 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025



Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
Re-evaluating Open-ended Evaluation of Large Language Models
Feb 27, 2025

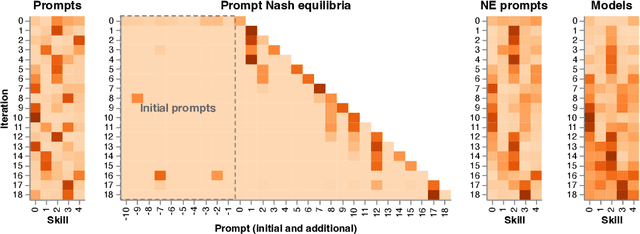

Evaluation has traditionally focused on ranking candidates for a specific skill. Modern generalist models, such as Large Language Models (LLMs), decidedly outpace this paradigm. Open-ended evaluation systems, where candidate models are compared on user-submitted prompts, have emerged as a popular solution. Despite their many advantages, we show that the current Elo-based rating systems can be susceptible to and even reinforce biases in data, intentional or accidental, due to their sensitivity to redundancies. To address this issue, we propose evaluation as a 3-player game, and introduce novel game-theoretic solution concepts to ensure robustness to redundancy. We show that our method leads to intuitive ratings and provide insights into the competitive landscape of LLM development.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
Deviation Ratings: A General, Clone-Invariant Rating Method
Feb 17, 2025Many real-world multi-agent or multi-task evaluation scenarios can be naturally modelled as normal-form games due to inherent strategic (adversarial, cooperative, and mixed motive) interactions. These strategic interactions may be agentic (e.g. players trying to win), fundamental (e.g. cost vs quality), or complementary (e.g. niche finding and specialization). In such a formulation, it is the strategies (actions, policies, agents, models, tasks, prompts, etc.) that are rated. However, the rating problem is complicated by redundancy and complexity of N-player strategic interactions. Repeated or similar strategies can distort ratings for those that counter or complement them. Previous work proposed ``clone invariant'' ratings to handle such redundancies, but this was limited to two-player zero-sum (i.e. strictly competitive) interactions. This work introduces the first N-player general-sum clone invariant rating, called deviation ratings, based on coarse correlated equilibria. The rating is explored on several domains including LLMs evaluation.
Dynamic Frequency-Adaptive Knowledge Distillation for Speech Enhancement
Feb 07, 2025Deep learning-based speech enhancement (SE) models have recently outperformed traditional techniques, yet their deployment on resource-constrained devices remains challenging due to high computational and memory demands. This paper introduces a novel dynamic frequency-adaptive knowledge distillation (DFKD) approach to effectively compress SE models. Our method dynamically assesses the model's output, distinguishing between high and low-frequency components, and adapts the learning objectives to meet the unique requirements of different frequency bands, capitalizing on the SE task's inherent characteristics. To evaluate the DFKD's efficacy, we conducted experiments on three state-of-the-art models: DCCRN, ConTasNet, and DPTNet. The results demonstrate that our method not only significantly enhances the performance of the compressed model (student model) but also surpasses other logit-based knowledge distillation methods specifically for SE tasks.
Unsupervised Event Outlier Detection in Continuous Time
Nov 25, 2024



