 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-fine Q-attention with Tree Expansion
May 02, 2022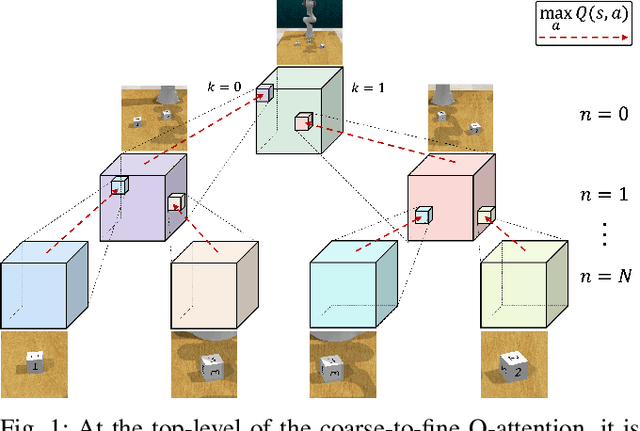


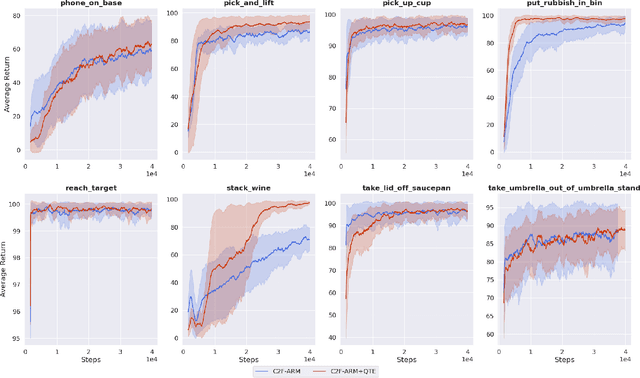
Coarse-to-fine Q-attention enables sample-efficient robot manipulation by discretizing the translation space in a coarse-to-fine manner, where the resolution gradually increases at each layer in the hierarchy. Although effective, Q-attention suffers from "coarse ambiguity" - when voxelization is significantly coarse, it is not feasible to distinguish similar-looking objects without first inspecting at a finer resolution. To combat this, we propose to envision Q-attention as a tree that can be expanded and used to accumulate value estimates across the top-k voxels at each Q-attention depth. When our extension, Q-attention with Tree Expansion (QTE), replaces standard Q-attention in the Attention-driven Robot Manipulation (ARM) system, we are able to accomplish a larger set of tasks; especially on those that suffer from "coarse ambiguity". In addition to evaluating our approach across 12 RLBench tasks, we also show that the improved performance is visible in a real-world task involving small objects.
Sim-to-Real 6D Object Pose Estimation via Iterative Self-training for Robotic Bin-picking
Apr 14, 2022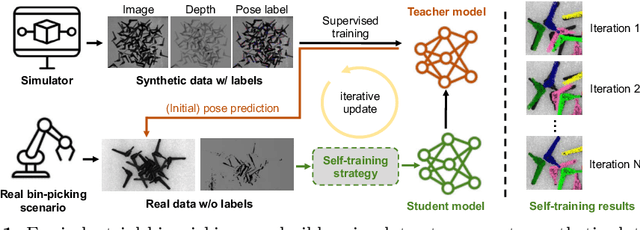
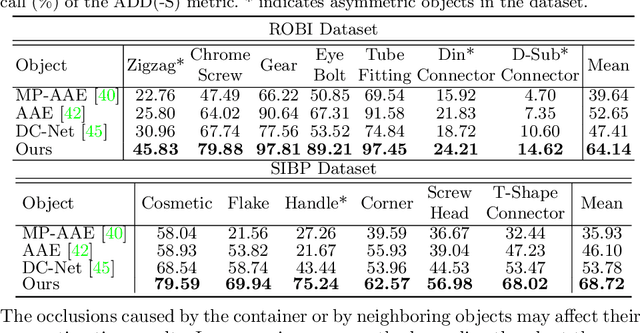
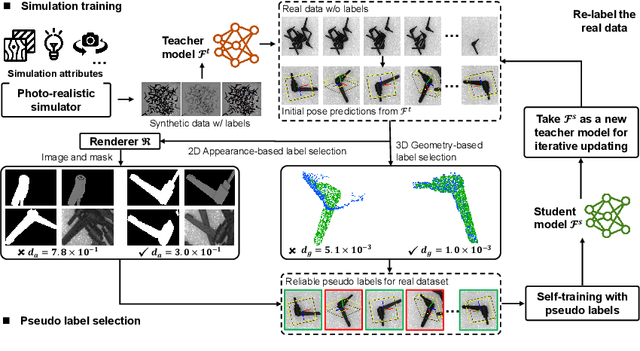
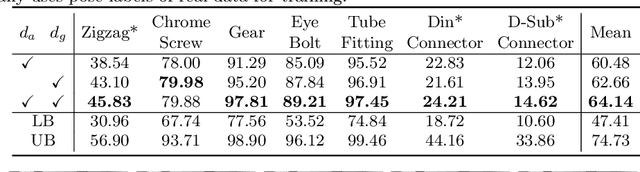
