 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQGen: On the Ability to Generalize in Quantization Aware Training
Apr 19, 2024



Quantization lowers memory usage, computational requirements, and latency by utilizing fewer bits to represent model weights and activations. In this work, we investigate the generalization properties of quantized neural networks, a characteristic that has received little attention despite its implications on model performance. In particular, first, we develop a theoretical model for quantization in neural networks and demonstrate how quantization functions as a form of regularization. Second, motivated by recent work connecting the sharpness of the loss landscape and generalization, we derive an approximate bound for the generalization of quantized models conditioned on the amount of quantization noise. We then validate our hypothesis by experimenting with over 2000 models trained on CIFAR-10, CIFAR-100, and ImageNet datasets on convolutional and transformer-based models.
Statistical Hardware Design With Multi-model Active Learning
Mar 26, 2023



With the rising complexity of numerous novel applications that serve our modern society comes the strong need to design efficient computing platforms. Designing efficient hardware is, however, a complex multi-objective problem that deals with multiple parameters and their interactions. Given that there are a large number of parameters and objectives involved in hardware design, synthesizing all possible combinations is not a feasible method to find the optimal solution. One promising approach to tackle this problem is statistical modeling of a desired hardware performance. Here, we propose a model-based active learning approach to solve this problem. Our proposed method uses Bayesian models to characterize various aspects of hardware performance. We also use transfer learning and Gaussian regression bootstrapping techniques in conjunction with active learning to create more accurate models. Our proposed statistical modeling method provides hardware models that are sufficiently accurate to perform design space exploration as well as performance prediction simultaneously. We use our proposed method to perform design space exploration and performance prediction for various hardware setups, such as micro-architecture design and OpenCL kernels for FPGA targets. Our experiments show that the