 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Rolling Shutter Images Alive with Dual Reversed Distortion
Mar 15, 2022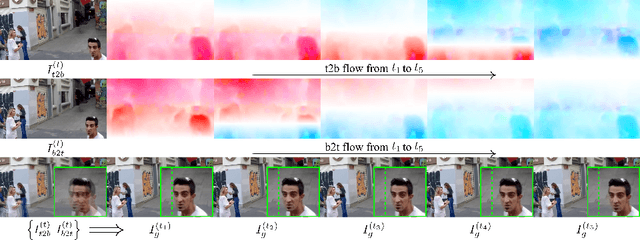

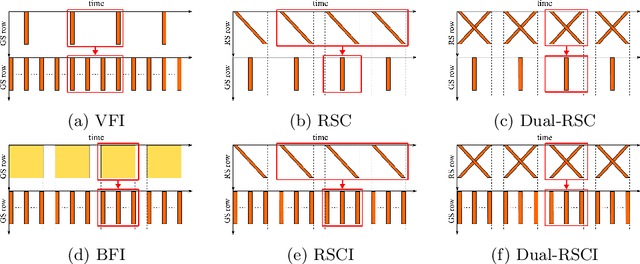
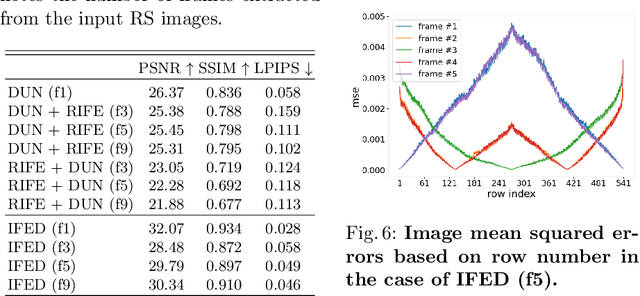
Rolling shutter (RS) distortion can be interpreted as the result of picking a row of pixels from instant global shutter (GS) frames over time during the exposure of the RS camera. This means that the information of each instant GS frame is partially, yet sequentially, embedded into the row-dependent distortion. Inspired by this fact, we address the challenging task of reversing this process, i.e., extracting undistorted GS frames from images suffering from RS distortion. However, since RS distortion is coupled with other factors such as readout settings and the relative velocity of scene elements to the camera, models that only exploit the geometric correlation between temporally adjacent images suffer from poor generality in processing data with different readout settings and dynamic scenes with both camera motion and object motion. In this paper, instead of two consecutive frames, we propose to exploit a pair of images captured by dual RS cameras with reversed RS directions for this highly challenging task. Grounded on the symmetric and complementary nature of dual reversed distortion, we develop a novel end-to-end model, IFED, to generate dual optical flow sequence through iterative learning of the velocity field during the RS time. Extensive experimental results demonstrate that IFED is superior to naive cascade schemes, as well as the state-of-the-art which utilizes adjacent RS images. Most importantly, although it is trained on a synthetic dataset, IFED is shown to be effective at retrieving GS frame sequences from real-world RS distorted images of dynamic scenes.