In this paper, we propose an iterative self-training framework for sim-to-real 6D object pose estimation to facilitate cost-effective robotic grasping. Given a bin-picking scenario, we establish a photo-realistic simulator to synthesize abundant virtual data, and use this to train an initial pose estimation network. This network then takes the role of a teacher model, which generates pose predictions for unlabeled real data. With these predictions, we further design a comprehensive adaptive selection scheme to distinguish reliable results, and leverage them as pseudo labels to update a student model for pose estimation on real data. To continuously improve the quality of pseudo labels, we iterate the above steps by taking the trained student model as a new teacher and re-label real data using the refined teacher model. We evaluate our method on a public benchmark and our newly-released dataset, achieving an ADD(-S) improvement of 11.49% and 22.62% respectively. Our method is also able to improve robotic bin-picking success by 19.54%, demonstrating the potential of iterative sim-to-real solutions for robotic applications.
Coarse-to-Fine Q-attention with Learned Path Ranking
Apr 04, 2022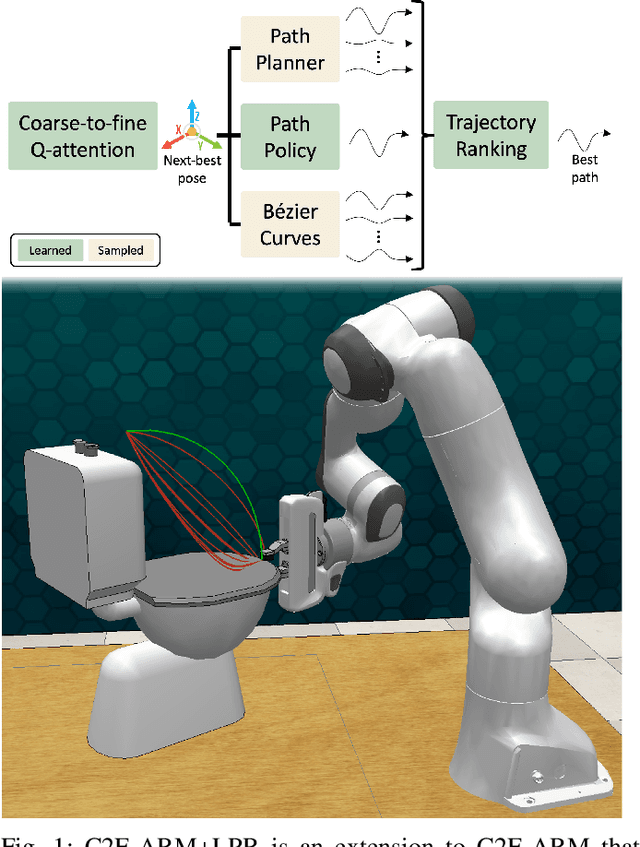

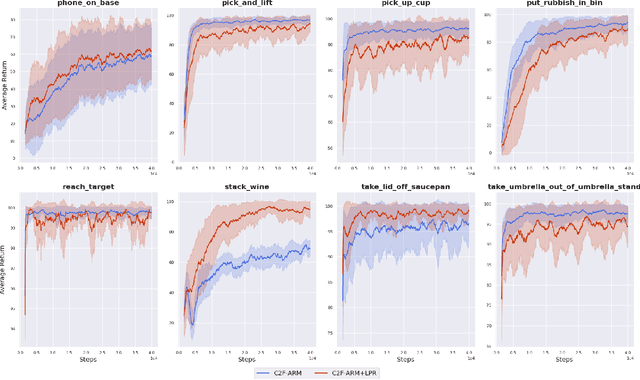
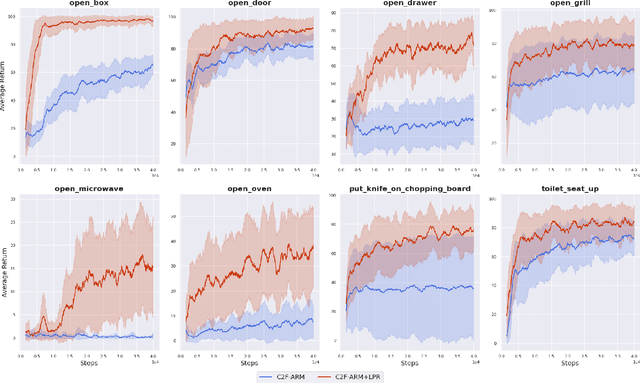
We propose Learned Path Ranking (LPR), a method that accepts an end-effector goal pose, and learns to rank a set of goal-reaching paths generated from an array of path generating methods, including: path planning, Bezier curve sampling, and a learned policy. The core idea being that each of the path generation modules will be useful in different