number of samples required to create performance models significantly reduces while maintaining the predictive power of our proposed statistical models. For instance, in our performance prediction setting, the proposed method needs 65% fewer samples to create the model, and in the design space exploration setting, our proposed method can find the best parameter settings by exploring less than 50 samples.
QReg: On Regularization Effects of Quantization
Jun 27, 2022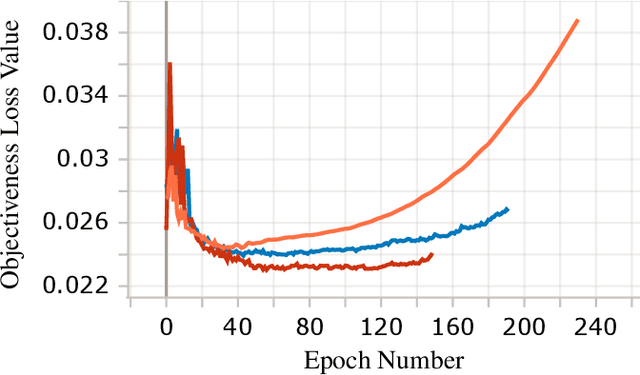
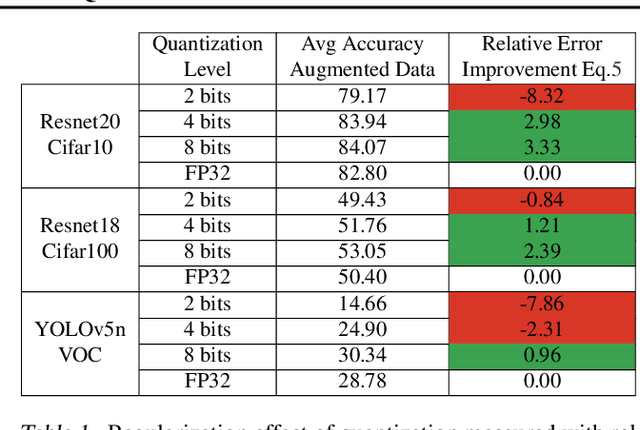
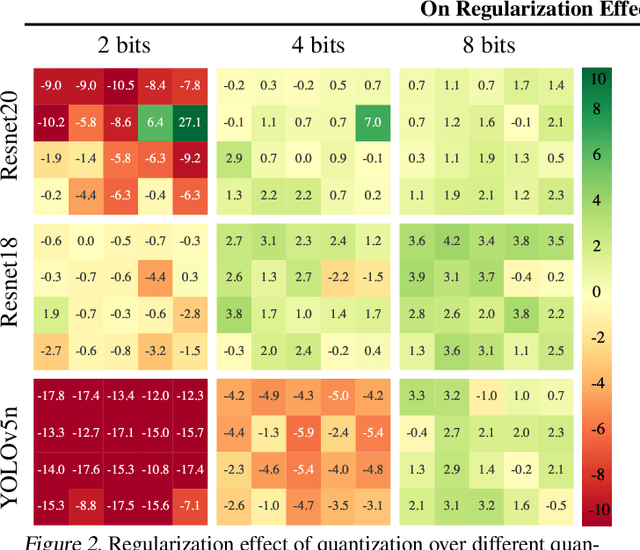
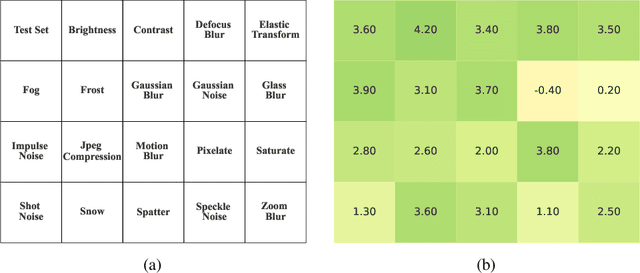
In this paper we study the effects of quantization in DNN training. We hypothesize that weight quantization is a form of regularization and the amount of regularization is correlated with the quantization level (precision). We confirm our hypothesis by providing analytical study and empirical results. By modeling weight quantization as a form of additive noise to weights, we explore how this noise propagates through the network at training time. We then show that the magnitude of this noise is correlated with the level of quantization. To confirm our analytical study, we performed an extensive list of experiments summarized in this paper in which we show that the regularization effects of quantization can be seen in various vision tasks and models, over various datasets. Based on our study, we propose that 8-bit quantization provides a reliable form of regularization in different vision tasks and models.
Mobile-URSONet: an Embeddable Neural Network for Onboard Spacecraft Pose Estimation
May 04, 2022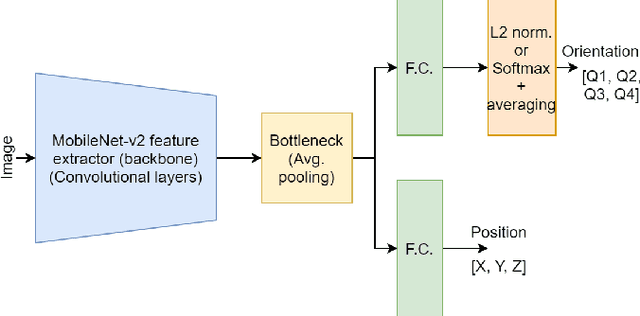
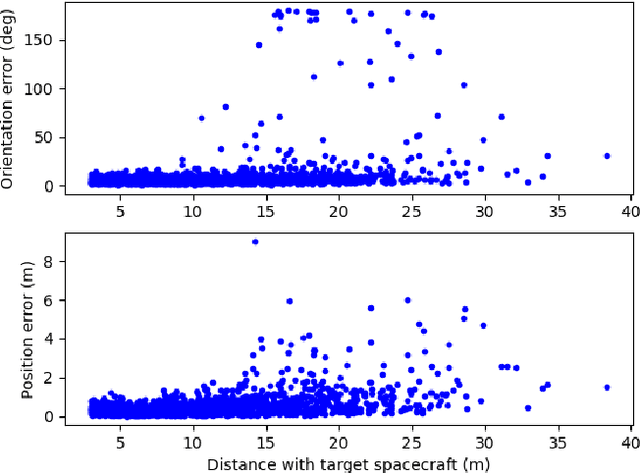
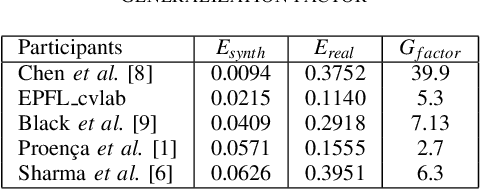

Spacecraft pose estimation is an essential computer vision application that can improve the autonomy of in-orbit operations. An ESA/Stanford competition brought out solutions that seem hardly compatible with the constraints imposed on spacecraft onboard computers. URSONet is among the best in the competition for its generalization capabilities but at the cost of a tremendous number of parameters and high computational complexity. In this paper, we propose Mobile-URSONet: a spacecraft pose estimation convolutional neural network with 178 times fewer parameters while degrading accuracy by no more than four times compared to URSONet.
