 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo Correspondence and Reconstruction of Endoscopic Data Challenge
Jan 28, 2021

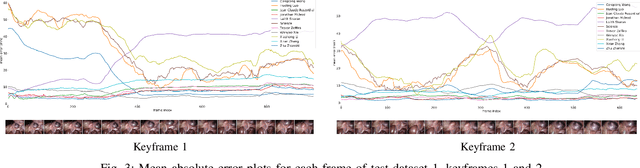
The stereo correspondence and reconstruction of endoscopic data sub-challenge was organized during the Endovis challenge at MICCAI 2019 in Shenzhen, China. The task was to perform dense depth estimation using 7 training datasets and 2 test sets of structured light data captured using porcine cadavers. These were provided by a team at Intuitive Surgical. 10 teams participated in the challenge day. This paper contains 3 additional methods which were submitted after the challenge finished as well as a supplemental section from these teams on issues they found with the dataset.
SERV-CT: A disparity dataset from CT for validation of endoscopic 3D reconstruction
Dec 22, 2020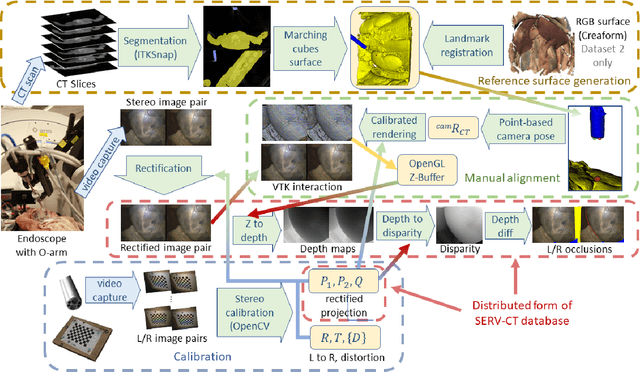
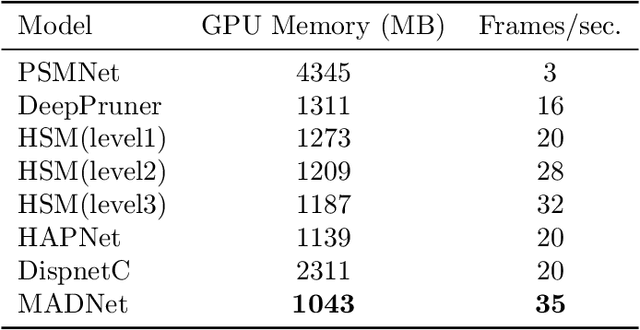
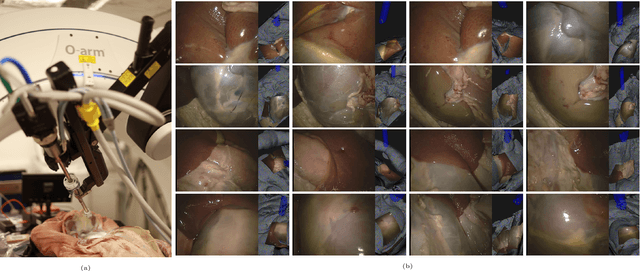
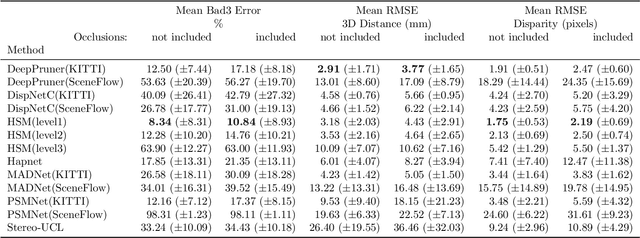
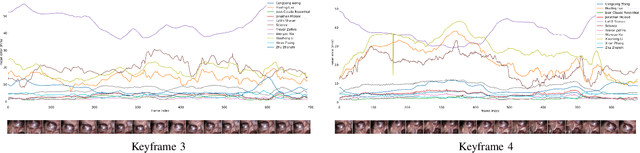
In computer vision, reference datasets have been highly successful in promoting algorithmic development in stereo reconstruction. Surgical scenes gives rise to specific problems, including the lack of clear corner features, highly specular surfaces and the presence of blood and smoke. Publicly available datasets have been produced using CT and either phantom images or biological tissue samples covering a relatively small region of the endoscope field-of-view. We present a stereo-endoscopic reconstruction validation dataset based on CT (SERV-CT). Two {\it ex vivo} small porcine full torso cadavers were placed within the view of the endoscope with both the endoscope and target anatomy visible in the CT scan. Orientation of the endoscope was manually aligned to the stereoscopic view. Reference disparities and occlusions were calculated for 8 stereo pairs from each sample. For the second sample an RGB surface was acquired to aid alignment of smooth, featureless surfaces. Repeated manual alignments showed an RMS disparity accuracy of ~2 pixels and a depth accuracy of ~2mm. The reference dataset includes endoscope image pairs with corresponding calibration, disparities, depths and occlusions covering the majority of the endoscopic image and a range of tissue types. Smooth specular surfaces and images with significant variation of depth are included. We assessed the performance of various stereo algorithms from online available repositories. There is a significant variation between algorithms, highlighting some of the challenges of surgical endoscopic images. The SERV-CT dataset provides an easy to use stereoscopic validation for surgical applications with smooth reference disparities and depths with coverage over the majority of the endoscopic images. This complements existing resources well and we hope will aid the development of surgical endoscopic anatomical reconstruction algorithms.
