 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Parametric Pose Prior
Dec 08, 2021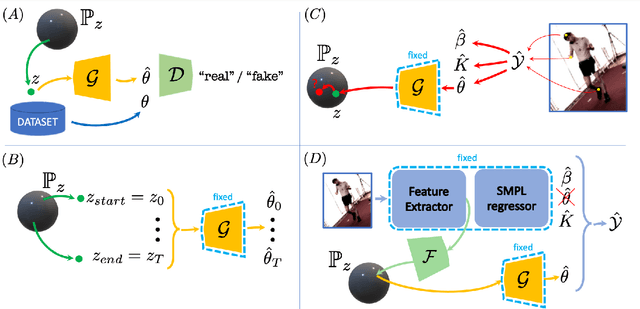
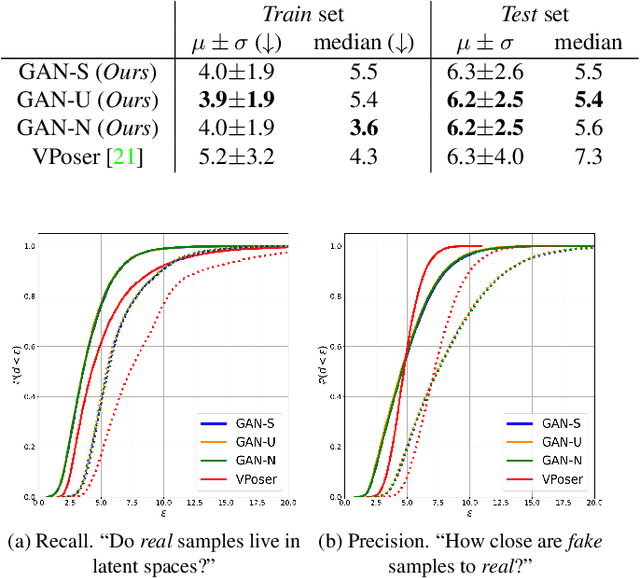
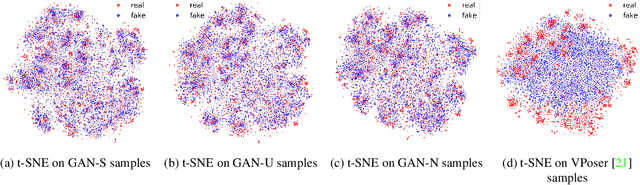
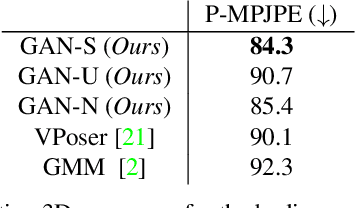
The Skinned Multi-Person Linear (SMPL) model can represent a human body by mapping pose and shape parameters to body meshes. This has been shown to facilitate inferring 3D human pose and shape from images via different learning models. However, not all pose and shape parameter values yield physically-plausible or even realistic body meshes. In other words, SMPL is under-constrained and may thus lead to invalid results when used to reconstruct humans from images, either by directly optimizing its parameters, or by learning a mapping from the image to these parameters. In this paper, we therefore learn a prior that restricts the SMPL parameters to values that produce realistic poses via adversarial training. We show that our learned prior covers the diversity of the real-data distribution, facilitates optimization for 3D reconstruction from 2D keypoints, and yields better pose estimates when used for regression from images. We found that the prior based on spherical distribution gets the best results. Furthermore, in all these tasks, it outperforms the state-of-the-art VAE-based approach to constraining the SMPL parameters.
