 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGALA: Toward Geometry-and-Lighting-Aware Object Search for Compositing
Mar 31, 2022
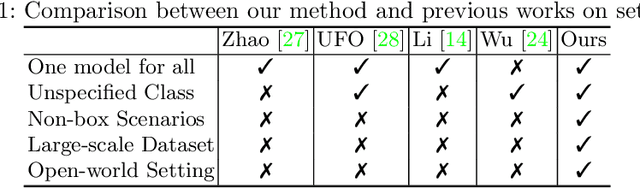

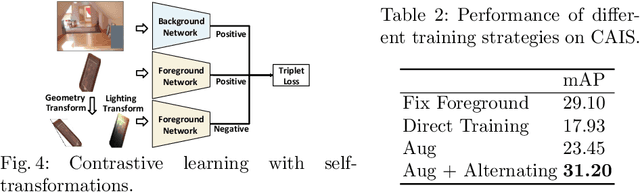
Compositing-aware object search aims to find the most compatible objects for compositing given a background image and a query bounding box. Previous works focus on learning compatibility between the foreground object and background, but fail to learn other important factors from large-scale data, i.e. geometry and lighting. To move a step further, this paper proposes GALA (Geometry-and-Lighting-Aware), a generic foreground object search method with discriminative modeling on geometry and lighting compatibility for open-world image compositing. Remarkably, it achieves state-of-the-art results on the CAIS dataset and generalizes well on large-scale open-world datasets, i.e. Pixabay and Open Images. In addition, our method can effectively handle non-box scenarios, where users only provide background images without any input bounding box. A web demo (see supplementary materials) is built to showcase applications of the proposed method for compositing-aware search and automatic location/scale prediction for the foreground object.
TransGeo: Transformer Is All You Need for Cross-view Image Geo-localization
Mar 31, 2022

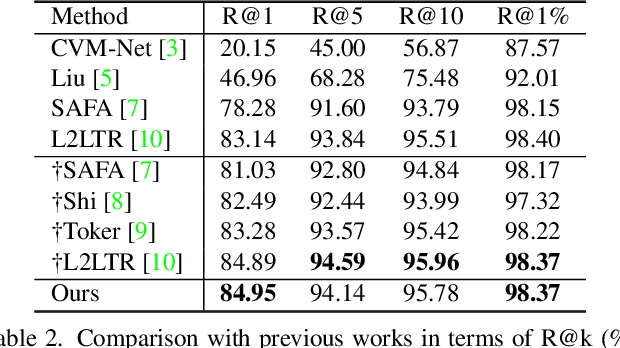
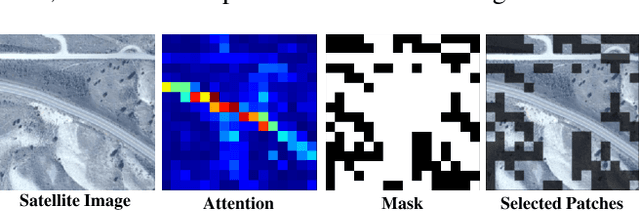
The dominant CNN-based methods for cross-view image geo-localization rely on polar transform and fail to model global correlation. We propose a pure transformer-based approach (TransGeo) to address these limitations from a different perspective. TransGeo takes full advantage of the strengths of transformer related to global information modeling and explicit position information encoding. We further leverage the flexibility of transformer input and propose an attention-guided non-uniform cropping method, so that uninformative image patches are removed with negligible drop on performance to reduce computation cost. The saved computation can be reallocated to increase resolution only for informative patches, resulting in performance improvement with no additional computation cost. This "attend and zoom-in" strategy is highly similar to human behavior when observing images. Remarkably, TransGeo achieves state-of-the-art results on both urban and rural datasets, with significantly less computation cost than CNN-based methods. It does not rely on polar transform and infers faster than CNN-based methods. Code is available at https://github.com/Jeff-Zilence/TransGeo2022.
