 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable ConvNets v2: More Deformable, Better Results
Nov 28, 2018
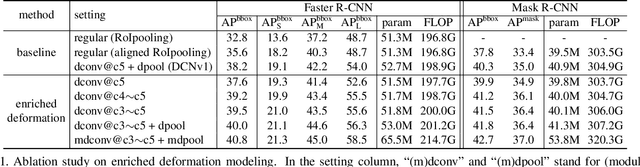

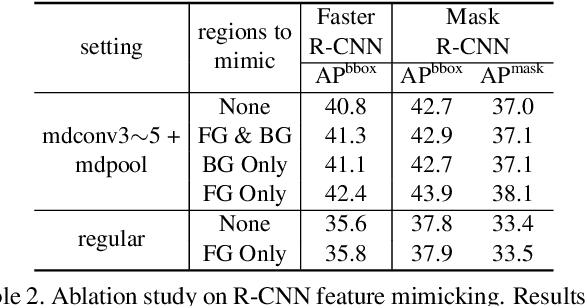
The superior performance of Deformable Convolutional Networks arises from its ability to adapt to the geometric variations of objects. Through an examination of its adaptive behavior, we observe that while the spatial support for its neural features conforms more closely than regular ConvNets to object structure, this support may nevertheless extend well beyond the region of interest, causing features to be influenced by irrelevant image content. To address this problem, we present a reformulation of Deformable ConvNets that improves its ability to focus on pertinent image regions, through increased modeling power and stronger training. The modeling power is enhanced through a more comprehensive integration of deformable convolution within the network, and by introducing a modulation mechanism that expands the scope of deformation modeling. To effectively harness this enriched modeling capability, we guide network training via a proposed feature mimicking scheme that helps the network to learn features that reflect the object focus and classification power of R-CNN features. With the proposed contributions, this new version of Deformable ConvNets yields significant performance gains over the original model and produces leading results on the COCO benchmark for object detection and instance segmentation.
Integrated Object Detection and Tracking with Tracklet-Conditioned Detection
Nov 27, 2018
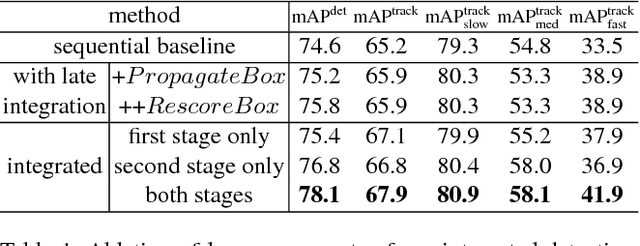


Accurate detection and tracking of objects is vital for effective video understanding. In previous work, the two tasks have been combined in a way that tracking is based heavily on detection, but the detection benefits marginally from the tracking. To increase synergy, we propose to more tightly integrate the tasks by conditioning the object detection in the current frame on tracklets computed in prior frames. With this approach, the object detection results not only have high detection responses, but also improved coherence with the existing tracklets. This greater coherence leads to estimated object trajectories that are smoother and more stable than the jittered paths obtained without tracklet-conditioned detection. Over extensive experiments, this approach is shown to achieve state-of-the-art performance in terms of both detection and tracking accuracy, as well as noticeable improvements in tracking stability.
