 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Skill Composition and Simulation-to-Real Transfer by Learning Task Representations
Nov 13, 2018

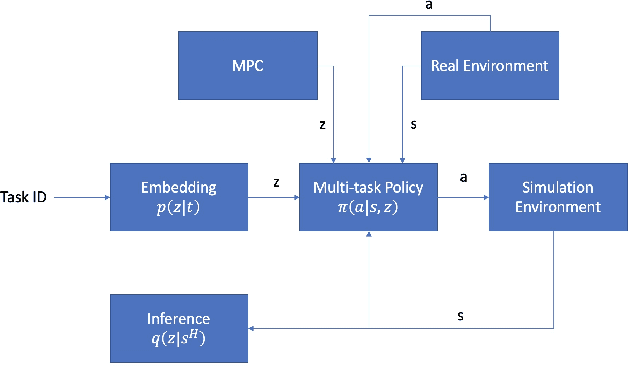
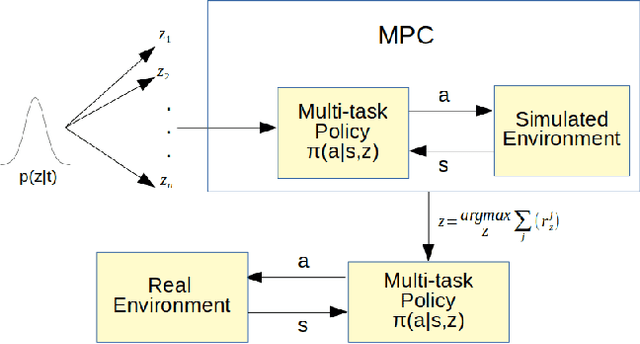
Simulation-to-real transfer is an important strategy for making reinforcement learning practical with real robots. Successful sim-to-real transfer systems have difficulty producing policies which generalize across tasks, despite training for thousands of hours equivalent real robot time. To address this shortcoming, we present a novel approach to efficiently learning new robotic skills directly on a real robot, based on model-predictive control (MPC) and an algorithm for learning task representations. In short, we show how to reuse the simulation from the pre-training step of sim-to-real methods as a tool for foresight, allowing the sim-to-real policy adapt to unseen tasks. Rather than end-to-end learning policies for single tasks and attempting to transfer them, we first use simulation to simultaneously learn (1) a continuous parameterization (i.e. a skill embedding or latent) of task-appropriate primitive skills, and (2) a single policy for these skills which is conditioned on this representation. We then directly transfer our multi-skill policy to a real robot, and actuate the robot by choosing sequences of skill latents which actuate the policy, with each latent corresponding to a pre-learned primitive skill controller. We complete unseen tasks by choosing new sequences of skill latents to control the robot using MPC, where our MPC model is composed of the pre-trained skill policy executed in the simulation environment, run in parallel with the real robot. We discuss the background and principles of our method, detail its practical implementation, and evaluate its performance by using our method to train a real Sawyer Robot to achieve motion tasks such as drawing and block pushing.
Combining learned and analytical models for predicting action effects
Oct 19, 2018

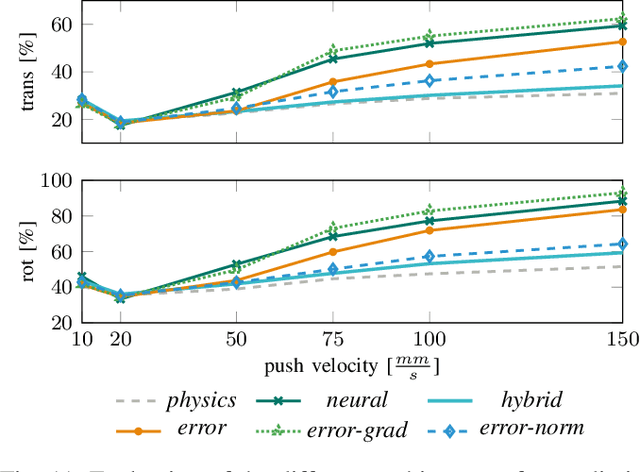
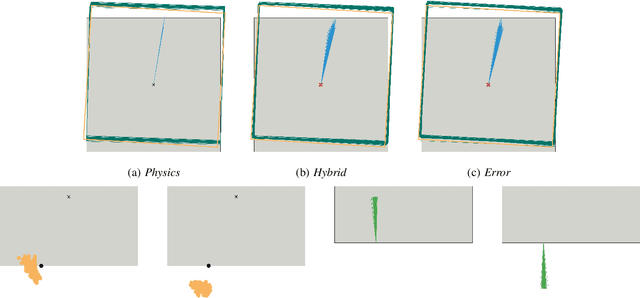
One of the most basic skills a robot should possess is predicting the effect of physical interactions with objects in the environment. This enables optimal action selection to reach a certain goal state. Traditionally, dynamics are approximated by physics-based analytical models. These models rely on specific state representations that may be hard to obtain from raw sensory data, especially if no knowledge of the object shape is assumed. More recently, we have seen learning approaches that can predict the