 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming the Domain Gap in Contrastive Learning of Neural Action Representations
Nov 29, 2021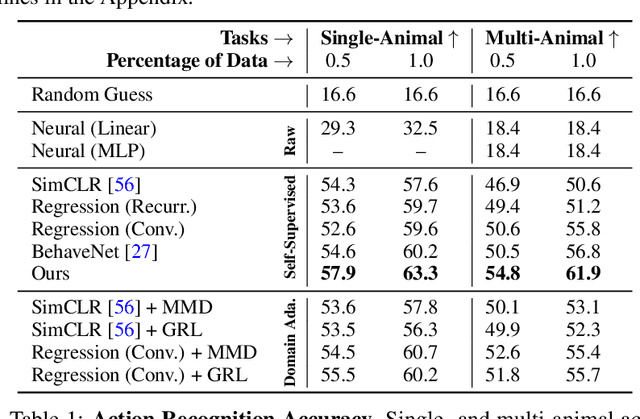
A fundamental goal in neuroscience is to understand the relationship between neural activity and behavior. For example, the ability to extract behavioral intentions from neural data, or neural decoding, is critical for developing effective brain machine interfaces. Although simple linear models have been applied to this challenge, they cannot identify important non-linear relationships. Thus, a self-supervised means of identifying non-linear relationships between neural dynamics and behavior, in order to compute neural representations, remains an important open problem. To address this challenge, we generated a new multimodal dataset consisting of the spontaneous behaviors generated by fruit flies, Drosophila melanogaster -- a popular model organism in neuroscience research. The dataset includes 3D markerless motion capture data from six camera views of the animal generating spontaneous actions, as well as synchronously acquired two-photon microscope images capturing the activity of descending neuron populations that are thought to drive actions. Standard contrastive learning and unsupervised domain adaptation techniques struggle to learn neural action representations (embeddings computed from the neural data describing action labels) due to large inter-animal differences in both neural and behavioral modalities. To overcome this deficiency, we developed simple yet effective augmentations that close the inter-animal domain gap, allowing us to extract behaviorally relevant, yet domain agnostic, information from neural data. This multimodal dataset and our new set of augmentations promise to accelerate the application of self-supervised learning methods in neuroscience.
SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation
Apr 30, 2021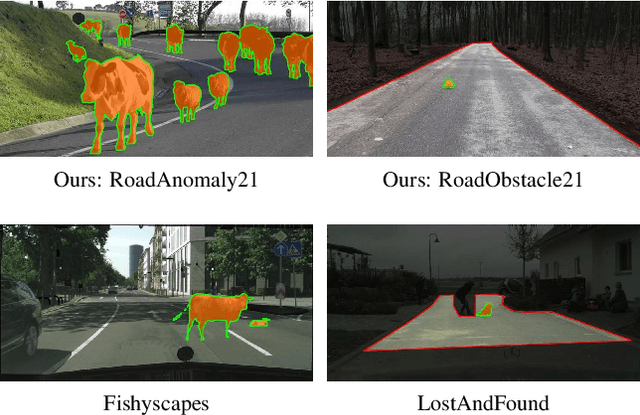
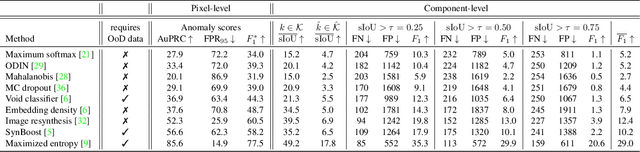

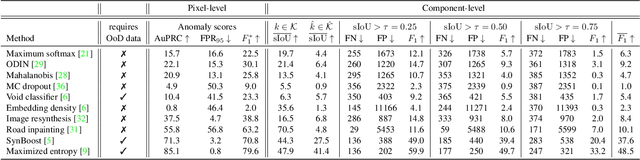
State-of-the-art semantic or instance segmentation deep neural networks (DNNs) are usually trained on a closed set of semantic classes. As such, they are ill-equipped to handle previously-unseen objects. However, detecting and localizing such objects is crucial for safety-critical applications such as perception for automated driving, especially if they appear on the road ahead. While some methods have tackled the tasks of anomalous or out-of-distribution object segmentation, progress remains slow, in large part due to the lack of solid benchmarks; existing datasets either consist of synthetic data, or suffer from label inconsistencies. In this paper, we bridge this gap by introducing the "SegmentMeIfYouCan" benchmark. Our benchmark addresses two tasks: Anomalous object segmentation, which considers any previously-unseen object category; and road obstacle segmentation, which focuses on any object on the road, may it be known or unknown. We provide two corresponding datasets together with a test suite performing an in-depth method analysis, considering both established pixel-wise performance metrics and recent component-wise ones, which are insensitive to object sizes. We empirically evaluate multiple state-of-the-art baseline methods, including several specifically designed for anomaly / obstacle segmentation, on our datasets as well as on public ones, using our benchmark suite. The anomaly and obstacle segmentation results show that our datasets contribute to the diversity and challengingness of both dataset landscapes.