A Simple Multi-Modality Transfer Learning Baseline for Sign Language Translation
Mar 08, 2022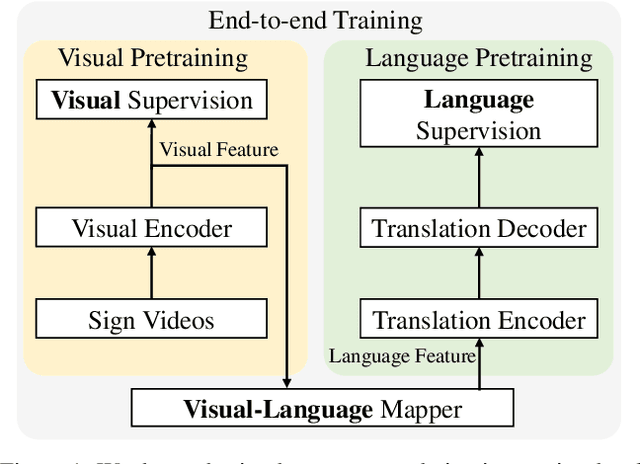
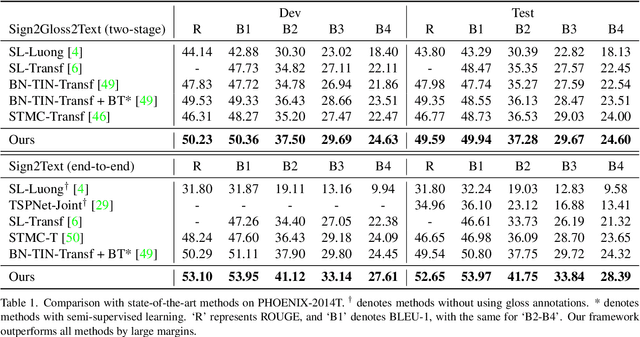
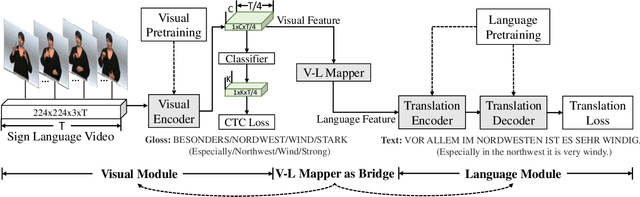
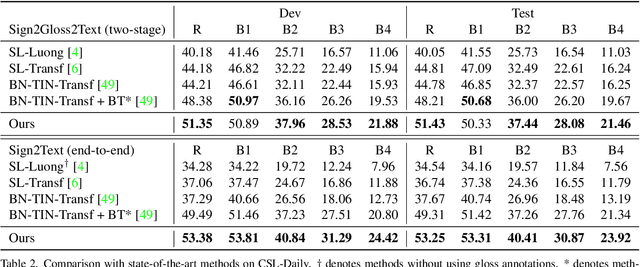
This paper proposes a simple transfer learning baseline for sign language translation. Existing sign language datasets (e.g. PHOENIX-2014T, CSL-Daily) contain only about 10K-20K pairs of sign videos, gloss annotations and texts, which are an order of magnitude smaller than typical parallel data for training spoken language translation models. Data is thus a bottleneck for training effective sign language translation models. To mitigate this problem, we propose to progressively pretrain the model from general-domain datasets that include a large amount of external supervision to within-domain datasets. Concretely, we pretrain the sign-to-gloss visual network on the general domain of human actions and the within-domain of a sign-to-gloss dataset, and pretrain the gloss-to-text translation network on the general domain of a multilingual corpus and the within-domain of a gloss-to-text corpus. The joint model is fine-tuned with an additional module named the visual-language mapper that connects the two networks. This simple baseline surpasses the previous state-of-the-art results on two sign language translation benchmarks, demonstrating the effectiveness of transfer learning. With its simplicity and strong performance, this approach can serve as a solid baseline for future research.
Cross-Model Pseudo-Labeling for Semi-Supervised Action Recognition
Dec 17, 2021
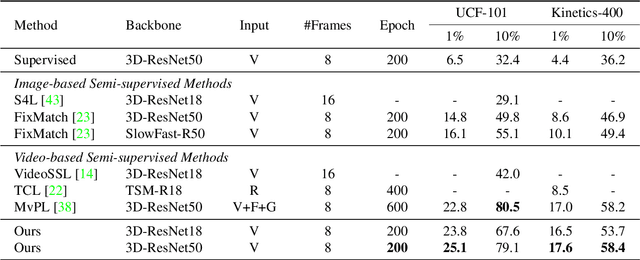
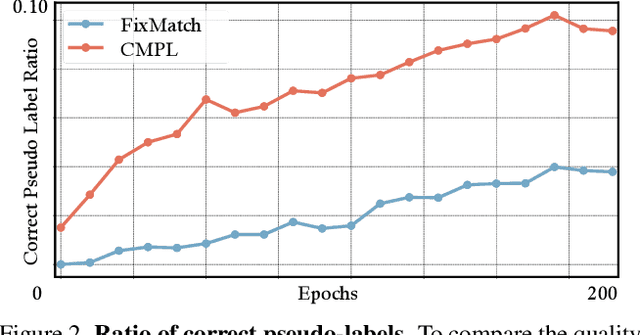
Semi-supervised action recognition is a challenging but important task due to the high cost of data annotation. A common approach to this problem is to assign unlabeled data with pseudo-labels, which are then used as additional supervision in training. Typically in recent work, the pseudo-labels are obtained by training a model on the labeled data, and then using confident predictions from the model to teach itself. In this work, we propose a more effective pseudo-labeling scheme, called Cross-Model Pseudo-Labeling (CMPL). Concretely, we introduce a lightweight auxiliary network in addition to the primary backbone, and ask them to predict pseudo-labels for each other. We observe that, due to their different structural biases, these two models tend to learn complementary representations from the same video clips. Each model can thus benefit from its counterpart by utilizing cross-model predictions as supervision. Experiments on different data partition protocols demonstrate the significant improvement of our framework over existing alternatives. For example, CMPL achieves $17.6\%$ and $25.1\%$ Top-1 accuracy on Kinetics-400 and UCF-101 using only the RGB modality and $1\%$ labeled data, outperforming our baseline model, FixMatch, by $9.0\%$ and $10.3\%$, respectively.