effect of complex physical interactions directly from sensory input. It is however an open question how far these models generalize beyond their training data. In this work, we investigate the advantages and limitations of neural network based learning approaches for predicting the effects of actions based on sensory input and show how analytical and learned models can be combined to leverage the best of both worlds. As physical interaction task, we use planar pushing, for which there exists a well-known analytical model and a large real-world dataset. We propose to use a convolutional neural network to convert raw depth images or organized point clouds into a suitable representation for the analytical model and compare this approach to using neural networks for both, perception and prediction. A systematic evaluation of the proposed approach on a very large real-world dataset shows two main advantages of the hybrid architecture. Compared to a pure neural network, it significantly (i) reduces required training data and (ii) improves generalization to novel physical interaction.
Path Integral Guided Policy Search
Oct 11, 2018
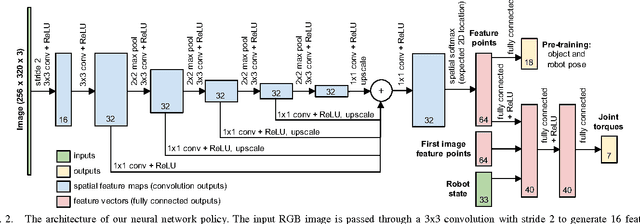

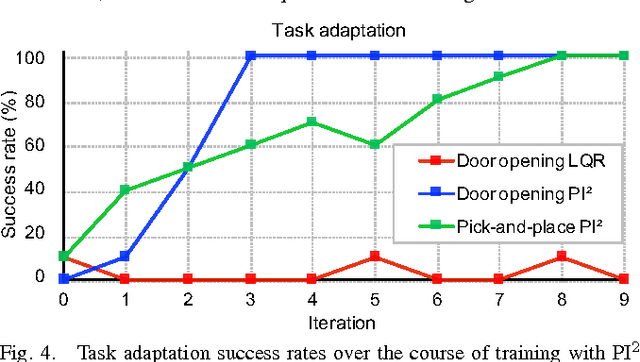
We present a policy search method for learning complex feedback control policies that map from high-dimensional sensory inputs to motor torques, for manipulation tasks with discontinuous contact dynamics. We build on a prior technique called guided policy search (GPS), which iteratively optimizes a set of local policies for specific instances of a task, and uses these to train a complex, high-dimensional global policy that generalizes across task instances. We extend GPS in the following ways: (1) we propose the use of a model-free local optimizer based on path integral stochastic optimal control (PI2), which enables us to learn local policies for tasks with highly discontinuous contact dynamics; and (2) we enable GPS to train on a new set of task instances in every iteration by using on-policy sampling: this increases the diversity of the instances that the policy is trained on, and is crucial for achieving good generalization. We show that these contributions enable us to learn deep neural network policies that can directly perform torque control from visual input. We validate the method on a challenging door opening task and a pick-and-place task, and we demonstrate that our approach substantially outperforms the prior LQR-based local policy optimizer on these tasks. Furthermore, we show that on-policy sampling significantly increases the generalization ability of these policies.