Event sequence data record the occurrences of events in continuous time. Event sequence forecasting based on temporal point processes (TPPs) has been extensively studied, but outlier or anomaly detection, especially without any supervision from humans, is still underexplored. In this work, we develop, to the best our knowledge, the first unsupervised outlier detection approach to detecting abnormal events. Our novel unsupervised outlier detection framework is based on ideas from generative adversarial networks (GANs) and reinforcement learning (RL). We train a 'generator' that corrects outliers in the data with a 'discriminator' that learns to discriminate the corrected data from the real data, which may contain outliers. A key insight is that if the generator made a mistake in the correction, it would generate anomalies that are different from the anomalies in the real data, so it serves as data augmentation for the discriminator learning. Different from typical GAN-based outlier detection approaches, our method employs the generator to detect outliers in an online manner. The experimental results show that our method can detect event outliers more accurately than the state-of-the-art approaches.
Convex Markov Games: A Framework for Fairness, Imitation, and Creativity in Multi-Agent Learning
Oct 22, 2024Expert imitation, behavioral diversity, and fairness preferences give rise to preferences in sequential decision making domains that do not decompose additively across time. We introduce the class of convex Markov games that allow general convex preferences over occupancy measures. Despite infinite time horizon and strictly higher generality than Markov games, pure strategy Nash equilibria exist under strict convexity. Furthermore, equilibria can be approximated efficiently by performing gradient descent on an upper bound of exploitability. Our experiments imitate human choices in ultimatum games, reveal novel solutions to the repeated prisoner's dilemma, and find fair solutions in a repeated asymmetric coordination game. In the prisoner's dilemma, our algorithm finds a policy profile that deviates from observed human play only slightly, yet achieves higher per-player utility while also being three orders of magnitude less exploitable.
Screen Them All: High-Throughput Pan-Cancer Genetic and Phenotypic Biomarker Screening from H&E Whole Slide Images
Aug 20, 2024Many molecular alterations serve as clinically prognostic or therapy-predictive biomarkers, typically detected using single or multi-gene molecular assays. However, these assays are expensive, tissue destructive and often take weeks to complete. Using AI on routine H&E WSIs offers a fast and economical approach to screen for multiple molecular biomarkers. We present a high-throughput AI-based system leveraging Virchow2, a foundation model pre-trained on 3 million slides, to interrogate genomic features previously determined by an next-generation sequencing (NGS) assay, using 47,960 scanned hematoxylin and eosin (H&E) whole slide images (WSIs) from 38,984 cancer patients. Unlike traditional methods that train individual models for each biomarker or cancer type, our system employs a unified model to simultaneously predict a wide range of clinically relevant molecular biomarkers across cancer types. By training the network to replicate the MSK-IMPACT targeted biomarker panel of 505 genes, it identified 80 high performing biomarkers with a mean AU-ROC of 0.89 in 15 most common cancer types. In addition, 40 biomarkers demonstrated strong associations with specific cancer histologic subtypes. Furthermore, 58 biomarkers were associated with targets frequently assayed clinically for therapy selection and response prediction. The model can also predict the activity of five canonical signaling pathways, identify defects in DNA repair mechanisms, and predict genomic instability measured by tumor mutation burden, microsatellite instability (MSI), and chromosomal instability (CIN). The proposed model can offer potential to guide therapy selection, improve treatment efficacy, accelerate patient screening for clinical trials and provoke the interrogation of new therapeutic targets.
Virchow2: Scaling Self-Supervised Mixed Magnification Models in Pathology
Aug 14, 2024Foundation models are rapidly being developed for computational pathology applications. However, it remains an open question which factors are most important for downstream performance with data scale and diversity, model size, and training algorithm all playing a role. In this work, we propose algorithmic modifications, tailored for pathology, and we present the result of scaling both data and model size, surpassing previous studies in both dimensions. We introduce two new models: Virchow2, a 632 million parameter vision transformer, and Virchow2G, a 1.9 billion parameter vision transformer, each trained with 3.1 million histopathology whole slide images, with diverse tissues, originating institutions, and stains. We achieve state of the art performance on 12 tile-level tasks, as compared to the top performing competing models. Our results suggest that data diversity and domain-specific methods can outperform models that only scale in the number of parameters, but, on average, performance benefits from the combination of domain-specific methods, data scale, and model scale.
Virchow 2: Scaling Self-Supervised Mixed Magnification Models in Pathology
Aug 01, 2024Foundation models are rapidly being developed for computational pathology applications. However, it remains an open question which factors are most important for downstream performance with data scale and diversity, model size, and training algorithm all playing a role. In this work, we present the result of scaling both data and model size, surpassing previous studies in both dimensions, and introduce two new models: Virchow 2, a 632M parameter vision transformer, and Virchow 2G, a 1.85B parameter vision transformer, each trained with 3.1M histopathology whole slide images. To support this scale, we propose domain-inspired adaptations to the DINOv2 training algorithm, which is quickly becoming the default method in self-supervised learning for computational pathology. We achieve state of the art performance on twelve tile-level tasks, as compared to the top performing competing models. Our results suggest that data diversity and domain-specific training can outperform models that only scale in the number of parameters, but, on average, performance benefits from domain-tailoring, data scale, and model scale.