MemSE: Fast MSE Prediction for Noisy Memristor-Based DNN Accelerators
May 03, 2022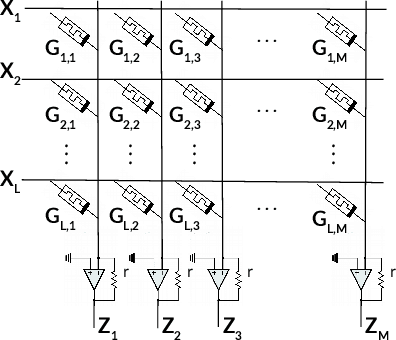
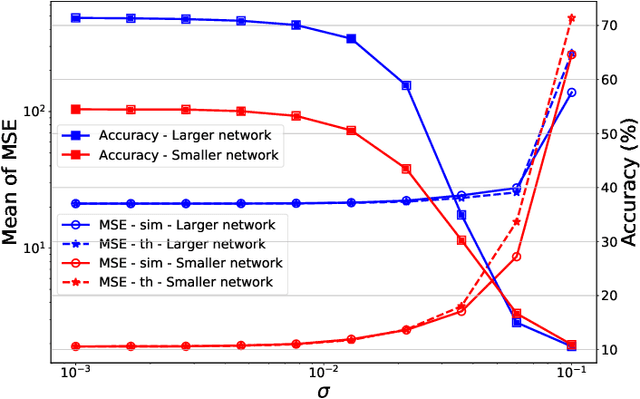
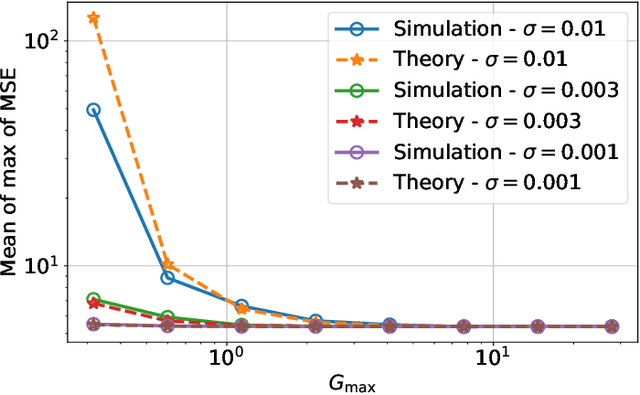
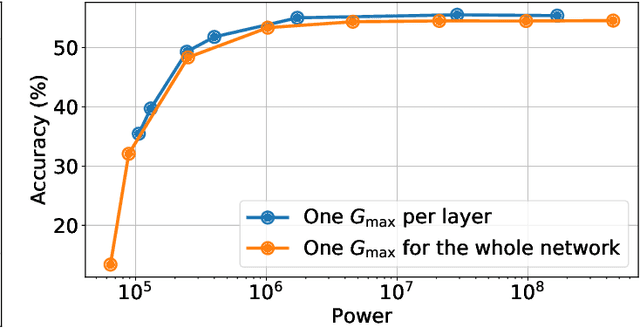
Memristors enable the computation of matrix-vector multiplications (MVM) in memory and, therefore, show great potential in highly increasing the energy efficiency of deep neural network (DNN) inference accelerators. However, computations in memristors suffer from hardware non-idealities and are subject to different sources of noise that may negatively impact system performance. In this work, we theoretically analyze the mean squared error of DNNs that use memristor crossbars to compute MVM. We take into account both the quantization noise, due to the necessity of reducing the DNN model size, and the programming noise, stemming from the variability during the programming of the memristance value. Simulations on pre-trained DNN models showcase the accuracy of the analytical prediction. Furthermore the proposed method is almost two order of magnitude faster than Monte-Carlo simulation, thus making it possible to optimize the implementation parameters to achieve minimal error for a given power constraint.
