 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Named Entity Recognition with Partially-Observed TreeCRFs
Dec 15, 2020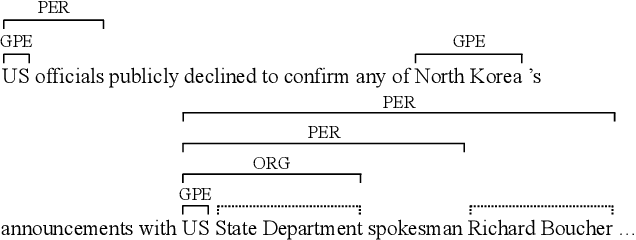
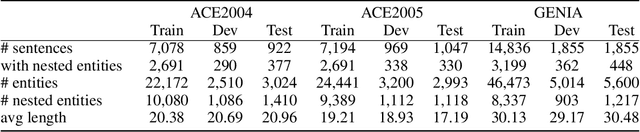
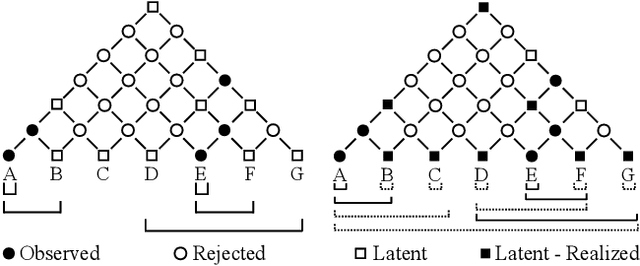
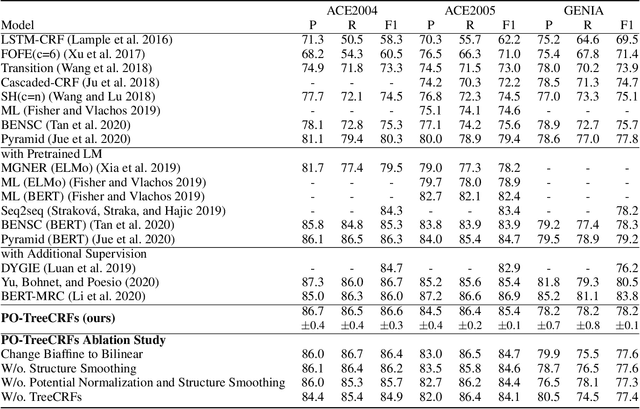
Named entity recognition (NER) is a well-studied task in natural language processing. However, the widely-used sequence labeling framework is difficult to detect entities with nested structures. In this work, we view nested NER as constituency parsing with partially-observed trees and model it with partially-observed TreeCRFs. Specifically, we view all labeled entity spans as observed nodes in a constituency tree, and other spans as latent nodes. With the TreeCRF we achieve a uniform way to jointly model the observed and the latent nodes. To compute the probability of partial trees with partial marginalization, we propose a variant of the Inside algorithm, the \textsc{Masked Inside} algorithm, that supports different inference operations for different nodes (evaluation for the observed, marginalization for the latent, and rejection for nodes incompatible with the observed) with efficient parallelized implementation, thus significantly speeding up training and inference. Experiments show that our approach achieves the state-of-the-art (SOTA) F1 scores on the ACE2004, ACE2005 dataset, and shows comparable performance to SOTA models on the GENIA dataset. Our approach is implemented at: \url{https://github.com/FranxYao/Partially-Observed-TreeCRFs}.
