 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Visible Tissue in Intraoperative Ultrasound Images during Brain Surgery: A Method and Application
Jun 01, 2023



Intraoperative ultrasound scanning is a demanding visuotactile task. It requires operators to simultaneously localise the ultrasound perspective and manually perform slight adjustments to the pose of the probe, making sure not to apply excessive force or breaking contact with the tissue, whilst also characterising the visible tissue. In this paper, we propose a method for the identification of the visible tissue, which enables the analysis of ultrasound probe and tissue contact via the detection of acoustic shadow and construction of confidence maps of the perceptual salience. Detailed validation with both in vivo and phantom data is performed. First, we show that our technique is capable of achieving state of the art acoustic shadow scan line classification - with an average binary classification accuracy on unseen data of 0.87. Second, we show that our framework for constructing confidence maps is able to produce an ideal response to a probe's pose that is being oriented in and out of optimality - achieving an average RMSE across five scans of 0.174. The performance evaluation justifies the potential clinical value of the method which can be used both to assist clinical training and optimise robot-assisted ultrasound tissue scanning.
Automated robotic intraoperative ultrasound for brain surgery
Apr 03, 2023


During brain tumour resection, localising cancerous tissue and delineating healthy and pathological borders is challenging, even for experienced neurosurgeons and neuroradiologists. Intraoperative imaging is commonly employed for determining and updating surgical plans in the operating room. Ultrasound (US) has presented itself a suitable tool for this task, owing to its ease of integration into the operating room and surgical procedure. However, widespread establishment of this tool has been limited because of the difficulty of anatomy localisation and data interpretation. In this work, we present a robotic framework designed and tested on a soft-tissue-mimicking brain phantom, simulating intraoperative US (iUS) scanning during brain tumour surgery.
SurgT challenge: Benchmark of Soft-Tissue Trackers for Robotic Surgery
Feb 28, 2023



This paper introduces the "SurgT: Surgical Tracking" challenge which was organised in conjunction with the 25th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2022). There were two purposes for the creation of this challenge: (1) the establishment of the first standardised benchmark for the research community to assess soft-tissue trackers; and (2) to encourage the development of unsupervised deep learning methods, given the lack of annotated data in surgery. A dataset of 157 stereo endoscopic videos from 20 clinical cases, along with stereo camera calibration parameters, have been provided. The participants were tasked with the development of algorithms to track a bounding box on stereo endoscopic videos. At the end of the challenge, the developed methods were assessed on a previously hidden test subset. This assessment uses benchmarking metrics that were purposely developed for this challenge and are now available online. The teams were ranked according to their Expected Average Overlap (EAO) score, which is a weighted average of the Intersection over Union (IoU) scores. The performance evaluation study verifies the efficacy of unsupervised deep learning algorithms in tracking soft-tissue. The best-performing method achieved an EAO score of 0.583 in the test subset. The dataset and benchmarking tool created for this challenge have been made publicly available. This challenge is expected to contribute to the development of autonomous robotic surgery and other digital surgical technologies.
Regularizing disparity estimation via multi task learning with structured light reconstruction
Jan 19, 20233D reconstruction is a useful tool for surgical planning and guidance. However, the lack of available medical data stunts research and development in this field, as supervised deep learning methods for accurate disparity estimation rely heavily on large datasets containing ground truth information. Alternative approaches to supervision have been explored, such as self-supervision, which can reduce or remove entirely the need for ground truth. However, no proposed alternatives have demonstrated performance capabilities close to what would be expected from a supervised setup. This work aims to alleviate this issue. In this paper, we investigate the learning of structured light projections to enhance the development of direct disparity estimation networks. We show for the first time that it is possible to accurately learn the projection of structured light on a scene, implicitly learning disparity. Secondly, we \textcolor{black}{explore the use of a multi task learning (MTL) framework for the joint training of structured light and disparity. We present results which show that MTL with structured light improves disparity training; without increasing the number of model parameters. Our MTL setup outperformed the single task learning (STL) network in every validation test. Notably, in the medical generalisation test, the STL error was 1.4 times worse than that of the best MTL performance. The benefit of using MTL is emphasised when the training data is limited.} A dataset containing stereoscopic images, disparity maps and structured light projections on medical phantoms and ex vivo tissue was created for evaluation together with virtual scenes. This dataset will be made publicly available in the future.