Towards Tokenized Human Dynamics Representation
Nov 22, 2021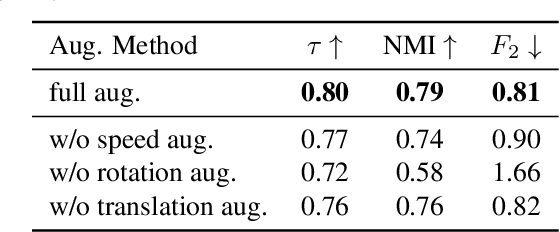
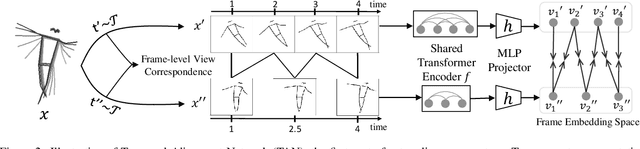

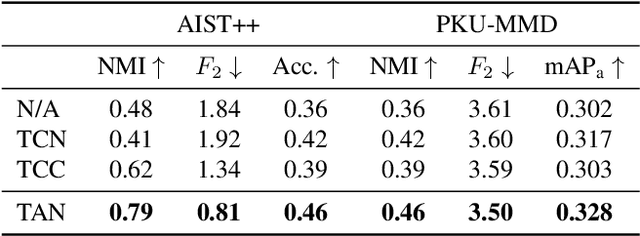
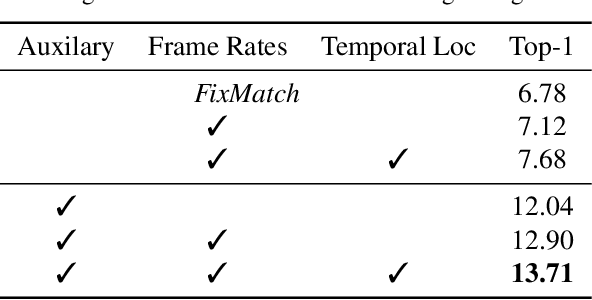
For human action understanding, a popular research direction is to analyze short video clips with unambiguous semantic content, such as jumping and drinking. However, methods for understanding short semantic actions cannot be directly translated to long human dynamics such as dancing, where it becomes challenging even to label the human movements semantically. Meanwhile, the natural language processing (NLP) community has made progress in solving a similar challenge of annotation scarcity by large-scale pre-training, which improves several downstream tasks with one model. In this work, we study how to segment and cluster videos into recurring temporal patterns in a self-supervised way, namely acton discovery, the main roadblock towards video tokenization. We propose a two-stage framework that first obtains a frame-wise representation by contrasting two augmented views of video frames conditioned on their temporal context. The frame-wise representations across a collection of videos are then clustered by K-means. Actons are then automatically extracted by forming a continuous motion sequence from frames within the same cluster. We evaluate the frame-wise representation learning step by Kendall's Tau and the lexicon building step by normalized mutual information and language entropy. We also study three applications of this tokenization: genre classification, action segmentation, and action composition. On the AIST++ and PKU-MMD datasets, actons bring significant performance improvements compared to several baselines.