Explicit Pose Deformation Learning for Tracking Human Poses
Nov 21, 2018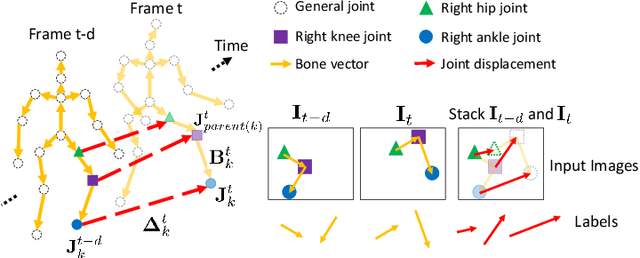

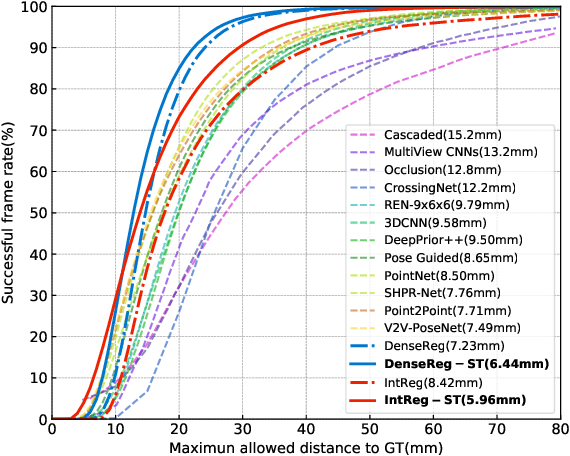
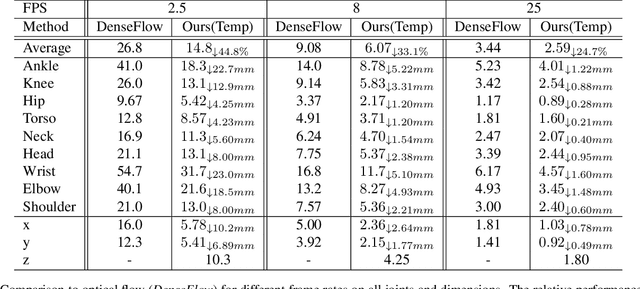
We present a method for human pose tracking that learns explicitly about the dynamic effects of human motion on joint appearance. In contrast to previous techniques which employ generic tools such as dense optical flow or spatio-temporal smoothness constraints to pass pose inference cues between frames, our system instead learns to predict joint displacements from the previous frame to the current frame based on the possibly changing appearance of relevant pixels surrounding the corresponding joints in the previous frame. This explicit learning of pose deformations is formulated by incorporating concepts from human pose estimation into an optical flow-like framework. With this approach, state-of-the-art performance is achieved on standard benchmarks for various pose tracking tasks including 3D body pose tracking in RGB video, 3D hand pose tracking in depth sequences, and 3D hand gesture tracking in RGB video.
Recurrent Transformer Networks for Semantic Correspondence
Oct 29, 2018
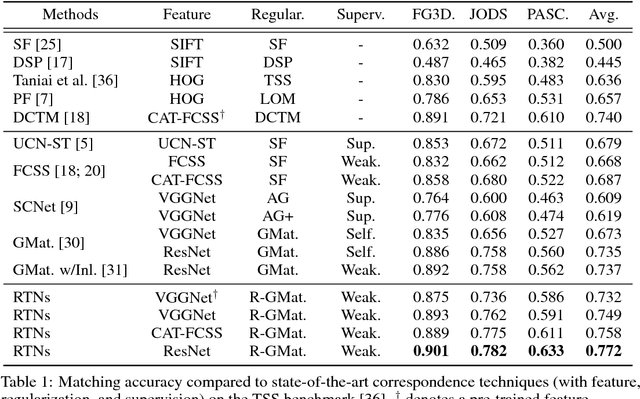
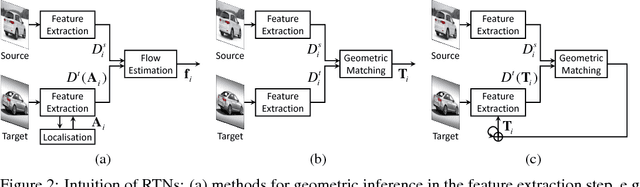
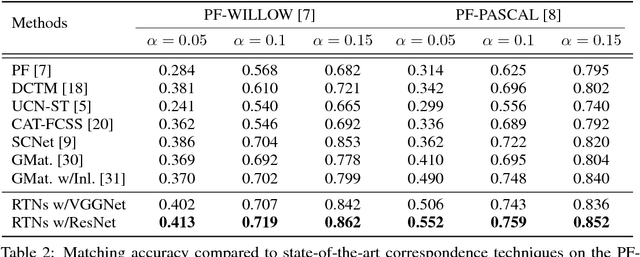
We present recurrent transformer networks (RTNs) for obtaining dense correspondences between semantically similar images. Our networks accomplish this through an iterative process of estimating spatial transformations between the input images and using these transformations to generate aligned convolutional activations. By directly estimating the transformations between an image pair, rather than employing spatial transformer networks to independently normalize each individual image, we show that greater accuracy can be achieved. This process is conducted in a recursive manner to refine both the transformation estimates and the feature representations. In addition, a technique is presented for weakly-supervised training of RTNs that is based on a proposed classification loss. With RTNs, state-of-the-art performance is attained on several benchmarks for semantic correspondence.
