 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning of Sequential Strategies
May 08, 2019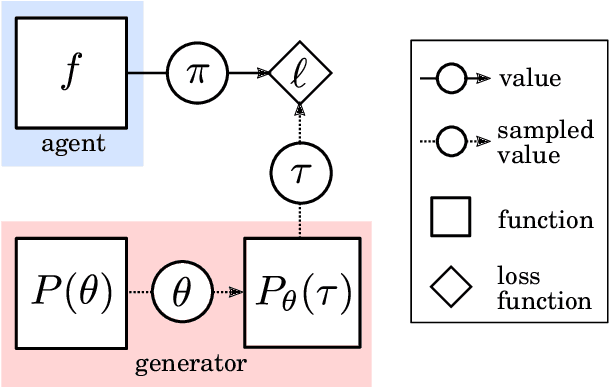
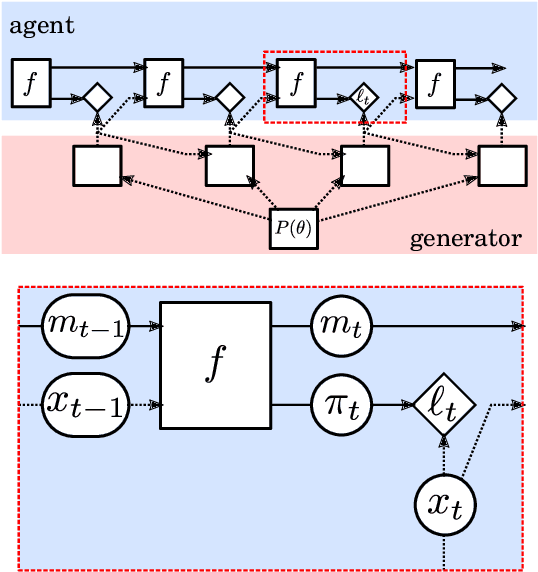
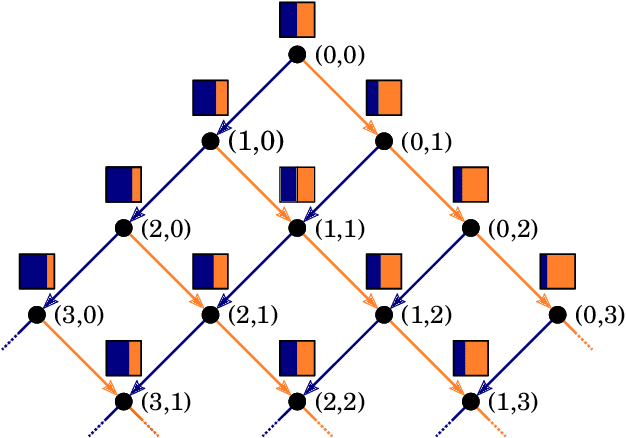
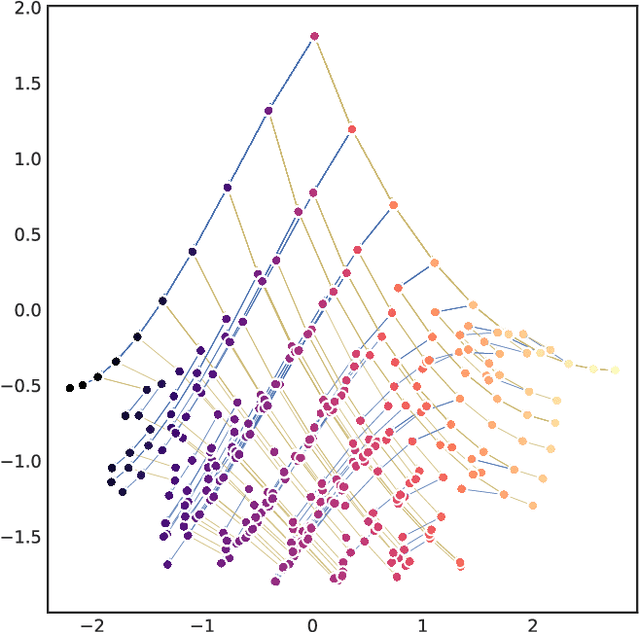
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Distilling Policy Distillation
Feb 06, 2019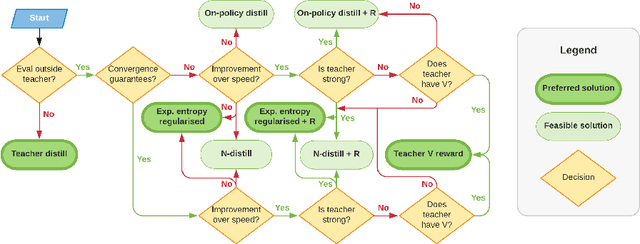



The transfer of knowledge from one policy to another is an important tool in Deep Reinforcement Learning. This process, referred to as distillation, has been used to great success, for example, by enhancing the optimisation of agents, leading to stronger performance faster, on harder domains [26, 32, 5, 8]. Despite the widespread use and conceptual simplicity of distillation, many different formulations are used in practice, and the subtle variations between them can often drastically change the performance and the resulting objective that is being optimised. In this work, we rigorously explore the entire landscape of policy distillation, comparing the motivations and strengths of each variant through theoretical and empirical analysis. Our results point to three distillation techniques, that are preferred depending on specifics of the task. Specifically a newly proposed expected entropy regularised distillation allows for quicker learning in a wide range of situations, while still guaranteeing convergence.