BDANet: Multiscale Convolutional Neural Network with Cross-directional Attention for Building Damage Assessment from Satellite Images
May 16, 2021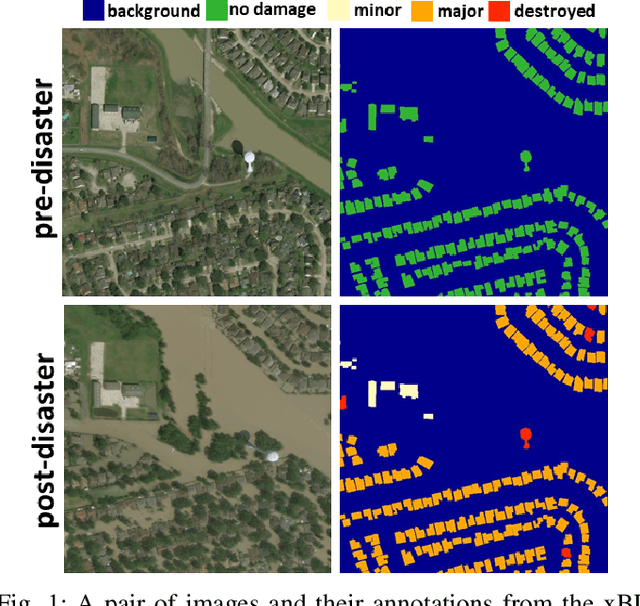
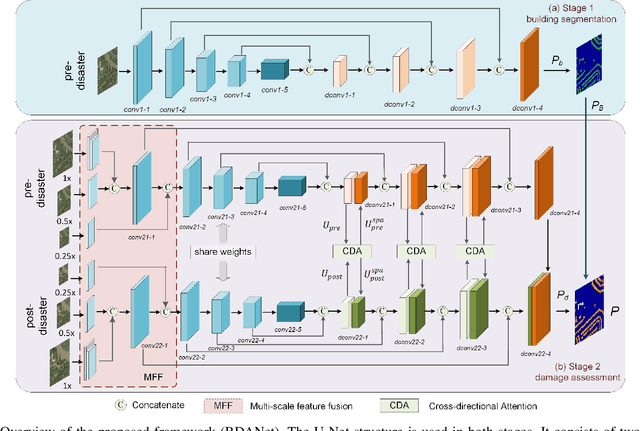
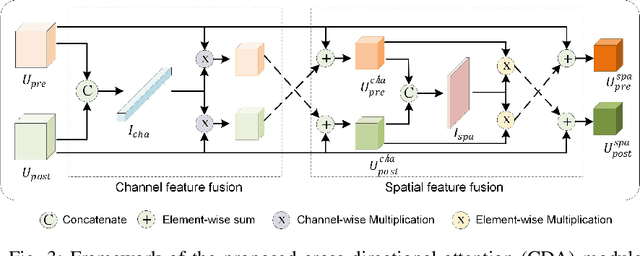
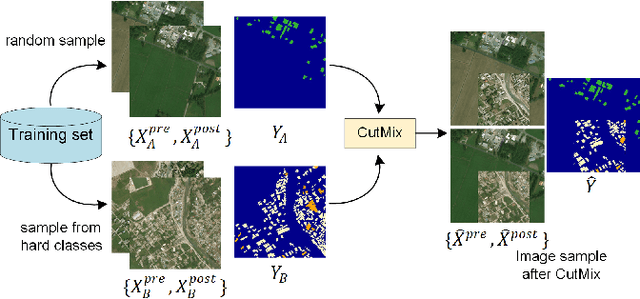
Fast and effective responses are required when a natural disaster (e.g., earthquake, hurricane, etc.) strikes. Building damage assessment from satellite imagery is critical before relief effort is deployed. With a pair of pre- and post-disaster satellite images, building damage assessment aims at predicting the extent of damage to buildings. With the powerful ability of feature representation, deep neural networks have been successfully applied to building damage assessment. Most existing works simply concatenate pre- and post-disaster images as input of a deep neural network without considering their correlations. In this paper, we propose a novel two-stage convolutional neural network for Building Damage Assessment, called BDANet. In the first stage, a U-Net is used to extract the locations of buildings. Then the network weights from the first stage are shared in the second stage for building damage assessment. In the second stage, a two-branch multi-scale U-Net is employed as backbone, where pre- and post-disaster images are fed into the network separately. A cross-directional attention module is proposed to explore the correlations between pre- and post-disaster images. Moreover, CutMix data augmentation is exploited to tackle the challenge of difficult classes. The proposed method achieves state-of-the-art performance on a large-scale dataset -- xBD. The code is available at https://github.com/ShaneShen/BDANet-Building-Damage-Assessment.
