 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCol3D -- 3D Reconstruction during Colonoscopy Challenge
Jul 20, 2023Colorectal cancer is one of the most common cancers in the world. While colonoscopy is an effective screening technique, navigating an endoscope through the colon to detect polyps is challenging. A 3D map of the observed surfaces could enhance the identification of unscreened colon tissue and serve as a training platform. However, reconstructing the colon from video footage remains unsolved due to numerous factors such as self-occlusion, reflective surfaces, lack of texture, and tissue deformation that limit feature-based methods. Learning-based approaches hold promise as robust alternatives, but necessitate extensive datasets. By establishing a benchmark, the 2022 EndoVis sub-challenge SimCol3D aimed to facilitate data-driven depth and pose prediction during colonoscopy. The challenge was hosted as part of MICCAI 2022 in Singapore. Six teams from around the world and representatives from academia and industry participated in the three sub-challenges: synthetic depth prediction, synthetic pose prediction, and real pose prediction. This paper describes the challenge, the submitted methods, and their results. We show that depth prediction in virtual colonoscopy is robustly solvable, while pose estimation remains an open research question.
ColNav: Real-Time Colon Navigation for Colonoscopy
Jun 07, 2023



Colorectal cancer screening through colonoscopy continues to be the dominant global standard, as it allows identifying pre-cancerous or adenomatous lesions and provides the ability to remove them during the procedure itself. Nevertheless, failure by the endoscopist to identify such lesions increases the likelihood of lesion progression to subsequent colorectal cancer. Ultimately, colonoscopy remains operator-dependent, and the wide range of quality in colonoscopy examinations among endoscopists is influenced by variations in their technique, training, and diligence. This paper presents a novel real-time navigation guidance system for Optical Colonoscopy (OC). Our proposed system employs a real-time approach that displays both an unfolded representation of the colon and a local indicator directing to un-inspected areas. These visualizations are presented to the physician during the procedure, providing actionable and comprehensible guidance to un-surveyed areas in real-time, while seamlessly integrating into the physician's workflow. Through coverage experimental evaluation, we demonstrated that our system resulted in a higher polyp recall (PR) and high inter-rater reliability with physicians for coverage prediction. These results suggest that our real-time navigation guidance system has the potential to improve the quality and effectiveness of Optical Colonoscopy and ultimately benefit patient outcomes.
Estimating the coverage in 3d reconstructions of the colon from colonoscopy videos
Oct 19, 2022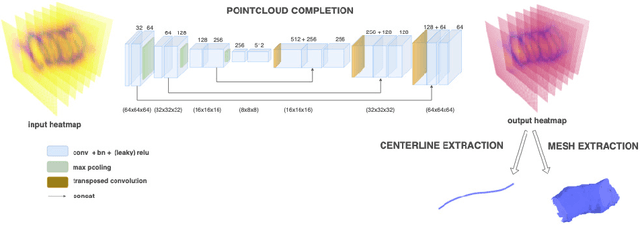