Collaborative Robotic Ultrasound Tissue Scanning for Surgical Resection Guidance in Neurosurgery
Jan 19, 2023

The aim of this paper is to introduce a robotic platform for autonomous iUS tissue scanning to optimise intraoperative diagnosis and improve surgical resection during robot-assisted operations. To guide anatomy specific robotic scanning and generate a representation of the robot task space, fast and accurate techniques for the recovery of 3D morphological structures of the surgical cavity are developed. The prototypic DLR MIRO surgical robotic arm is used to control the applied force and the in-plane motion of the US transducer. A key application of the proposed platform is the scanning of brain tissue to guide tumour resection.
Caveats on the first-generation da Vinci Research Kit: latent technical constraints and essential calibrations
Oct 24, 2022



Telesurgical robotic systems provide a well established form of assistance in the operating theater, with evidence of growing uptake in recent years. Until now, the da Vinci surgical system (Intuitive Surgical Inc, Sunnyvale, California) has been the most widely adopted robot of this kind, with more than 6,700 systems in current clinical use worldwide. To accelerate research on robotic-assisted surgery, the retired first-generation da Vinci robots have been redeployed for research use as "da Vinci Research Kits" (dVRKs), which have been distributed to research institutions around the world to support both training and research in the sector. In the past ten years, a great amount of research on the dVRK has been carried out across a vast range of research topics. During this extensive and distributed process, common technical issues have been identified that are buried deep within the dVRK research and development architecture, and were found to be common among dVRK user feedback, regardless of the breadth and disparity of research directions identified. This paper gathers and analyzes the most significant of these, with a focus on the technical constraints of the first-generation dVRK, which both existing and prospective users should be aware of before embarking onto dVRK-related research. The hope is that this review will aid users in identifying and addressing common limitations of the systems promptly, thus helping to accelerate progress in the field.
Self-Supervised Depth Estimation in Laparoscopic Image using 3D Geometric Consistency
Aug 17, 2022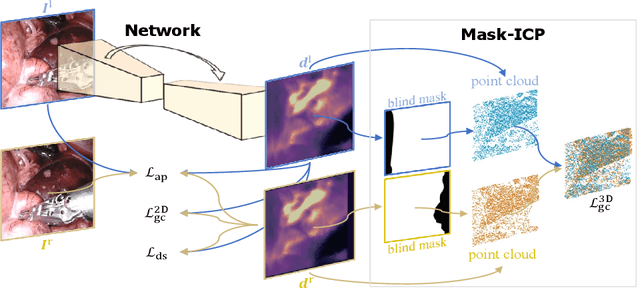
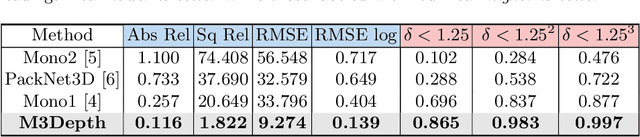
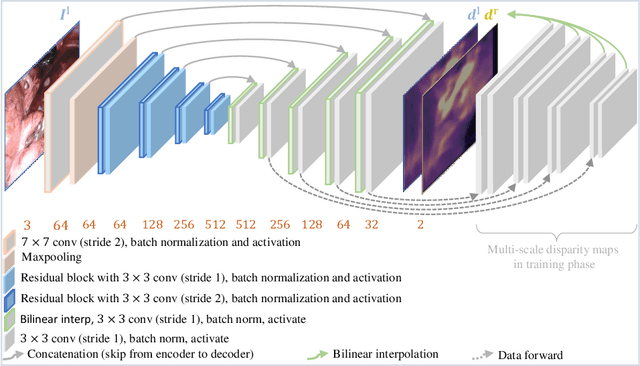

Depth estimation is a crucial step for image-guided intervention in robotic surgery and laparoscopic imaging system. Since per-pixel depth ground truth is difficult to acquire for laparoscopic image data, it is rarely possible to apply supervised depth estimation to surgical applications. As an alternative, self-supervised methods have been introduced to train depth estimators using only synchronized stereo image pairs. However, most recent work focused on the left-right consistency in 2D and ignored valuable inherent 3D information on the object in real world coordinates, meaning that the left-right 3D geometric structural consistency is not fully utilized. To overcome this limitation, we present M3Depth, a self-supervised depth estimator to leverage 3D geometric structural information hidden in stereo pairs while keeping monocular inference. The method also removes the influence of border regions unseen in at least one of the stereo images via masking, to enhance the correspondences between left and right images in overlapping areas. Intensive experiments show that our method outperforms previous self-supervised approaches on both a public dataset and a newly acquired dataset by a large margin, indicating a good generalization across different samples and laparoscopes.