An Integral Pose Regression System for the ECCV2018 PoseTrack Challenge
Sep 17, 2018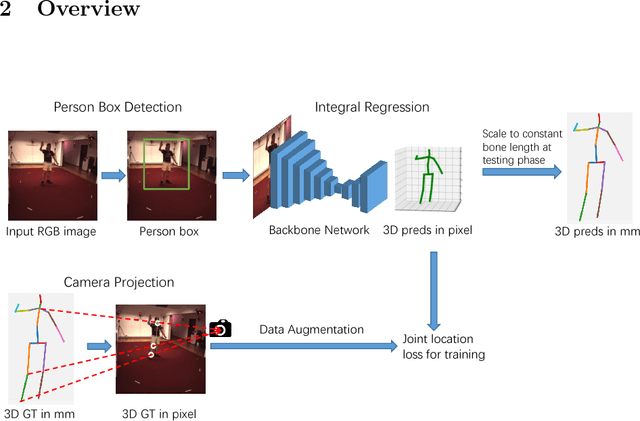

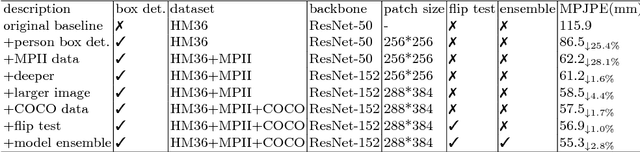
For the ECCV 2018 PoseTrack Challenge, we present a 3D human pose estimation system based mainly on the integral human pose regression method. We show a comprehensive ablation study to examine the key performance factors of the proposed system. Our system obtains 47mm MPJPE on the CHALL_H80K test dataset, placing second in the ECCV2018 3D human pose estimation challenge. Code will be released to facilitate future work.
Multi-Context Deep Network for Angle-Closure Glaucoma Screening in Anterior Segment OCT
Sep 10, 2018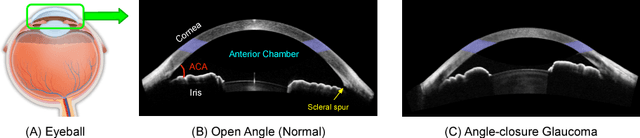
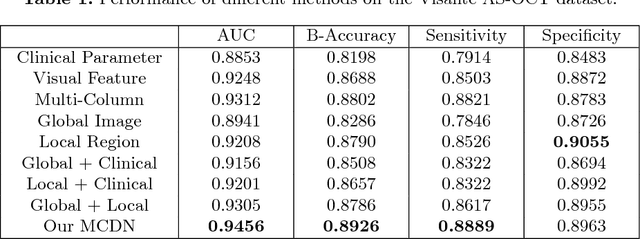
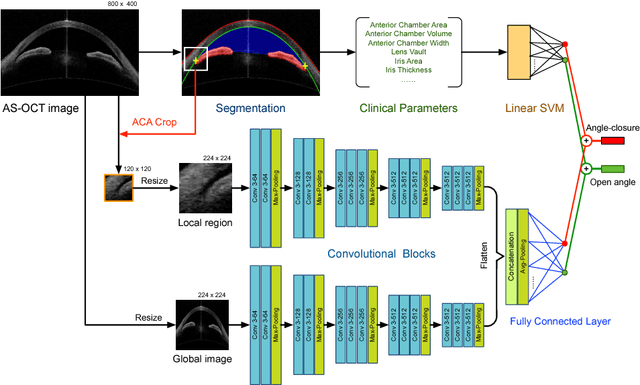
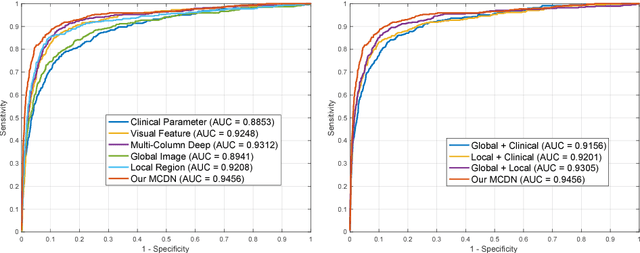
A major cause of irreversible visual impairment is angle-closure glaucoma, which can be screened through imagery from Anterior Segment Optical Coherence Tomography (AS-OCT). Previous computational diagnostic techniques address this screening problem by extracting specific clinical measurements or handcrafted visual features from the images for classification. In this paper, we instead propose to learn from training data a discriminative representation that may capture subtle visual cues not modeled by predefined features. Based on clinical priors, we formulate this learning with a presented Multi-Context Deep Network (MCDN) architecture, in which parallel Convolutional Neural Networks are applied to particular image regions and at corresponding scales known to be informative for clinically diagnosing angle-closure glaucoma. The output feature maps of the parallel streams