Meta-Learning with Latent Embedding Optimization
Sep 28, 2018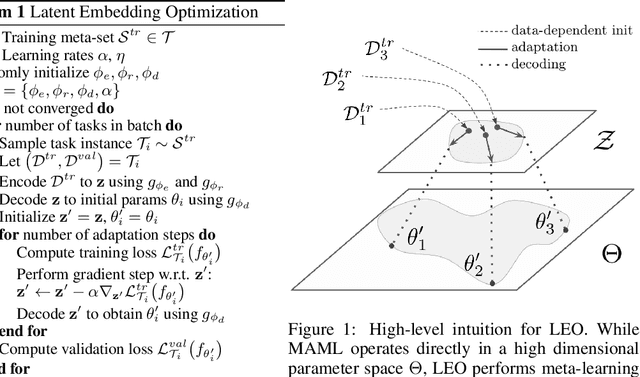
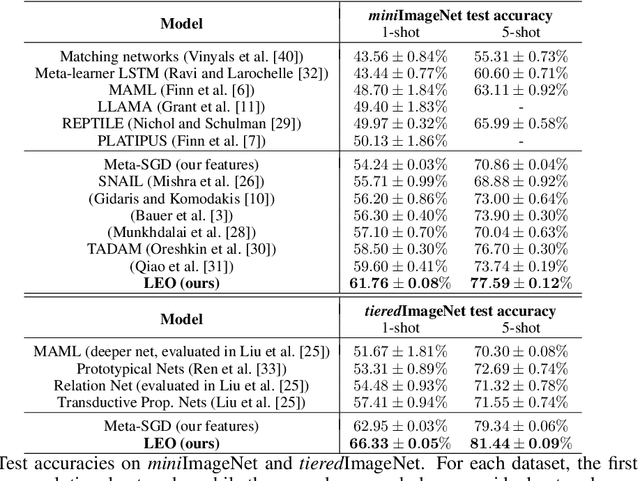
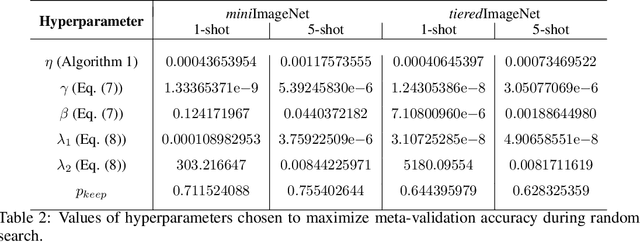
Gradient-based meta-learning techniques are both widely applicable and proficient at solving challenging few-shot learning and fast adaptation problems. However, they have practical difficulties when operating on high-dimensional parameter spaces in extreme low-data regimes. We show that it is possible to bypass these limitations by learning a data-dependent latent generative representation of model parameters, and performing gradient-based meta-learning in this low-dimensional latent space. The resulting approach, latent embedding optimization (LEO), decouples the gradient-based adaptation procedure from the underlying high-dimensional space of model parameters. Our evaluation shows that LEO can achieve state-of-the-art performance on the competitive miniImageNet and tieredImageNet few-shot classification tasks. Further analysis indicates LEO is able to capture uncertainty in the data, and can perform adaptation more effectively by optimizing in latent space.