MutualNet: Adaptive ConvNet via Mutual Learning from Different Model Configurations
May 14, 2021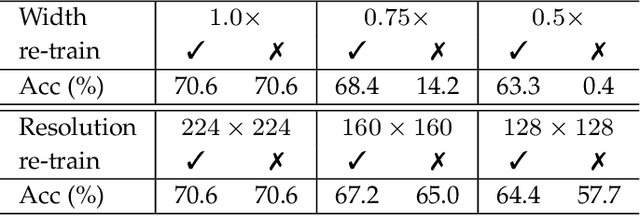


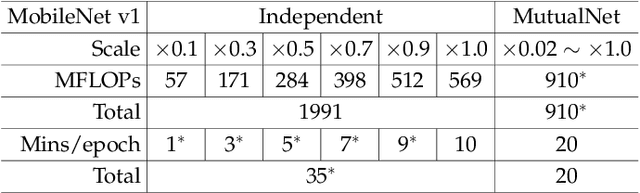
Most existing deep neural networks are static, which means they can only do inference at a fixed complexity. But the resource budget can vary substantially across different devices. Even on a single device, the affordable budget can change with different scenarios, and repeatedly training networks for each required budget would be incredibly expensive. Therefore, in this work, we propose a general method called MutualNet to train a single network that can run at a diverse set of resource constraints. Our method trains a cohort of model configurations with various network widths and input resolutions. This mutual learning scheme not only allows the model to run at different width-resolution configurations but also transfers the unique knowledge among these configurations, helping the model to learn stronger representations overall. MutualNet is a general training methodology that can be applied to various network structures (e.g., 2D networks: MobileNets, ResNet, 3D networks: SlowFast, X3D) and various tasks (e.g., image classification, object detection, segmentation, and action recognition), and is demonstrated to achieve consistent improvements on a variety of datasets. Since we only train the model once, it also greatly reduces the training cost compared to independently training several models. Surprisingly, MutualNet can also be used to significantly boost the performance of a single network, if dynamic resource constraint is not a concern. In summary, MutualNet is a unified method for both static and adaptive, 2D and 3D networks. Codes and pre-trained models are available at \url{https://github.com/taoyang1122/MutualNet}.