Online Learning of a Memory for Learning Rates
Mar 23, 2018
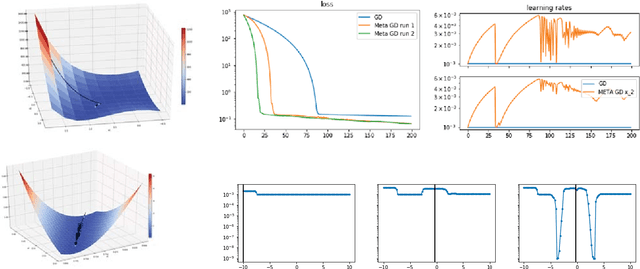

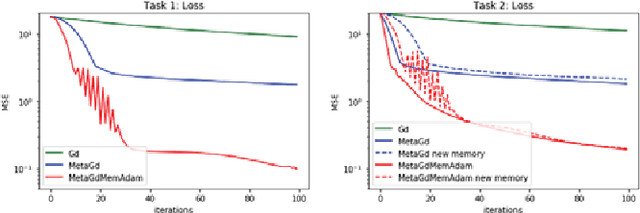
The promise of learning to learn for robotics rests on the hope that by extracting some information about the learning process itself we can speed up subsequent similar learning tasks. Here, we introduce a computationally efficient online meta-learning algorithm that builds and optimizes a memory model of the optimal learning rate landscape from previously observed gradient behaviors. While performing task specific optimization, this memory of learning rates predicts how to scale currently observed gradients. After applying the gradient scaling our meta-learner updates its internal memory based on the observed effect its prediction had. Our meta-learner can be combined with any gradient-based optimizer, learns on the fly and can be transferred to new optimization tasks. In our evaluations we show that our meta-learning algorithm speeds up learning of MNIST classification and a variety of learning control tasks, either in batch or online learning settings.
Time-Contrastive Networks: Self-Supervised Learning from Video
Mar 20, 2018

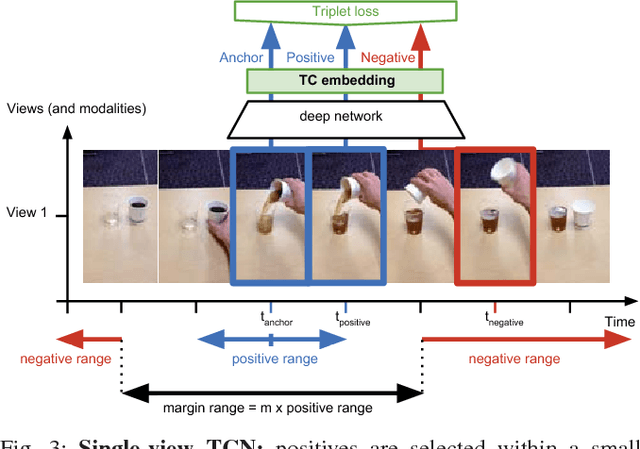
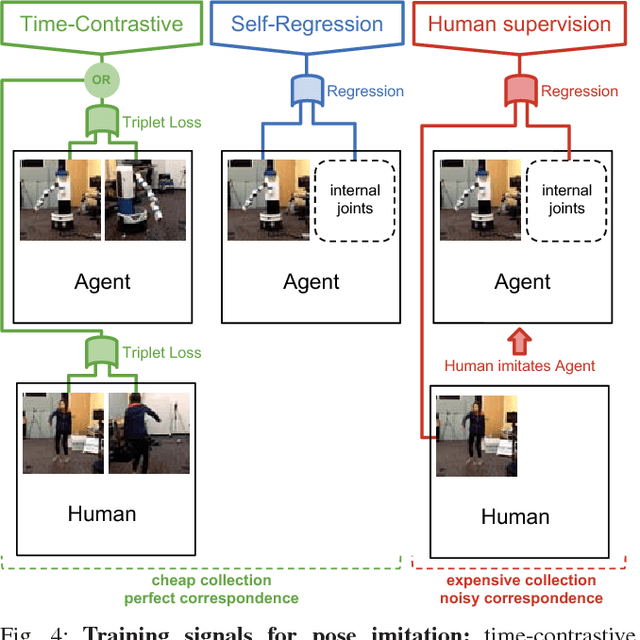
We propose a self-supervised approach for learning representations and robotic behaviors entirely from unlabeled videos recorded from multiple viewpoints, and study how this representation can be used in two robotic imitation settings: imitating object interactions from videos of humans, and imitating human poses. Imitation of human behavior requires a viewpoint-invariant representation that captures the relationships between end-effectors (hands or robot grippers) and the environment, object attributes, and body pose. We train our representations using a metric learning loss, where multiple simultaneous viewpoints of the same observation are attracted in the embedding space, while being repelled from temporal neighbors which are often visually