Massively Parallel Video Networks
Sep 05, 2018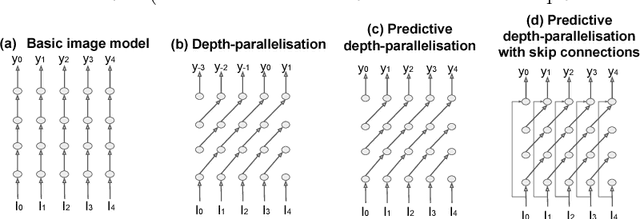

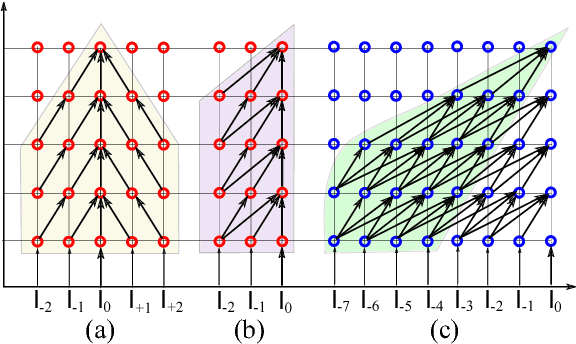
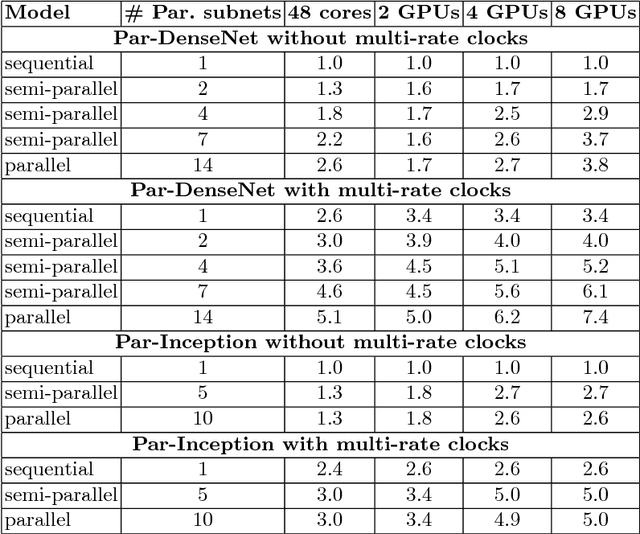
We introduce a class of causal video understanding models that aims to improve efficiency of video processing by maximising throughput, minimising latency, and reducing the number of clock cycles. Leveraging operation pipelining and multi-rate clocks, these models perform a minimal amount of computation (e.g. as few as four convolutional layers) for each frame per timestep to produce an output. The models are still very deep, with dozens of such operations being performed but in a pipelined fashion that enables depth-parallel computation. We illustrate the proposed principles by applying them to existing image architectures and analyse their behaviour on two video tasks: action recognition and human keypoint localisation. The results show that a significant degree of parallelism, and implicitly speedup, can be achieved with little loss in performance.