Unsupervised Learning on Monocular Videos for 3D Human Pose Estimation
Dec 02, 2020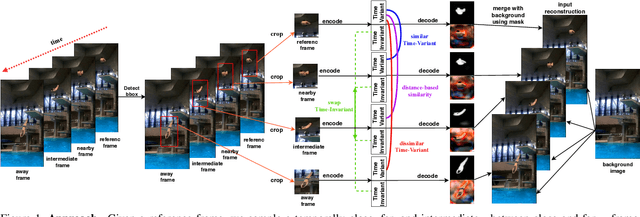
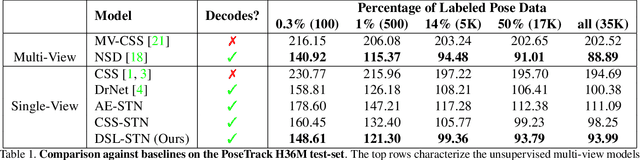
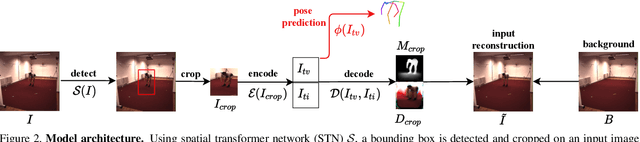
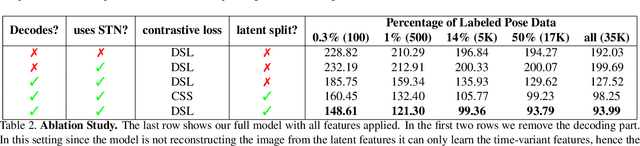
In this paper, we introduce an unsupervised feature extraction method that exploits contrastive self-supervised (CSS) learning to extract rich latent vectors from single-view videos. Instead of simply treating the latent features of nearby frames as positive pairs and those of temporally-distant ones as negative pairs as in other CSS approaches, we explicitly separate each latent vector into a time-variant component and a time-invariant one. We then show that applying CSS only to the time-variant features, while also reconstructing the input and encouraging a gradual transition between nearby and away features yields a rich latent space, well-suited for human pose estimation. Our approach outperforms other unsupervised single-view methods and match the performance of multi-view techniques.
Self-supervised Segmentation via Background Inpainting
Nov 11, 2020
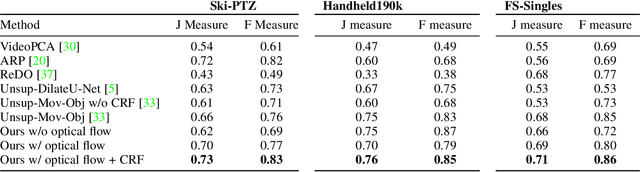
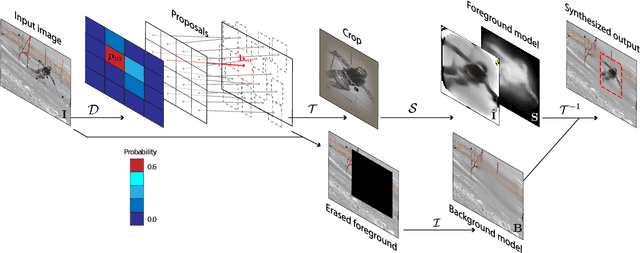

While supervised object detection and segmentation methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this when annotating data is prohibitively expensive, we introduce a self-supervised detection and segmentation approach that can work with single images captured by a potentially moving camera. At the heart of our approach lies the observation that object segmentation and background reconstruction are linked tasks, and that, for structured scenes, background regions can be re-synthesized from their surroundings, whereas regions depicting the moving object cannot. We encode this intuition into a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of the proposals, we develop a Monte Carlo-based training strategy that allows the algorithm to explore the large space of object proposals. We apply our method to human detection and segmentation in images that visually depart from those of standard benchmarks and outperform existing self-supervised methods.