Rethinking Pareto Frontier for Performance Evaluation of Deep Neural Networks
Feb 18, 2022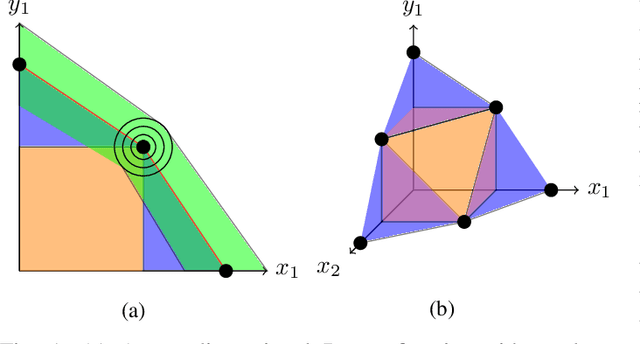

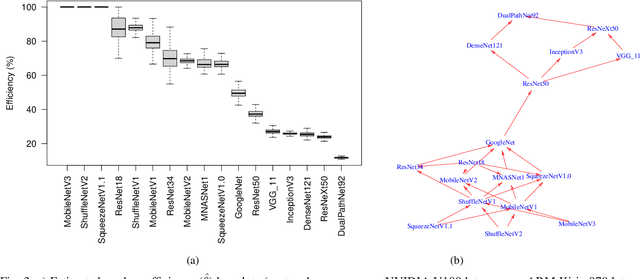

Recent efforts in deep learning show a considerable advancement in redesigning deep learning models for low-resource and edge devices. The performance optimization of deep learning models are conducted either manually or through automatic architecture search, or a combination of both. The throughput and power consumption of deep learning models strongly depend on the target hardware. We propose to use a \emph{multi-dimensional} Pareto frontier to re-define the efficiency measure using a multi-objective optimization, where other variables such as power consumption, latency, and accuracy play a relative role in defining a dominant model. Furthermore, a random version of the multi-dimensional Pareto frontier is introduced to mitigate the uncertainty of accuracy, latency, and throughput variations of deep learning models in different experimental setups. These two breakthroughs provide an objective benchmarking method for a wide range of deep learning models. We run our novel multi-dimensional stochastic relative efficiency on a wide range of deep image classification models trained ImageNet data. Thank to this new approach we combine competing variables with stochastic nature simultaneously in a single relative efficiency measure. This allows to rank deep models that run efficiently on different computing hardware, and combines inference efficiency with training efficiency objectively.
CNN2Gate: Toward Designing a General Framework for Implementation of Convolutional Neural Networks on FPGA
Apr 10, 2020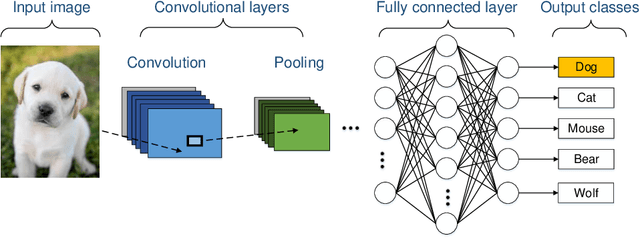
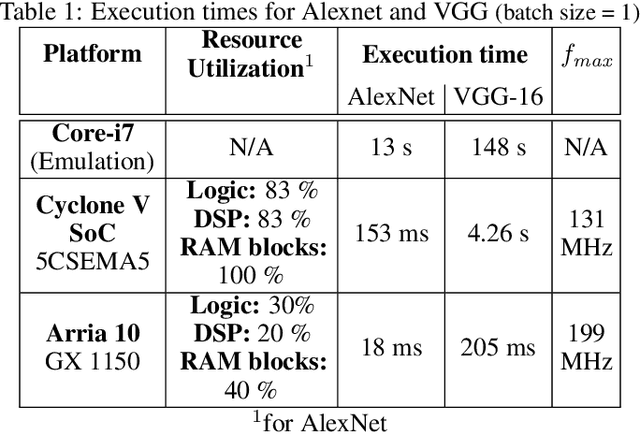
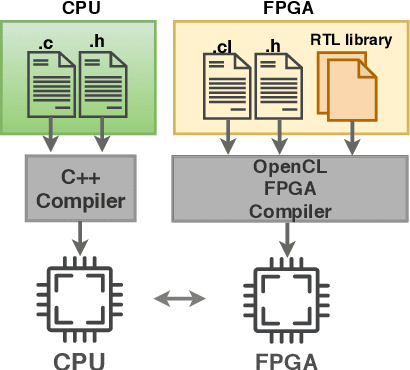
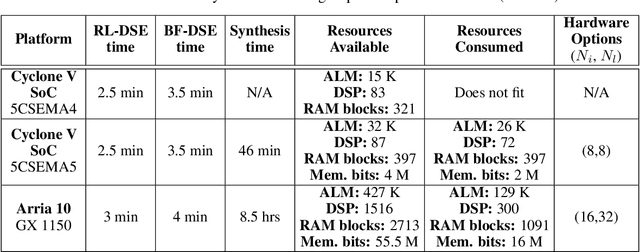