Surgical Data Science -- from Concepts to Clinical Translation
Oct 30, 2020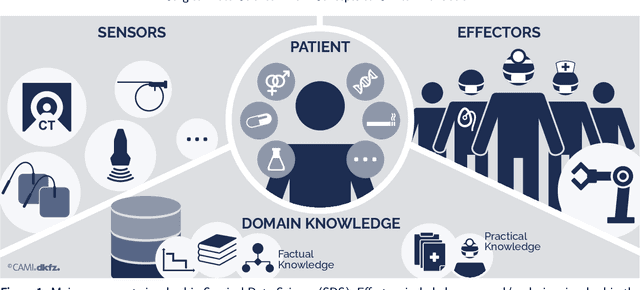
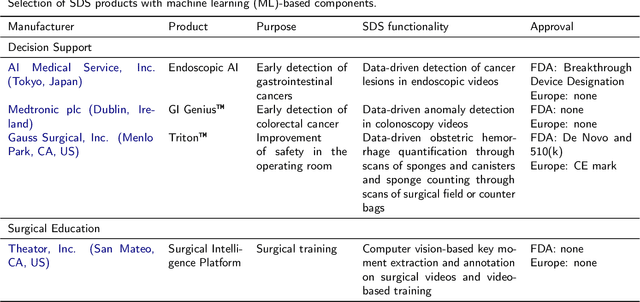
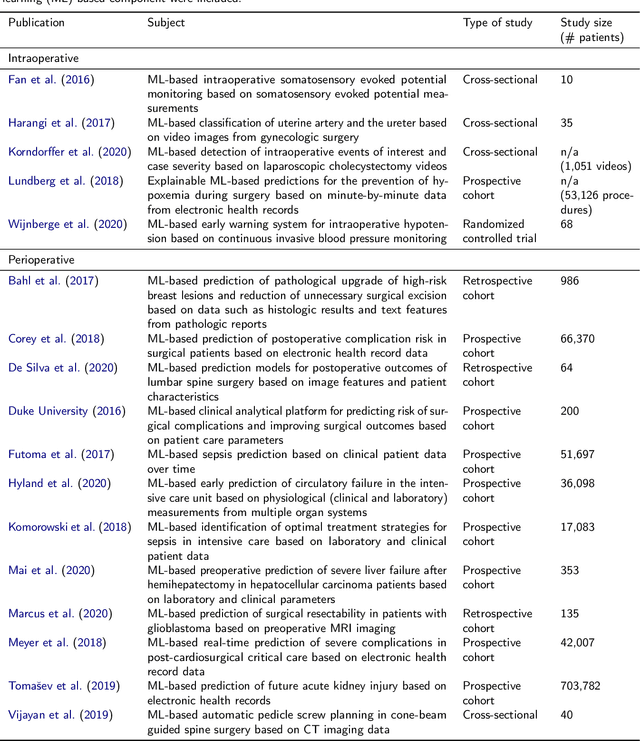
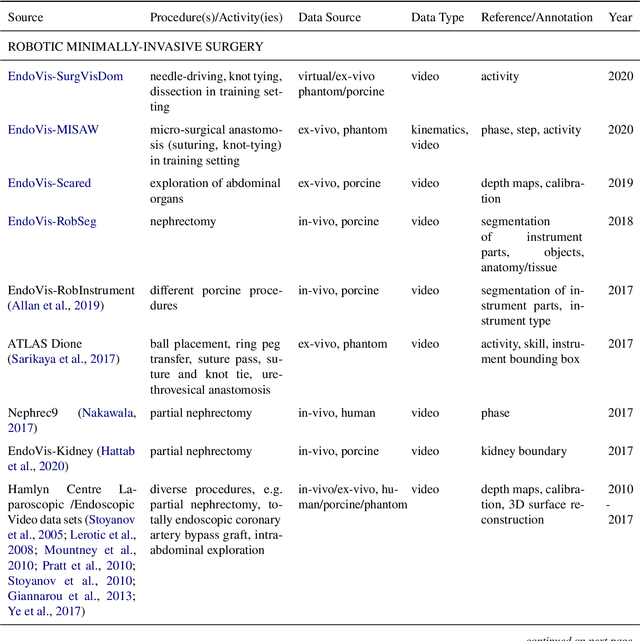
Recent developments in data science in general and machine learning in particular have transformed the way experts envision the future of surgery. Surgical data science is a new research field that aims to improve the quality of interventional healthcare through the capture, organization, analysis and modeling of data. While an increasing number of data-driven approaches and clinical applications have been studied in the fields of radiological and clinical data science, translational success stories are still lacking in surgery. In this publication, we shed light on the underlying reasons and provide a roadmap for future advances in the field. Based on an international workshop involving leading researchers in the field of surgical data science, we review current practice, key achievements and initiatives as well as available standards and tools for a number of topics relevant to the field, namely (1) technical infrastructure for data acquisition, storage and access in the presence of regulatory constraints, (2) data annotation and sharing and (3) data analytics. Drawing from this extensive review, we present current challenges for technology development and (4) describe a roadmap for faster clinical translation and exploitation of the full potential of surgical data science.