Meta-Learning by the Baldwin Effect
Jun 22, 2018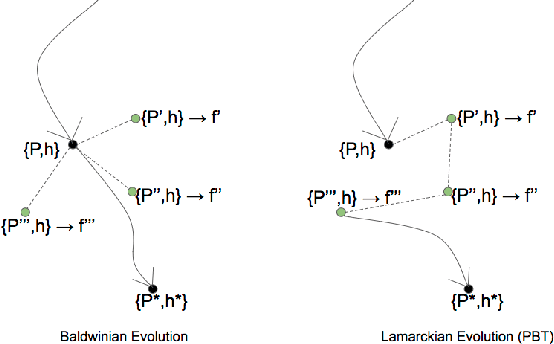
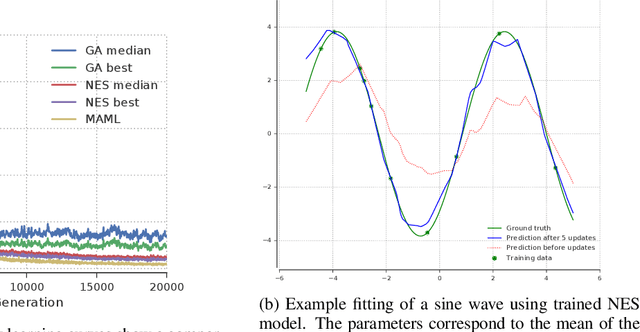
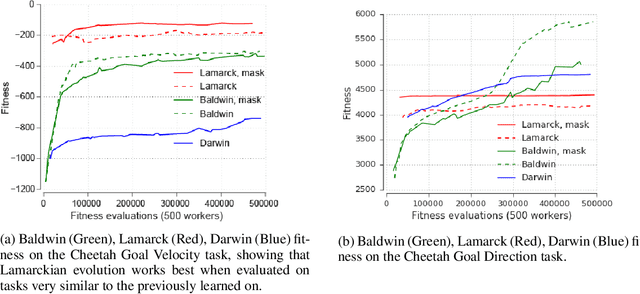
The scope of the Baldwin effect was recently called into question by two papers that closely examined the seminal work of Hinton and Nowlan. To this date there has been no demonstration of its necessity in empirically challenging tasks. Here we show that the Baldwin effect is capable of evolving few-shot supervised and reinforcement learning mechanisms, by shaping the hyperparameters and the initial parameters of deep learning algorithms. Furthermore it can genetically accommodate strong learning biases on the same set of problems as a recent machine learning algorithm called MAML "Model Agnostic Meta-Learning" which uses second-order gradients instead of evolution to learn a set of reference parameters (initial weights) that can allow rapid adaptation to tasks sampled from a distribution. Whilst in simple cases MAML is more data efficient than the Baldwin effect, the Baldwin effect is more general in that it does not require gradients to be backpropagated to the reference parameters or hyperparameters, and permits effectively any number of gradient updates in the inner loop. The Baldwin effect learns strong learning dependent biases, rather than purely genetically accommodating fixed behaviours in a learning independent manner.