3D Human Pose Estimation with Spatial and Temporal Transformers
Mar 24, 2021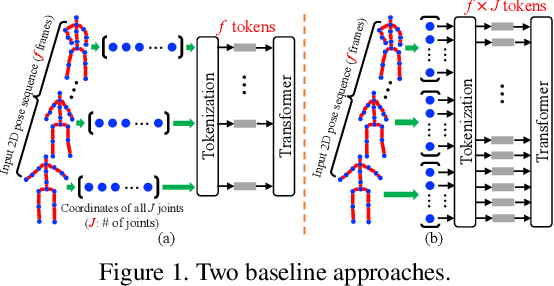
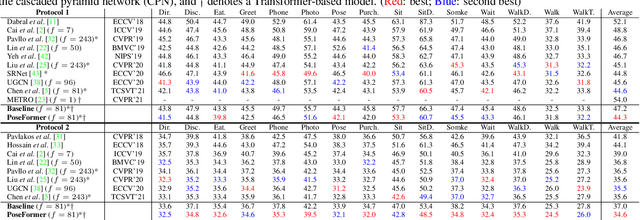
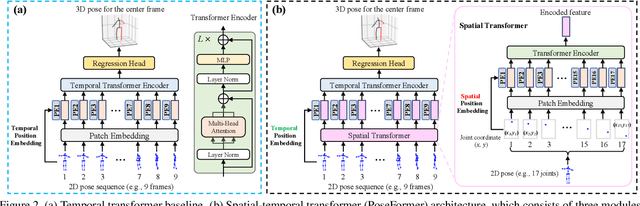
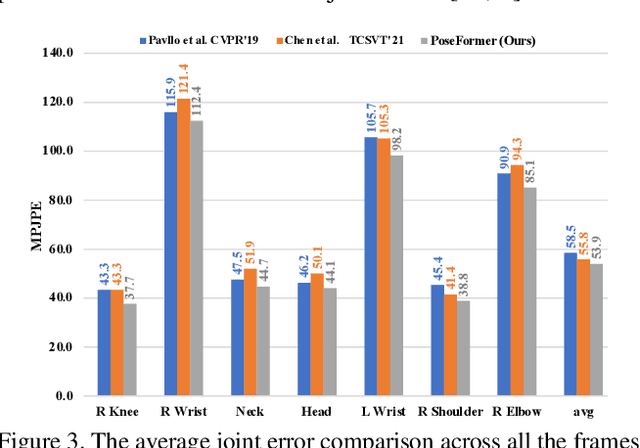
Transformer architectures have become the model of choice in natural language processing and are now being introduced into computer vision tasks such as image classification, object detection, and semantic segmentation. However, in the field of human pose estimation, convolutional architectures still remain dominant. In this work, we present PoseFormer, a purely transformer-based approach for 3D human pose estimation in videos without convolutional architectures involved. Inspired by recent developments in vision transformers, we design a spatial-temporal transformer structure to comprehensively model the human joint relations within each frame as well as the temporal correlations across frames, then output an accurate 3D human pose of the center frame. We quantitatively and qualitatively evaluate our method on two popular and standard benchmark datasets: Human3.6M and MPI-INF-3DHP. Extensive experiments show that PoseFormer achieves state-of-the-art performance on both datasets. Code is available at \url{https://github.com/zczcwh/PoseFormer}
Consistency-based Active Learning for Object Detection
Mar 23, 2021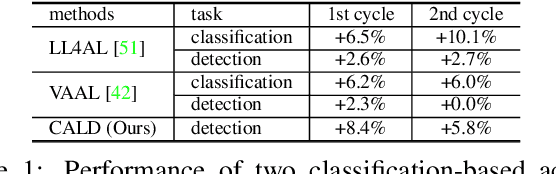
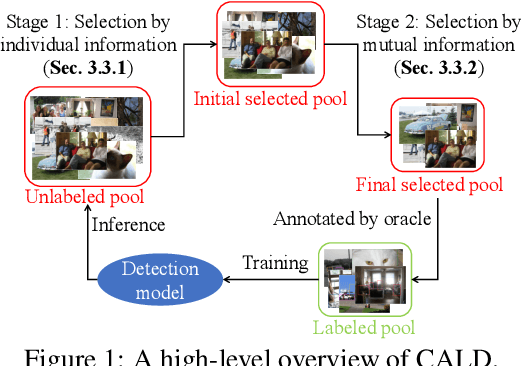
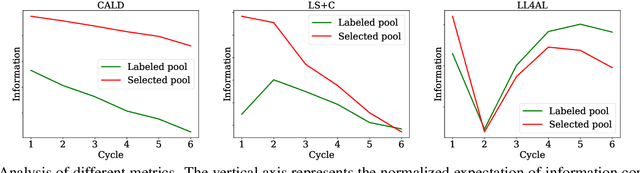
Active learning aims to improve the performance of task model by selecting the most informative samples with a limited budget. Unlike most recent works that focused on applying active learning for image classification, we propose an effective Consistency-based Active Learning method for object Detection (CALD), which fully explores the consistency between original and augmented