 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Spatially Sparse Inference for Conditional GANs and Diffusion Models
Nov 15, 2022



During image editing, existing deep generative models tend to re-synthesize the entire output from scratch, including the unedited regions. This leads to a significant waste of computation, especially for minor editing operations. In this work, we present Spatially Sparse Inference (SSI), a general-purpose technique that selectively performs computation for edited regions and accelerates various generative models, including both conditional GANs and diffusion models. Our key observation is that users tend to make gradual changes to the input image. This motivates us to cache and reuse the feature maps of the original image. Given an edited image, we sparsely apply the convolutional filters to the edited regions while reusing the cached features for the unedited regions. Based on our algorithm, we further propose Sparse Incremental Generative Engine (SIGE) to convert the computation reduction to latency reduction on off-the-shelf hardware. With 1.2%-area edited regions, our method reduces the computation of DDIM by 7.5$\times$ and GauGAN by 18$\times$ while preserving the visual fidelity. With SIGE, we accelerate the speed of DDIM by 3.0x on RTX 3090 and 6.6$\times$ on Apple M1 Pro CPU, and GauGAN by 4.2$\times$ on RTX 3090 and 14$\times$ on Apple M1 Pro CPU.
QuEst: Graph Transformer for Quantum Circuit Reliability Estimation
Oct 30, 2022Among different quantum algorithms, PQC for QML show promises on near-term devices. To facilitate the QML and PQC research, a recent python library called TorchQuantum has been released. It can construct, simulate, and train PQC for machine learning tasks with high speed and convenient debugging supports. Besides quantum for ML, we want to raise the community's attention on the reversed direction: ML for quantum. Specifically, the TorchQuantum library also supports using data-driven ML models to solve problems in quantum system research, such as predicting the impact of quantum noise on circuit fidelity and improving the quantum circuit compilation efficiency. This paper presents a case study of the ML for quantum part. Since estimating the noise impact on circuit reliability is an essential step toward understanding and mitigating noise, we propose to leverage classical ML to predict noise impact on circuit fidelity. Inspired by the natural graph representation of quantum circuits, we propose to leverage a graph transformer model to predict the noisy circuit fidelity. We firstly collect a large dataset with a variety of quantum circuits and obtain their fidelity on noisy simulators and real machines. Then we embed each circuit into a graph with gate and noise properties as node features, and adopt a graph transformer to predict the fidelity. Evaluated on 5 thousand random and algorithm circuits, the graph transformer predictor can provide accurate fidelity estimation with RMSE error 0.04 and outperform a simple neural network-based model by 0.02 on average. It can achieve 0.99 and 0.95 R$^2$ scores for random and algorithm circuits, respectively. Compared with circuit simulators, the predictor has over 200X speedup for estimating the fidelity.
