 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical-DeSAM: Decoupling SAM for Instrument Segmentation in Robotic Surgery
Apr 22, 2024Purpose: The recent Segment Anything Model (SAM) has demonstrated impressive performance with point, text or bounding box prompts, in various applications. However, in safety-critical surgical tasks, prompting is not possible due to (i) the lack of per-frame prompts for supervised learning, (ii) it is unrealistic to prompt frame-by-frame in a real-time tracking application, and (iii) it is expensive to annotate prompts for offline applications. Methods: We develop Surgical-DeSAM to generate automatic bounding box prompts for decoupling SAM to obtain instrument segmentation in real-time robotic surgery. We utilise a commonly used detection architecture, DETR, and fine-tuned it to obtain bounding box prompt for the instruments. We then empolyed decoupling SAM (DeSAM) by replacing the image encoder with DETR encoder and fine-tune prompt encoder and mask decoder to obtain instance segmentation for the surgical instruments. To improve detection performance, we adopted the Swin-transformer to better feature representation. Results: The proposed method has been validated on two publicly available datasets from the MICCAI surgical instruments segmentation challenge EndoVis 2017 and 2018. The performance of our method is also compared with SOTA instrument segmentation methods and demonstrated significant improvements with dice metrics of 89.62 and 90.70 for the EndoVis 2017 and 2018. Conclusion: Our extensive experiments and validations demonstrate that Surgical-DeSAM enables real-time instrument segmentation without any additional prompting and outperforms other SOTA segmentation methods.
Gaussian Pancakes: Geometrically-Regularized 3D Gaussian Splatting for Realistic Endoscopic Reconstruction
Apr 09, 2024



Within colorectal cancer diagnostics, conventional colonoscopy techniques face critical limitations, including a limited field of view and a lack of depth information, which can impede the detection of precancerous lesions. Current methods struggle to provide comprehensive and accurate 3D reconstructions of the colonic surface which can help minimize the missing regions and reinspection for pre-cancerous polyps. Addressing this, we introduce 'Gaussian Pancakes', a method that leverages 3D Gaussian Splatting (3D GS) combined with a Recurrent Neural Network-based Simultaneous Localization and Mapping (RNNSLAM) system. By introducing geometric and depth regularization into the 3D GS framework, our approach ensures more accurate alignment of Gaussians with the colon surface, resulting in smoother 3D reconstructions with novel viewing of detailed textures and structures. Evaluations across three diverse datasets show that Gaussian Pancakes enhances novel view synthesis quality, surpassing current leading methods with a 18% boost in PSNR and a 16% improvement in SSIM. It also delivers over 100X faster rendering and more than 10X shorter training times, making it a practical tool for real-time applications. Hence, this holds promise for achieving clinical translation for better detection and diagnosis of colorectal cancer.
Investigation of Federated Learning Algorithms for Retinal Optical Coherence Tomography Image Classification with Statistical Heterogeneity
Feb 15, 2024Purpose: We apply federated learning to train an OCT image classifier simulating a realistic scenario with multiple clients and statistical heterogeneous data distribution where data in the clients lack samples of some categories entirely. Methods: We investigate the effectiveness of FedAvg and FedProx to train an OCT image classification model in a decentralized fashion, addressing privacy concerns associated with centralizing data. We partitioned a publicly available OCT dataset across multiple clients under IID and Non-IID settings and conducted local training on the subsets for each client. We evaluated two federated learning methods, FedAvg and FedProx for these settings. Results: Our experiments on the dataset suggest that under IID settings, both methods perform on par with training on a central data pool. However, the performance of both algorithms declines as we increase the statistical heterogeneity across the client data, while FedProx consistently performs better than FedAvg in the increased heterogeneity settings. Conclusion: Despite the effectiveness of federated learning in the utilization of private data across multiple medical institutions, the large number of clients and heterogeneous distribution of labels deteriorate the performance of both algorithms. Notably, FedProx appears to be more robust to the increased heterogeneity.