Rethinking Anticipation Tasks: Uncertainty-aware Anticipation of Sparse Surgical Instrument Usage for Context-aware Assistance
Jul 16, 2020
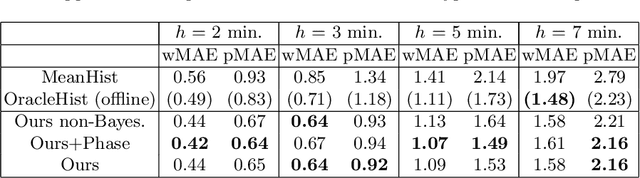
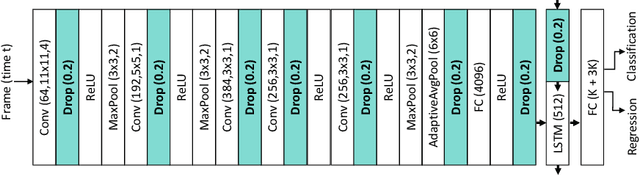
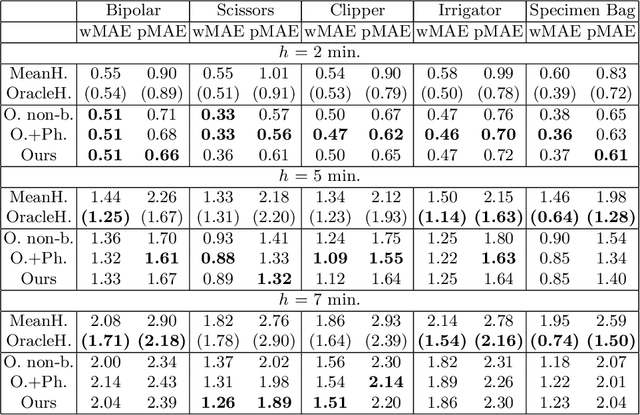
Intra-operative anticipation of instrument usage is a necessary component for context-aware assistance in surgery, e.g. for instrument preparation or semi-automation of robotic tasks. However, the sparsity of instrument occurrences in long videos poses a challenge. Current approaches are limited as they assume knowledge on the timing of future actions or require dense temporal segmentations during training and inference. We propose a novel learning task for anticipation of instrument usage in laparoscopic videos that overcomes these limitations. During training, only sparse instrument annotations are required and inference is done solely on image data. We train a probabilistic model to address the uncertainty associated with future events. Our approach outperforms several baselines and is competitive to a variant using richer annotations. We demonstrate the model's ability to quantify task-relevant uncertainties. To the best of our knowledge, we are the first to propose a method for anticipating instruments in surgery.