data. CALD has three appealing benefits. (i) CALD is systematically designed by investigating the weaknesses of existing active learning methods, which do not take the unique challenges of object detection into account. (ii) CALD unifies box regression and classification with a single metric, which is not concerned by active learning methods for classification. CALD also focuses on the most informative local region rather than the whole image, which is beneficial for object detection. (iii) CALD not only gauges individual information for sample selection, but also leverages mutual information to encourage a balanced data distribution. Extensive experiments show that CALD significantly outperforms existing state-of-the-art task-agnostic and detection-specific active learning methods on general object detection datasets. Based on the Faster R-CNN detector, CALD consistently surpasses the baseline method (random selection) by 2.9/2.8/0.8 mAP on average on PASCAL VOC 2007, PASCAL VOC 2012, and MS COCO. Code is available at \url{https://github.com/we1pingyu/CALD}
Deep Learning-Based Human Pose Estimation: A Survey
Jan 02, 2021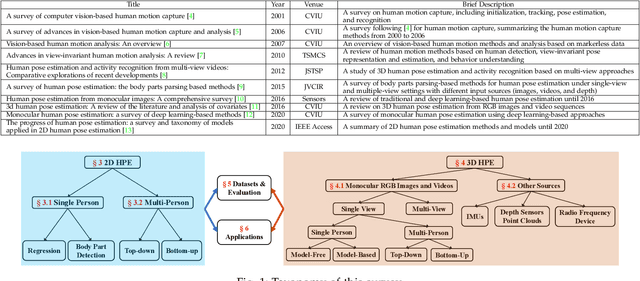
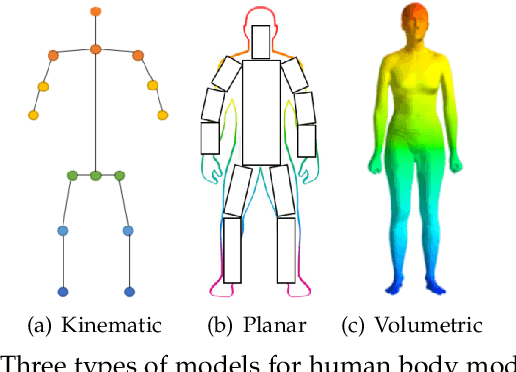
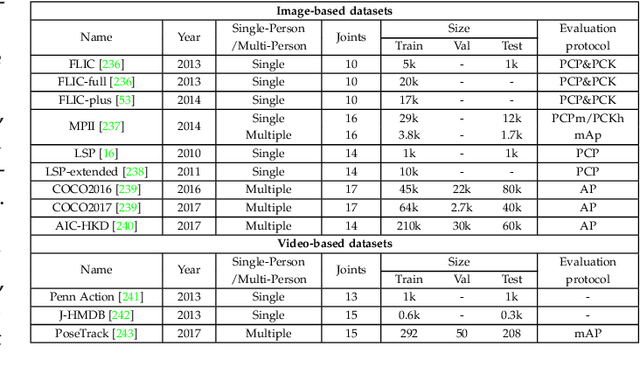
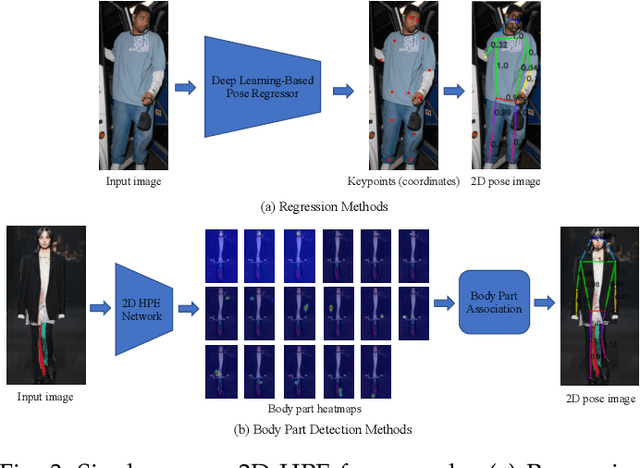
Human pose estimation aims to locate the human body parts and build human body representation (e.g., body skeleton) from input data such as images and videos. It has drawn increasing attention during the past decade and has been utilized in a wide range of applications including human-computer interaction, motion analysis, augmented reality, and virtual reality. Although the recently developed deep learning-based solutions have achieved high performance in human pose estimation, there still remain challenges due to insufficient training data, depth