PAN: Pulse Ansatz on NISQ Machines
Aug 02, 2022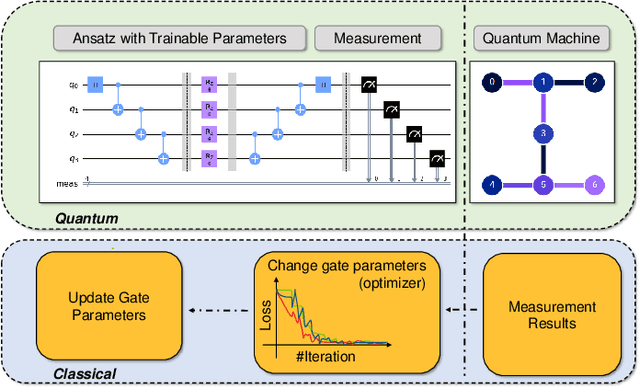
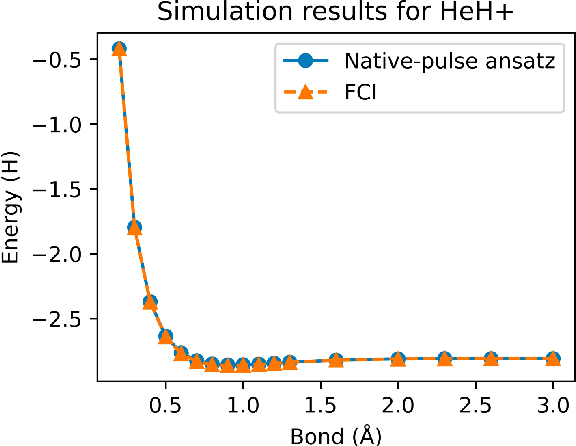
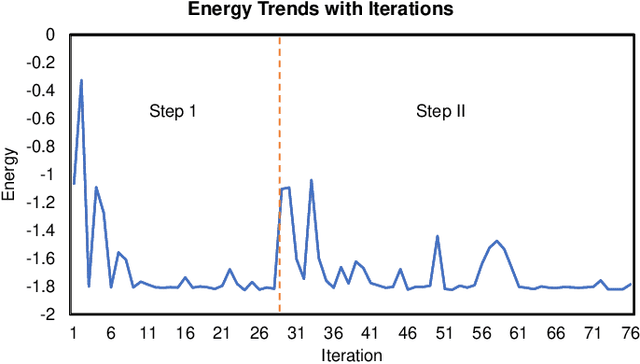

Variational quantum algorithms (VQAs) have demonstrated great potentials in the NISQ era. In the workflow of VQA, the parameters of ansatz are iteratively updated to approximate the desired quantum states. We have seen various efforts to draft better ansatz with less gates. In quantum computers, the gate ansatz will eventually be transformed into control signals such as microwave pulses on transmons. And the control pulses need elaborate calibration to minimize the errors such as over-rotation and under-rotation. In the case of VQAs, this procedure will introduce redundancy, but the variational properties of VQAs can naturally handle problems of over-rotation and under-rotation by updating the amplitude and frequency parameters. Therefore, we propose PAN, a native-pulse ansatz generator framework for VQAs. We generate native-pulse ansatz with trainable parameters for amplitudes and frequencies. In our proposed PAN, we are tuning parametric pulses, which are natively supported on NISQ computers. Considering that parameter-shift rules do not hold for native-pulse ansatz, we need to deploy non-gradient optimizers. To constrain the number of parameters sent to the optimizer, we adopt a progressive way to generate our native-pulse ansatz. Experiments are conducted on both simulators and quantum devices to validate our methods. When adopted on NISQ machines, PAN obtained improved the performance with decreased latency by an average of 86%. PAN is able to achieve 99.336% and 96.482% accuracy for VQE tasks on H2 and HeH+ respectively, even with considerable noises in NISQ machines.
On-Device Training Under 256KB Memory
Jul 14, 2022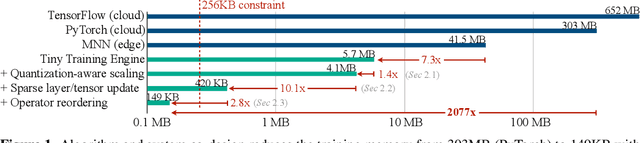
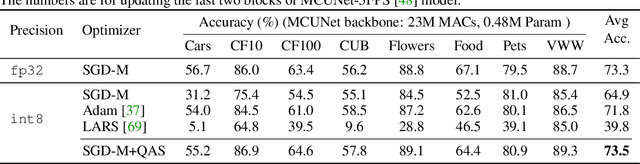
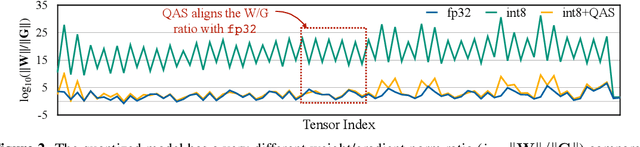
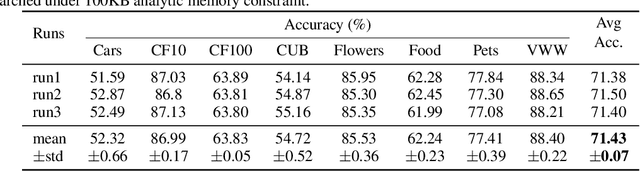
On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to mixed bit-precision and the lack of normalization; (2) the limited hardware resource (memory and computation) does not allow full backward computation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offloads the runtime auto-differentiation to compile time. Our framework is the first practical solution for on-device transfer learning of visual recognition on tiny IoT devices (e.g., a microcontroller with only 256KB SRAM), using less than 1/100 of the memory of existing frameworks while matching the accuracy of cloud training+edge deployment for the tinyML application VWW. Our study enables IoT devices to not only perform inference but also continuously adapt to new data for on-device lifelong learning.