tasks, or at different stages in a task. When LPR is added as an extension to C2F-ARM, our new system, C2F-ARM+LPR, retains the sample efficiency of its predecessor, while also being able to accomplish a larger set of tasks; in particular, tasks that require very specific motions (e.g. opening toilet seat) that need to be inferred from both demonstrations and exploration data. In addition to benchmarking our approach across 16 RLBench tasks, we also learn real-world tasks, tabula rasa, in 10-15 minutes, with only 3 demonstrations.
Reinforcement Learning with Action-Free Pre-Training from Videos
Mar 25, 2022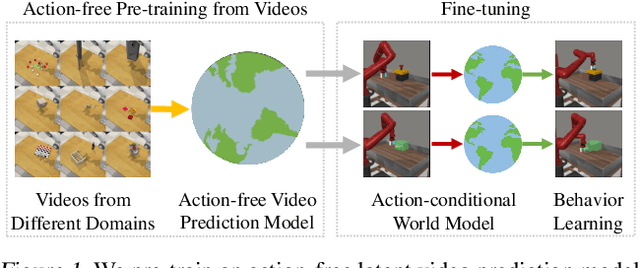
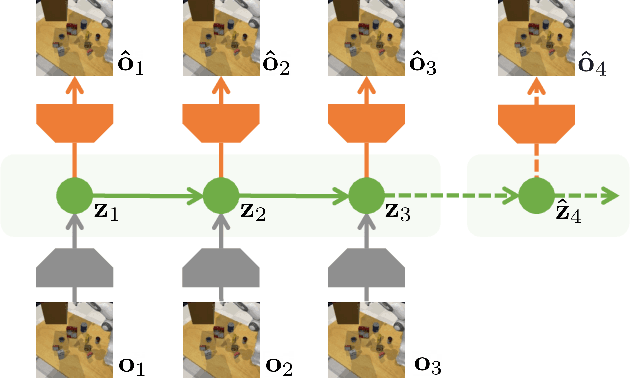
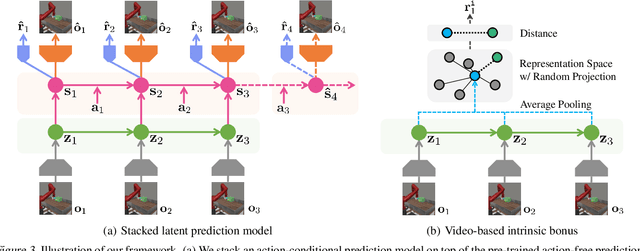
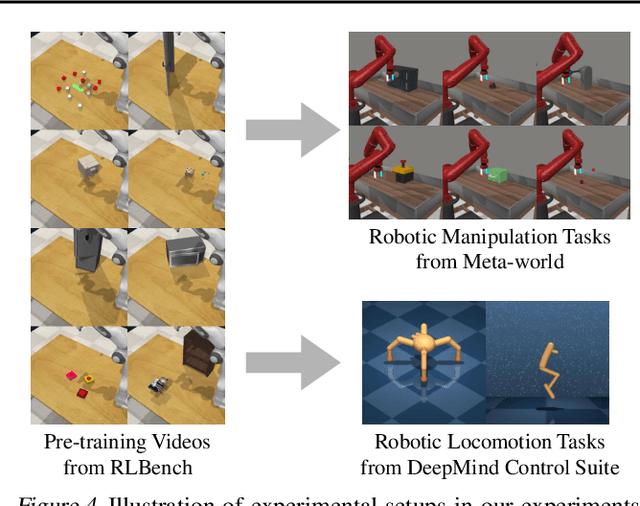
Recent unsupervised pre-training methods have shown to be effective on language and vision domains by learning useful representations for multiple downstream tasks. In this paper, we investigate if such unsupervised pre-training methods can also be effective for vision-based reinforcement learning (RL). To this end, we introduce a framework that learns representations useful for understanding the dynamics via generative pre-training on videos. Our framework consists of two phases: we pre-train an action-free latent video prediction model, and then utilize the pre-trained representations for efficiently learning action-conditional world models on unseen environments. To incorporate additional action inputs during fine-tuning, we introduce a new architecture that stacks an action-conditional