ambiguities, and occlusion. The goal of this survey paper is to provide a comprehensive review of recent deep learning-based solutions for both 2D and 3D pose estimation via a systematic analysis and comparison of these solutions based on their input data and inference procedures. More than 240 research papers since 2014 are covered in this survey. Furthermore, 2D and 3D human pose estimation datasets and evaluation metrics are included. Quantitative performance comparisons of the reviewed methods on popular datasets are summarized and discussed. Finally, the challenges involved, applications, and future research directions are concluded. We also provide a regularly updated project page: \url{https://github.com/zczcwh/DL-HPE}
A3D: Adaptive 3D Networks for Video Action Recognition
Nov 24, 2020
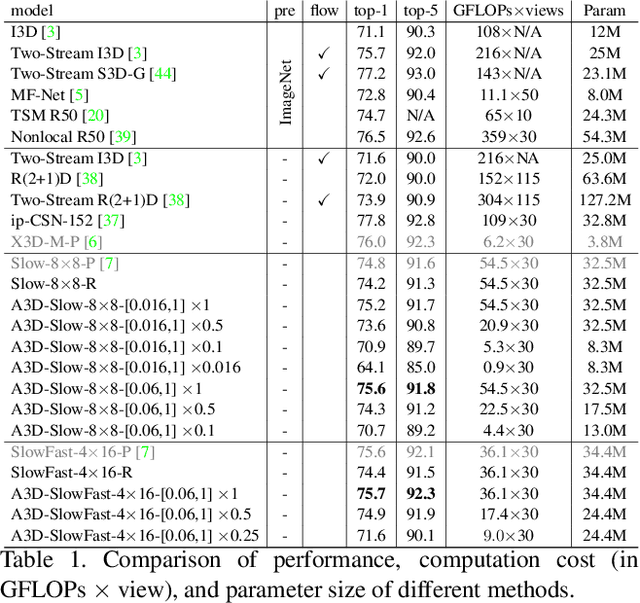
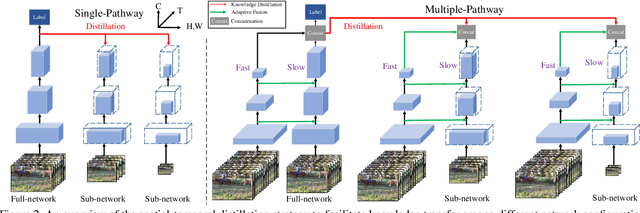

This paper presents A3D, an adaptive 3D network that can infer at a wide range of computational constraints with one-time training. Instead of training multiple models in a grid-search manner, it generates good configurations by trading off between network width and spatio-temporal resolution. Furthermore, the computation cost can be adapted after the model is deployed to meet variable constraints, for example, on edge devices. Even under the same computational constraints, the performance of our adaptive networks can be significantly boosted over the baseline counterparts by the mutual training along three dimensions. When a multiple pathway framework, e.g. SlowFast, is adopted, our adaptive method encourages a better trade-off between pathways than manual designs. Extensive experiments on the Kinetics dataset show the effectiveness of the proposed framework. The performance gain is also verified to transfer well between datasets and tasks. Code will be made available.
