 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating High Order Gradients of the Data Distribution by Denoising
Nov 08, 2021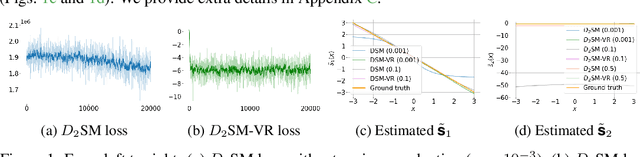

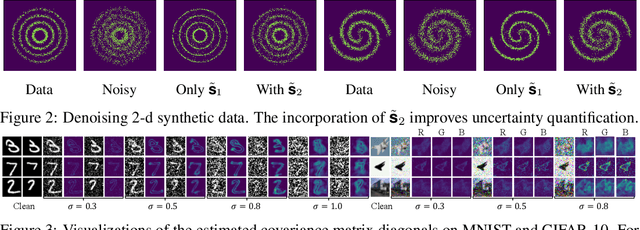

The first order derivative of a data density can be estimated efficiently by denoising score matching, and has become an important component in many applications, such as image generation and audio synthesis. Higher order derivatives provide additional local information about the data distribution and enable new applications. Although they can be estimated via automatic differentiation of a learned density model, this can amplify estimation errors and is expensive in high dimensional settings. To overcome these limitations, we propose a method to directly estimate high order derivatives (scores) of a data density from samples. We first show that denoising score matching can be interpreted as a particular case of Tweedie's formula. By leveraging Tweedie's formula on higher order moments, we generalize denoising score matching to estimate higher order derivatives. We demonstrate empirically that models trained with the proposed method can approximate second order derivatives more efficiently and accurately than via automatic differentiation. We show that our models can be used to quantify uncertainty in denoising and to improve the mixing speed of Langevin dynamics via Ozaki discretization for sampling synthetic data and natural images.
SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
Nov 08, 2021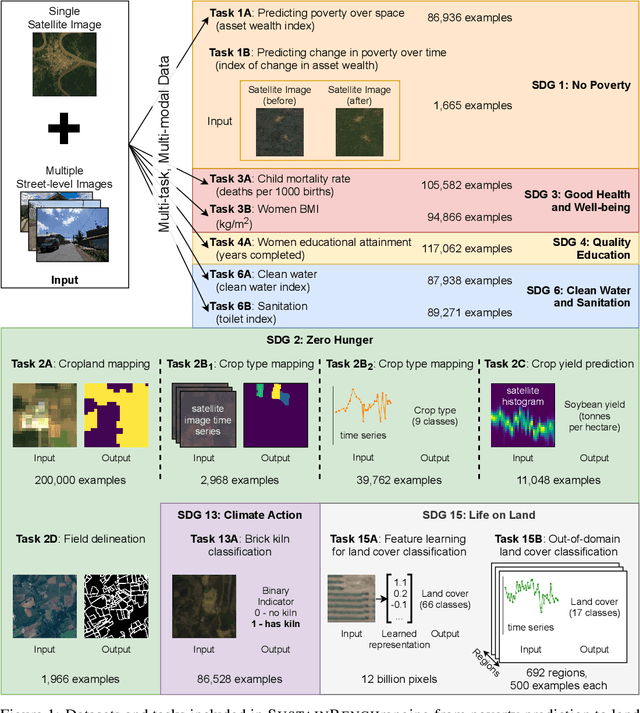
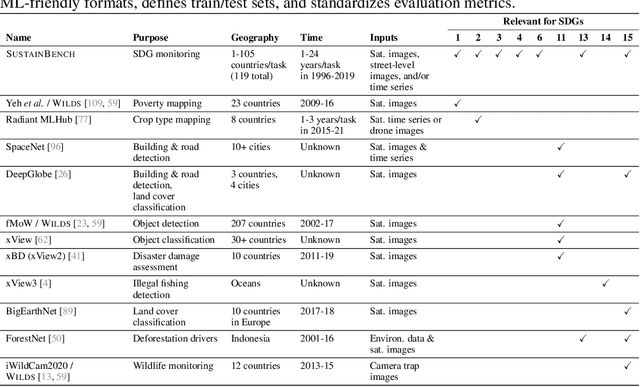
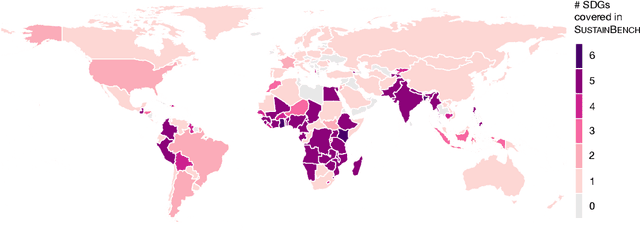