Convolutional Neural Networks (CNNs) have a major impact on our society because of the numerous services they provide. On the other hand, they require considerable computing power. To satisfy these requirements, it is possible to use graphic processing units (GPUs). However, high power consumption and limited external IOs constrain their usability and suitability in industrial and mission-critical scenarios. Recently, the number of researches that utilize FPGAs to implement CNNs are increasing rapidly. This is due to the lower power consumption and easy reconfigurability offered by these platforms. Because of the research efforts put into topics such as architecture, synthesis and optimization, some new challenges are arising to integrate such hardware solutions to high-level machine learning software libraries. This paper introduces an integrated framework (CNN2Gate) that supports compilation of a CNN model for an FPGA target. CNN2Gate exploits the OpenCL synthesis workflow for FPGAs offered by commercial vendors. CNN2Gate is capable of parsing CNN models from several popular high-level machine learning libraries such as Keras, Pytorch, Caffe2 etc. CNN2Gate extracts computation flow of layers, in addition to weights and biases and applies a "given" fixed-point quantization. Furthermore, it writes this information in the proper format for OpenCL synthesis tools that are then used to build and run the project on FPGA. CNN2Gate performs design-space exploration using a reinforcement learning agent and fits the design on different FPGAs with limited logic resources automatically. This paper reports results of automatic synthesis and design-space exploration of AlexNet and VGG-16 on various Intel FPGA platforms. CNN2Gate achieves a latency of 205 ms for VGG-16 and 18 ms for AlexNet on the FPGA.
Layerwise Noise Maximisation to Train Low-Energy Deep Neural Networks
Dec 23, 2019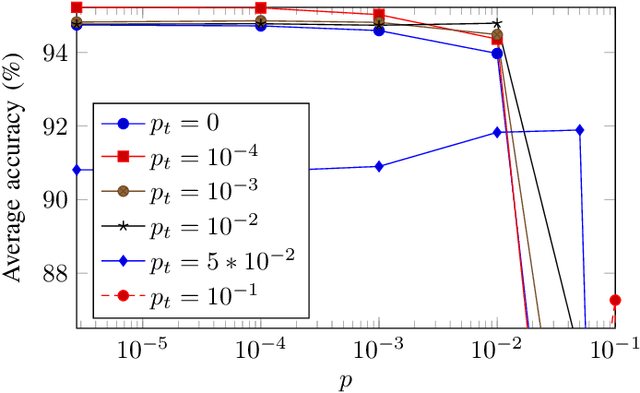
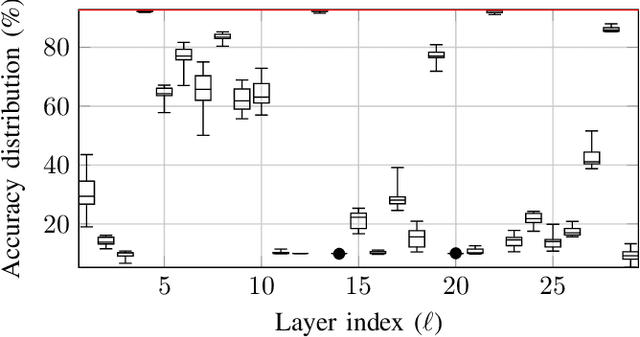
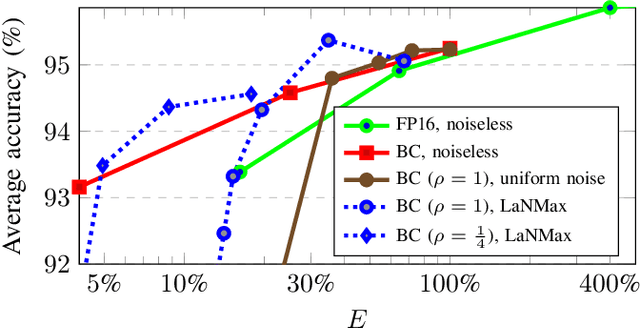
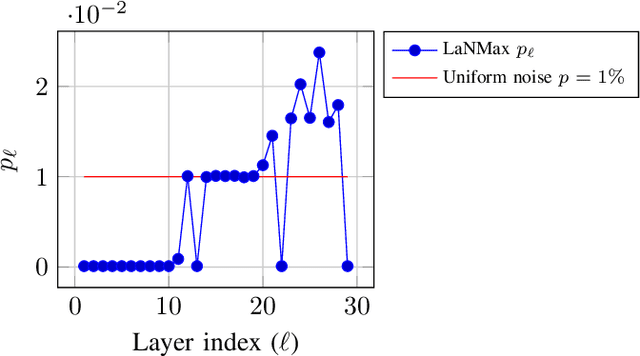
Deep neural networks (DNNs) depend on the storage of a large number of parameters, which consumes an important portion of the energy used during inference. This paper considers the case where the energy usage of memory elements can be reduced at the cost of reduced reliability. A training algorithm is proposed to optimize the reliability of the storage separately for each layer of the network, while