Non-Rigid Volume to Surface Registration using a Data-Driven Biomechanical Model
May 29, 2020

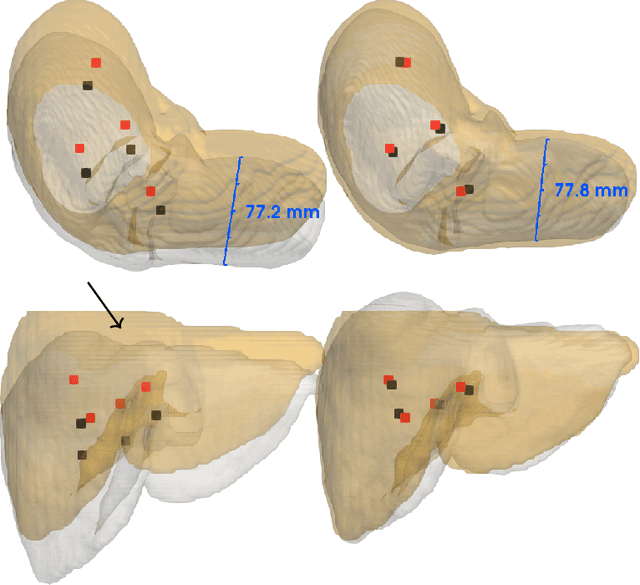
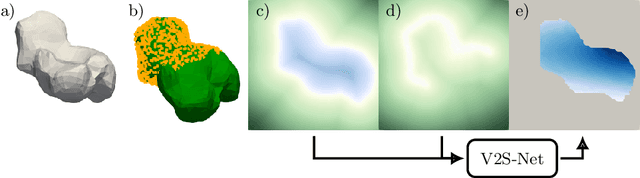
Non-rigid registration is a key component in soft-tissue navigation. We focus on laparoscopic liver surgery, where we register the organ model obtained from a preoperative CT scan to the intraoperative partial organ surface, reconstructed from the laparoscopic video. This is a challenging task due to sparse and noisy intraoperative data, real-time requirements and many unknowns - such as tissue properties and boundary conditions. Furthermore, establishing correspondences between pre- and intraoperative data can be extremely difficult since the liver usually lacks distinct surface features and the used imaging modalities suffer from very different types of noise. In this work, we train a convolutional neural network to perform both the search for surface correspondences as well as the non-rigid registration in one step. The network is trained on physically accurate biomechanical simulations of randomly generated, deforming organ-like structures. This enables the network to immediately generalize to a new patient organ without the need to re-train. We add various amounts of noise to the intraoperative surfaces during training, making the network robust to noisy intraoperative data. During inference, the network outputs the displacement field which matches the preoperative volume to the partial intraoperative surface. In multiple experiments, we show that the network translates well to real data while maintaining a high inference speed. Our code is made available online.