The Emergence of Objectness: Learning Zero-Shot Segmentation from Videos
Nov 11, 2021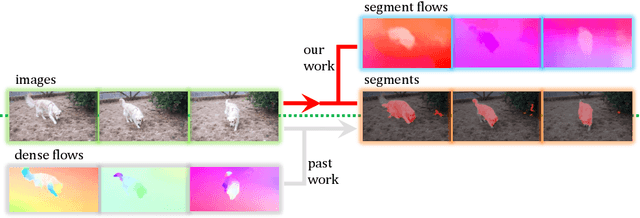

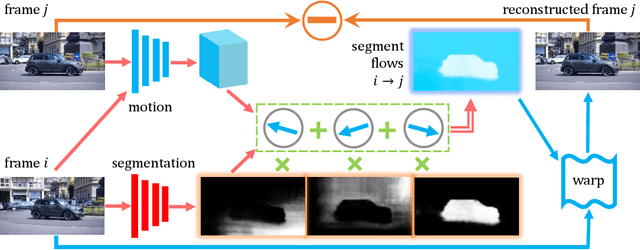

Humans can easily segment moving objects without knowing what they are. That objectness could emerge from continuous visual observations motivates us to model grouping and movement concurrently from unlabeled videos. Our premise is that a video has different views of the same scene related by moving components, and the right region segmentation and region flow would allow mutual view synthesis which can be checked from the data itself without any external supervision. Our model starts with two separate pathways: an appearance pathway that outputs feature-based region segmentation for a single image, and a motion pathway that outputs motion features for a pair of images. It then binds them in a conjoint representation called segment flow that pools flow offsets over each region and provides a gross characterization of moving regions for the entire scene. By training the model to minimize view synthesis errors based on segment flow, our appearance and motion pathways learn region segmentation and flow estimation automatically without building them up from low-level edges or optical flows respectively. Our model demonstrates the surprising emergence of objectness in the appearance pathway, surpassing prior works on zero-shot object segmentation from an image, moving object segmentation from a video with unsupervised test-time adaptation, and semantic image segmentation by supervised fine-tuning. Our work is the first truly end-to-end zero-shot object segmentation from videos. It not only develops generic objectness for segmentation and tracking, but also outperforms prevalent image-based contrastive learning methods without augmentation engineering.
Bootstrap Your Object Detector via Mixed Training
Nov 04, 2021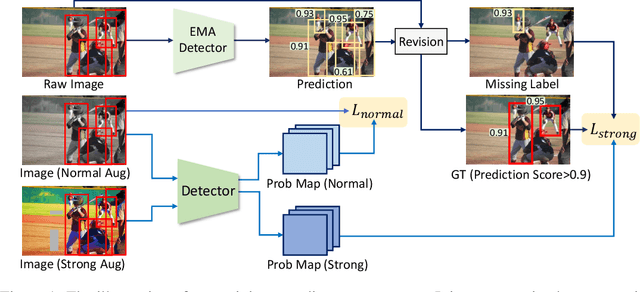


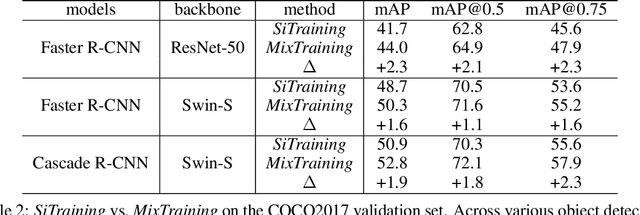
We introduce MixTraining, a new training paradigm for object detection that can improve the performance of existing detectors for free. MixTraining enhances data augmentation by utilizing augmentations of different strengths while excluding the strong augmentations of certain training samples that may be detrimental to training. In addition, it addresses localization noise and missing labels in human annotations by incorporating pseudo boxes that can compensate for these errors. Both of these MixTraining capabilities are made possible through bootstrapping on the detector, which can be used to predict the difficulty of training on a strong augmentation, as well as to generate reliable pseudo boxes thanks to the robustness of neural networks to labeling error. MixTraining is found to bring consistent improvements across various detectors on the COCO dataset. In particular, the performance of Faster R-CNN \cite{ren2015faster} with a ResNet-50 \cite{he2016deep} backbone is improved from 41.7 mAP to 44.0 mAP, and the accuracy of Cascade-RCNN \cite{cai2018cascade} with a Swin-Small \cite{liu2021swin} backbone is raised from 50.9 mAP to 52.8 mAP. The code and models will be made publicly available at \url{https://github.com/MendelXu/MixTraining}.