Self-Supervised Generative Adversarial Network for Depth Estimation in Laparoscopic Images
Jul 09, 2021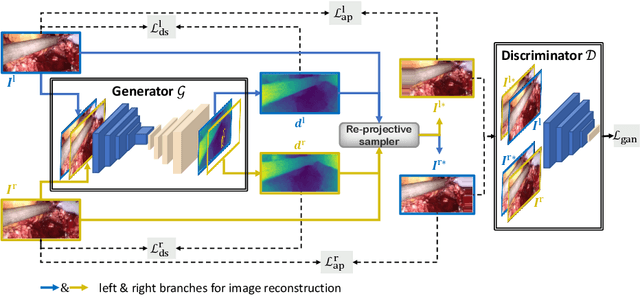
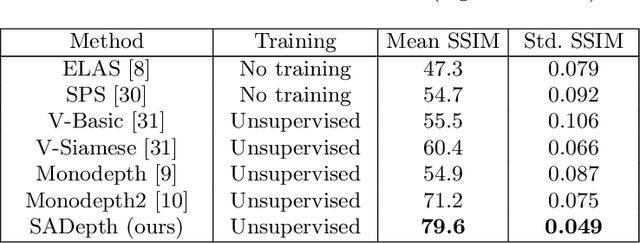
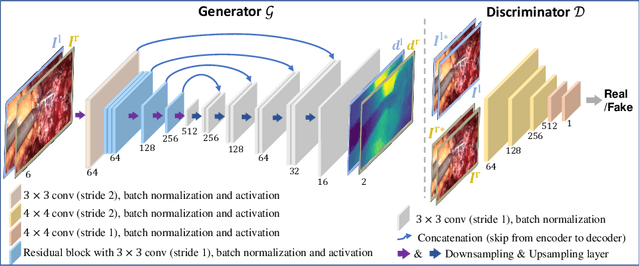
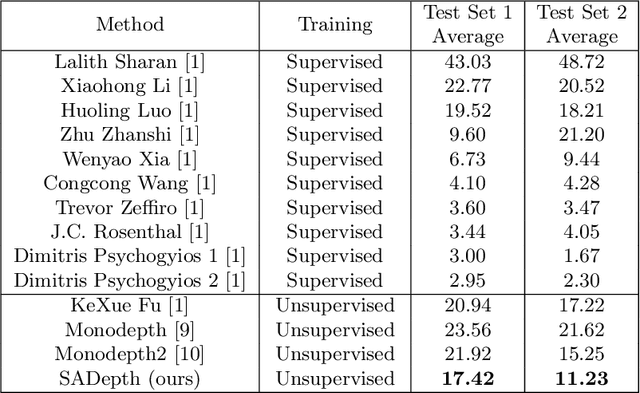
Dense depth estimation and 3D reconstruction of a surgical scene are crucial steps in computer assisted surgery. Recent work has shown that depth estimation from a stereo images pair could be solved with convolutional neural networks. However, most recent depth estimation models were trained on datasets with per-pixel ground truth. Such data is especially rare for laparoscopic imaging, making it hard to apply supervised depth estimation to real surgical applications. To overcome this limitation, we propose SADepth, a new self-supervised depth estimation method based on Generative Adversarial Networks. It consists of an encoder-decoder generator and a discriminator to incorporate geometry constraints during training. Multi-scale outputs from the generator help to solve the local minima caused by the photometric reprojection loss, while the adversarial learning improves the framework generation quality. Extensive experiments on two public datasets show that SADepth outperforms recent state-of-the-art unsupervised methods by a large margin, and reduces the gap between supervised and unsupervised depth estimation in laparoscopic images.