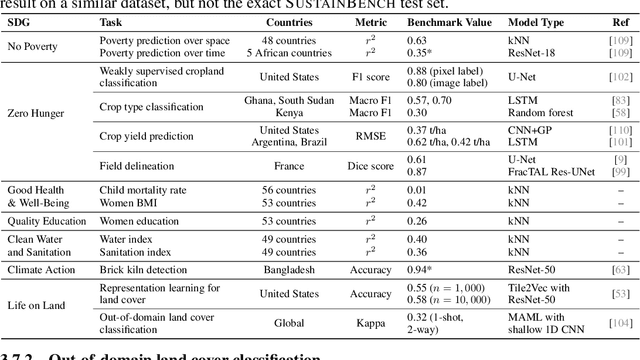
Progress toward the United Nations Sustainable Development Goals (SDGs) has been hindered by a lack of data on key environmental and socioeconomic indicators, which historically have come from ground surveys with sparse temporal and spatial coverage. Recent advances in machine learning have made it possible to utilize abundant, frequently-updated, and globally available data, such as from satellites or social media, to provide insights into progress toward SDGs. Despite promising early results, approaches to using such data for SDG measurement thus far have largely evaluated on different datasets or used inconsistent evaluation metrics, making it hard to understand whether performance is improving and where additional research would be most fruitful. Furthermore, processing satellite and ground survey data requires domain knowledge that many in the machine learning community lack. In this paper, we introduce SustainBench, a collection of 15 benchmark tasks across 7 SDGs, including tasks related to economic development, agriculture, health, education, water and sanitation, climate action, and life on land. Datasets for 11 of the 15 tasks are released publicly for the first time. Our goals for SustainBench are to (1) lower the barriers to entry for the machine learning community to contribute to measuring and achieving the SDGs; (2) provide standard benchmarks for evaluating machine learning models on tasks across a variety of SDGs; and (3) encourage the development of novel machine learning methods where improved model performance facilitates progress towards the SDGs.