Detecting Road Obstacles by Erasing Them
Dec 25, 2020
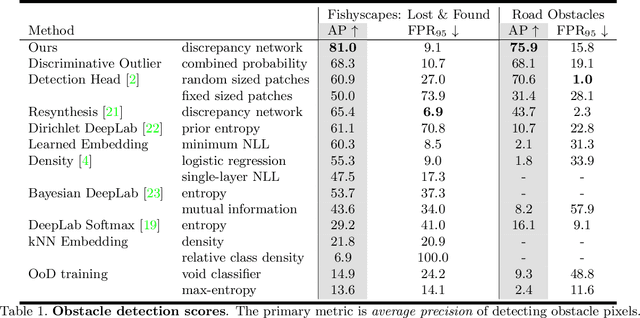

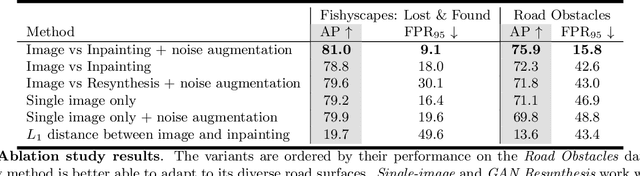
Vehicles can encounter a myriad of obstacles on the road, and it is not feasible to record them all beforehand to train a detector. Our method selects image patches and inpaints them with the surrounding road texture, which tends to remove obstacles from those patches. It them uses a network trained to recognize discrepancies between the original patch and the inpainted one, which signals an erased obstacle. We also contribute a new dataset for monocular road obstacle detection, and show that our approach outperforms the state-of-the-art methods on both our new dataset and the standard Fishyscapes Lost & Found benchmark.
Unsupervised Learning on Monocular Videos for 3D Human Pose Estimation
Dec 02, 2020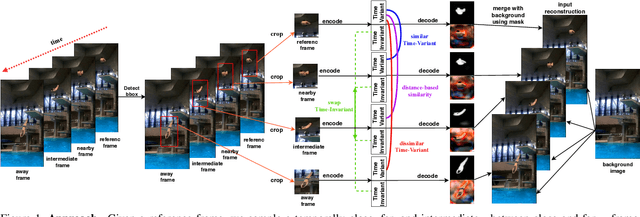
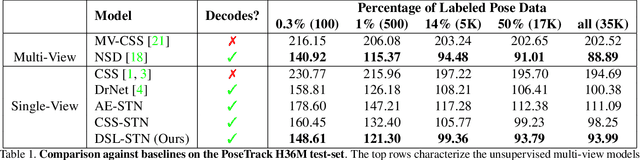
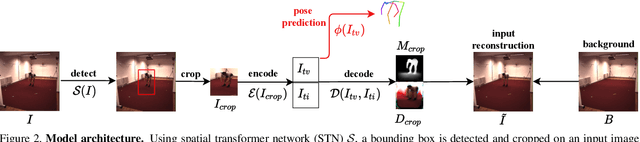
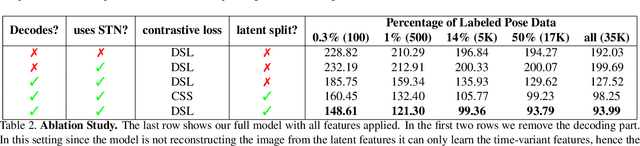
In this paper, we introduce an unsupervised feature extraction method that exploits contrastive self-supervised (CSS) learning to extract rich latent vectors from single-view videos. Instead of simply treating the latent features of nearby frames as positive pairs and those of temporally-distant ones as negative pairs as in other CSS approaches, we explicitly separate each latent vector into a time-variant component and a time-invariant one. We then show that applying CSS only to the time-variant features, while also reconstructing the input and encouraging a gradual transition between nearby and away features yields a rich latent space, well-suited for human pose estimation. Our approach outperforms other unsupervised single-view methods and match the performance of multi-view techniques.