latent prediction model on top of the pre-trained action-free prediction model. Moreover, for better exploration, we propose a video-based intrinsic bonus that leverages pre-trained representations. We demonstrate that our framework significantly improves both final performances and sample-efficiency of vision-based RL in a variety of manipulation and locomotion tasks. Code is available at https://github.com/younggyoseo/apv.
SafePicking: Learning Safe Object Extraction via Object-Level Mapping
Mar 01, 2022
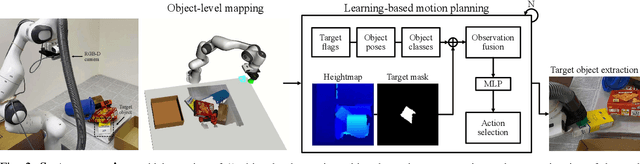
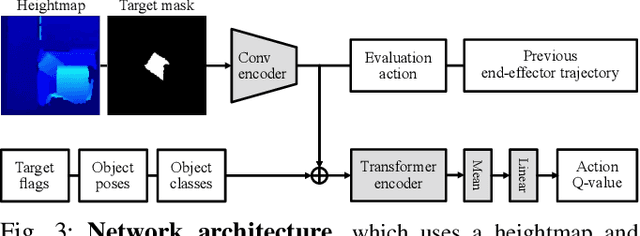

Robots need object-level scene understanding to manipulate objects while reasoning about contact, support, and occlusion among objects. Given a pile of objects, object recognition and reconstruction can identify the boundary of object instances, giving important cues as to how the objects form and support the pile. In this work, we present a system, SafePicking, that integrates object-level mapping and learning-based motion planning to generate a motion that safely extracts occluded target objects from a pile. Planning is done by learning a deep Q-network that receives observations of predicted poses and a depth-based heightmap to output a motion trajectory, trained to maximize a safety metric reward. Our results show that the observation fusion of poses and depth-sensing gives both better performance and robustness to the model. We evaluate our methods using the YCB objects in both simulation and the real world, achieving safe object extraction from piles.