Heidelberg Colorectal Data Set for Surgical Data Science in the Sensor Operating Room
May 28, 2020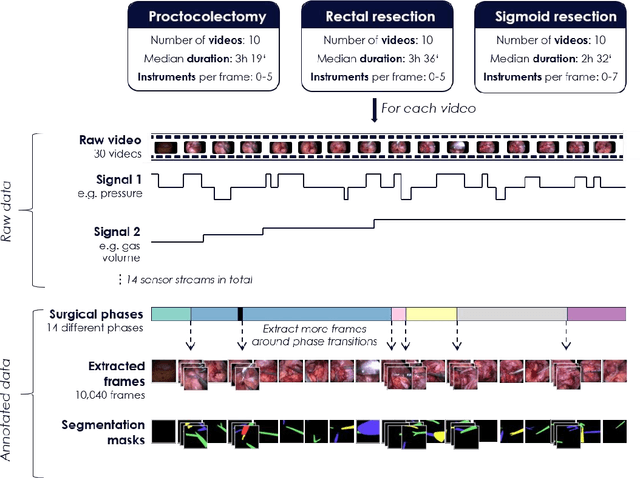
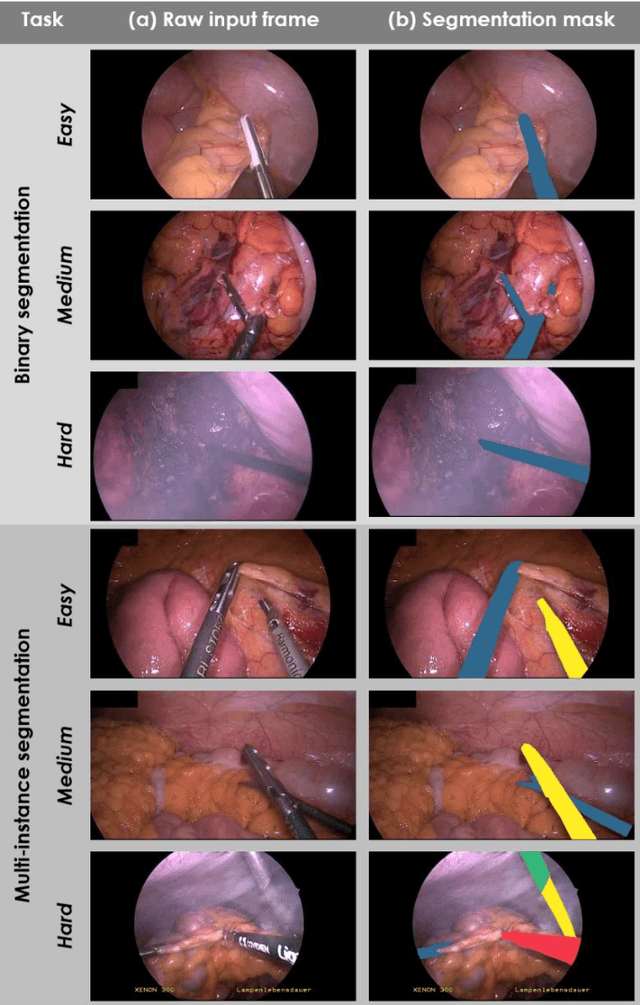
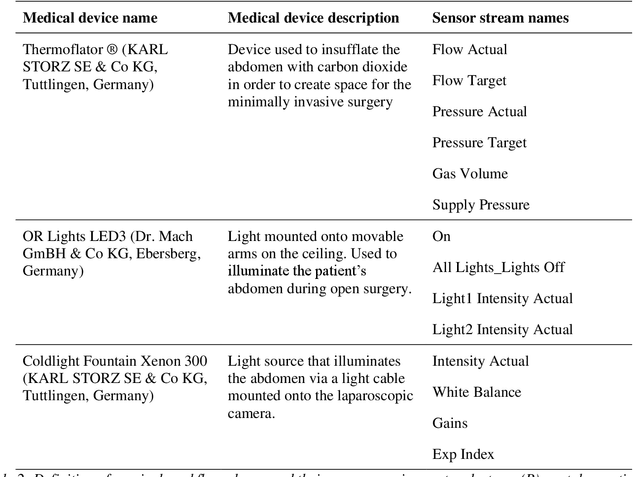
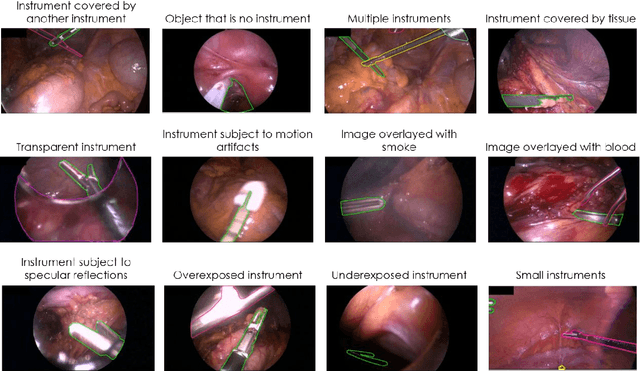
Image-based tracking of medical instruments is an integral part of many surgical data science applications. Previous research has addressed the tasks of detecting, segmenting and tracking medical instruments based on laparoscopic video data. However, the methods proposed still tend to fail when applied to challenging images and do not generalize well to data they have not been trained on. This paper introduces the Heidelberg Colorectal (HeiCo) data set - the first publicly available data set enabling comprehensive benchmarking of medical instrument detection and segmentation algorithms with a specific emphasis on robustness and generalization capabilities of the methods. Our data set comprises 30 laparoscopic videos and corresponding sensor data from medical devices in the operating room for three different types of laparoscopic surgery. Annotations include surgical phase labels for all frames in the videos as well as instance-wise segmentation masks for surgical instruments in more than 10,000 individual frames. The data has successfully been used to organize international competitions in the scope of the Endoscopic Vision Challenges (EndoVis) 2017 and 2019.