Lightweight Multi-View 3D Pose Estimation through Camera-Disentangled Representation
Apr 05, 2020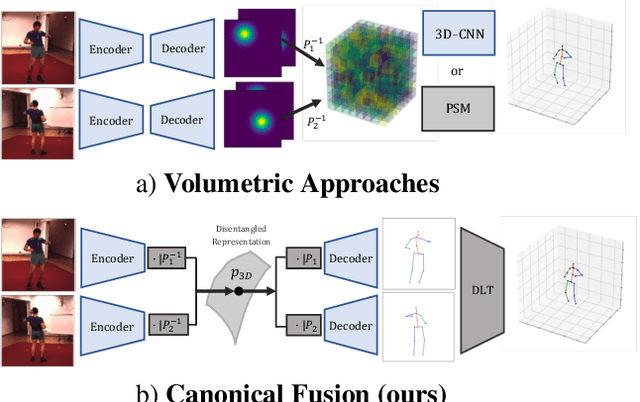
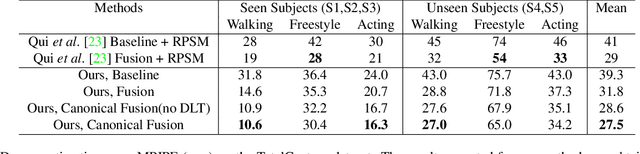
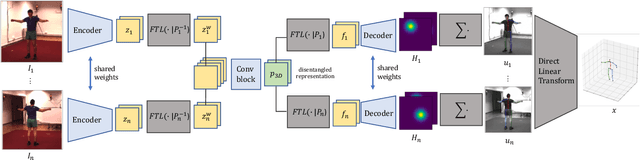
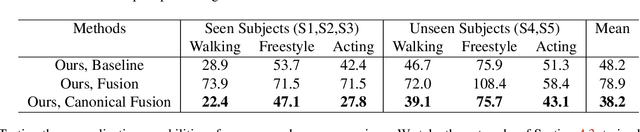
We present a lightweight solution to recover 3D pose from multi-view images captured with spatially calibrated cameras. Building upon recent advances in interpretable representation learning, we exploit 3D geometry to fuse input images into a unified latent representation of pose, which is disentangled from camera view-points. This allows us to reason effectively about 3D pose across different views without using compute-intensive volumetric grids. Our architecture then conditions the learned representation on camera projection operators to produce accurate per-view 2d detections, that can be simply lifted to 3D via a differentiable Direct Linear Transform (DLT) layer. In order to do it efficiently, we propose a novel implementation of DLT that is orders of magnitude faster on GPU architectures than standard SVD-based triangulation methods. We evaluate our approach on two large-scale human pose datasets (H36M and Total Capture): our method outperforms or performs comparably to the state-of-the-art volumetric methods, while, unlike them, yielding real-time performance.