ACP++: Action Co-occurrence Priors for Human-Object Interaction Detection
Sep 09, 2021
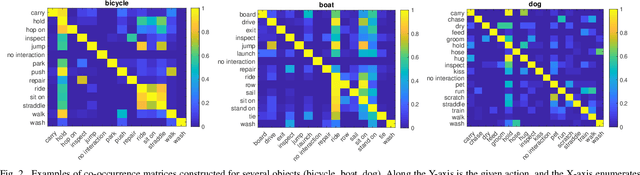
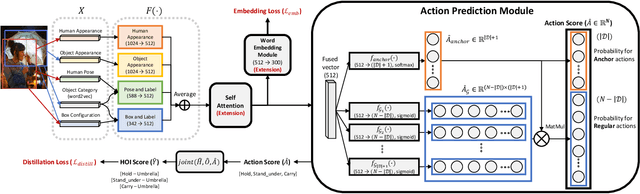

A common problem in the task of human-object interaction (HOI) detection is that numerous HOI classes have only a small number of labeled examples, resulting in training sets with a long-tailed distribution. The lack of positive labels can lead to low classification accuracy for these classes. Towards addressing this issue, we observe that there exist natural correlations and anti-correlations among human-object interactions. In this paper, we model the correlations as action co-occurrence matrices and present techniques to learn these priors and leverage them for more effective training, especially on rare classes. The efficacy of our approach is demonstrated experimentally, where the performance of our approach consistently improves over the state-of-the-art methods on both of the two leading HOI detection benchmark datasets, HICO-Det and V-COCO.
Video Swin Transformer
Jun 24, 2021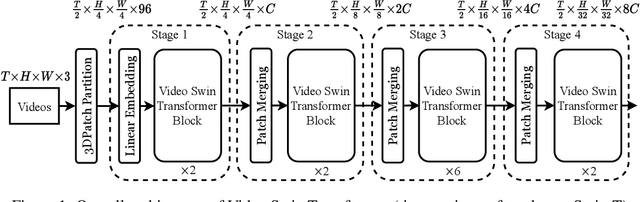
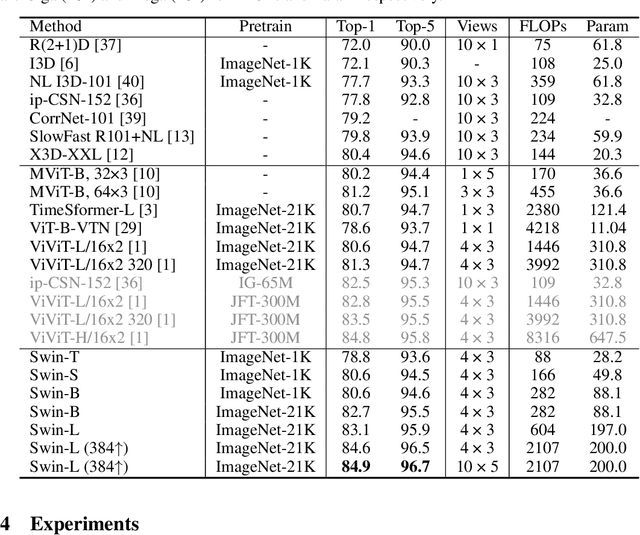
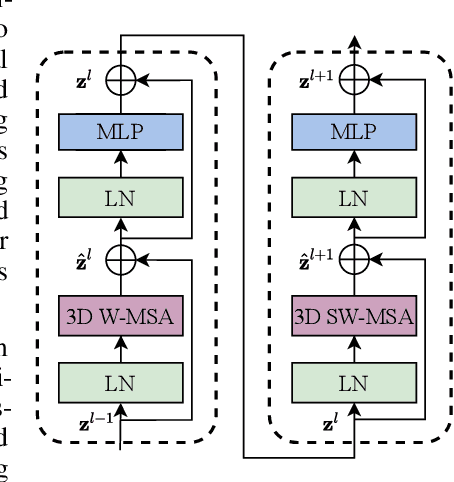
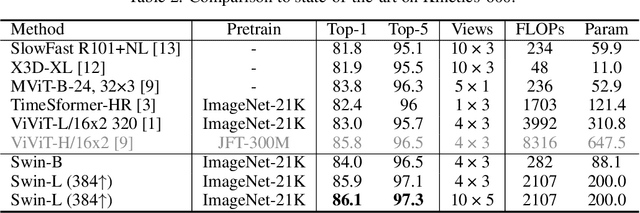
The vision community is witnessing a modeling shift from CNNs to Transformers, where pure Transformer architectures have attained top accuracy on the major video recognition benchmarks. These video models are all built on Transformer layers that globally connect patches across the spatial and temporal dimensions. In this paper, we instead advocate an inductive bias of locality in video Transformers, which leads to a better speed-accuracy trade-off compared to previous approaches which compute self-attention globally even with spatial-temporal factorization. The locality of the proposed video architecture is realized by adapting the Swin Transformer designed for the