VECO: Variable Encoder-decoder Pre-training for Cross-lingual Understanding and Generation
Oct 30, 2020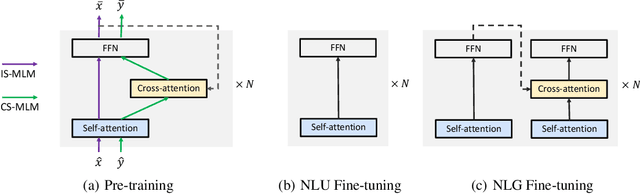
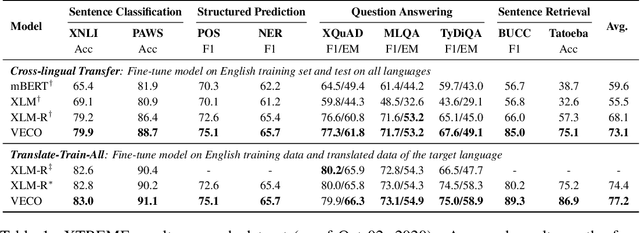

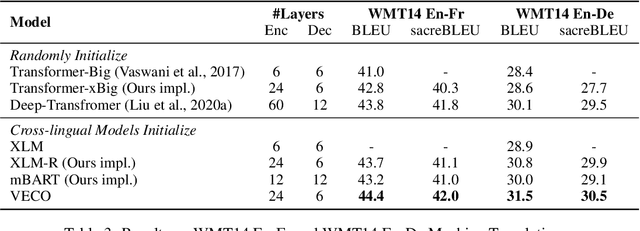
Recent studies about learning multilingual representations have achieved significant performance gains across a wide range of downstream cross-lingual tasks. They train either an encoder-only Transformer mainly for understanding tasks, or an encoder-decoder Transformer specifically for generation tasks, ignoring the correlation between the two tasks and frameworks. In contrast, this paper presents a variable encoder-decoder (VECO) pre-training approach to unify the two mainstreams in both model architectures and pre-training tasks. VECO splits the standard Transformer block into several sub-modules trained with both inner-sequence and cross-sequence masked language modeling, and correspondingly reorganizes certain sub-modules for understanding and generation tasks during inference. Such a workflow not only ensures to train the most streamlined parameters necessary for two kinds of tasks, but also enables them to boost each other via sharing common sub-modules. As a result, VECO delivers new state-of-the-art results on various cross-lingual understanding tasks of the XTREME benchmark covering text classification, sequence labeling, question answering, and sentence retrieval. For generation tasks, VECO also outperforms all existing cross-lingual models and state-of-the-art Transformer variants on WMT14 English-to-German and English-to-French translation datasets, with gains of up to 1$\sim$2 BLEU.
Predicting Clinical Trial Results by Implicit Evidence Integration
Oct 12, 2020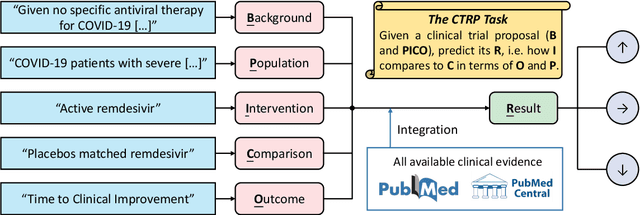
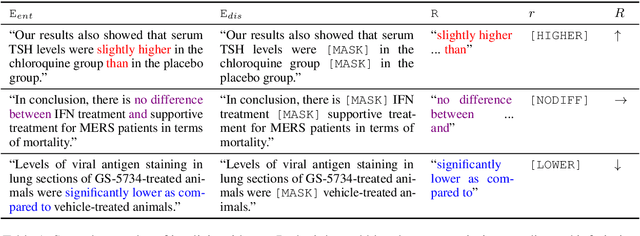
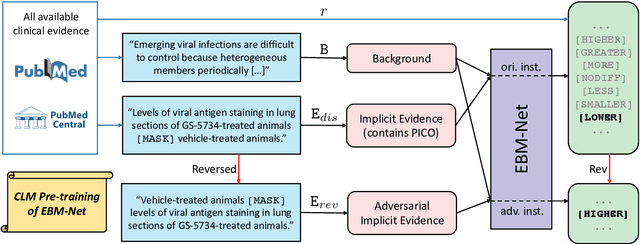
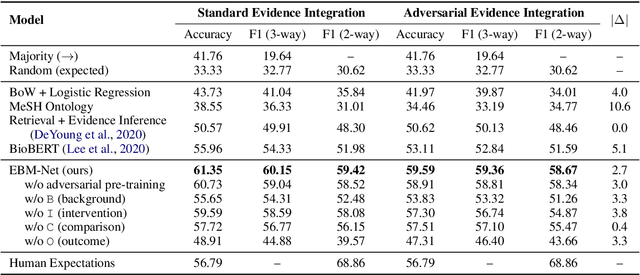
Clinical trials provide essential guidance for practicing Evidence-Based Medicine, though often accompanying with unendurable costs and risks. To optimize the design of clinical trials, we introduce a novel Clinical Trial Result Prediction (CTRP) task. In the CTRP framework, a model takes a PICO-formatted clinical trial proposal with its background as input and predicts the result, i.e. how the Intervention group compares with the Comparison group in terms of the measured Outcome in the studied Population. While structured clinical evidence is prohibitively expensive for manual collection, we exploit large-scale unstructured sentences from medical literature that implicitly contain PICOs and results as evidence. Specifically, we pre-train a model to predict the disentangled results from such implicit evidence and fine-tune the model with limited data on the downstream datasets. Experiments on the benchmark Evidence Integration dataset show that the proposed model outperforms the baselines by large margins, e.g., with a 10.7% relative gain over BioBERT in macro-F1. Moreover, the performance improvement is also validated on another dataset composed of clinical trials related to COVID-19.