incurring a negligible complexity overhead compared to a conventional stochastic gradient descent training. For an exponential energy-reliability model, the proposed training approach can decrease the memory energy consumption of a DNN with binary parameters by 3.3$\times$ at isoaccuracy, compared to a reliable implementation.
U-Net Fixed-Point Quantization for Medical Image Segmentation
Sep 09, 2019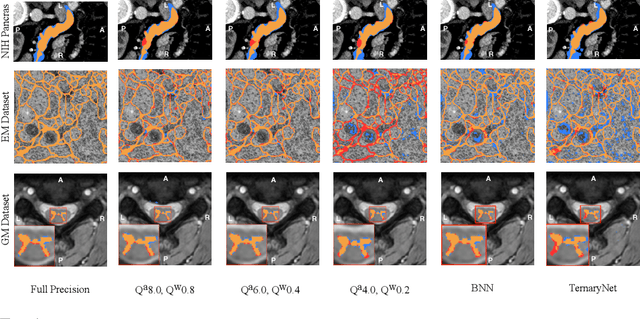
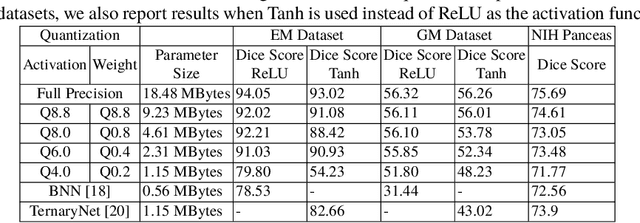
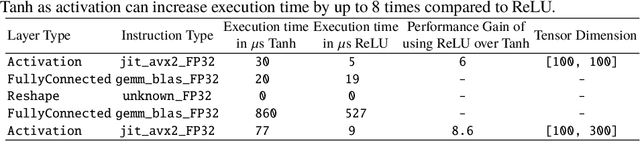
Model quantization is leveraged to reduce the memory consumption and the computation time of deep neural networks. This is achieved by representing weights and activations with a lower bit resolution when compared to their high precision floating point counterparts. The suitable level of quantization is directly related to the model performance. Lowering the quantization precision (e.g. 2 bits), reduces the amount of memory required to store model parameters and the amount of logic required to implement computational blocks, which contributes to reducing the power consumption of the entire system. These benefits typically come at the cost of reduced accuracy. The main challenge is to quantize a network as much as possible, while maintaining the performance accuracy. In this work, we present a quantization method for the U-Net architecture, a popular model in medical image segmentation. We then apply our quantization algorithm to three datasets: (1) the Spinal Cord Gray Matter Segmentation (GM), (2) the ISBI challenge for segmentation of neuronal structures in Electron Microscopic (EM), and (3) the public National Institute of Health (NIH) dataset for pancreas segmentation in abdominal CT scans. The reported results demonstrate that with only 4 bits for weights and 6 bits for activations, we obtain 8 fold reduction in memory requirements while loosing only 2.21%, 0.57% and 2.09% dice overlap score for EM, GM and NIH datasets respectively. Our fixed point quantization provides a flexible trade off between accuracy and memory requirement which is not provided by previous quantization methods for U-Net such as TernaryNet.