U-Net Fixed-Point Quantization for Medical Image Segmentation
Sep 09, 2019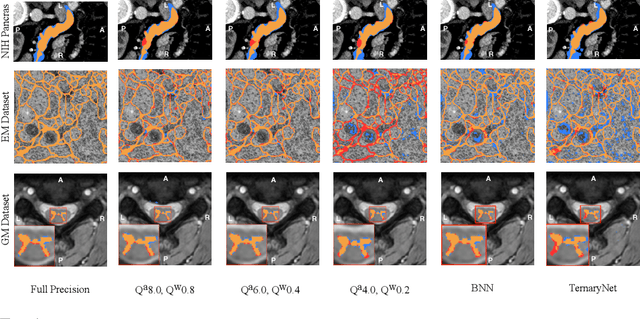
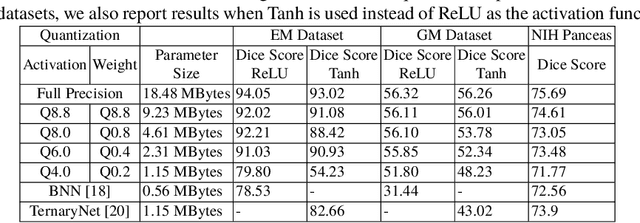
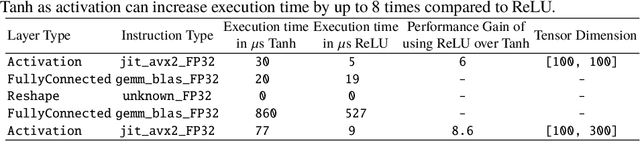
Model quantization is leveraged to reduce the memory consumption and the computation time of deep neural networks. This is achieved by representing weights and activations with a lower bit resolution when compared to their high precision floating point counterparts. The suitable level of quantization is directly related to the model performance. Lowering the quantization precision (e.g. 2 bits), reduces the amount of memory required to store model parameters and the amount of logic required to implement computational blocks, which contributes to reducing the power consumption of the entire system. These benefits typically come at the cost of reduced accuracy. The main challenge is to quantize a network as much as possible, while maintaining the performance accuracy. In this work, we present a quantization method for the U-Net architecture, a popular model in medical image segmentation. We then apply our quantization algorithm to three datasets: (1) the Spinal Cord Gray Matter Segmentation (GM), (2) the ISBI challenge for segmentation of neuronal structures in Electron Microscopic (EM), and (3) the public National Institute of Health (NIH) dataset for pancreas segmentation in abdominal CT scans. The reported results demonstrate that with only 4 bits for weights and 6 bits for activations, we obtain 8 fold reduction in memory requirements while loosing only 2.21%, 0.57% and 2.09% dice overlap score for EM, GM and NIH datasets respectively. Our fixed point quantization provides a flexible trade off between accuracy and memory requirement which is not provided by previous quantization methods for U-Net such as TernaryNet.
Adversarial Mixup Resynthesizers
Apr 04, 2019
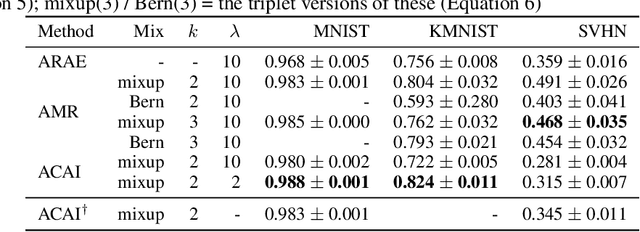
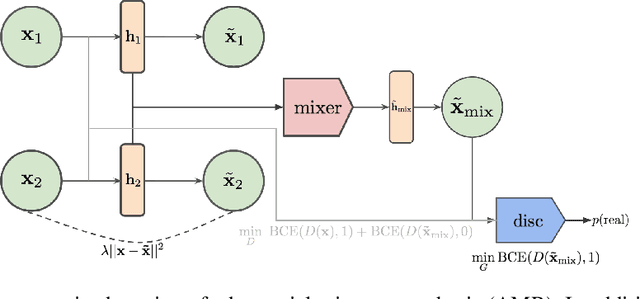
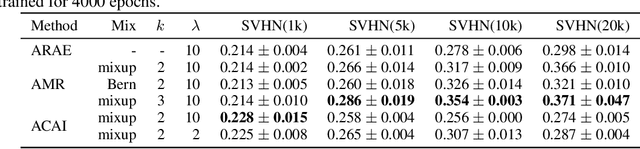
In this paper, we explore new approaches to combining information encoded within the learned representations of autoencoders. We explore models that are capable of combining the attributes of multiple inputs such that a resynthesised output is trained to fool an adversarial discriminator for real versus synthesised data. Furthermore, we explore the use of such an architecture in the context of semi-supervised learning, where we learn a mixing function whose objective is to produce interpolations of hidden states, or masked combinations of latent representations that are consistent with a conditioned class label. We show quantitative and qualitative evidence that such a formulation is an interesting avenue of research.