ReorientBot: Learning Object Reorientation for Specific-Posed Placement
Feb 22, 2022
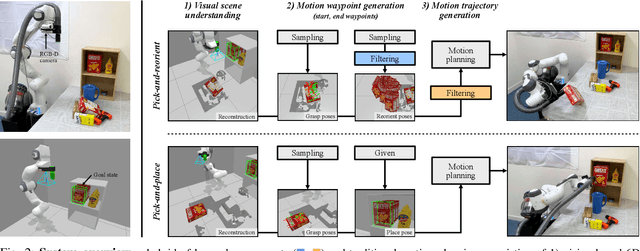
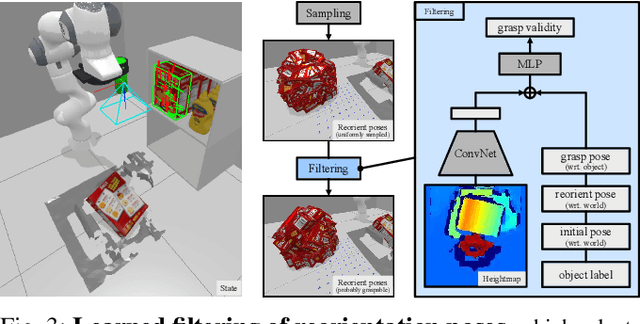
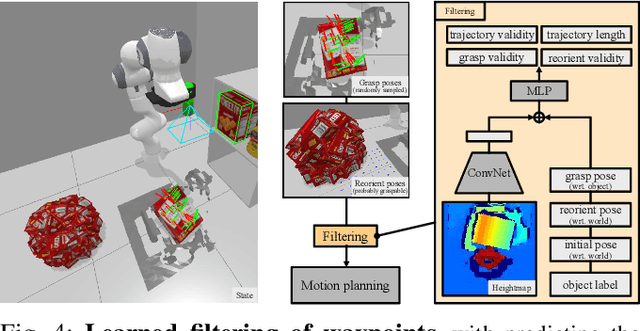
Robots need the capability of placing objects in arbitrary, specific poses to rearrange the world and achieve various valuable tasks. Object reorientation plays a crucial role in this as objects may not initially be oriented such that the robot can grasp and then immediately place them in a specific goal pose. In this work, we present a vision-based manipulation system, ReorientBot, which consists of 1) visual scene understanding with pose estimation and volumetric reconstruction using an onboard RGB-D camera; 2) learned waypoint selection for successful and efficient motion generation for reorientation; 3) traditional motion planning to generate a collision-free trajectory from the selected waypoints. We evaluate our method using the YCB objects in both simulation and the real world, achieving 93% overall success, 81% improvement in success rate, and 22% improvement in execution time compared to a heuristic approach. We demonstrate extended multi-object rearrangement showing the general capability of the system.
Bingham Policy Parameterization for 3D Rotations in Reinforcement Learning
Feb 08, 2022We propose a new policy parameterization for representing 3D rotations during reinforcement learning. Today in the continuous control reinforcement learning literature, many stochastic policy parameterizations are Gaussian. We argue that universally applying a Gaussian policy parameterization is not always desirable for all environments. One such case in particular where this is true are tasks that involve predicting a 3D rotation output, either in isolation, or coupled with translation as part of a full 6D pose output. Our proposed Bingham Policy Parameterization (BPP) models the Bingham distribution and allows for better rotation (quaternion) prediction over a Gaussian policy parameterization in a range of reinforcement learning tasks. We evaluate BPP on the rotation Wahba problem task, as well as a set of vision-based next-best pose robot manipulation tasks from RLBench. We hope that this paper encourages more research into developing other policy parameterization that are more suited for particular environments, rather than always assuming Gaussian.