Mix&Match - Agent Curricula for Reinforcement Learning
Jun 05, 2018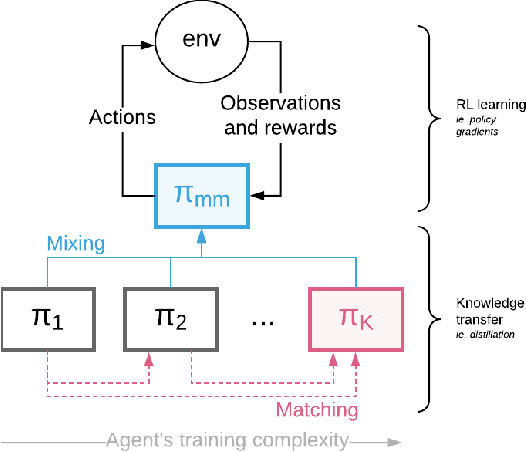
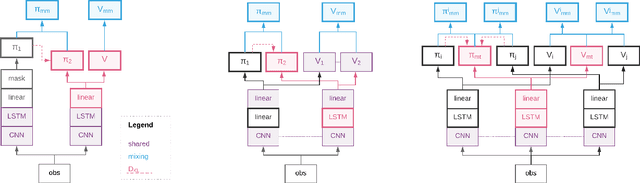
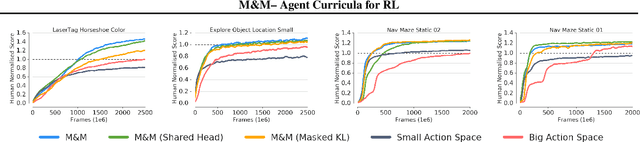
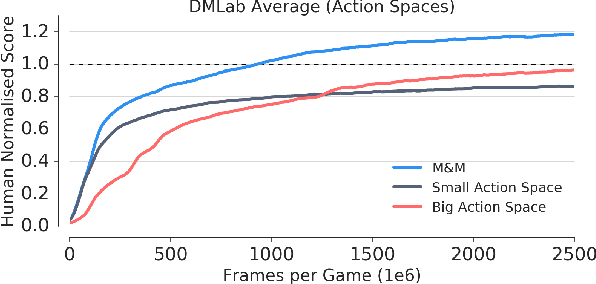
We introduce Mix&Match (M&M) - a training framework designed to facilitate rapid and effective learning in RL agents, especially those that would be too slow or too challenging to train otherwise. The key innovation is a procedure that allows us to automatically form a curriculum over agents. Through such a curriculum we can progressively train more complex agents by, effectively, bootstrapping from solutions found by simpler agents. In contradistinction to typical curriculum learning approaches, we do not gradually modify the tasks or environments presented, but instead use a process to gradually alter how the policy is represented internally. We show the broad applicability of our method by demonstrating significant performance gains in three different experimental setups: (1) We train an agent able to control more than 700 actions in a challenging 3D first-person task; using our method to progress through an action-space curriculum we achieve both faster training and better final performance than one obtains using traditional methods. (2) We further show that M&M can be used successfully to progress through a curriculum of architectural variants defining an agents internal state. (3) Finally, we illustrate how a variant of our method can be used to improve agent performance in a multitask setting.