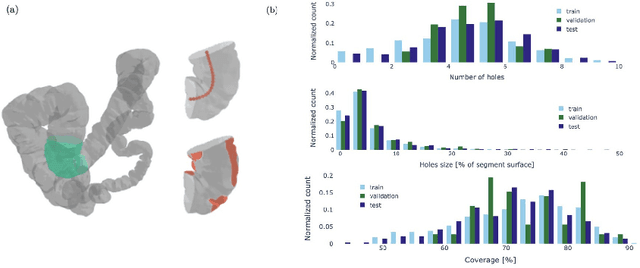
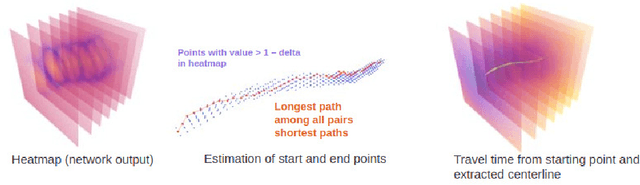
Colonoscopy is the most common procedure for early detection and removal of polyps, a critical component of colorectal cancer prevention. Insufficient visual coverage of the colon surface during the procedure often results in missed polyps. To mitigate this issue, reconstructing the 3D surfaces of the colon in order to visualize the missing regions has been proposed. However, robustly estimating the local and global coverage from such a reconstruction has not been thoroughly investigated until now. In this work, we present a new method to estimate the coverage from a reconstructed colon pointcloud. Our method splits a reconstructed colon into segments and estimates the coverage of each segment by estimating the area of the missing surfaces. We achieve a mean absolute coverage error of 3-6\% on colon segments generated from synthetic colonoscopy data and real colonography CT scans. In addition, we show good qualitative results on colon segments reconstructed from real colonoscopy videos.
Colonoscopy Landmark Detection using Vision Transformers
Sep 27, 2022
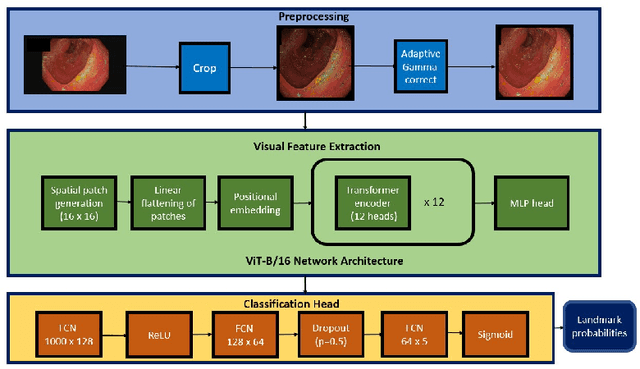
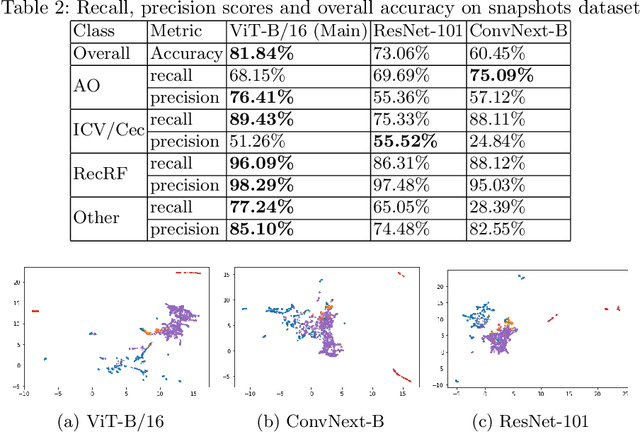
Colonoscopy is a routine outpatient procedure used to examine the colon and rectum for any abnormalities including polyps, diverticula and narrowing of colon structures. A significant amount of the clinician's time is spent in post-processing snapshots taken during the colonoscopy procedure, for maintaining medical records or further investigation. Automating this step can save time and improve the efficiency of the process. In our work, we have collected a dataset of 120 colonoscopy videos and 2416 snapshots taken during the procedure, that have been annotated by experts. Further, we have developed a novel, vision-transformer based landmark detection algorithm that identifies key anatomical landmarks (the appendiceal orifice, ileocecal valve/cecum landmark and rectum retroflexion) from snapshots taken during colonoscopy. Our algorithm uses an adaptive gamma correction during preprocessing to maintain a consistent brightness for all images. We then use a vision transformer as the feature extraction backbone and a fully connected network based classifier head to categorize a given frame into four classes: the three landmarks or a non-landmark frame. We compare the vision transformer (ViT-B/16) backbone with ResNet-101 and ConvNext-B backbones that have been trained similarly. We report an accuracy of 82% with the vision transformer backbone on a test dataset of snapshots.
C$^3$Fusion: Consistent Contrastive Colon Fusion, Towards Deep SLAM in Colonoscopy
Jun 04, 2022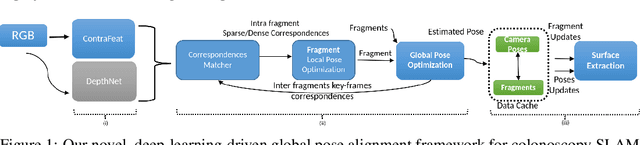