Robust Medical Instrument Segmentation Challenge 2019
Mar 23, 2020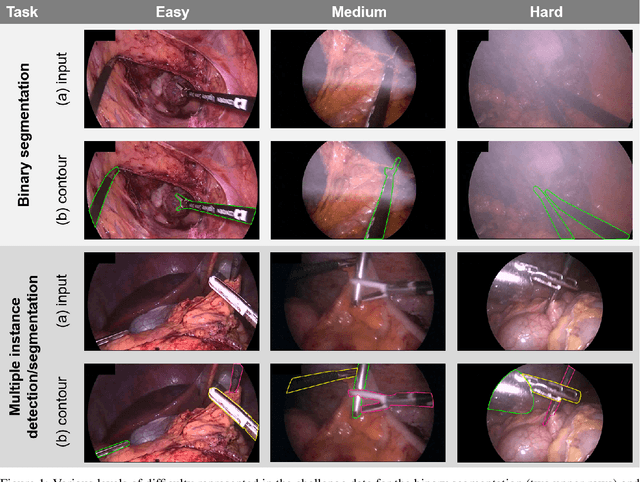
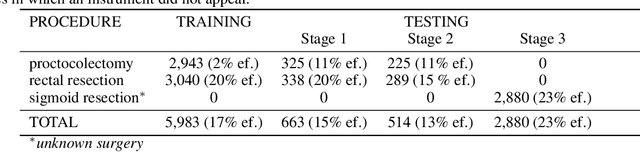
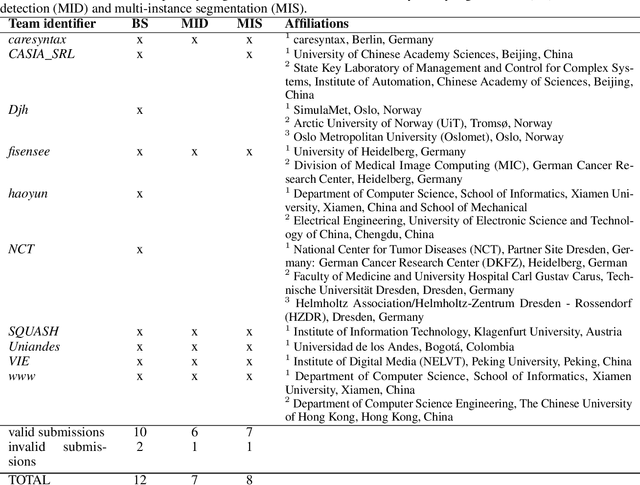
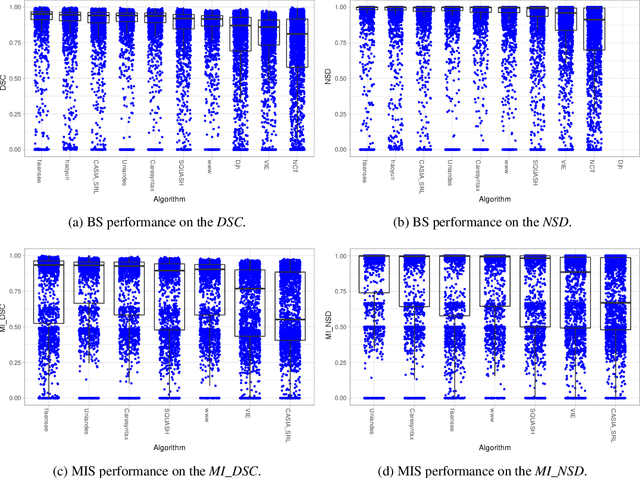
Intraoperative tracking of laparoscopic instruments is often a prerequisite for computer and robotic-assisted interventions. While numerous methods for detecting, segmenting and tracking of medical instruments based on endoscopic video images have been proposed in the literature, key limitations remain to be addressed: Firstly, robustness, that is, the reliable performance of state-of-the-art methods when run on challenging images (e.g. in the presence of blood, smoke or motion artifacts). Secondly, generalization; algorithms trained for a specific intervention in a specific hospital should generalize to other interventions or institutions. In an effort to promote solutions for these limitations, we organized the Robust Medical Instrument Segmentation (ROBUST-MIS) challenge as an international benchmarking competition with a specific focus on the robustness and generalization capabilities of algorithms. For the first time in the field of endoscopic image processing, our challenge included a task on binary segmentation and also addressed multi-instance detection and segmentation. The challenge was based on a surgical data set comprising 10,040 annotated images acquired from a total of 30 surgical procedures from three different types of surgery. The validation of the competing methods for the three tasks (binary segmentation, multi-instance detection and multi-instance segmentation) was performed in three different stages with an increasing domain gap between the training and the test data. The results confirm the initial hypothesis, namely that algorithm performance degrades with an increasing domain gap. While the average detection and segmentation quality of the best-performing algorithms is high, future research should concentrate on detection and segmentation of small, crossing, moving and transparent instrument(s) (parts).