Pseudo-Spherical Contrastive Divergence
Nov 01, 2021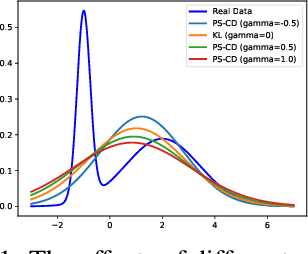
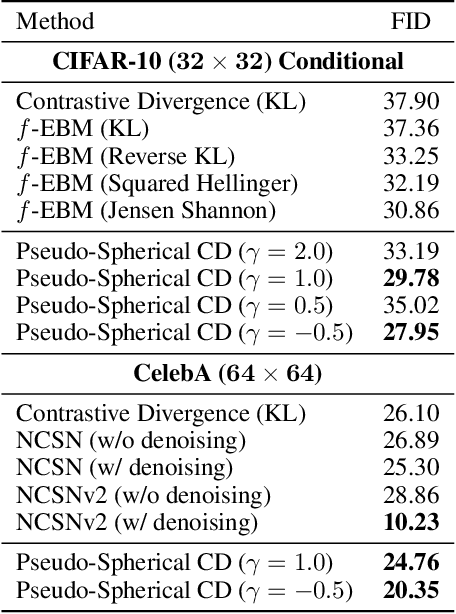

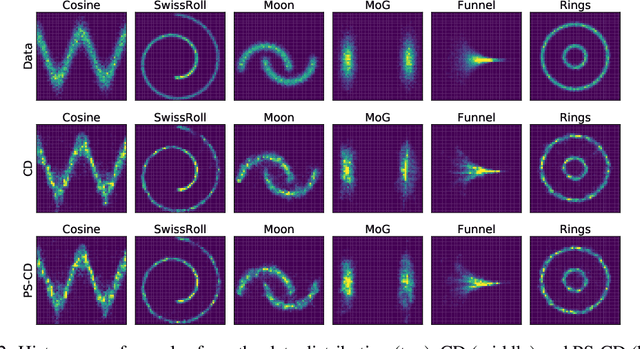
Energy-based models (EBMs) offer flexible distribution parametrization. However, due to the intractable partition function, they are typically trained via contrastive divergence for maximum likelihood estimation. In this paper, we propose pseudo-spherical contrastive divergence (PS-CD) to generalize maximum likelihood learning of EBMs. PS-CD is derived from the maximization of a family of strictly proper homogeneous scoring rules, which avoids the computation of the intractable partition function and provides a generalized family of learning objectives that include contrastive divergence as a special case. Moreover, PS-CD allows us to flexibly choose various learning objectives to train EBMs without additional computational cost or variational minimax optimization. Theoretical analysis on the proposed method and extensive experiments on both synthetic data and commonly used image datasets demonstrate the effectiveness and modeling flexibility of PS-CD, as well as its robustness to data contamination, thus showing its superiority over maximum likelihood and $f$-EBMs.
Equivariant Neural Network for Factor Graphs
Sep 29, 2021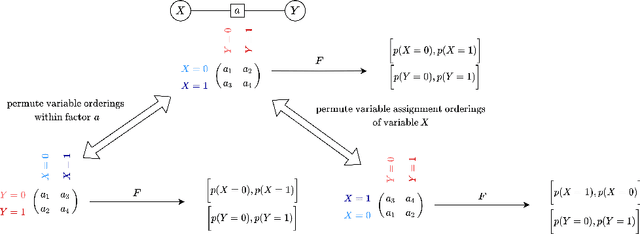

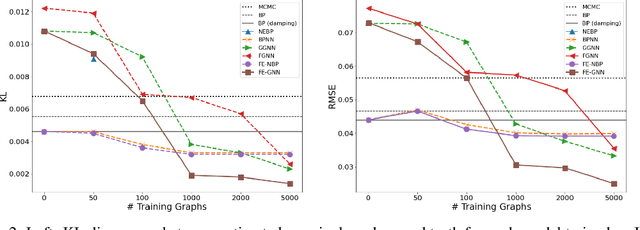
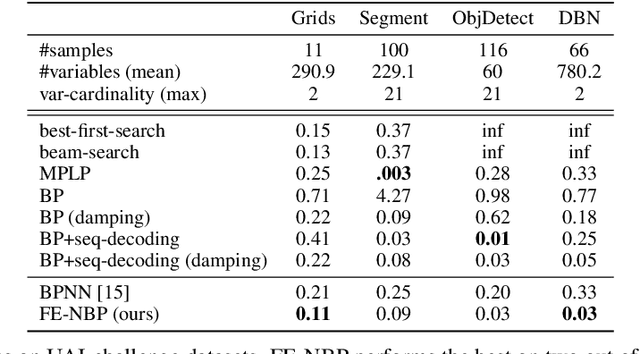
Several indices used in a factor graph data structure can be permuted without changing the underlying probability distribution. An algorithm that performs inference on a factor graph should ideally be equivariant or invariant to permutations of global indices of nodes, variable orderings within a factor, and variable assignment orderings. However, existing neural network-based inference procedures fail to take advantage of this inductive bias. In this paper, we precisely characterize these isomorphic properties of factor graphs and propose two inference models: Factor-Equivariant Neural Belief Propagation (FE-NBP) and Factor-Equivariant Graph Neural Networks (FE-GNN). FE-NBP is a neural network that generalizes BP and respects each of the above properties of factor graphs while FE-GNN is an expressive GNN model that relaxes an isomorphic property in favor of greater expressivity. Empirically, we demonstrate on both real-world and synthetic datasets, for both marginal inference and MAP inference, that FE-NBP and FE-GNN together cover a range of sample complexity regimes: FE-NBP achieves state-of-the-art performance on small datasets while FE-GNN achieves state-of-the-art performance on large datasets.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