Improving Landmark Localization with Semi-Supervised Learning
Oct 28, 2018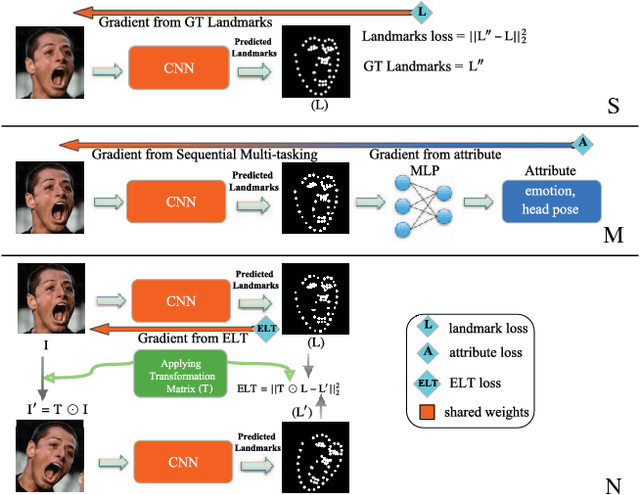
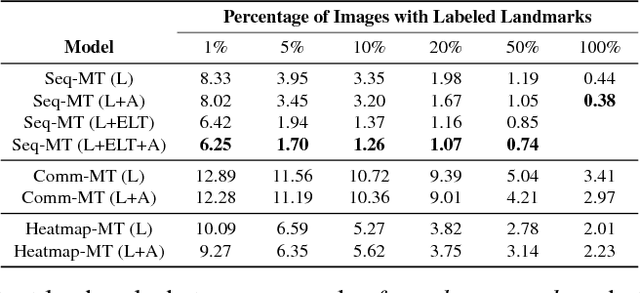
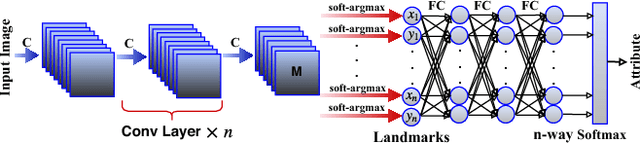

We present two techniques to improve landmark localization in images from partially annotated datasets. Our primary goal is to leverage the common situation where precise landmark locations are only provided for a small data subset, but where class labels for classification or regression tasks related to the landmarks are more abundantly available. First, we propose the framework of sequential multitasking and explore it here through an architecture for landmark localization where training with class labels acts as an auxiliary signal to guide the landmark localization on unlabeled data. A key aspect of our approach is that errors can be backpropagated through a complete landmark localization model. Second, we propose and explore an unsupervised learning technique for landmark localization based on having a model predict equivariant landmarks with respect to transformations applied to the image. We show that these techniques, improve landmark prediction considerably and can learn effective detectors even when only a small fraction of the dataset has landmark labels. We present results on two toy datasets and four real datasets, with hands and faces, and report new state-of-the-art on two datasets in the wild, e.g. with only 5\% of labeled images we outperform previous state-of-the-art trained on the AFLW dataset.