Encoding Implicit Relation Requirements for Relation Extraction: A Joint Inference Approach
Nov 09, 2018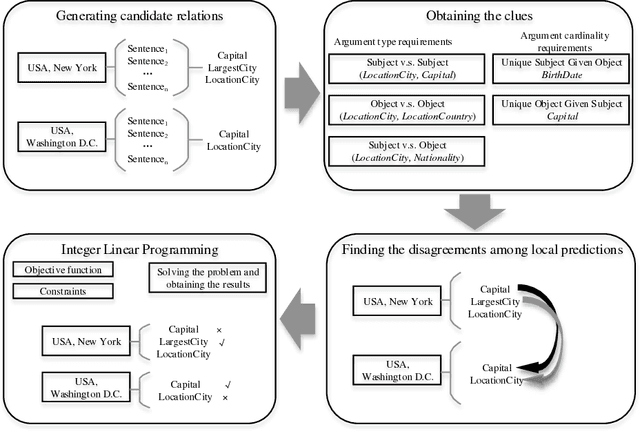
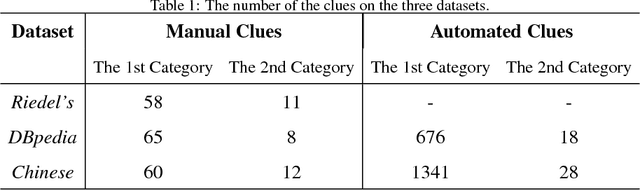
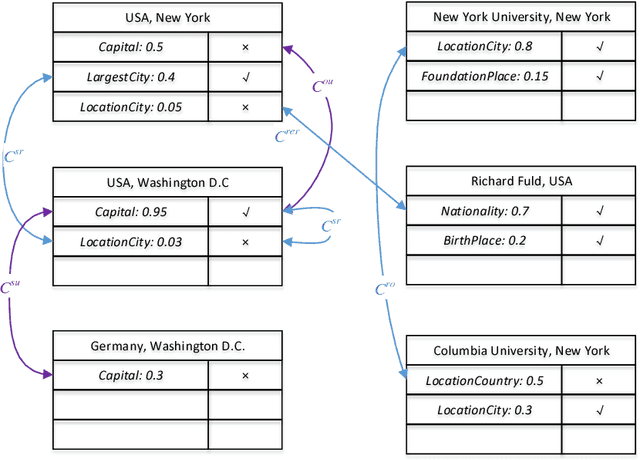

Relation extraction is the task of identifying predefined relationship between entities, and plays an essential role in information extraction, knowledge base construction, question answering and so on. Most existing relation extractors make predictions for each entity pair locally and individually, while ignoring implicit global clues available across different entity pairs and in the knowledge base, which often leads to conflicts among local predictions from different entity pairs. This paper proposes a joint inference framework that employs such global clues to resolve disagreements among local predictions. We exploit two kinds of clues to generate constraints which can capture the implicit type and cardinality requirements of a relation. Those constraints can be examined in either hard style or soft style, both of which can be effectively explored in an integer linear program formulation. Experimental results on both English and Chinese datasets show that our proposed framework can effectively utilize those two categories of global clues and resolve the disagreements among local predictions, thus improve various relation extractors when such clues are applicable to the datasets. Our experiments also indicate that the clues learnt automatically from existing knowledge bases perform comparably to or better than those refined by human.