are merged into a classification layer to produce the deep screening result. Moreover, we incorporate estimated clinical parameters to further enhance performance. On a clinical AS-OCT dataset, our system is validated through comparisons to previous screening methods.
Faces as Lighting Probes via Unsupervised Deep Highlight Extraction
Jul 21, 2018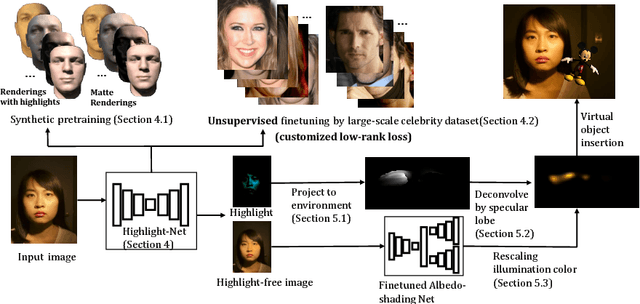
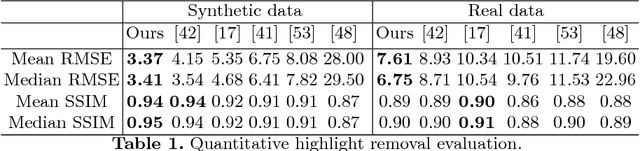
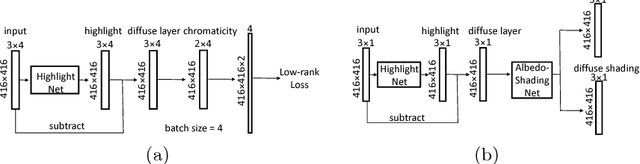
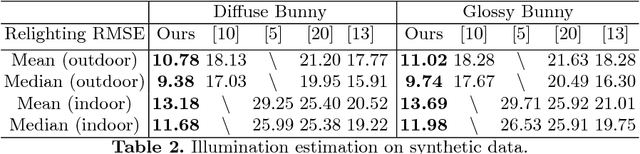
We present a method for estimating detailed scene illumination using human faces in a single image. In contrast to previous works that estimate lighting in terms of low-order basis functions or distant point lights, our technique estimates illumination at a higher precision in the form of a non-parametric environment map. Based on the observation that faces can exhibit strong highlight reflections from a broad range of lighting directions, we propose a deep neural network for extracting highlights from faces, and then trace these reflections back to the scene to acquire the environment map. Since real training data for highlight extraction is very limited, we introduce an unsupervised scheme for finetuning the network on real images, based on the consistent diffuse chromaticity of a given face seen in multiple real images. In tracing the estimated highlights to the environment, we reduce the blurring effect of skin reflectance on reflected light through a deconvolution determined by prior knowledge on face material properties. Comparisons to previous techniques for highlight extraction and illumination estimation show the state-of-the-art performance of this approach on a variety of indoor and outdoor scenes.