RobustAnalog: Fast Variation-Aware Analog Circuit Design Via Multi-task RL
Jul 13, 2022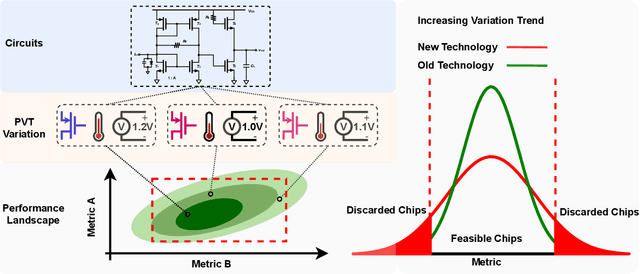
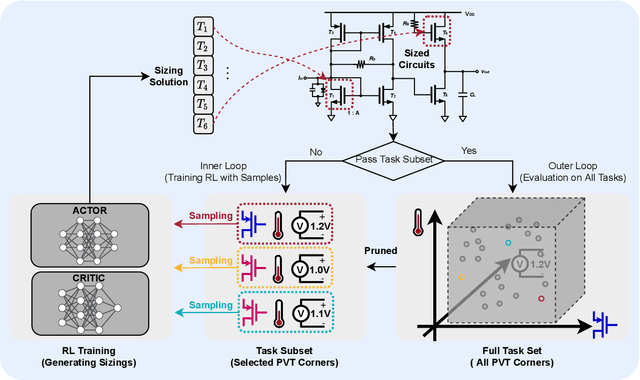
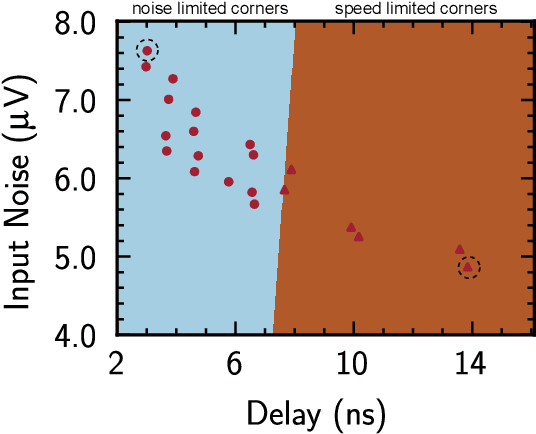
Analog/mixed-signal circuit design is one of the most complex and time-consuming stages in the whole chip design process. Due to various process, voltage, and temperature (PVT) variations from chip manufacturing, analog circuits inevitably suffer from performance degradation. Although there has been plenty of work on automating analog circuit design under the typical condition, limited research has been done on exploring robust designs under real and unpredictable silicon variations. Automatic analog design against variations requires prohibitive computation and time costs. To address the challenge, we present RobustAnalog, a robust circuit design framework that involves the variation information in the optimization process. Specifically, circuit optimizations under different variations are considered as a set of tasks. Similarities among tasks are leveraged and competitions are alleviated to realize a sample-efficient multi-task training. Moreover, RobustAnalog prunes the task space according to the current performance in each iteration, leading to a further simulation cost reduction. In this way, RobustAnalog can rapidly produce a set of circuit parameters that satisfies diverse constraints (e.g. gain, bandwidth, noise...) across variations. We compare RobustAnalog with Bayesian optimization, Evolutionary algorithm, and Deep Deterministic Policy Gradient (DDPG) and demonstrate that RobustAnalog can significantly reduce required optimization time by 14-30 times. Therefore, our study provides a feasible method to handle various real silicon conditions.