SDEdit: Image Synthesis and Editing with Stochastic Differential Equations
Aug 02, 2021
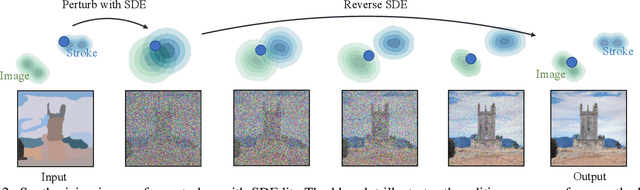
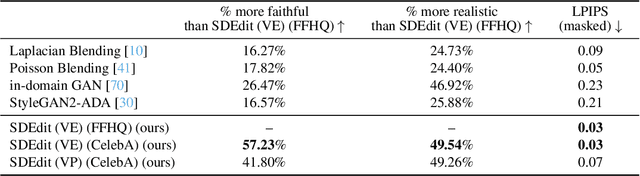

We introduce a new image editing and synthesis framework, Stochastic Differential Editing (SDEdit), based on a recent generative model using stochastic differential equations (SDEs). Given an input image with user edits (e.g., hand-drawn color strokes), we first add noise to the input according to an SDE, and subsequently denoise it by simulating the reverse SDE to gradually increase its likelihood under the prior. Our method does not require task-specific loss function designs, which are critical components for recent image editing methods based on GAN inversion. Compared to conditional GANs, we do not need to collect new datasets of original and edited images for new applications. Therefore, our method can quickly adapt to various editing tasks at test time without re-training models. Our approach achieves strong performance on a wide range of applications, including image synthesis and editing guided by stroke paintings and image compositing.
Calibrating Predictions to Decisions: A Novel Approach to Multi-Class Calibration
Jul 12, 2021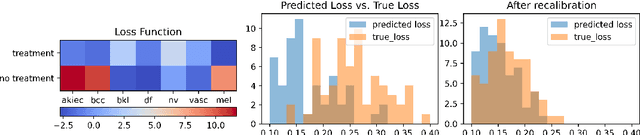


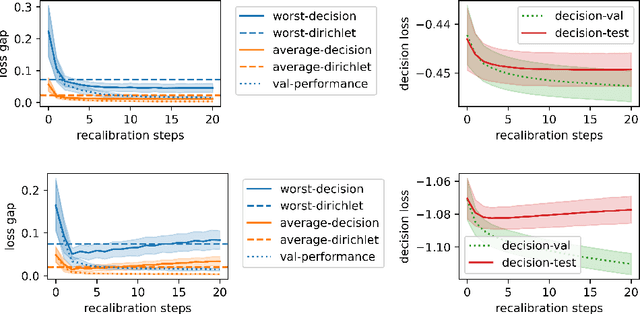
When facing uncertainty, decision-makers want predictions they can trust. A machine learning provider can convey confidence to decision-makers by guaranteeing their predictions are distribution calibrated -- amongst the inputs that receive a predicted class probabilities vector $q$, the actual distribution over classes is $q$. For multi-class prediction problems, however, achieving distribution calibration tends to be infeasible, requiring sample complexity exponential in the number of classes $C$. In this work, we introduce a new notion -- \emph{decision calibration} -- that requires the predicted distribution and true distribution to be ``indistinguishable'' to a set of downstream decision-makers. When all possible decision makers are under consideration, decision calibration is the same as distribution calibration. However, when we only consider decision makers choosing between a bounded number of actions (e.g. polynomial in $C$), our main result shows that decisions calibration becomes feasible -- we design a recalibration algorithm that requires sample complexity polynomial in the number of actions and the number of classes. We validate our recalibration algorithm empirically: compared to existing methods, decision calibration improves decision-making on skin lesion and ImageNet classification with modern neural network predictors.