Exposure: A White-Box Photo Post-Processing Framework
Feb 06, 2018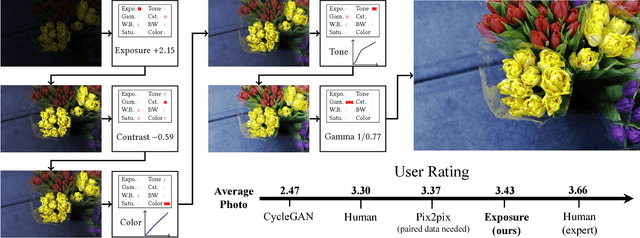


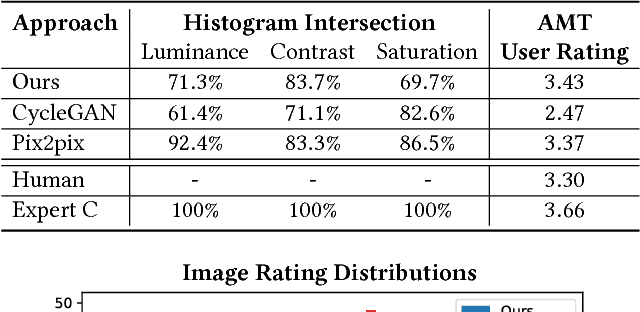
Retouching can significantly elevate the visual appeal of photos, but many casual photographers lack the expertise to do this well. To address this problem, previous works have proposed automatic retouching systems based on supervised learning from paired training images acquired before and after manual editing. As it is difficult for users to acquire paired images that reflect their retouching preferences, we present in this paper a deep learning approach that is instead trained on unpaired data, namely a set of photographs that exhibits a retouching style the user likes, which is much easier to collect. Our system is formulated using deep convolutional neural networks that learn to apply different retouching operations on an input image. Network training with respect to various types of edits is enabled by modeling these retouching operations in a unified manner as resolution-independent differentiable filters. To apply the filters in a proper sequence and with suitable parameters, we employ a deep reinforcement learning approach that learns to make decisions on what action to take next, given the current state of the image. In contrast to many deep learning systems, ours provides users with an understandable solution in the