Unsupervised Temporal Video Segmentation as an Auxiliary Task for Predicting the Remaining Surgery Duration
Feb 26, 2020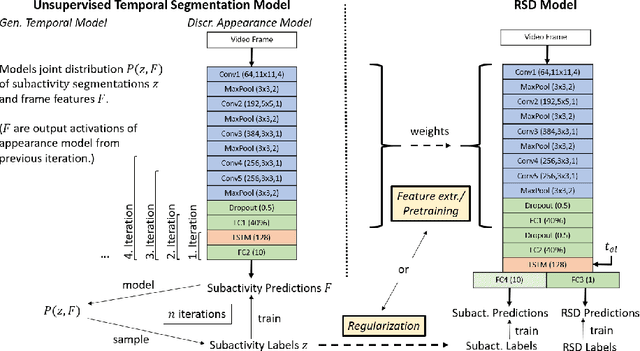
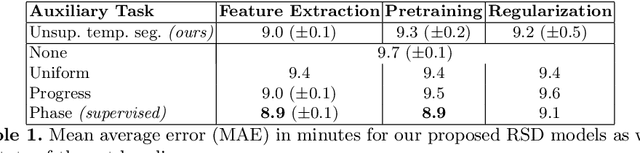

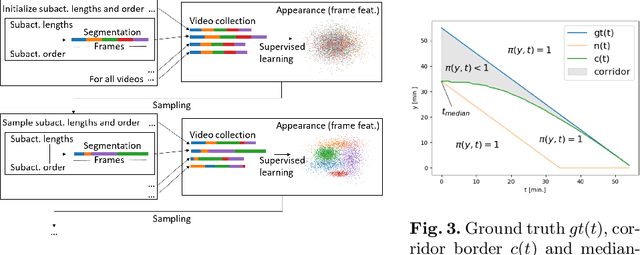
Estimating the remaining surgery duration (RSD) during surgical procedures can be useful for OR planning and anesthesia dose estimation. With the recent success of deep learning-based methods in computer vision, several neural network approaches have been proposed for fully automatic RSD prediction based solely on visual data from the endoscopic camera. We investigate whether RSD prediction can be improved using unsupervised temporal video segmentation as an auxiliary learning task. As opposed to previous work, which presented supervised surgical phase recognition as auxiliary task, we avoid the need for manual annotations by proposing a similar but unsupervised learning objective which clusters video sequences into temporally coherent segments. In multiple experimental setups, results obtained by learning the auxiliary task are incorporated into a deep RSD model through feature extraction, pretraining or regularization. Further, we propose a novel loss function for RSD training which attempts to counteract unfavorable characteristics of the RSD ground truth. Using our unsupervised method as an auxiliary task for RSD training, we outperform other self-supervised methods and are comparable to the supervised state-of-the-art. Combined with the novel RSD loss, we slightly outperform the supervised approach.
2018 Robotic Scene Segmentation Challenge
Feb 03, 2020
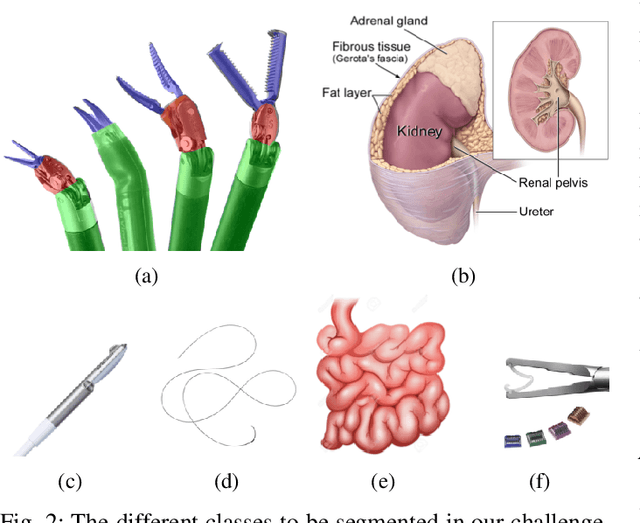
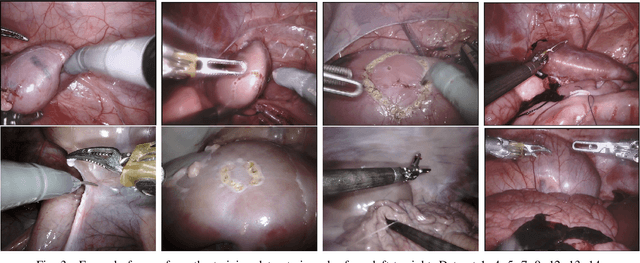
In 2015 we began a sub-challenge at the EndoVis workshop at MICCAI in Munich using endoscope images of ex-vivo tissue with automatically generated annotations from robot forward kinematics and instrument CAD models. However, the limited background variation and simple motion rendered the dataset uninformative in learning about which techniques would be suitable for segmentation in real surgery. In 2017, at the same workshop in Quebec we introduced the robotic instrument segmentation dataset with 10 teams participating in the challenge to perform binary, articulating parts and type segmentation of da Vinci instruments. This challenge included realistic instrument motion and more complex porcine tissue as background and was widely addressed with modifications on U-Nets and other popular CNN architectures. In 2018 we added to the complexity by introducing a set of anatomical objects and medical devices to the segmented classes. To avoid over-complicating the challenge, we continued with porcine data which is dramatically simpler than human tissue due to the lack of fatty tissue occluding many organs.