SimCol3D -- 3D Reconstruction during Colonoscopy Challenge
Jul 20, 2023Colorectal cancer is one of the most common cancers in the world. While colonoscopy is an effective screening technique, navigating an endoscope through the colon to detect polyps is challenging. A 3D map of the observed surfaces could enhance the identification of unscreened colon tissue and serve as a training platform. However, reconstructing the colon from video footage remains unsolved due to numerous factors such as self-occlusion, reflective surfaces, lack of texture, and tissue deformation that limit feature-based methods. Learning-based approaches hold promise as robust alternatives, but necessitate extensive datasets. By establishing a benchmark, the 2022 EndoVis sub-challenge SimCol3D aimed to facilitate data-driven depth and pose prediction during colonoscopy. The challenge was hosted as part of MICCAI 2022 in Singapore. Six teams from around the world and representatives from academia and industry participated in the three sub-challenges: synthetic depth prediction, synthetic pose prediction, and real pose prediction. This paper describes the challenge, the submitted methods, and their results. We show that depth prediction in virtual colonoscopy is robustly solvable, while pose estimation remains an open research question.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Retrieval of surgical phase transitions using reinforcement learning
Aug 01, 2022
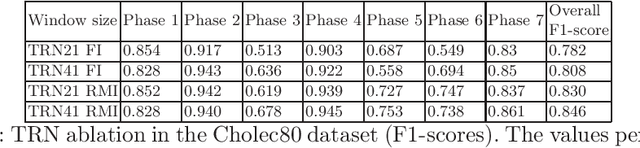
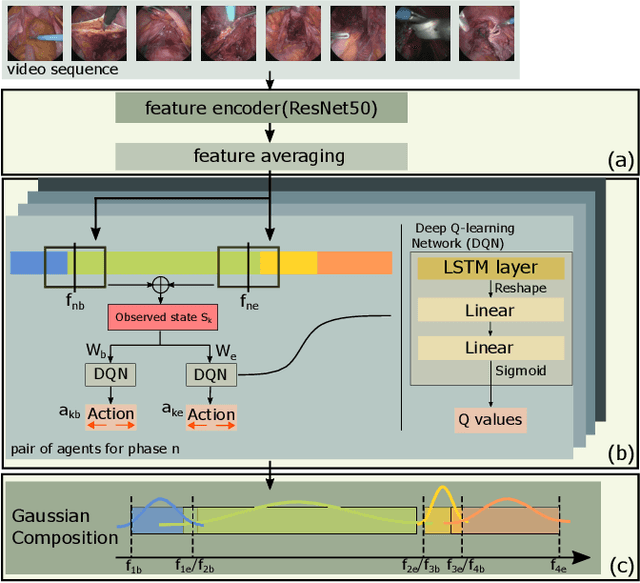
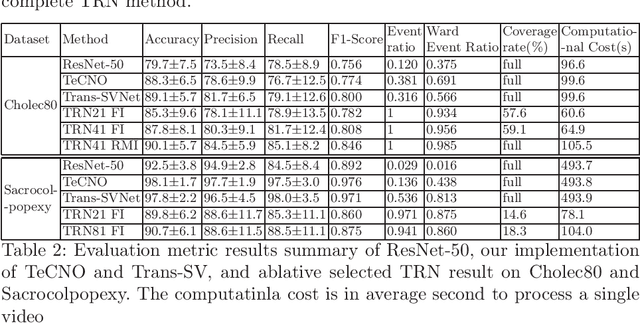
In minimally invasive surgery, surgical workflow segmentation from video analysis is a well studied topic. The conventional approach defines it as a multi-class classification problem, where individual video frames are attributed a surgical phase label. We introduce a novel reinforcement learning formulation for offline phase transition retrieval. Instead of attempting to classify every video frame, we identify the timestamp of each phase transition. By construction, our model does not produce spurious and noisy phase transitions, but contiguous phase blocks. We investigate two different configurations of this model. The first does not require processing all frames in a video (only <60% and <20% of frames in 2 different applications), while producing results slightly under the state-of-the-art accuracy. The second configuration processes all video frames, and outperforms the state-of-the art at a comparable computational cost. We compare our method against the recent top-performing frame-based approaches TeCNO and Trans-SVNet on the public dataset Cholec80 and also on an in-house dataset of laparoscopic sacrocolpopexy. We perform both a frame-based (accuracy, precision, recall and F1-score) and an event-based (event ratio) evaluation of our algorithms.