form of conventional retouching edits, rather than just a "black-box" result. Through quantitative comparisons and user studies, we show that this technique generates retouching results consistent with the provided photo set.
DCTM: Discrete-Continuous Transformation Matching for Semantic Flow
Jul 18, 2017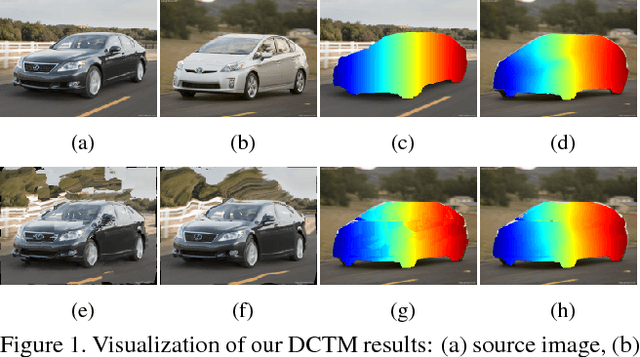
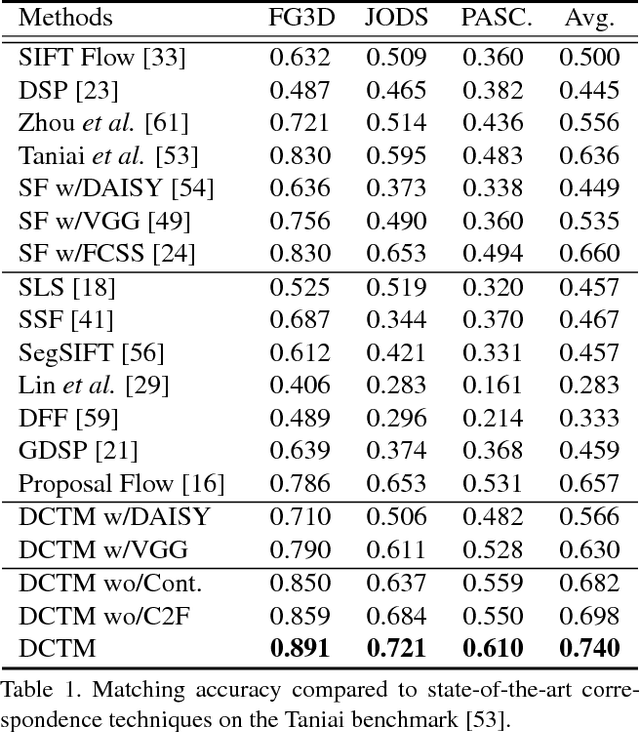
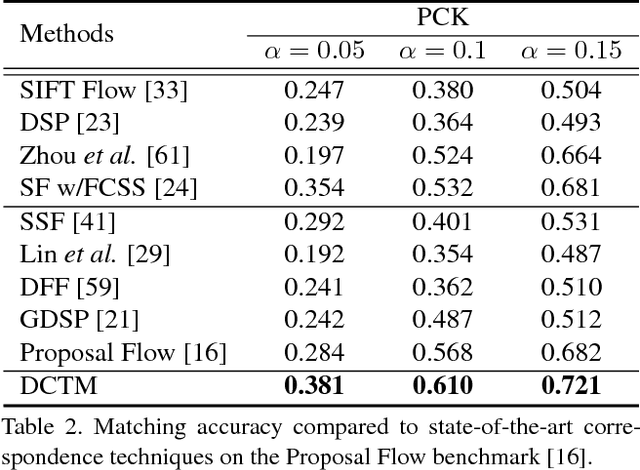
Techniques for dense semantic correspondence have provided limited ability to deal with the geometric variations that commonly exist between semantically similar images. While variations due to scale and rotation have been examined, there lack practical solutions for more complex deformations such as affine transformations because of the tremendous size of the associated solution space. To address this problem, we present a discrete-continuous transformation matching (DCTM) framework where dense affine transformation fields are inferred through a discrete label optimization in which the labels are iteratively updated via continuous regularization. In this way, our approach draws solutions from the continuous space of affine transformations in a manner that can be computed efficiently through constant-time edge-aware filtering and a proposed affine-varying CNN-based descriptor. Experimental results show that this model outperforms the state-of-the-art methods for dense semantic correspondence on various benchmarks.