similar but functionally different. In other words, the model simultaneously learns to recognize what is common between different-looking images, and what is different between similar-looking images. This signal causes our model to discover attributes that do not change across viewpoint, but do change across time, while ignoring nuisance variables such as occlusions, motion blur, lighting and background. We demonstrate that this representation can be used by a robot to directly mimic human poses without an explicit correspondence, and that it can be used as a reward function within a reinforcement learning algorithm. While representations are learned from an unlabeled collection of task-related videos, robot behaviors such as pouring are learned by watching a single 3rd-person demonstration by a human. Reward functions obtained by following the human demonstrations under the learned representation enable efficient reinforcement learning that is practical for real-world robotic systems. Video results, open-source code and dataset are available at https://sermanet.github.io/imitate
Learning Sensor Feedback Models from Demonstrations via Phase-Modulated Neural Networks
Mar 15, 2018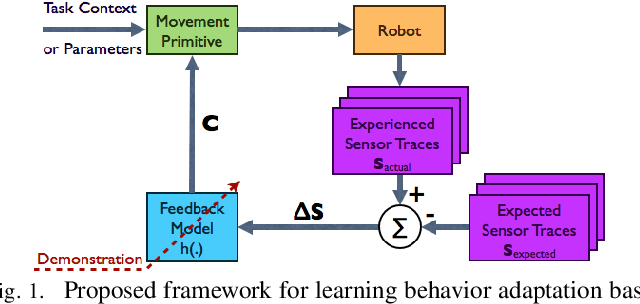
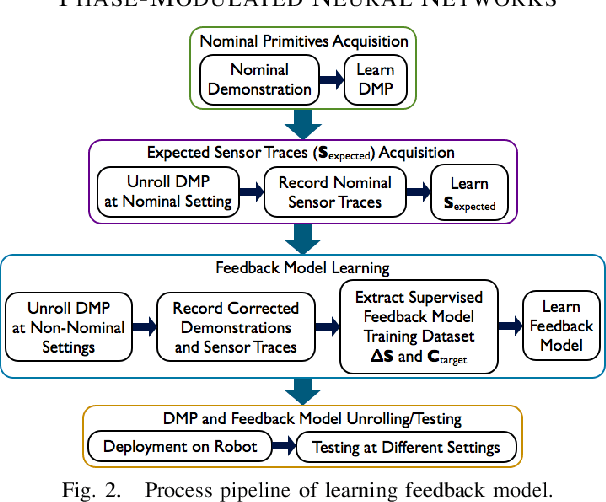
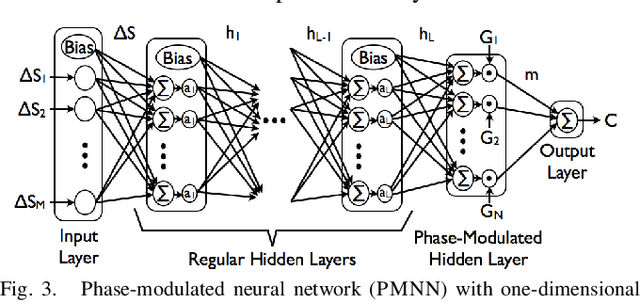
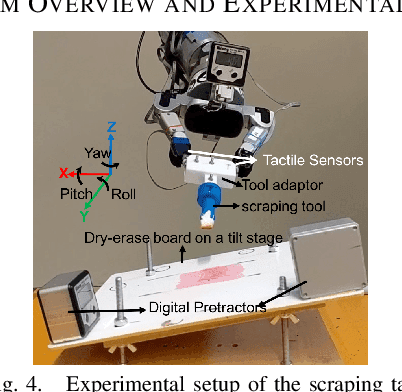
In order to robustly execute a task under environmental uncertainty, a robot needs to be able to reactively adapt to changes arising in its environment. The environment changes are usually reflected in deviation from expected sensory traces. These deviations in sensory traces can be used to drive the motion adaptation, and for this purpose, a feedback model is required. The feedback model maps the deviations in sensory traces to the motion plan adaptation. In this paper, we develop a general data-driven framework for learning a feedback model from demonstrations. We utilize a variant of a radial basis function network structure --with movement phases as kernel