MME-CRS: Multi-Metric Evaluation Based on Correlation Re-Scaling for Evaluating Open-Domain Dialogue
Jun 19, 2022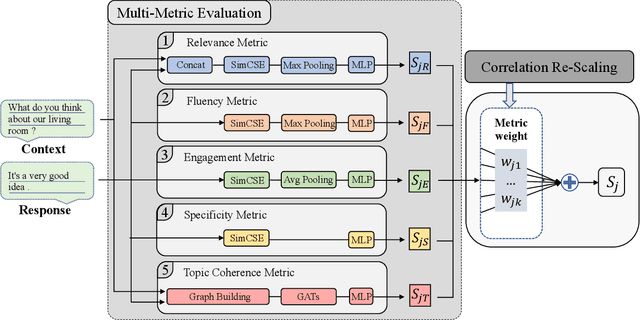
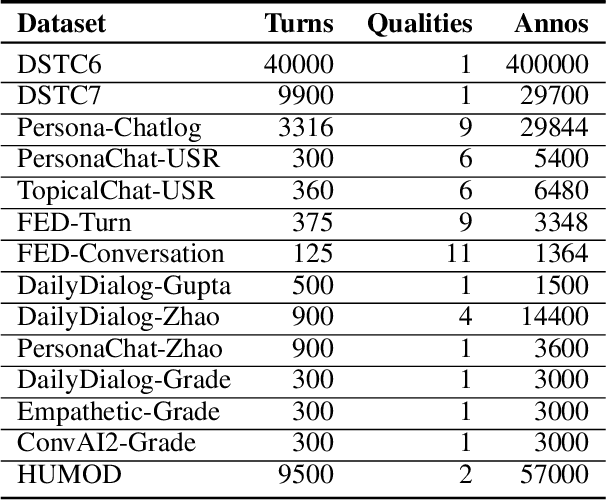

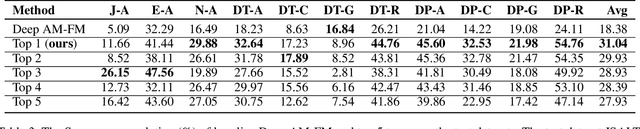
Automatic open-domain dialogue evaluation is a crucial component of dialogue systems. Recently, learning-based evaluation metrics have achieved state-of-the-art performance in open-domain dialogue evaluation. However, these metrics, which only focus on a few qualities, are hard to evaluate dialogue comprehensively. Furthermore, these metrics lack an effective score composition approach for diverse evaluation qualities. To address the above problems, we propose a Multi-Metric Evaluation based on Correlation Re-Scaling (MME-CRS) for evaluating open-domain dialogue. Firstly, we build an evaluation metric composed of 5 groups of parallel sub-metrics called Multi-Metric Evaluation (MME) to evaluate the quality of dialogue comprehensively. Furthermore, we propose a novel score composition method called Correlation Re-Scaling (CRS) to model the relationship between sub-metrics and diverse qualities. Our approach MME-CRS ranks first on the final test data of DSTC10 track5 subtask1 Automatic Open-domain Dialogue Evaluation Challenge with a large margin, which proved the effectiveness of our proposed approach.