Multi-Agent Imitation Learning with Copulas
Jul 10, 2021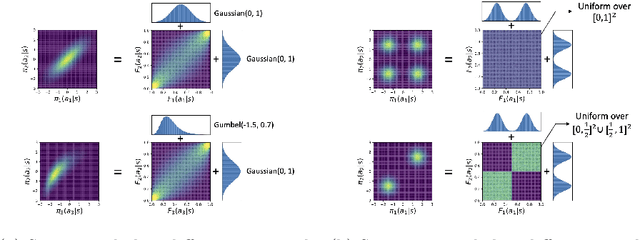
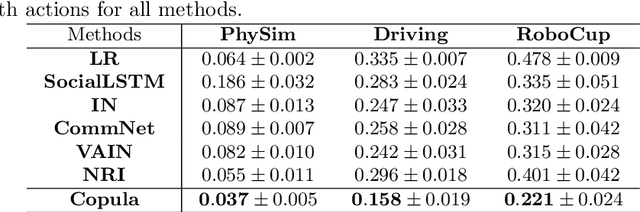
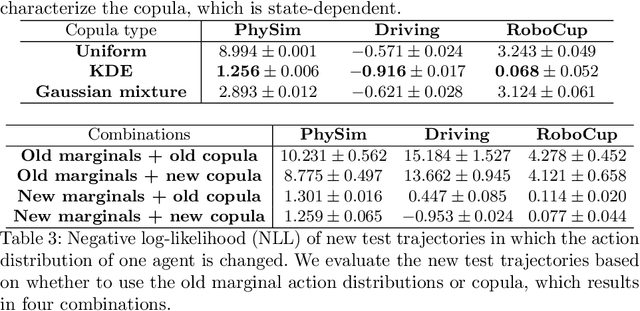
Multi-agent imitation learning aims to train multiple agents to perform tasks from demonstrations by learning a mapping between observations and actions, which is essential for understanding physical, social, and team-play systems. However, most existing works on modeling multi-agent interactions typically assume that agents make independent decisions based on their observations, ignoring the complex dependence among agents. In this paper, we propose to use copula, a powerful statistical tool for capturing dependence among random variables, to explicitly model the correlation and coordination in multi-agent systems. Our proposed model is able to separately learn marginals that capture the local behavioral patterns of each individual agent, as well as a copula function that solely and fully captures the dependence structure among agents. Extensive experiments on synthetic and real-world datasets show that our model outperforms state-of-the-art baselines across various scenarios in the action prediction task, and is able to generate new trajectories close to expert demonstrations.