centers-- which can generally be applied to represent any feedback models for movement primitives. To demonstrate the effectiveness of our framework, we test it on the task of scraping on a tilt board. In this task, we are learning a reactive policy in the form of orientation adaptation, based on deviations of tactile sensor traces. As a proof of concept of our method, we provide evaluations on an anthropomorphic robot. A video demonstrating our approach and its results can be seen in https://youtu.be/7Dx5imy1Kcw
Learning Task-Specific Dynamics to Improve Whole-Body Control
Mar 08, 2018
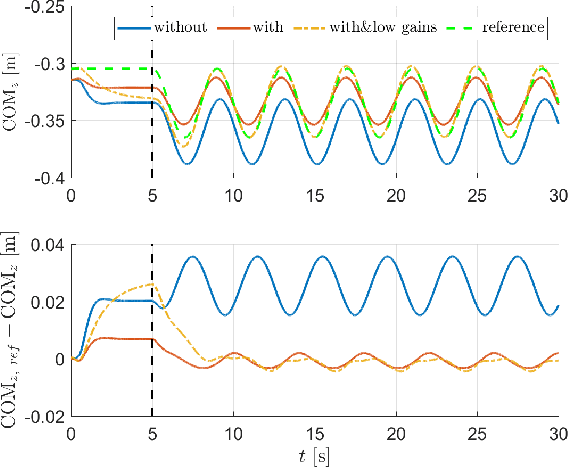
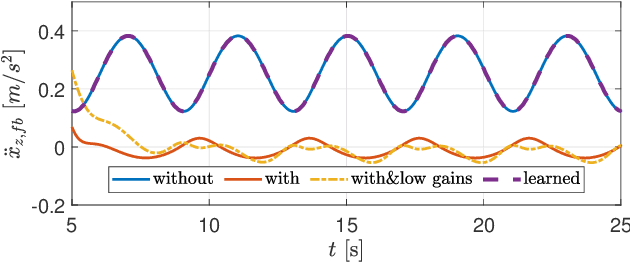
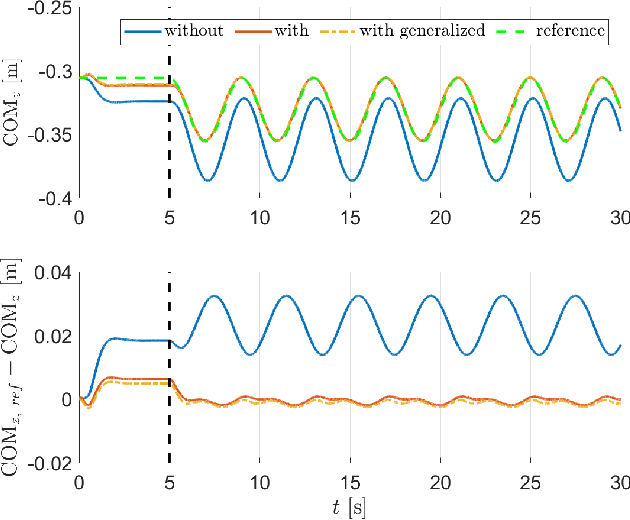
In task-based inverse dynamics control, reference accelerations used to follow a desired plan can be broken down into feedforward and feedback trajectories. The feedback term accounts for tracking errors that are caused from inaccurate dynamic models or external disturbances. On underactuated, free-floating robots, such as humanoids, high feedback terms can be used to improve tracking accuracy; however, this can lead to very stiff behavior or poor tracking accuracy due to limited control bandwidth. In this paper, we show how to reduce the required contribution of the feedback controller by incorporating learned task-space reference accelerations. Thus, we i) improve the execution of the given specific task, and ii) offer the means to reduce feedback gains, providing for greater compliance of the system. With a systematic approach we also reduce heuristic tuning of the model parameters and feedback gains, often present in real-world experiments. In contrast to learning task-specific joint-torques, which might produce a similar effect but can lead to poor generalization, our approach directly learns the task-space dynamics of the center of mass of a humanoid robot. Simulated and real-world results on the lower part of the Sarcos Hermes humanoid robot demonstrate the applicability of the approach.
