cartesian space DMP formulation by adding a coupling term that enforces a pre-defined set of non-holonomic constraints. We obtain the closed-form expression for the constraint forcing term using the Udwadia-Kalaba method. This approach offers a clean and practical solution for guaranteed constraint satisfaction at run-time. Further, the proposed analytical form of the constraint forcing term enables efficient trajectory optimization subject to constraints. We demonstrate the usefulness of this approach by showing how we can learn robotic cutting skills from human demonstration.