GarNet++: Improving Fast and Accurate Static3D Cloth Draping by Curvature Loss
Jul 20, 2020
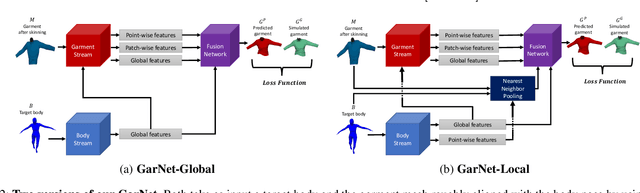
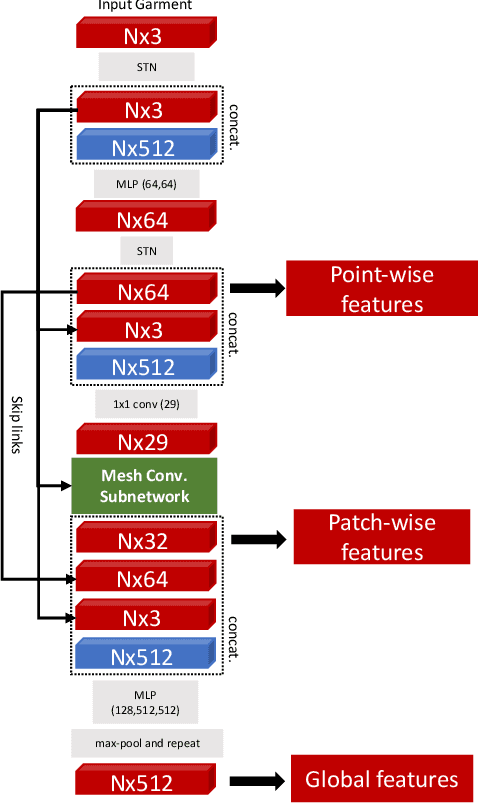
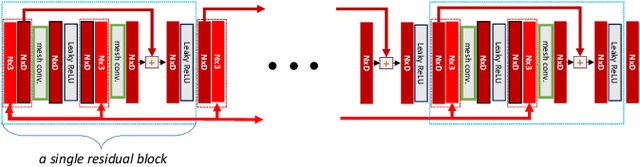
In this paper, we tackle the problem of static 3D cloth draping on virtual human bodies. We introduce a two-stream deep network model that produces a visually plausible draping of a template cloth on virtual 3D bodies by extracting features from both the body and garment shapes. Our network learns to mimic a Physics-Based Simulation (PBS) method while requiring two orders of magnitude less computation time. To train the network, we introduce loss terms inspired by PBS to produce plausible results and make the model collision-aware. To increase the details of the draped garment, we introduce two loss functions that penalize the difference between the curvature of the predicted cloth and PBS. Particularly, we study the impact of mean curvature normal and a novel detail-preserving loss both qualitatively and quantitatively. Our new curvature loss computes the local covariance matrices of the 3D points, and compares the Rayleigh quotients of the prediction and PBS. This leads to more details while performing favorably or comparably against the loss that considers mean curvature normal vectors in the 3D triangulated meshes. We validate our framework on four garment types for various body shapes and poses. Finally, we achieve superior performance against a recently proposed data-driven method.
Self-supervised Training of Proposal-based Segmentation via Background Prediction
Jul 18, 2019

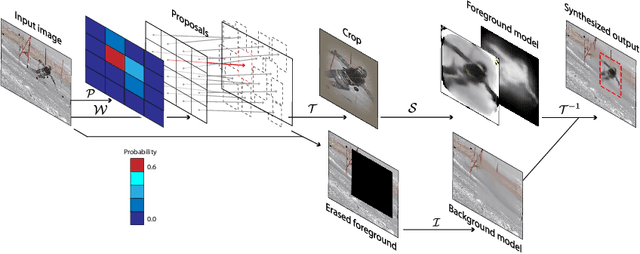
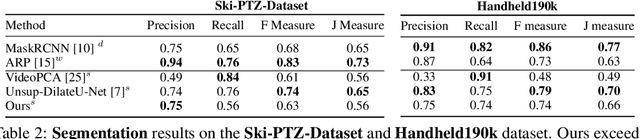
While supervised object detection methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this in scenarios where annotating data is prohibitively expensive, we introduce a self-supervised approach to object detection and segmentation, able to work with monocular images captured with a moving camera. At the heart of our approach lies the observation that segmentation and background reconstruction are linked tasks, and the idea that, because we observe a structured scene, background regions can be re-synthesized from their surroundings, whereas regions depicting the object cannot. We therefore encode this intuition as a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of object proposals, we develop a Monte Carlo-based training strategy that allows us to explore the large space of object proposals. Our experiments demonstrate that our approach yields accurate detections and segmentations in images that visually depart from those of standard benchmarks, outperforming existing self-supervised methods and approaching weakly supervised ones that exploit large annotated datasets.