image domain, while continuing to leverage the power of pre-trained image models. Our approach achieves state-of-the-art accuracy on a broad range of video recognition benchmarks, including on action recognition (84.9 top-1 accuracy on Kinetics-400 and 86.1 top-1 accuracy on Kinetics-600 with ~20x less pre-training data and ~3x smaller model size) and temporal modeling (69.6 top-1 accuracy on Something-Something v2). The code and models will be made publicly available at https://github.com/SwinTransformer/Video-Swin-Transformer.
Aligning Pretraining for Detection via Object-Level Contrastive Learning
Jun 04, 2021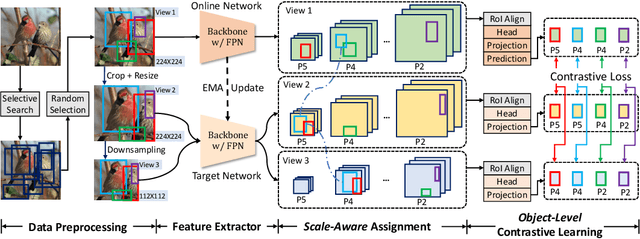
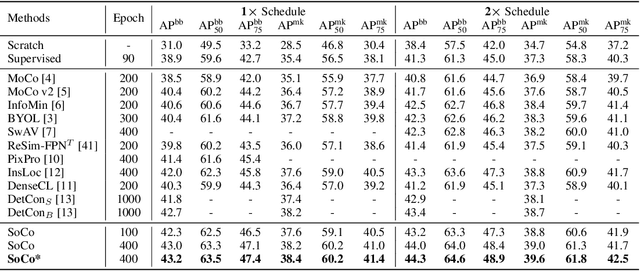
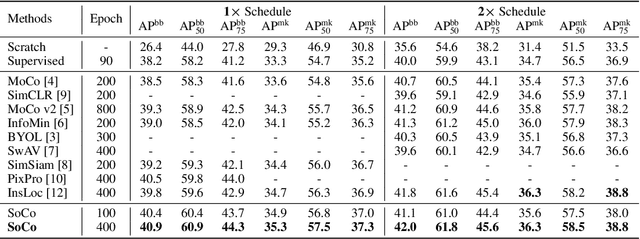

Image-level contrastive representation learning has proven to be highly effective as a generic model for transfer learning. Such generality for transfer learning, however, sacrifices specificity if we are interested in a certain downstream task. We argue that this could be sub-optimal and thus advocate a design principle which encourages alignment between the self-supervised pretext task and the downstream task. In this paper, we follow this principle with a pretraining method specifically designed for the task of object detection. We attain alignment in the following three aspects: 1) object-level representations are introduced via selective search bounding boxes as object proposals; 2) the pretraining network architecture incorporates the same dedicated modules used in the detection pipeline (e.g. FPN); 3) the pretraining is equipped with object detection properties such as object-level translation invariance and scale invariance. Our method, called Selective Object COntrastive learning (SoCo), achieves state-of-the-art results for transfer performance on COCO detection using a Mask R-CNN framework. Code and models will be made available.