Auto-Lambda: Disentangling Dynamic Task Relationships
Feb 07, 2022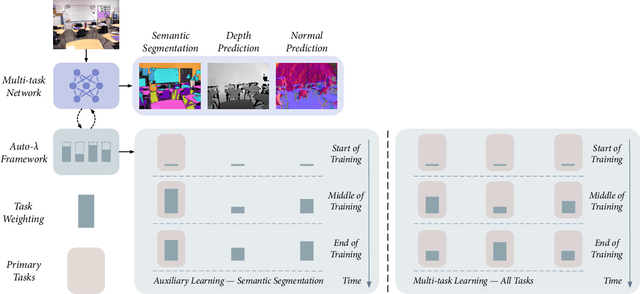
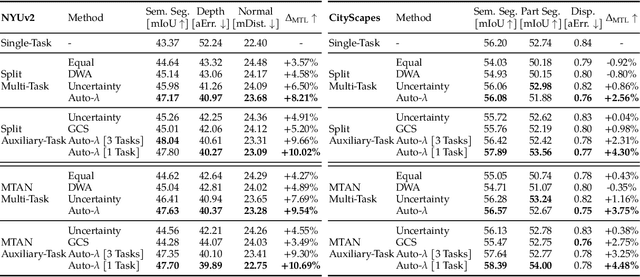
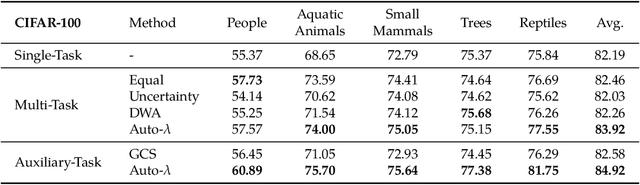

Understanding the structure of multiple related tasks allows for multi-task learning to improve the generalisation ability of one or all of them. However, it usually requires training each pairwise combination of tasks together in order to capture task relationships, at an extremely high computational cost. In this work, we learn task relationships via an automated weighting framework, named Auto-Lambda. Unlike previous methods where task relationships are assumed to be fixed, Auto-Lambda is a gradient-based meta learning framework which explores continuous, dynamic task relationships via task-specific weightings, and can optimise any choice of combination of tasks through the formulation of a meta-loss; where the validation loss automatically influences task weightings throughout training. We apply the proposed framework to both multi-task and auxiliary learning problems in computer vision and robotics, and show that Auto-Lambda achieves state-of-the-art performance, even when compared to optimisation strategies designed specifically for each problem and data domain. Finally, we observe that Auto-Lambda can discover interesting learning behaviors, leading to new insights in multi-task learning. Code is available at https://github.com/lorenmt/auto-lambda.
Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation
Jun 23, 2021
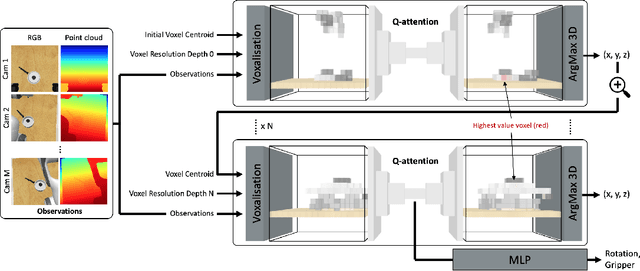
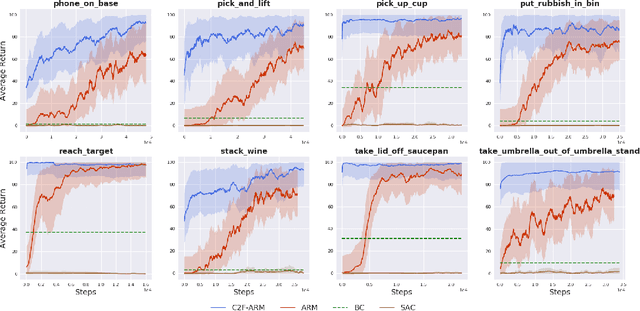
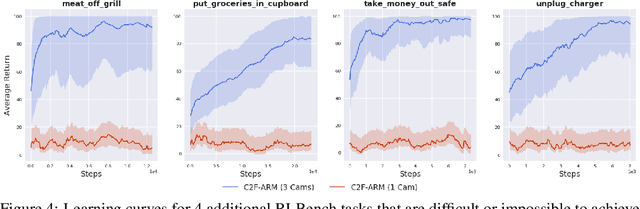
Reflecting on the last few years, the biggest breakthroughs in deep reinforcement learning (RL) have been in the discrete action domain. Robotic manipulation, however, is inherently a continuous control environment, but these continuous control reinforcement learning algorithms often depend on actor-critic methods that are sample-inefficient and inherently difficult to train, due to the joint optimisation of the actor and critic. To that end, we explore how we can bring the stability of discrete action RL algorithms to the robot manipulation domain. We extend the recently released ARM algorithm, by replacing the continuous next-best pose agent with a discrete next-best pose agent. Discretisation of rotation is trivial given its bounded nature, while translation is inherently unbounded, making