Neural Scene Decomposition for Multi-Person Motion Capture
Mar 13, 2019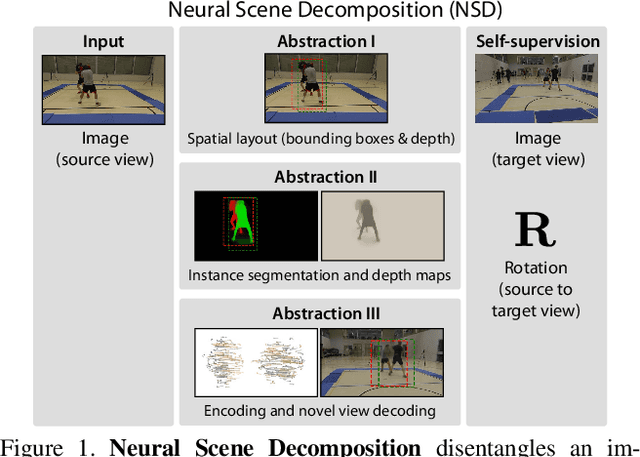
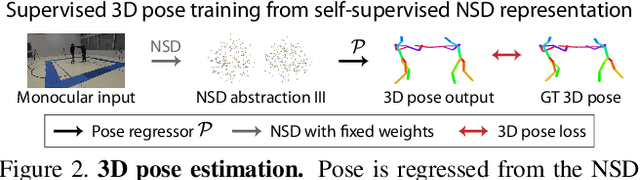
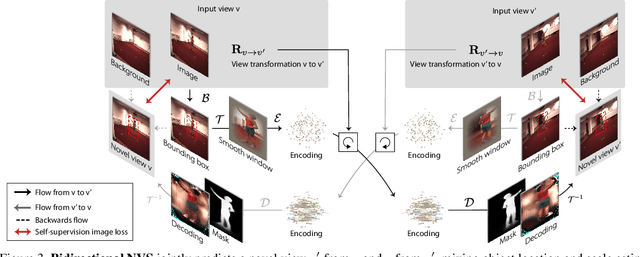

Learning general image representations has proven key to the success of many computer vision tasks. For example, many approaches to image understanding problems rely on deep networks that were initially trained on ImageNet, mostly because the learned features are a valuable starting point to learn from limited labeled data. However, when it comes to 3D motion capture of multiple people, these features are only of limited use. In this paper, we therefore propose an approach to learning features that are useful for this purpose. To this end, we introduce a self-supervised approach to learning what we call a neural scene decomposition (NSD) that can be exploited for 3D pose estimation. NSD comprises three layers of abstraction to represent human subjects: spatial layout in terms of bounding-boxes and relative depth; a 2D shape representation in terms of an instance segmentation mask; and subject-specific appearance and 3D pose information. By exploiting self-supervision coming from multiview data, our NSD model can be trained end-to-end without any 2D or 3D supervision. In contrast to previous approaches, it works for multiple persons and full-frame images. Because it encodes 3D geometry, NSD can then be effectively leveraged to train a 3D pose estimation network from small amounts of annotated data.
GarNet: A Two-stream Network for Fast and Accurate 3D Cloth Draping
Nov 27, 2018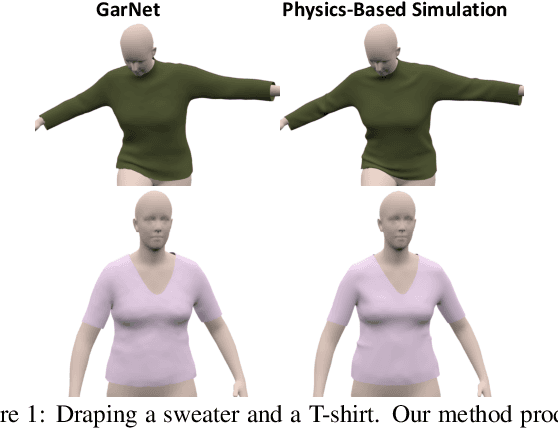
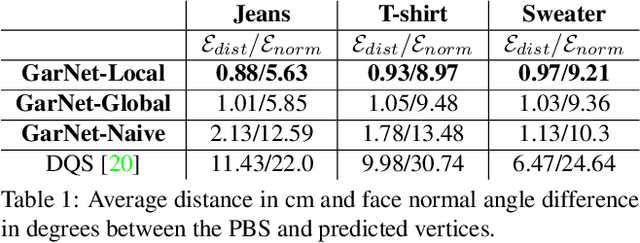
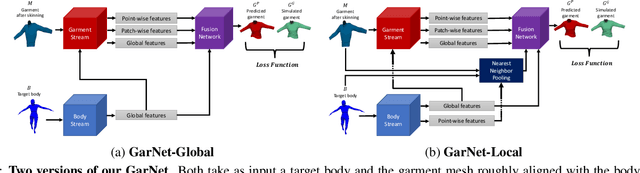
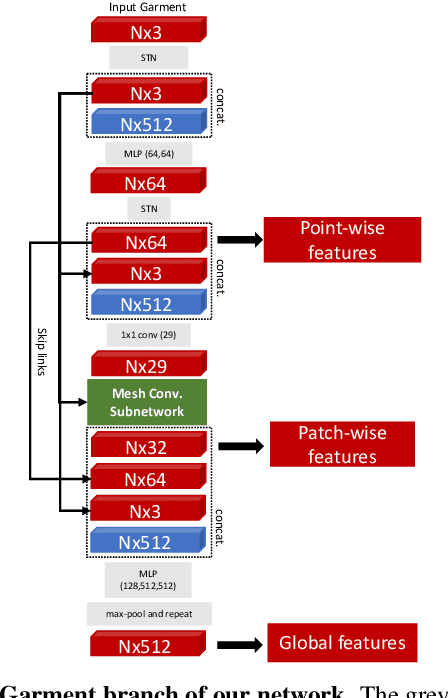