* to appear in Artificial Intelligence
Marrying up Regular Expressions with Neural Networks: A Case Study for Spoken Language Understanding
May 15, 2018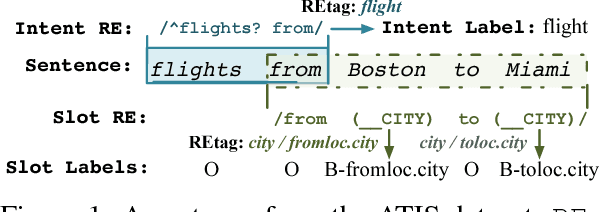
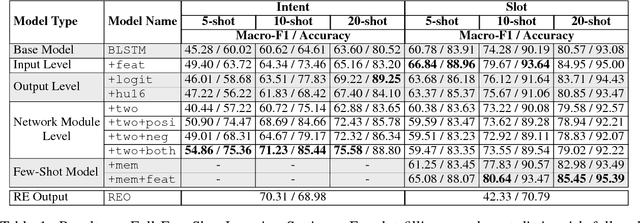
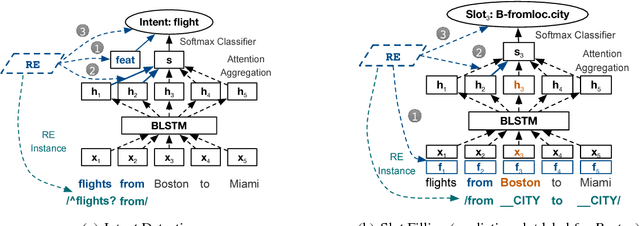
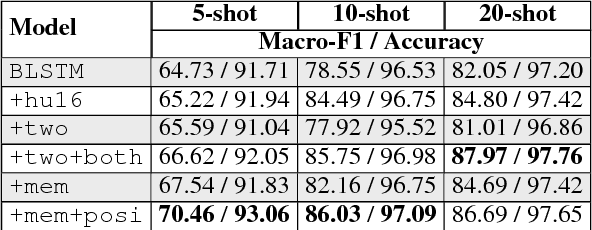
The success of many natural language processing (NLP) tasks is bound by the number and quality of annotated data, but there is often a shortage of such training data. In this paper, we ask the question: "Can we combine a neural network (NN) with regular expressions (RE) to improve supervised learning for NLP?". In answer, we develop novel methods to exploit the rich expressiveness of REs at different levels within a NN, showing that the combination significantly enhances the learning effectiveness when a small number of training examples are available. We evaluate our approach by applying it to spoken language understanding for intent detection and slot filling. Experimental results show that our approach is highly effective in exploiting the available training data, giving a clear boost to the RE-unaware NN.
Learning with Noise: Enhance Distantly Supervised Relation Extraction with Dynamic Transition Matrix
May 11, 2017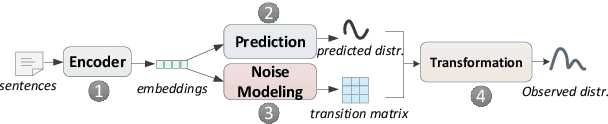
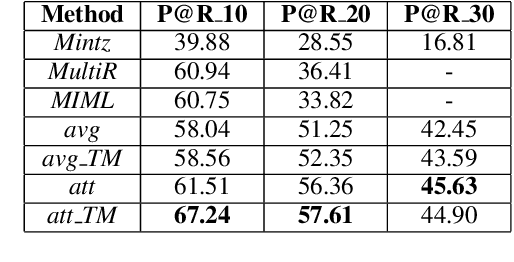
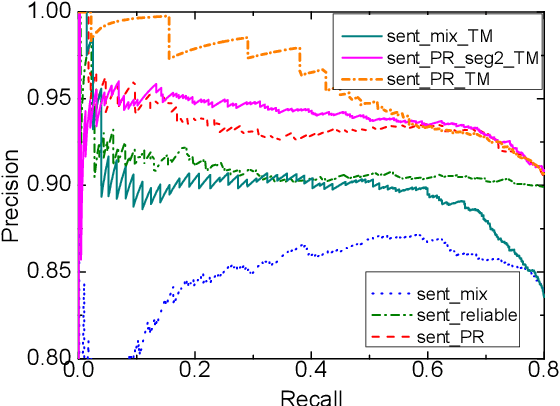
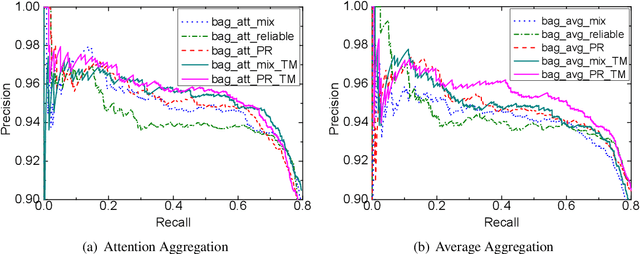
Distant supervision significantly reduces human efforts in building training data for many classification tasks. While promising, this technique often introduces noise to the generated training data, which can severely affect the model performance. In this paper, we take a deep look at the application of distant supervision in relation extraction. We show that the dynamic transition matrix can effectively characterize the noise in the training data built by distant supervision. The transition matrix can be effectively trained using a novel curriculum learning based method without any direct supervision about the noise. We thoroughly evaluate our approach under a wide range of extraction scenarios. Experimental results show that our approach consistently improves the extraction results and outperforms the state-of-the-art in various evaluation scenarios.