H-Net: Unsupervised Attention-based Stereo Depth Estimation Leveraging Epipolar Geometry
Apr 22, 2021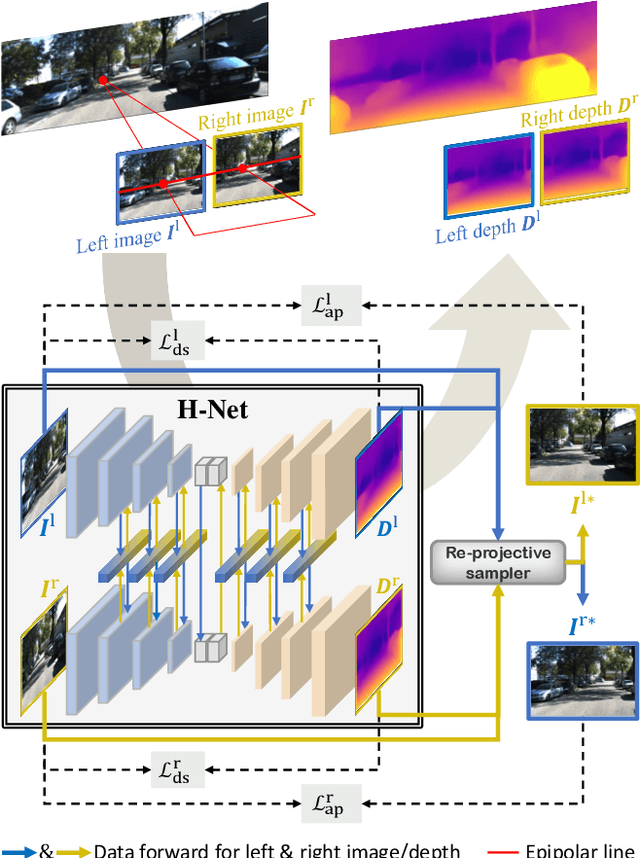
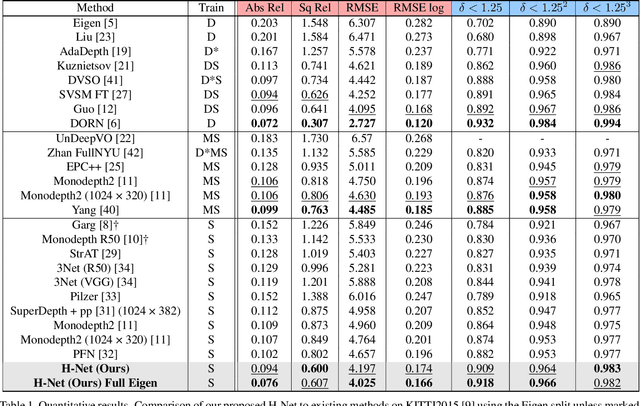
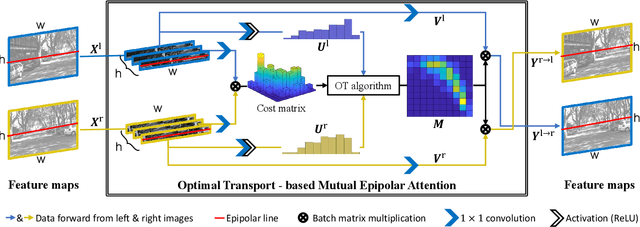
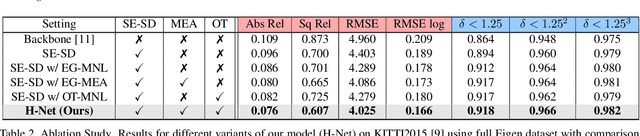
Depth estimation from a stereo image pair has become one of the most explored applications in computer vision, with most of the previous methods relying on fully supervised learning settings. However, due to the difficulty in acquiring accurate and scalable ground truth data, the training of fully supervised methods is challenging. As an alternative, self-supervised methods are becoming more popular to mitigate this challenge. In this paper, we introduce the H-Net, a deep-learning framework for unsupervised stereo depth estimation that leverages epipolar geometry to refine stereo matching. For the first time, a Siamese autoencoder architecture is used for depth estimation which allows mutual information between the rectified stereo images to be extracted. To enforce the epipolar constraint, the mutual epipolar attention mechanism has been designed which gives more emphasis to correspondences of features which lie on the same epipolar line while learning mutual information between the input stereo pair. Stereo correspondences are further enhanced by incorporating semantic information to the proposed attention mechanism. More specifically, the optimal transport algorithm is used to suppress attention and eliminate outliers in areas not visible in both cameras. Extensive experiments on KITTI2015 and Cityscapes show that our method outperforms the state-ofthe-art unsupervised stereo depth estimation methods while closing the gap with the fully supervised approaches.