While Physics-Based Simulation (PBS) can highly accurately drape a 3D garment model on a 3D body, it remains too costly for real-time applications, such as virtual try-on. By contrast, inference in a deep network, that is, a single forward pass, is typically quite fast. In this paper, we leverage this property and introduce a novel architecture to fit a 3D garment template to a 3D body model. Specifically, we build upon the recent progress in 3D point-cloud processing with deep networks to extract garment features at varying levels of detail, including point-wise, patch-wise and global features. We then fuse these features with those extracted in parallel from the 3D body, so as to model the cloth-body interactions. The resulting two-stream architecture is trained with a loss function inspired by physics-based modeling, and delivers realistic garment shapes whose 3D points are, on average, less than 1.5cm away from those of a PBS method, while running 40 times faster.
Learning Monocular 3D Human Pose Estimation from Multi-view Images
Mar 24, 2018
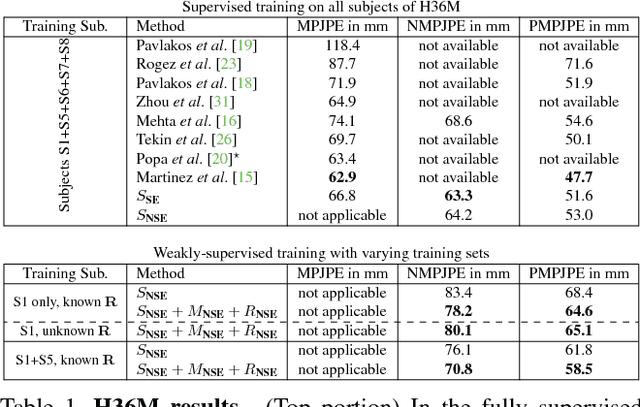

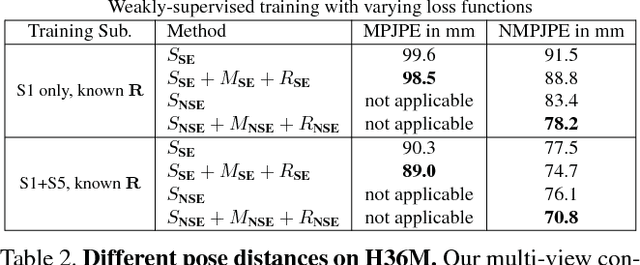
Accurate 3D human pose estimation from single images is possible with sophisticated deep-net architectures that have been trained on very large datasets. However, this still leaves open the problem of capturing motions for which no such database exists. Manual annotation is tedious, slow, and error-prone. In this paper, we propose to replace most of the annotations by the use of multiple views, at training time only. Specifically, we train the system to predict the same pose in all views. Such a consistency constraint is necessary but not sufficient to predict accurate poses. We therefore complement it with a supervised loss aiming to predict the correct pose in a small set of labeled images, and with a regularization term that penalizes drift from initial predictions. Furthermore, we propose a method to estimate camera pose jointly with human pose, which lets us utilize multi-view footage where calibration is difficult, e.g., for pan-tilt or moving handheld cameras. We demonstrate the effectiveness of our approach on established benchmarks, as well as on a new Ski dataset with rotating cameras and expert ski motion, for which annotations are truly hard to obtain.