Learning-Based Keypoint Registration for Fetoscopic Mosaicking
Jul 26, 2022
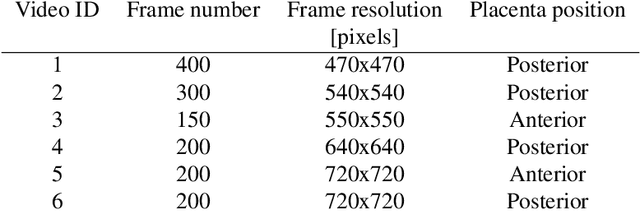
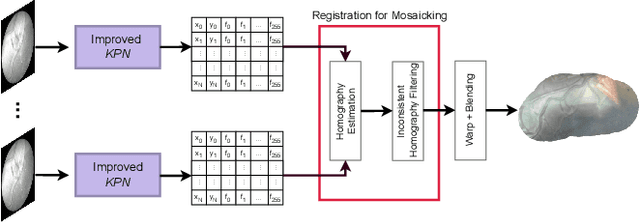

In Twin-to-Twin Transfusion Syndrome (TTTS), abnormal vascular anastomoses in the monochorionic placenta can produce uneven blood flow between the two fetuses. In the current practice, TTTS is treated surgically by closing abnormal anastomoses using laser ablation. This surgery is minimally invasive and relies on fetoscopy. Limited field of view makes anastomosis identification a challenging task for the surgeon. To tackle this challenge, we propose a learning-based framework for in-vivo fetoscopy frame registration for field-of-view expansion. The novelties of this framework relies on a learning-based keypoint proposal network and an encoding strategy to filter (i) irrelevant keypoints based on fetoscopic image segmentation and (ii) inconsistent homographies. We validate of our framework on a dataset of 6 intraoperative sequences from 6 TTTS surgeries from 6 different women against the most recent state of the art algorithm, which relies on the segmentation of placenta vessels. The proposed framework achieves higher performance compared to the state of the art, paving the way for robust mosaicking to provide surgeons with context awareness during TTTS surgery.
FetReg2021: A Challenge on Placental Vessel Segmentation and Registration in Fetoscopy
Jun 30, 2022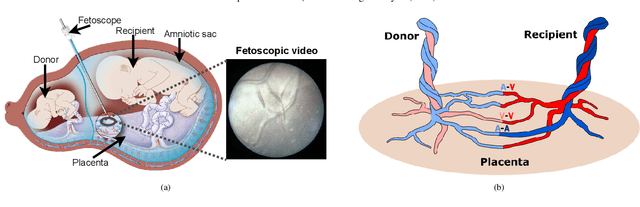
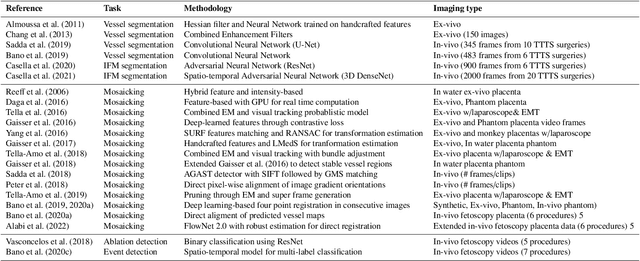
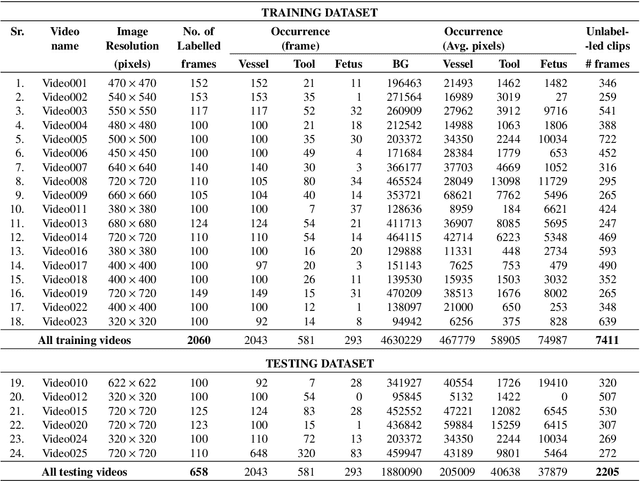
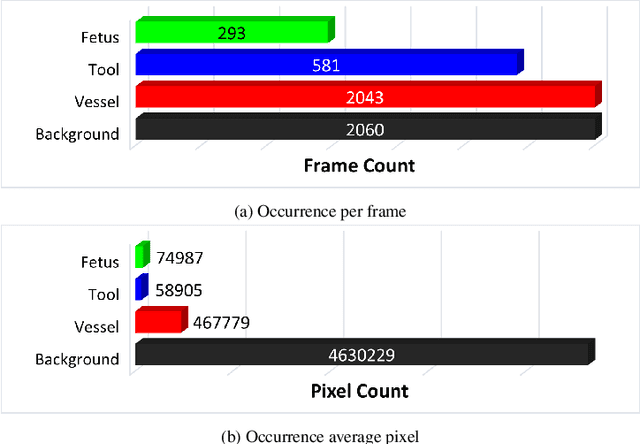
Fetoscopy laser photocoagulation is a widely adopted procedure for treating Twin-to-Twin Transfusion Syndrome (TTTS). The procedure involves photocoagulation pathological anastomoses to regulate blood exchange among twins. The procedure is particularly challenging due to the limited field of view, poor manoeuvrability of the fetoscope, poor visibility, and variability in illumination. These challenges may lead to increased surgery time and incomplete ablation. Computer-assisted intervention (CAI) can provide surgeons with decision support and context awareness by identifying key structures in the scene and expanding the fetoscopic field of view through video mosaicking. Research in this domain has been hampered by the lack of high-quality data to design, develop and test CAI algorithms. Through the Fetoscopic Placental Vessel Segmentation and Registration (FetReg2021) challenge, which was organized as part of the MICCAI2021 Endoscopic Vision challenge, we released the first largescale multicentre TTTS dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms. For this challenge, we released a dataset of 2060 images, pixel-annotated for vessels, tool, fetus and background classes, from 18 in-vivo TTTS fetoscopy procedures and 18 short video clips. Seven teams participated in this challenge and their model performance was assessed on an unseen test dataset of 658 pixel-annotated images from 6 fetoscopic procedures and 6 short clips. The challenge provided an opportunity for creating generalized solutions for fetoscopic scene understanding and mosaicking. In this paper, we present the findings of the FetReg2021 challenge alongside reporting a detailed literature review for CAI in TTTS fetoscopy. Through this challenge, its analysis and the release of multi-centre fetoscopic data, we provide a benchmark for future research in this field.