An MPC Walking Framework With External Contact Forces
Feb 27, 2018
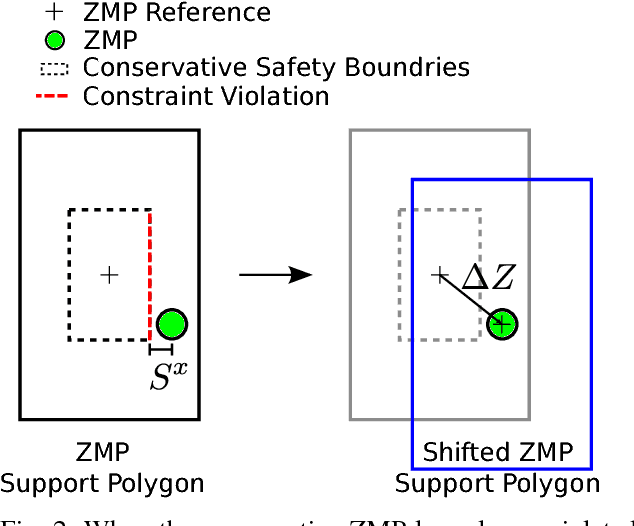
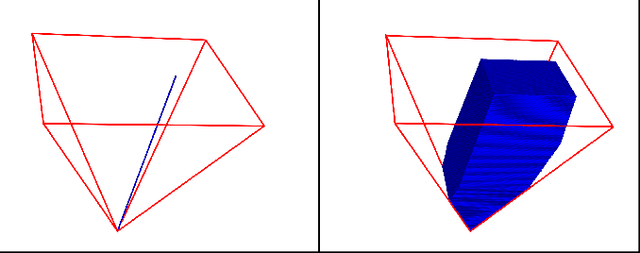
In this work, we present an extension to a linear Model Predictive Control (MPC) scheme that plans external contact forces for the robot when given multiple contact locations and their corresponding friction cone. To this end, we set up a two-step optimization problem. In the first optimization, we compute the Center of Mass (CoM) trajectory, foot step locations, and introduce slack variables to account for violating the imposed constraints on the Zero Moment Point (ZMP). We then use the slack variables to trigger the second optimization, in which we calculate the optimal external force that compensates for the ZMP tracking error. This optimization considers multiple contacts positions within the environment by formulating the problem as a Mixed Integer Quadratic Program (MIQP) that can be solved at a speed between 100-300 Hz. Once contact is created, the MIQP reduces to a single Quadratic Program (QP) that can be solved in real-time ($<$ 1kHz). Simulations show that the presented walking control scheme can withstand disturbances 2-3x larger with the additional force provided by a hand contact.
On Time Optimization of Centroidal Momentum Dynamics
Feb 26, 2018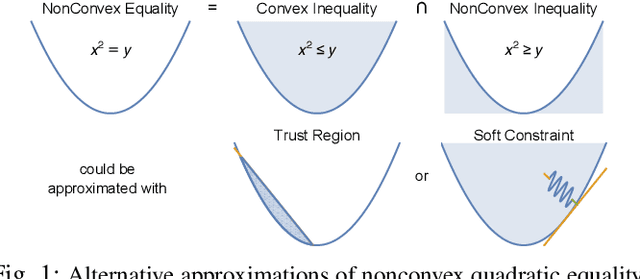
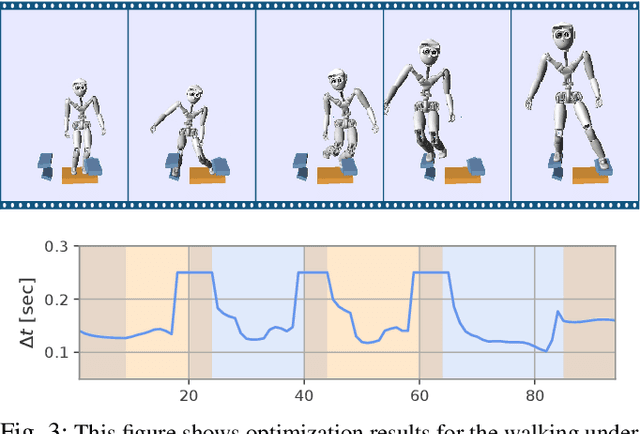
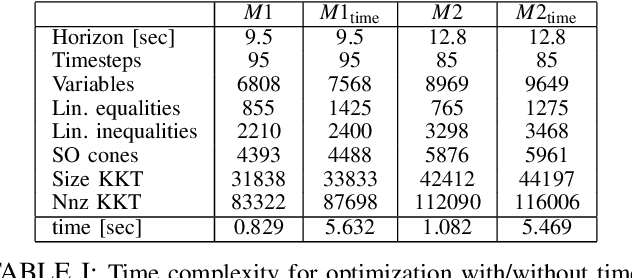
Recently, the centroidal momentum dynamics has received substantial attention to plan dynamically consistent motions for robots with arms and legs in multi-contact scenarios. However, it is also non convex which renders any optimization approach difficult and timing is usually kept fixed in most trajectory optimization techniques to not introduce additional non convexities to the problem. But this can limit the versatility of the algorithms. In our previous work, we proposed a convex relaxation of the problem that allowed to efficiently compute momentum trajectories and contact forces. However, our approach could not minimize a desired angular momentum objective which seriously limited its applicability. Noticing that the non-convexity introduced by the time variables is of similar nature as the centroidal dynamics one, we propose two convex relaxations to the problem based on trust regions and soft constraints. The resulting approaches can compute time-optimized dynamically consistent trajectories sufficiently fast to make the approach realtime capable. The performance of the algorithm is demonstrated in several multi-contact scenarios for a humanoid robot. In particular, we show that the proposed convex relaxation of the original problem finds solutions that are consistent with the original non-convex problem and illustrate how timing optimization allows to find motion plans that would be difficult to plan with fixed timing.