Surgical Data Science -- from Concepts to Clinical Translation
Oct 30, 2020
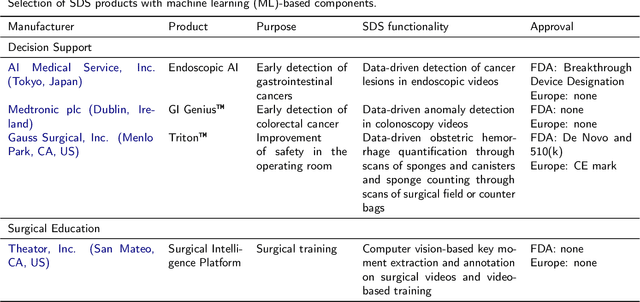
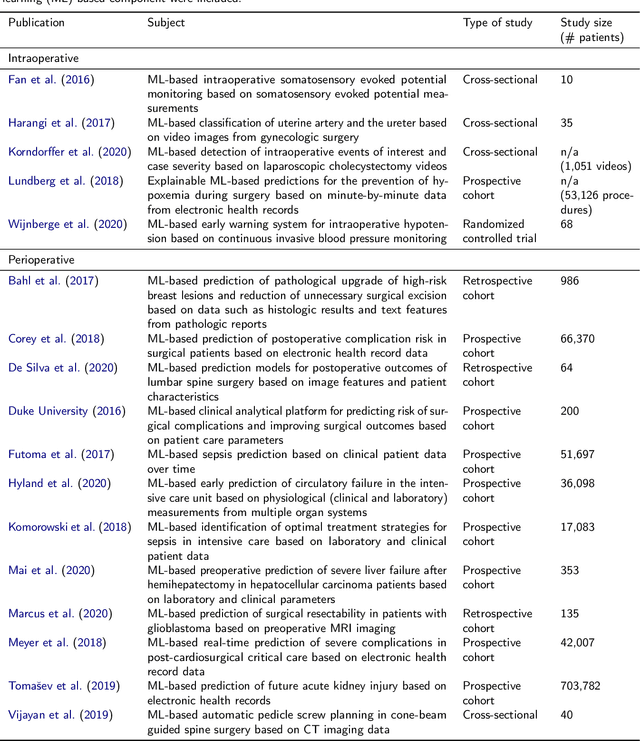
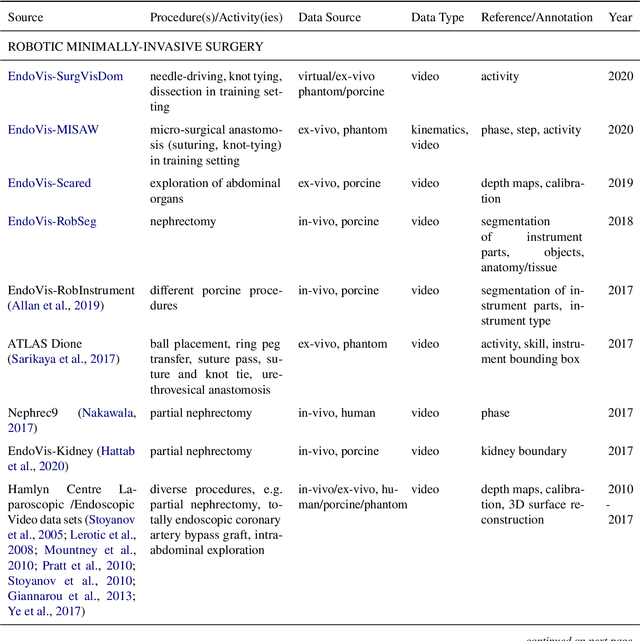
Recent developments in data science in general and machine learning in particular have transformed the way experts envision the future of surgery. Surgical data science is a new research field that aims to improve the quality of interventional healthcare through the capture, organization, analysis and modeling of data. While an increasing number of data-driven approaches and clinical applications have been studied in the fields of radiological and clinical data science, translational success stories are still lacking in surgery. In this publication, we shed light on the underlying reasons and provide a roadmap for future advances in the field. Based on an international workshop involving leading researchers in the field of surgical data science, we review current practice, key achievements and initiatives as well as available standards and tools for a number of topics relevant to the field, namely (1) technical infrastructure for data acquisition, storage and access in the presence of regulatory constraints, (2) data annotation and sharing and (3) data analytics. Drawing from this extensive review, we present current challenges for technology development and (4) describe a roadmap for faster clinical translation and exploitation of the full potential of surgical data science.