Question Answering on Freebase via Relation Extraction and Textual Evidence
Jun 09, 2016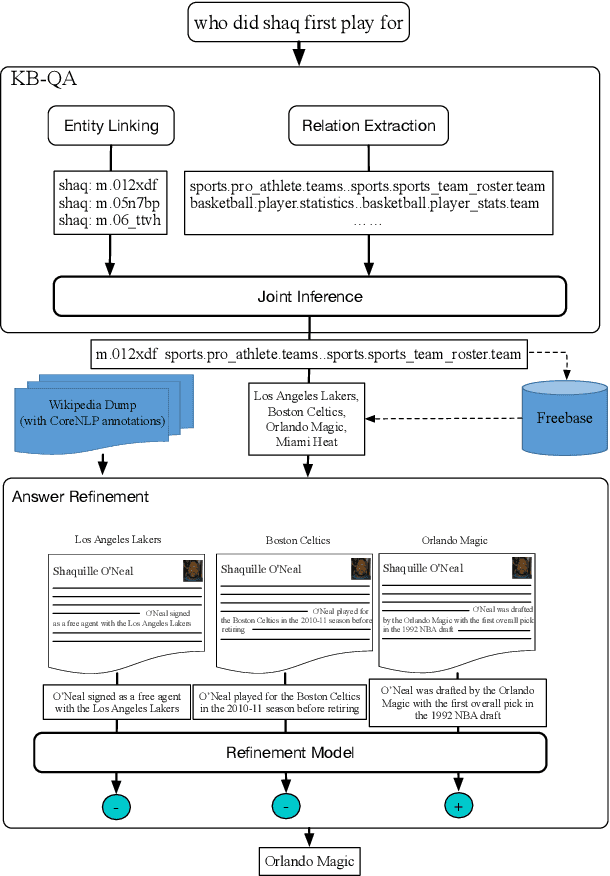
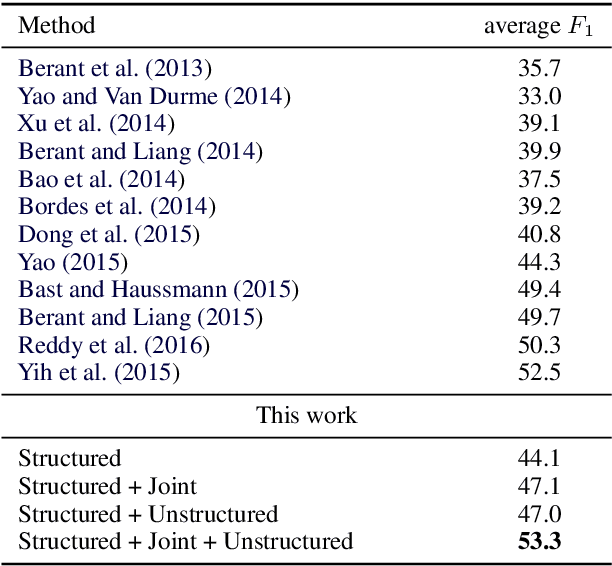
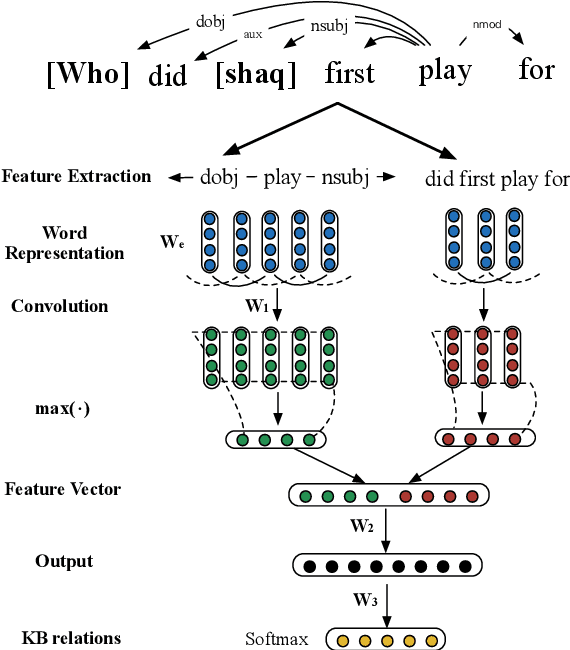

Existing knowledge-based question answering systems often rely on small annotated training data. While shallow methods like relation extraction are robust to data scarcity, they are less expressive than the deep meaning representation methods like semantic parsing, thereby failing at answering questions involving multiple constraints. Here we alleviate this problem by empowering a relation extraction method with additional evidence from Wikipedia. We first present a neural network based relation extractor to retrieve the candidate answers from Freebase, and then infer over Wikipedia to validate these answers. Experiments on the WebQuestions question answering dataset show that our method achieves an F_1 of 53.3%, a substantial improvement over the state-of-the-art.
Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling
Jun 25, 2015

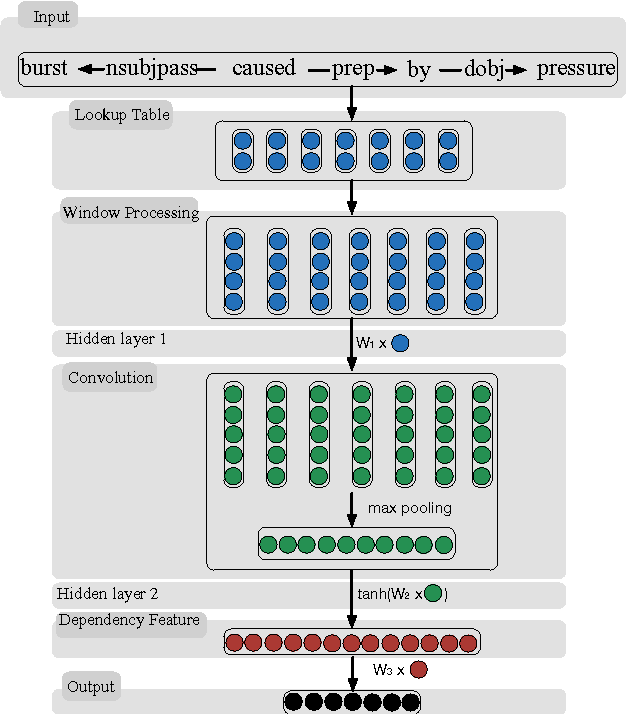
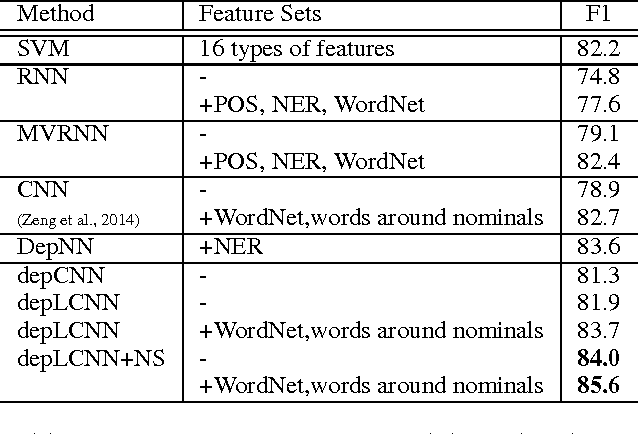
Syntactic features play an essential role in identifying relationship in a sentence. Previous neural network models often suffer from irrelevant information introduced when subjects and objects are in a long distance. In this paper, we propose to learn more robust relation representations from the shortest dependency path through a convolution neural network. We further propose a straightforward negative sampling strategy to improve the assignment of subjects and objects. Experimental results show that our method outperforms the state-of-the-art methods on the SemEval-2010 Task 8 dataset.