EfficientViT: Enhanced Linear Attention for High-Resolution Low-Computation Visual Recognition
May 29, 2022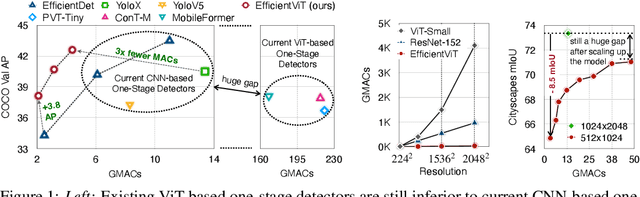
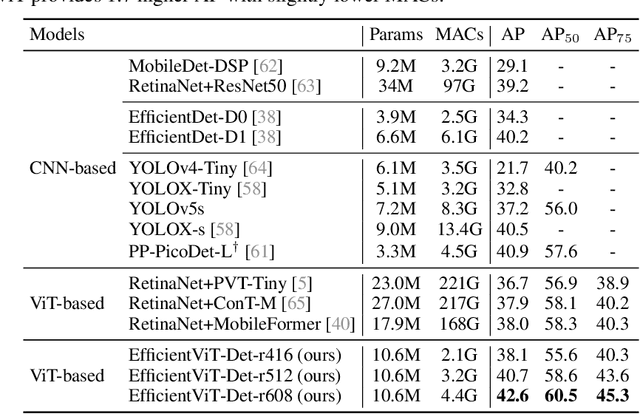
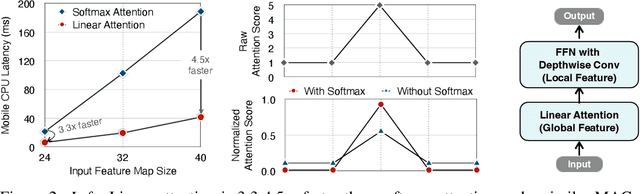
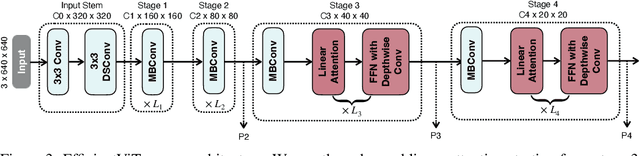
Vision Transformer (ViT) has achieved remarkable performance in many vision tasks. However, ViT is inferior to convolutional neural networks (CNNs) when targeting high-resolution mobile vision applications. The key computational bottleneck of ViT is the softmax attention module which has quadratic computational complexity with the input resolution. It is essential to reduce the cost of ViT to deploy it on edge devices. Existing methods (e.g., Swin, PVT) restrict the softmax attention within local windows or reduce the resolution of key/value tensors to reduce the cost, which sacrifices ViT's core advantages on global feature extractions. In this work, we present EfficientViT, an efficient ViT architecture for high-resolution low-computation visual recognition. Instead of restricting the softmax attention, we propose to replace softmax attention with linear attention while enhancing its local feature extraction ability with depthwise convolution. EfficientViT maintains global and local feature extraction capability while enjoying linear computational complexity. Extensive experiments on COCO object detection and Cityscapes semantic segmentation demonstrate the effectiveness of our method. On the COCO dataset, EfficientViT achieves 42.6 AP with 4.4G MACs, surpassing EfficientDet-D1 by 2.4 AP while having 27.9% fewer MACs. On Cityscapes, EfficientViT reaches 78.7 mIoU with 19.1G MACs, outperforming SegFormer by 2.5 mIoU while requiring less than 1/3 the computational cost. On Qualcomm Snapdragon 855 CPU, EfficientViT is 3x faster than EfficientNet while achieving higher ImageNet accuracy.
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
May 26, 2022
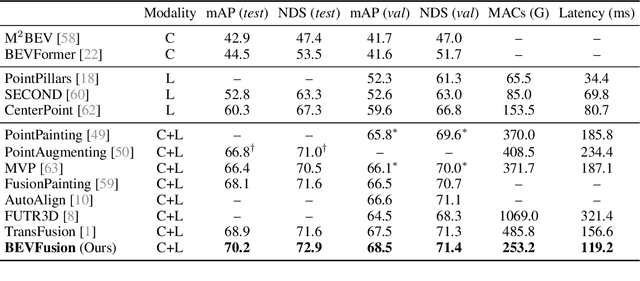
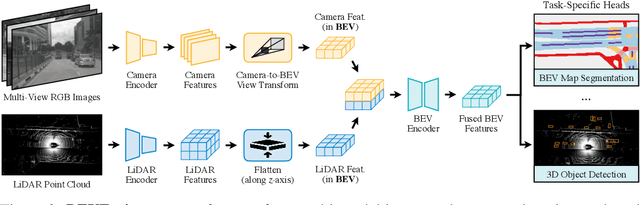
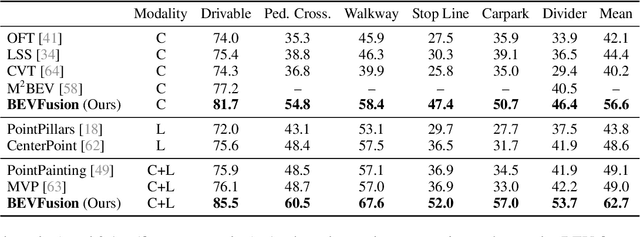
Multi-sensor fusion is essential for an accurate and reliable autonomous driving system. Recent approaches are based on point-level fusion: augmenting the LiDAR point cloud with camera features. However, the camera-to-LiDAR projection throws away the semantic density of camera features, hindering the effectiveness of such methods, especially for semantic-oriented tasks (such as 3D scene segmentation). In this paper, we break this deeply-rooted convention with BEVFusion, an efficient and generic multi-task multi-sensor fusion framework. It unifies multi-modal features in the shared bird's-eye view (BEV) representation space, which nicely preserves both geometric and semantic information. To achieve this, we diagnose and lift key efficiency bottlenecks in the view transformation with optimized BEV pooling, reducing latency by more than 40x. BEVFusion is fundamentally task-agnostic and seamlessly supports different 3D perception tasks with almost no architectural changes. It establishes the new state of the art on nuScenes, achieving 1.3% higher mAP and NDS on 3D object detection and 13.6% higher mIoU on BEV map segmentation, with 1.9x lower computation cost.
Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation
May 03, 2022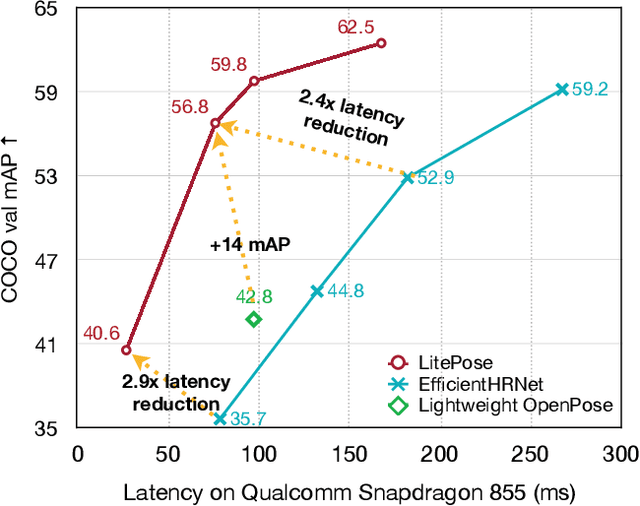
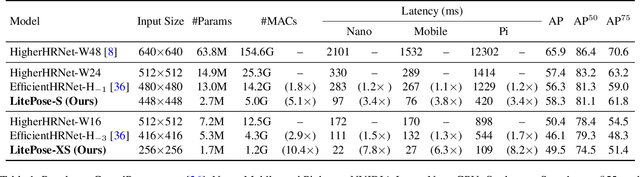
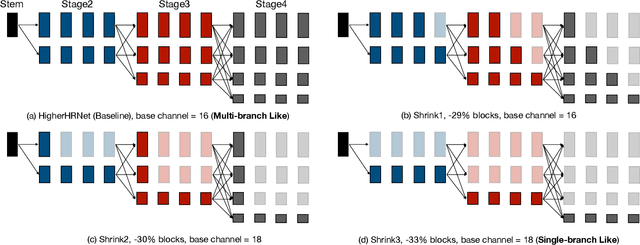
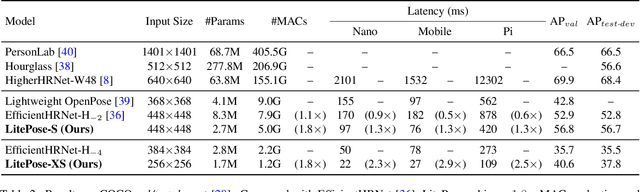
Pose estimation plays a critical role in human-centered vision applications. However, it is difficult to deploy state-of-the-art HRNet-based pose estimation models on resource-constrained edge devices due to the high computational cost (more than 150 GMACs per frame). In this paper, we study efficient architecture design for real-time multi-person pose estimation on edge. We reveal that HRNet's high-resolution branches are redundant for models at the low-computation region via our gradual shrinking experiments. Removing them improves both efficiency and performance. Inspired by this finding, we design LitePose, an efficient single-branch architecture for pose estimation, and introduce two simple approaches to enhance the capacity of LitePose, including Fusion Deconv Head and Large Kernel Convs. Fusion Deconv Head removes the redundancy in high-resolution branches, allowing scale-aware feature fusion with low overhead. Large Kernel Convs significantly improve the model's capacity and receptive field while maintaining a low computational cost. With only 25% computation increment, 7x7 kernels achieve +14.0 mAP better than 3x3 kernels on the CrowdPose dataset. On mobile platforms, LitePose reduces the latency by up to 5.0x without sacrificing performance, compared with prior state-of-the-art efficient pose estimation models, pushing the frontier of real-time multi-person pose estimation on edge. Our code and pre-trained models are released at https://github.com/mit-han-lab/litepose.