Probabilistic Recurrent State-Space Models
Feb 10, 2018
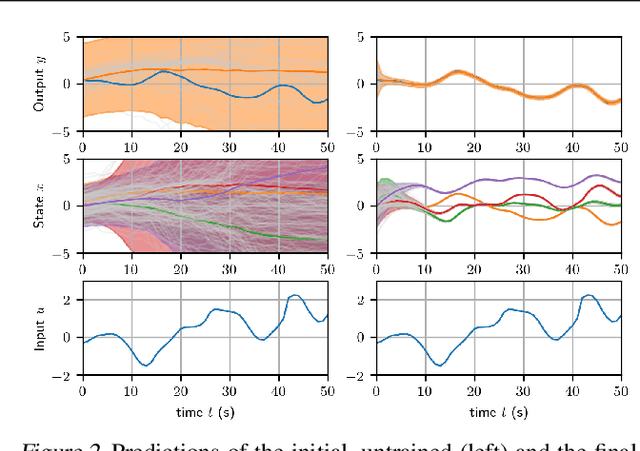

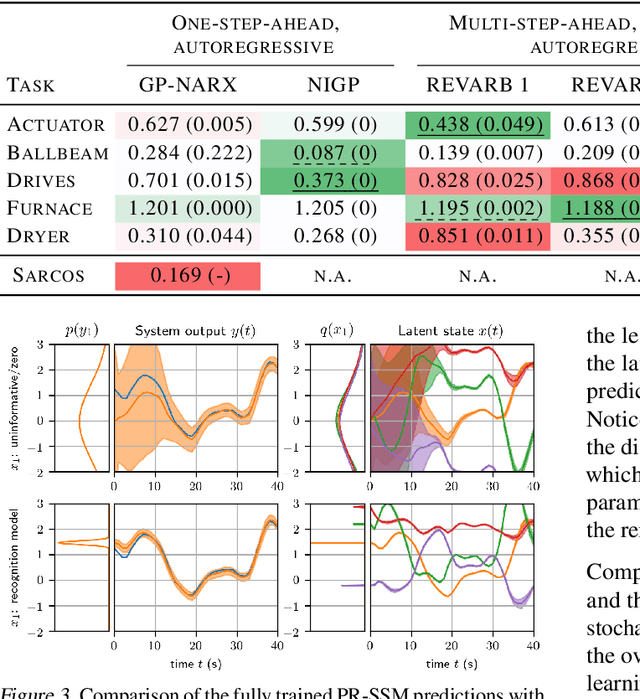
State-space models (SSMs) are a highly expressive model class for learning patterns in time series data and for system identification. Deterministic versions of SSMs (e.g. LSTMs) proved extremely successful in modeling complex time series data. Fully probabilistic SSMs, however, are often found hard to train, even for smaller problems. To overcome this limitation, we propose a novel model formulation and a scalable training algorithm based on doubly stochastic variational inference and Gaussian processes. In contrast to existing work, the proposed variational approximation allows one to fully capture the latent state temporal correlations. These correlations are the key to robust training. The effectiveness of the proposed PR-SSM is evaluated on a set of real-world benchmark datasets in comparison to state-of-the-art probabilistic model learning methods. Scalability and robustness are demonstrated on a high dimensional problem.