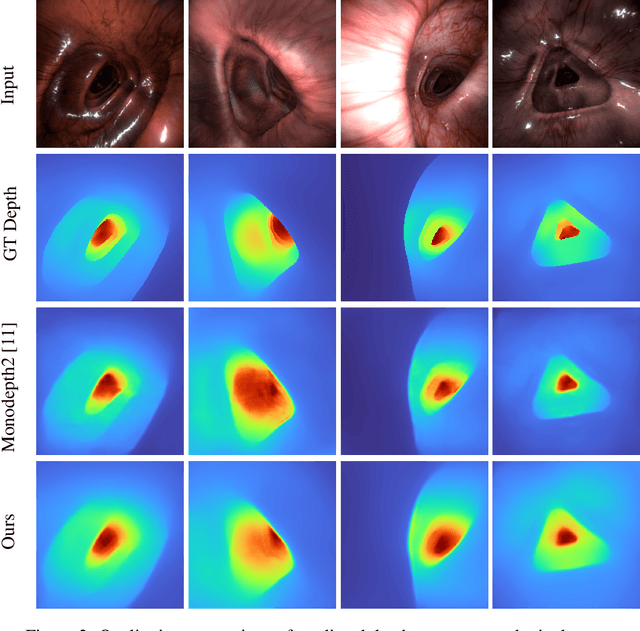

3D colon reconstruction from Optical Colonoscopy (OC) to detect non-examined surfaces remains an unsolved problem. The challenges arise from the nature of optical colonoscopy data, characterized by highly reflective low-texture surfaces, drastic illumination changes and frequent tracking loss. Recent methods demonstrate compelling results, but suffer from: (1) frangible frame-to-frame (or frame-to-model) pose estimation resulting in many tracking failures; or (2) rely on point-based representations at the cost of scan quality. In this paper, we propose a novel reconstruction framework that addresses these issues end to end, which result in both quantitatively and qualitatively accurate and robust 3D colon reconstruction. Our SLAM approach, which employs correspondences based on contrastive deep features, and deep consistent depth maps, estimates globally optimized poses, is able to recover from frequent tracking failures, and estimates a global consistent 3D model; all within a single framework. We perform an extensive experimental evaluation on multiple synthetic and real colonoscopy videos, showing high-quality results and comparisons against relevant baselines.
Motion Segmentation Using Locally Affine Atom Voting
Jul 13, 2019

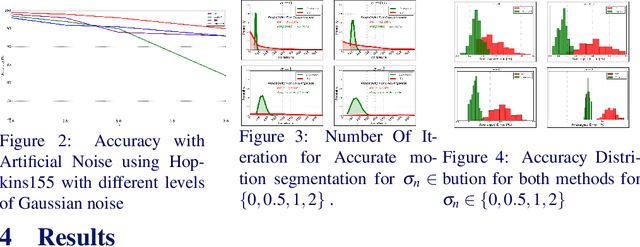
We present a novel method for motion segmentation called LAAV (Locally Affine Atom Voting). Our model's main novelty is using sets of features to segment motion for all features in the scene. LAAV acts as a pre-processing pipeline stage for features in the image, followed by a fine-tuned version of the state-of-the-art Random Voting (RV) method. Unlike standard approaches, LAAV segments motion using feature-set affinities instead of pair-wise affinities between all features; therefore, it significantly simplifies complex scenarios and reduces the computational cost without a loss of accuracy. We describe how the challenges encountered by using previously suggested approaches are addressed using our model. We then compare our algorithm with several state-of-the-art methods. Experiments shows that our approach achieves the most accurate motion segmentation results and, in the presence of measurement noise, achieves comparable results to the other algorithms.