BiometryNet: Landmark-based Fetal Biometry Estimation from Standard Ultrasound Planes
Jun 29, 2022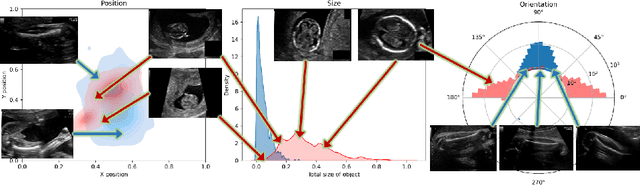
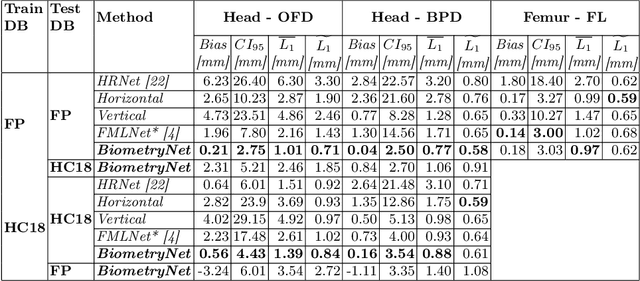
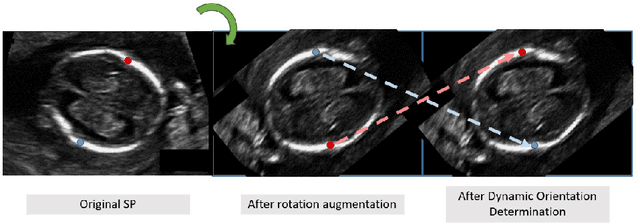
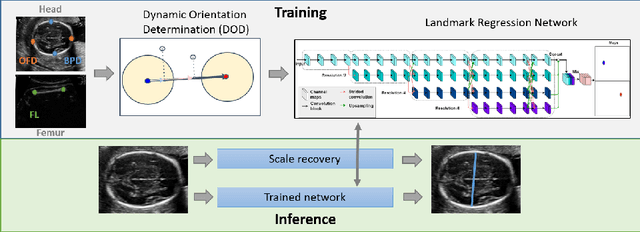
Fetal growth assessment from ultrasound is based on a few biometric measurements that are performed manually and assessed relative to the expected gestational age. Reliable biometry estimation depends on the precise detection of landmarks in standard ultrasound planes. Manual annotation can be time-consuming and operator dependent task, and may results in high measurements variability. Existing methods for automatic fetal biometry rely on initial automatic fetal structure segmentation followed by geometric landmark detection. However, segmentation annotations are time-consuming and may be inaccurate, and landmark detection requires developing measurement-specific geometric methods. This paper describes BiometryNet, an end-to-end landmark regression framework for fetal biometry estimation that overcomes these limitations. It includes a novel Dynamic Orientation Determination (DOD) method for enforcing measurement-specific orientation consistency during network training. DOD reduces variabilities in network training, increases landmark localization accuracy, thus yields accurate and robust biometric measurements. To validate our method, we assembled a dataset of 3,398 ultrasound images from 1,829 subjects acquired in three clinical sites with seven different ultrasound devices. Comparison and cross-validation of three different biometric measurements on two independent datasets shows that BiometryNet is robust and yields accurate measurements whose errors are lower than the clinically permissible errors, outperforming other existing automated biometry estimation methods. Code is available at https://github.com/netanellavisdris/fetalbiometry.