Kickstarting Deep Reinforcement Learning
Mar 10, 2018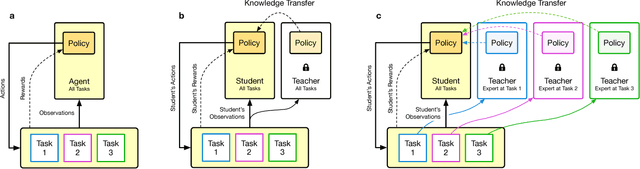
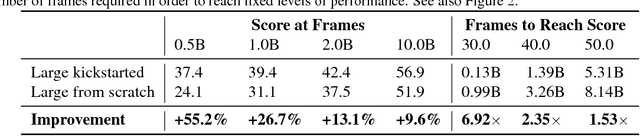
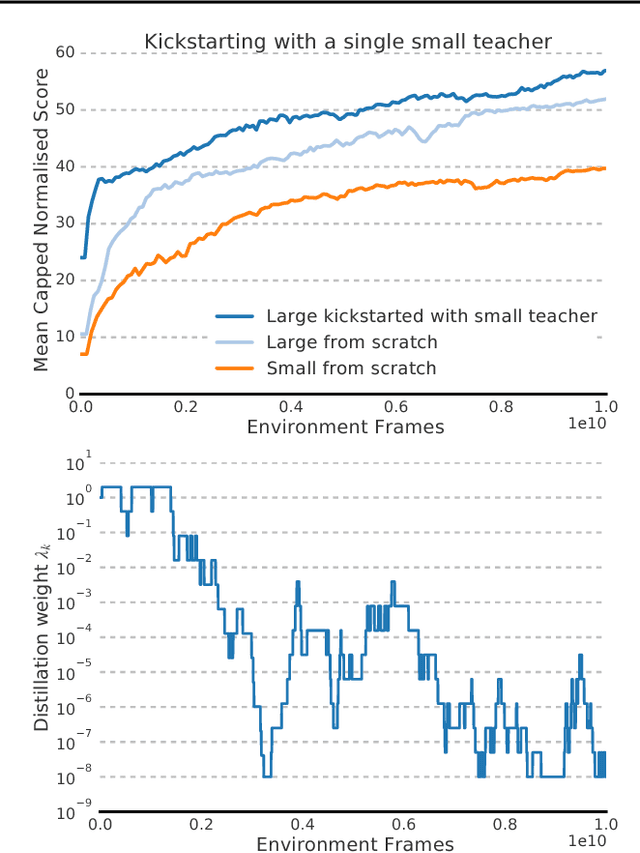
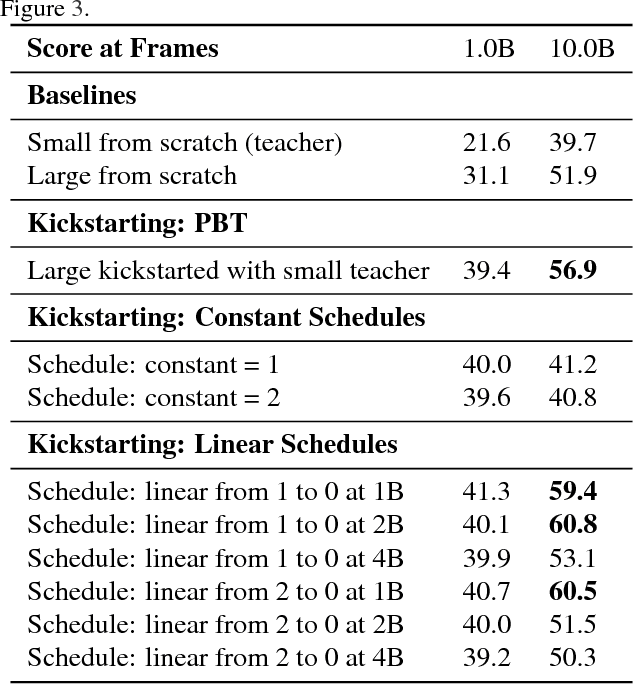
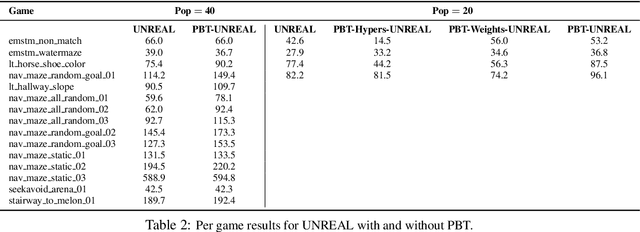
We present a method for using previously-trained 'teacher' agents to kickstart the training of a new 'student' agent. To this end, we leverage ideas from policy distillation and population based training. Our method places no constraints on the architecture of the teacher or student agents, and it regulates itself to allow the students to surpass their teachers in performance. We show that, on a challenging and computationally-intensive multi-task benchmark (DMLab-30), kickstarted training improves the data efficiency of new agents, making it significantly easier to iterate on their design. We also show that the same kickstarting pipeline can allow a single student agent to leverage multiple 'expert' teachers which specialize on individual tasks. In this setting kickstarting yields surprisingly large gains, with the kickstarted agent matching the performance of an agent trained from scratch in almost 10x fewer steps, and surpassing its final performance by 42 percent. Kickstarting is conceptually simple and can easily be incorporated into reinforcement learning experiments.