Using 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video
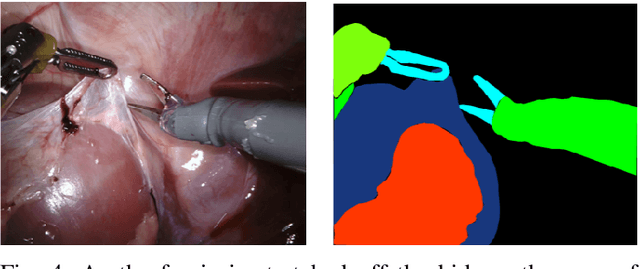
Jul 26, 2019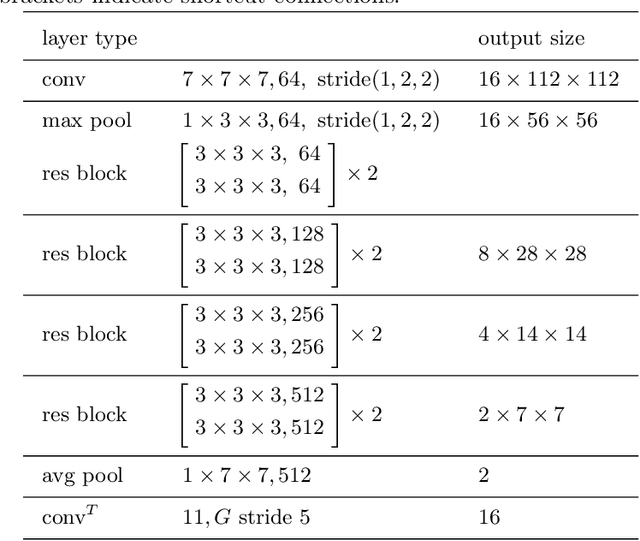


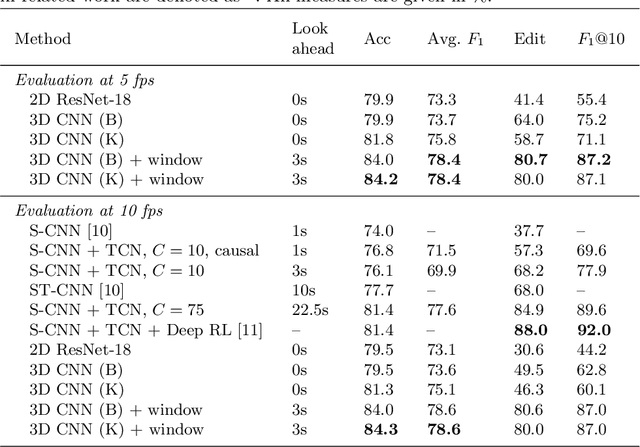
Automatically recognizing surgical gestures is a crucial step towards a thorough understanding of surgical skill. Possible areas of application include automatic skill assessment, intra-operative monitoring of critical surgical steps, and semi-automation of surgical tasks. Solutions that rely only on the laparoscopic video and do not require additional sensor hardware are especially attractive as they can be implemented at low cost in many scenarios. However, surgical gesture recognition based only on video is a challenging problem that requires effective means to extract both visual and temporal information from the video. Previous approaches mainly rely on frame-wise feature extractors, either handcrafted or learned, which fail to capture the dynamics in surgical video. To address this issue, we propose to use a 3D Convolutional Neural Network (CNN) to learn spatiotemporal features from consecutive video frames. We evaluate our approach on recordings of robot-assisted suturing on a bench-top model, which are taken from the publicly available JIGSAWS dataset. Our approach achieves high frame-wise surgical gesture recognition accuracies of more than 84%, outperforming comparable models that either extract only spatial features or model spatial and low-level temporal information separately. For the first time, these results demonstrate the benefit of spatiotemporal CNNs for video-based surgical gesture recognition.