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation
Jul 07, 2021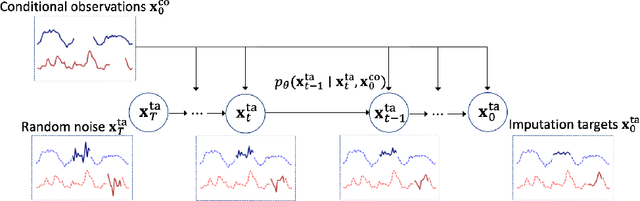

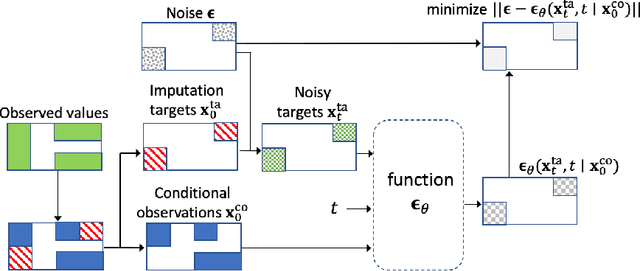
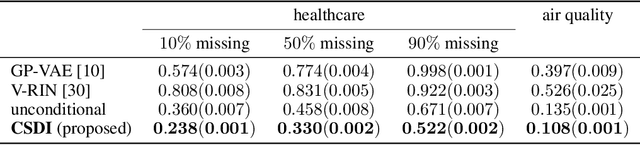
The imputation of missing values in time series has many applications in healthcare and finance. While autoregressive models are natural candidates for time series imputation, score-based diffusion models have recently outperformed existing counterparts including autoregressive models in many tasks such as image generation and audio synthesis, and would be promising for time series imputation. In this paper, we propose Conditional Score-based Diffusion models for Imputation (CSDI), a novel time series imputation method that utilizes score-based diffusion models conditioned on observed data. Unlike existing score-based approaches, the conditional diffusion model is explicitly trained for imputation and can exploit correlations between observed values. On healthcare and environmental data, CSDI improves by 40-70% over existing probabilistic imputation methods on popular performance metrics. In addition, deterministic imputation by CSDI reduces the error by 5-20% compared to the state-of-the-art deterministic imputation methods. Furthermore, CSDI can also be applied to time series interpolation and probabilistic forecasting, and is competitive with existing baselines.
Featurized Density Ratio Estimation
Jul 05, 2021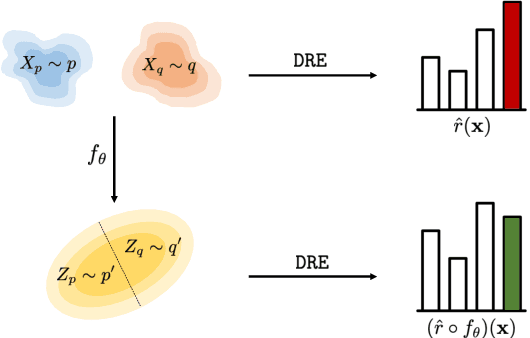

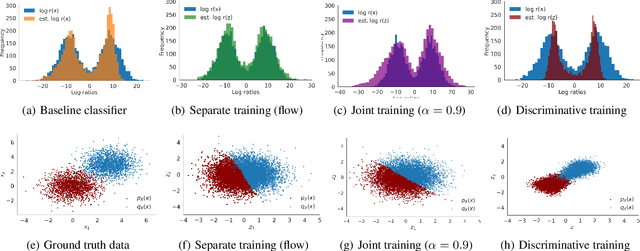
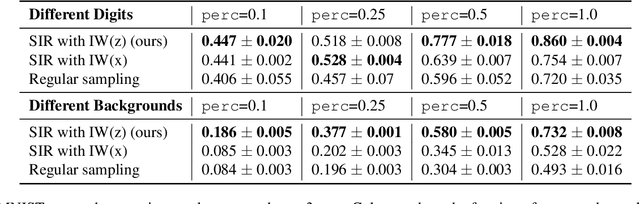
Density ratio estimation serves as an important technique in the unsupervised machine learning toolbox. However, such ratios are difficult to estimate for complex, high-dimensional data, particularly when the densities of interest are sufficiently different. In our work, we propose to leverage an invertible generative model to map the two distributions into a common feature space prior to estimation. This featurization brings the densities closer together in latent space, sidestepping pathological scenarios where the learned density ratios in input space can be arbitrarily inaccurate. At the same time, the invertibility of our feature map guarantees that the ratios computed in feature space are equivalent to those in input space. Empirically, we demonstrate the efficacy of our approach in a variety of downstream tasks that require access to accurate density ratios such as mutual information estimation, targeted sampling in deep generative models, and classification with data augmentation.