Population Based Training of Neural Networks
Nov 28, 2017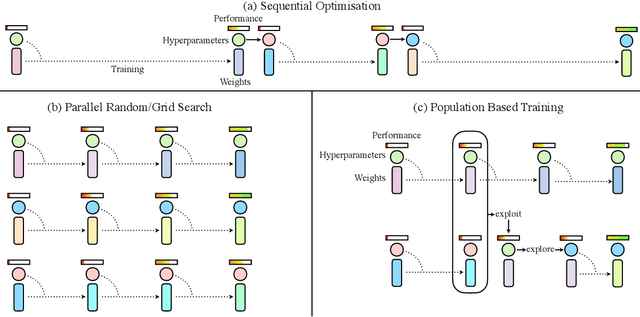

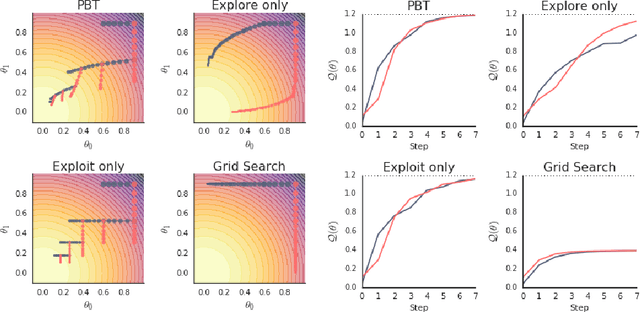
Neural networks dominate the modern machine learning landscape, but their training and success still suffer from sensitivity to empirical choices of hyperparameters such as model architecture, loss function, and optimisation algorithm. In this work we present \emph{Population Based Training (PBT)}, a simple asynchronous optimisation algorithm which effectively utilises a fixed computational budget to jointly optimise a population of models and their hyperparameters to maximise performance. Importantly, PBT discovers a schedule of hyperparameter settings rather than following the generally sub-optimal strategy of trying to find a single fixed set to use for the whole course of training. With just a small modification to a typical distributed hyperparameter training framework, our method allows robust and reliable training of models. We demonstrate the effectiveness of PBT on deep reinforcement learning problems, showing faster wall-clock convergence and higher final performance of agents by optimising over a suite of hyperparameters. In addition, we show the same method can be applied to supervised learning for machine translation, where PBT is used to maximise the BLEU score directly, and also to training of Generative Adversarial Networks to maximise the Inception score of generated images. In all cases PBT results in the automatic discovery of hyperparameter schedules and model selection which results in stable training and better final performance.
Beautiful and damned. Combined effect of content quality and social ties on user engagement
Nov 01, 2017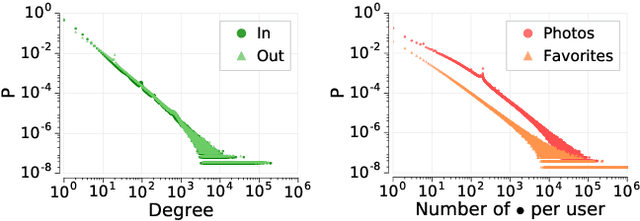
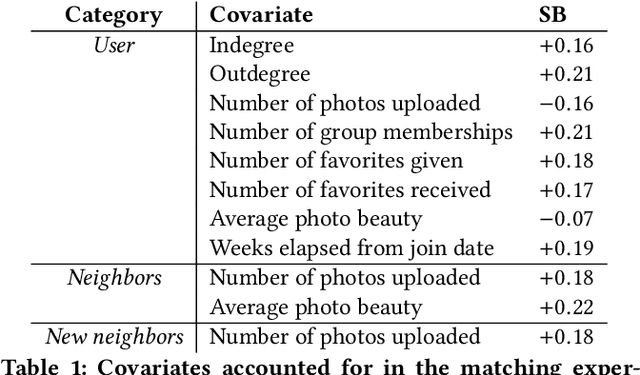
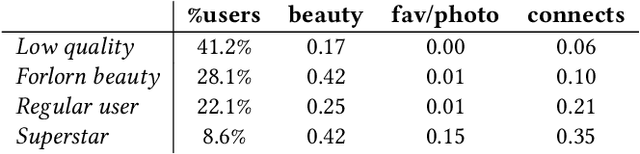
User participation in online communities is driven by the intertwinement of the social network structure with the crowd-generated content that flows along its links. These aspects are rarely explored jointly and at scale. By looking at how users generate and access pictures of varying beauty on Flickr, we investigate how the production of quality impacts the dynamics of online social systems. We develop a deep learning computer vision model to score images according to their aesthetic value and we validate its output through crowdsourcing. By applying it to over 15B Flickr photos, we study for the first time how image beauty is distributed over a large-scale social system. Beautiful images are evenly distributed in the network, although only a small core of people get social recognition for them. To study the impact of exposure to quality on user engagement, we set up matching experiments aimed at detecting causality from observational data. Exposure to beauty is double-edged: following people who produce high-quality content increases one's probability of uploading better photos; however, an excessive imbalance between the quality generated by a user and the user's neighbors leads to a decline in engagement. Our analysis has practical implications for improving link recommender systems.