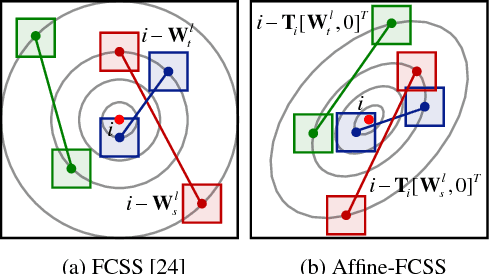
FCSS: Fully Convolutional Self-Similarity for Dense Semantic Correspondence
Feb 03, 2017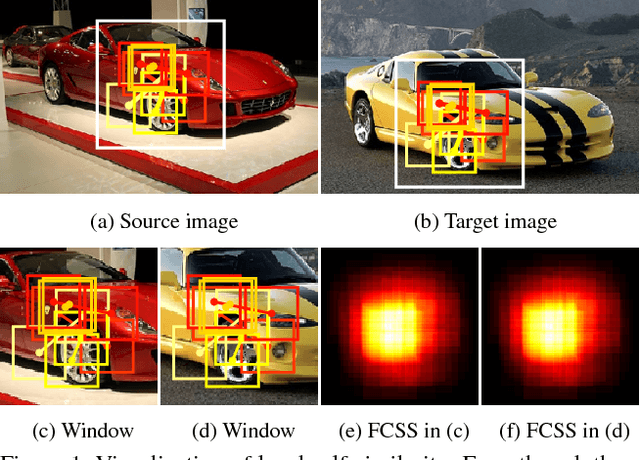
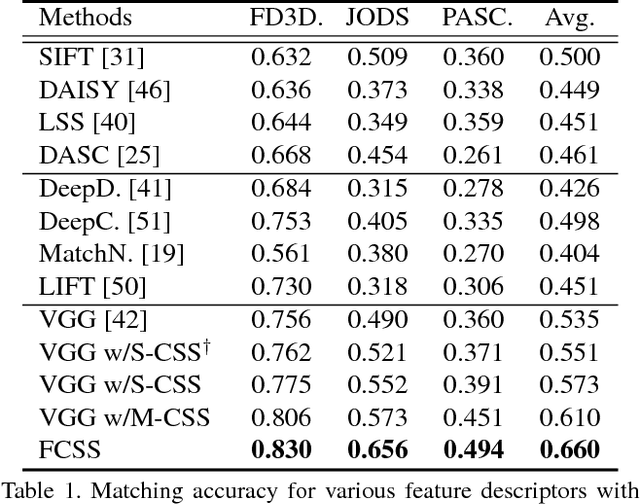
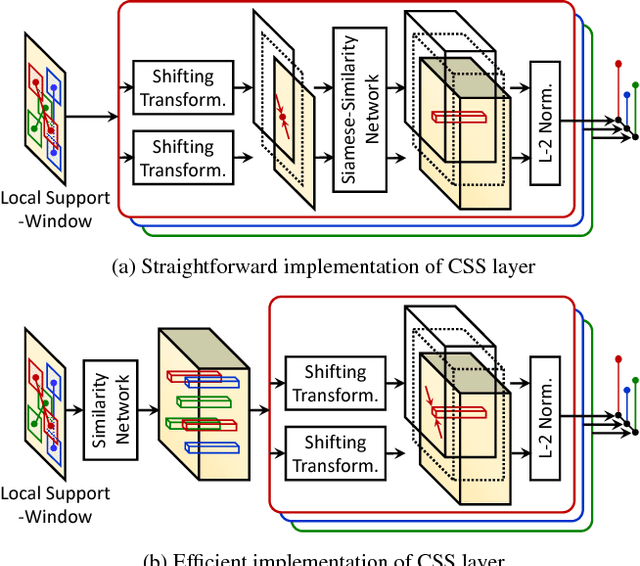
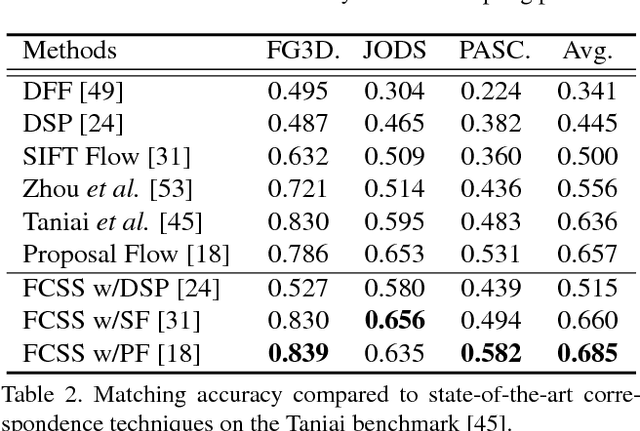
We present a descriptor, called fully convolutional self-similarity (FCSS), for dense semantic correspondence. To robustly match points among different instances within the same object class, we formulate FCSS using local self-similarity (LSS) within a fully convolutional network. In contrast to existing CNN-based descriptors, FCSS is inherently insensitive to intra-class appearance variations because of its LSS-based structure, while maintaining the precise localization ability of deep neural networks. The sampling patterns of local structure and the self-similarity measure are jointly learned within the proposed network in an end-to-end and multi-scale manner. As training data for semantic correspondence is rather limited, we propose to leverage object candidate priors provided in existing image datasets and also correspondence consistency between object pairs to enable weakly-supervised learning. Experiments demonstrate that FCSS outperforms conventional handcrafted descriptors and CNN-based descriptors on various benchmarks.