discretisation difficult. We formulate the translation prediction as the voxel prediction problem by discretising the 3D space; however, voxelisation of a large workspace is memory intensive and would not work with a high density of voxels, crucial to obtaining the resolution needed for robotic manipulation. We therefore propose to apply this voxel prediction in a coarse-to-fine manner by gradually increasing the resolution. In each step, we extract the highest valued voxel as the predicted location, which is then used as the centre of the higher-resolution voxelisation in the next step. This coarse-to-fine prediction is applied over several steps, giving a near-lossless prediction of the translation. We show that our new coarse-to-fine algorithm is able to accomplish RLBench tasks much more efficiently than the continuous control equivalent, and even train some real-world tasks, tabular rasa, in less than 7 minutes, with only 3 demonstrations. Moreover, we show that by moving to a voxel representation, we are able to easily incorporate observations from multiple cameras.
Q-attention: Enabling Efficient Learning for Vision-based Robotic Manipulation
May 31, 2021
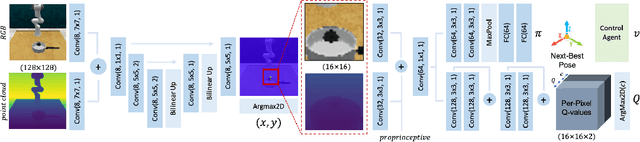
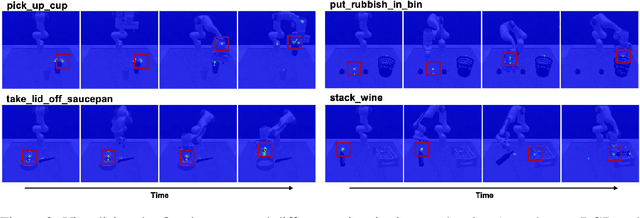
Despite the success of reinforcement learning methods, they have yet to have their breakthrough moment when applied to a broad range of robotic manipulation tasks. This is partly due to the fact that reinforcement learning algorithms are notoriously difficult and time consuming to train, which is exacerbated when training from images rather than full-state inputs. As humans perform manipulation tasks, our eyes closely monitor every step of the process with our gaze focusing sequentially on the objects being manipulated. With this in mind, we present our Attention-driven Robotic Manipulation (ARM) algorithm, which is a general manipulation algorithm that can be applied to a range of sparse-rewarded tasks, given only a small number of demonstrations. ARM splits the complex task of manipulation into a 3 stage pipeline: (1) a Q-attention agent extracts interesting pixel locations from RGB and point cloud inputs, (2) a next-best pose agent that accepts crops from the Q-attention agent and outputs poses, and (3) a control agent that takes the goal pose and outputs joint actions. We show that current learning algorithms fail on a range of RLBench tasks, whilst ARM is successful.