* 11 pages
PVNAS: 3D Neural Architecture Search with Point-Voxel Convolution
Apr 26, 2022
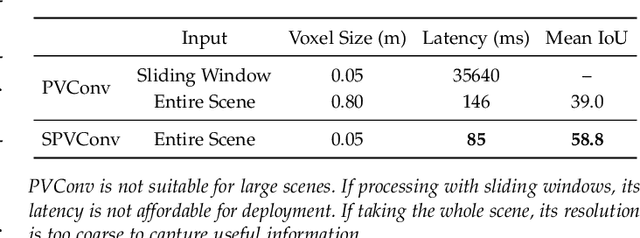
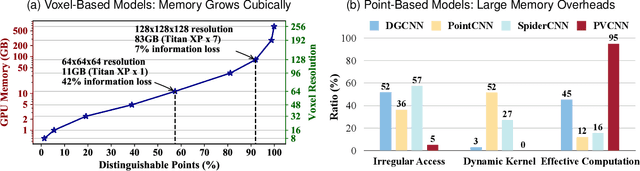
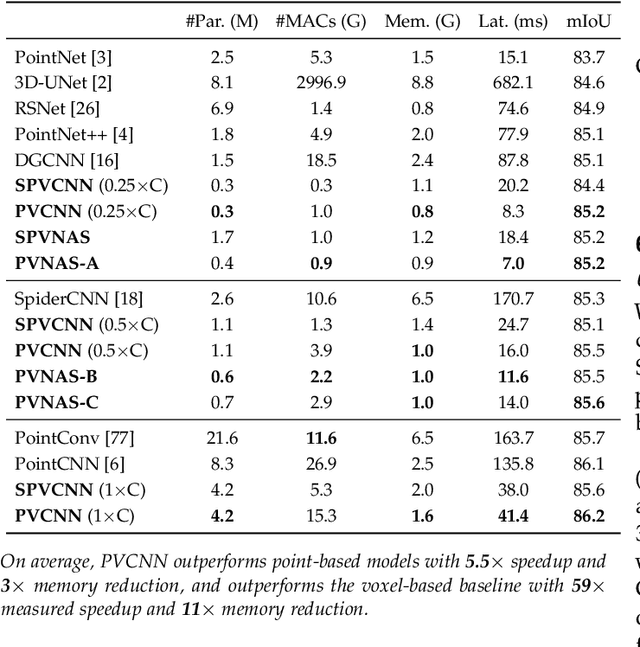
3D neural networks are widely used in real-world applications (e.g., AR/VR headsets, self-driving cars). They are required to be fast and accurate; however, limited hardware resources on edge devices make these requirements rather challenging. Previous work processes 3D data using either voxel-based or point-based neural networks, but both types of 3D models are not hardware-efficient due to the large memory footprint and random memory access. In this paper, we study 3D deep learning from the efficiency perspective. We first systematically analyze the bottlenecks of previous 3D methods. We then combine the best from point-based and voxel-based models together and propose a novel hardware-efficient 3D primitive, Point-Voxel Convolution (PVConv). We further enhance this primitive with the sparse convolution to make it more effective in processing large (outdoor) scenes. Based on our designed 3D primitive, we introduce 3D Neural Architecture Search (3D-NAS) to explore the best 3D network architecture given a resource constraint. We evaluate our proposed method on six representative benchmark datasets, achieving state-of-the-art performance with 1.8-23.7x measured speedup. Furthermore, our method has been deployed to the autonomous racing vehicle of MIT Driverless, achieving larger detection range, higher accuracy and lower latency.