Neural Articulated Radiance Field
Apr 07, 2021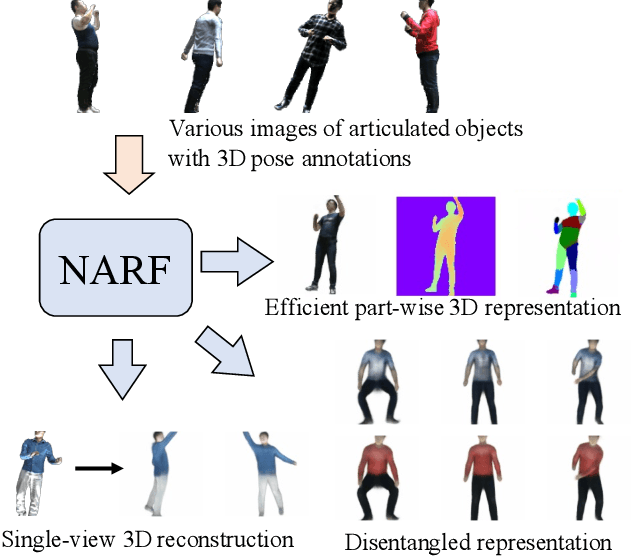
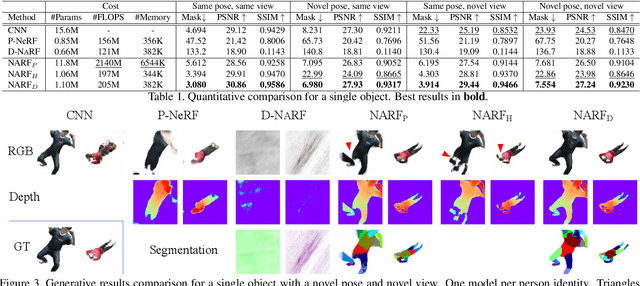
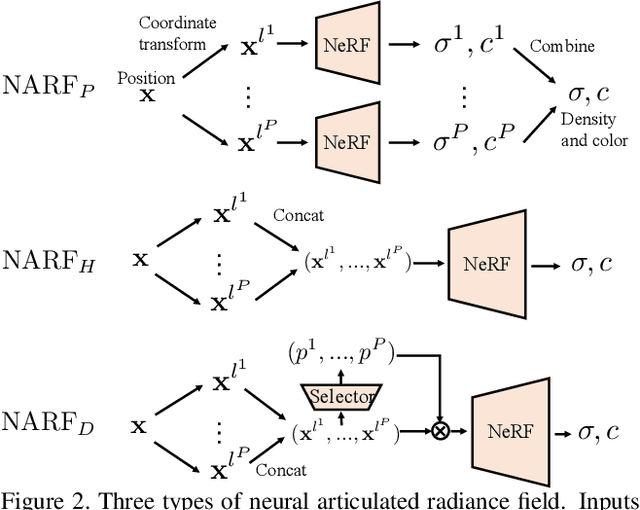
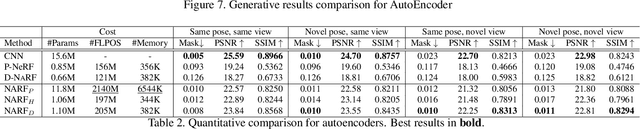
We present Neural Articulated Radiance Field (NARF), a novel deformable 3D representation for articulated objects learned from images. While recent advances in 3D implicit representation have made it possible to learn models of complex objects, learning pose-controllable representations of articulated objects remains a challenge, as current methods require 3D shape supervision and are unable to render appearance. In formulating an implicit representation of 3D articulated objects, our method considers only the rigid transformation of the most relevant object part in solving for the radiance field at each 3D location. In this way, the proposed method represents pose-dependent changes without significantly increasing the computational complexity. NARF is fully differentiable and can be trained from images with pose annotations. Moreover, through the use of an autoencoder, it can learn appearance variations over multiple instances of an object class. Experiments show that the proposed method is efficient and can generalize well to novel poses. We make the code, model and demo available for research purposes at https://github.com/nogu-atsu/NARF