Sobolev Training for Neural Networks
Jul 26, 2017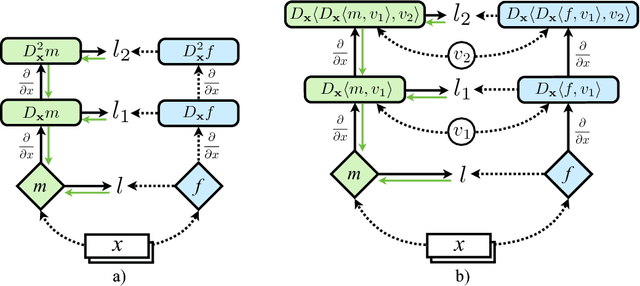
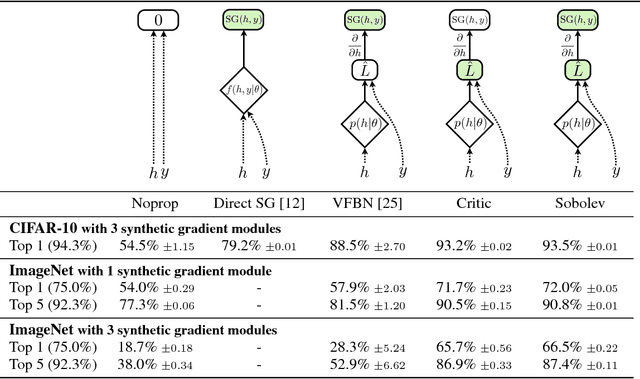
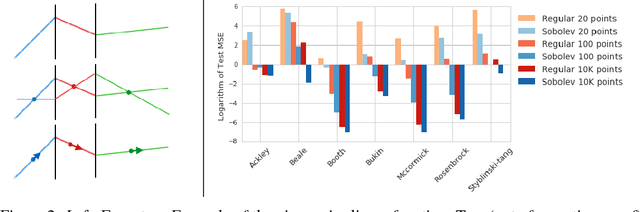
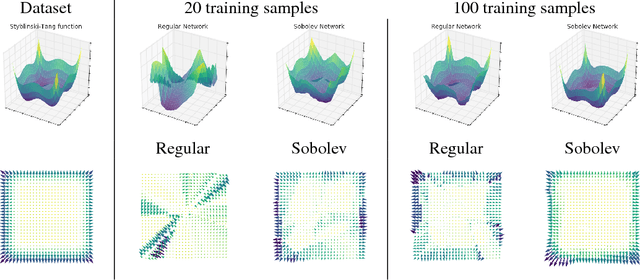
At the heart of deep learning we aim to use neural networks as function approximators - training them to produce outputs from inputs in emulation of a ground truth function or data creation process. In many cases we only have access to input-output pairs from the ground truth, however it is becoming more common to have access to derivatives of the target output with respect to the input - for example when the ground truth function is itself a neural network such as in network compression or distillation. Generally these target derivatives are not computed, or are ignored. This paper introduces Sobolev Training for neural networks, which is a method for incorporating these target derivatives in addition the to target values while training. By optimising neural networks to not only approximate the function's outputs but also the function's derivatives we encode additional information about the target function within the parameters of the neural network. Thereby we can improve the quality of our predictors, as well as the data-efficiency and generalization capabilities of our learned function approximation. We provide theoretical justifications for such an approach as well as examples of empirical evidence on three distinct domains: regression on classical optimisation datasets, distilling policies of an agent playing Atari, and on large-scale applications of synthetic gradients. In all three domains the use of Sobolev Training, employing target derivatives in addition to target values, results in models with higher accuracy and stronger generalisation.