Distribution Matching Losses Can Hallucinate Features in Medical Image Translation
Oct 03, 2018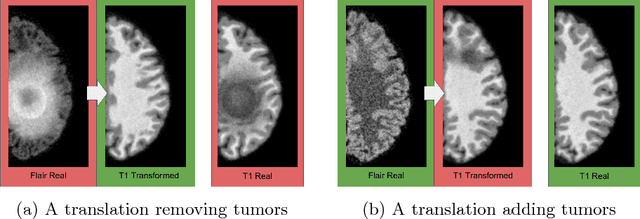
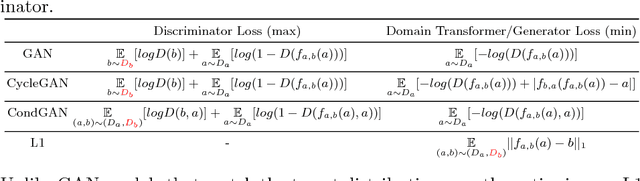
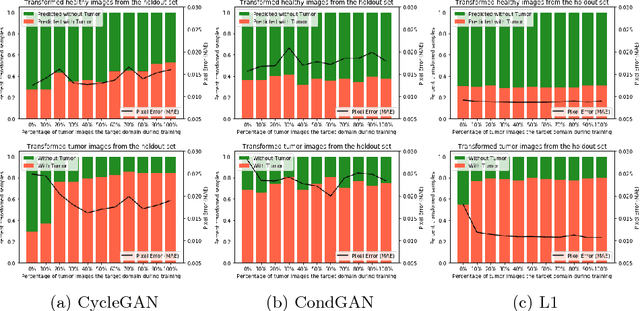

This paper discusses how distribution matching losses, such as those used in CycleGAN, when used to synthesize medical images can lead to mis-diagnosis of medical conditions. It seems appealing to use these new image synthesis methods for translating images from a source to a target domain because they can produce high quality images and some even do not require paired data. However, the basis of how these image translation models work is through matching the translation output to the distribution of the target domain. This can cause an issue when the data provided in the target domain has an over or under representation of some classes (e.g. healthy or sick). When the output of an algorithm is a transformed image there are uncertainties whether all known and unknown class labels have been preserved or changed. Therefore, we recommend that these translated images should not be used for direct interpretation (e.g. by doctors) because they may lead to misdiagnosis of patients based on hallucinated image features by an algorithm that matches a distribution. However there are many recent papers that seem as though this is the goal.
* Published at Medical Image Computing & Computer Assisted Intervention (MICCAI 2018). An abstract is published at the Medical Imaging with Deep Learning Conference (MIDL 2018) as "How to Cure Cancer (in images) with Unpaired Image Translation"
Unsupervised Depth Estimation, 3D Face Rotation and Replacement
Oct 01, 2018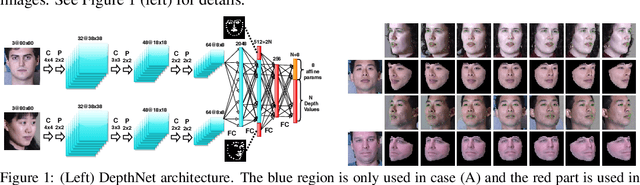

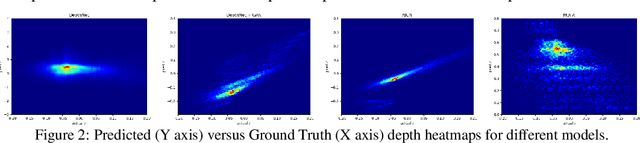
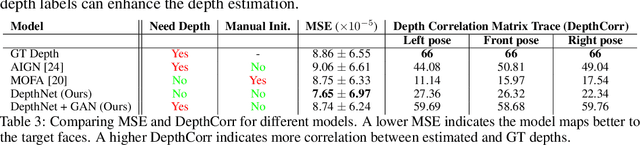
We present an unsupervised approach for learning to estimate three dimensional (3D) facial structure from a single image while also predicting 3D viewpoint transformations that match a desired pose and facial geometry. We achieve this by inferring the depth of facial keypoints of an input image in an unsupervised manner, without using any form of ground-truth depth information. We show how it is possible to use these depths as intermediate computations within a new backpropable loss to predict the parameters of a 3D affine transformation matrix that maps inferred 3D keypoints of an input face to the corresponding 2D keypoints on a desired target facial geometry or pose. Our resulting approach can therefore be used to infer plausible 3D transformations from one face pose to another, allowing faces to be frontalized, transformed into 3D models or even warped to another pose and facial geometry. Lastly, we identify certain shortcomings with our formulation, and explore adversarial image translation techniques as a post-processing step to re-synthesize complete head shots for faces re-targeted to different poses or identities.
* Depth Estimation, Face Rotation, Face Swap