VIGOR: Cross-View Image Geo-localization beyond One-to-one Retrieval
Nov 24, 2020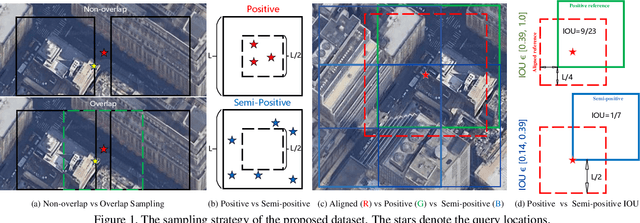
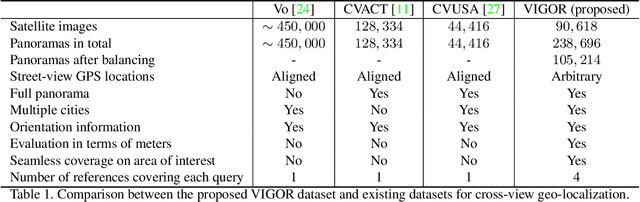
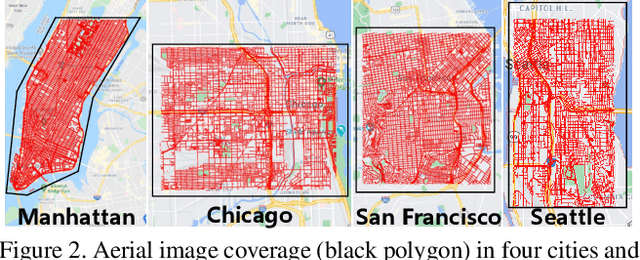
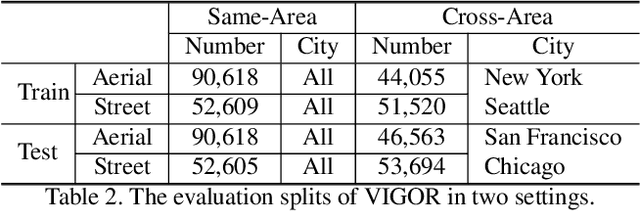
Cross-view image geo-localization aims to determine the locations of street-view query images by matching with GPS-tagged reference images from aerial view. Recent works have achieved surprisingly high retrieval accuracy on city-scale datasets. However, these results rely on the assumption that there exists a reference image exactly centered at the location of any query image, which is not applicable for practical scenarios. In this paper, we redefine this problem with a more realistic assumption that the query image can be arbitrary in the area of interest and the reference images are captured before the queries emerge. This assumption breaks the one-to-one retrieval setting of existing datasets as the queries and reference images are not perfectly aligned pairs, and there may be multiple reference images covering one query location. To bridge the gap between this realistic setting and existing datasets, we propose a new large-scale benchmark -- VIGOR -- for cross-View Image Geo-localization beyond One-to-one Retrieval. We benchmark existing state-of-the-art methods and propose a novel end-to-end framework to localize the query in a coarse-to-fine manner. Apart from the image-level retrieval accuracy, we also evaluate the localization accuracy in terms of the actual distance (meters) using the raw GPS data. Extensive experiments are conducted under different application scenarios to validate the effectiveness of the proposed method. The results indicate that cross-view geo-localization in this realistic setting is still challenging, fostering new research in this direction. Our dataset and code will be publicly available.
Cross-directional Feature Fusion Network for Building Damage Assessment from Satellite Imagery
Oct 27, 2020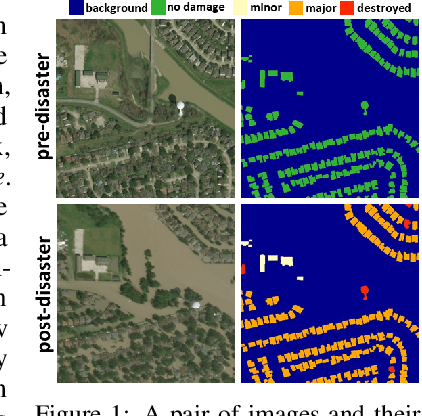
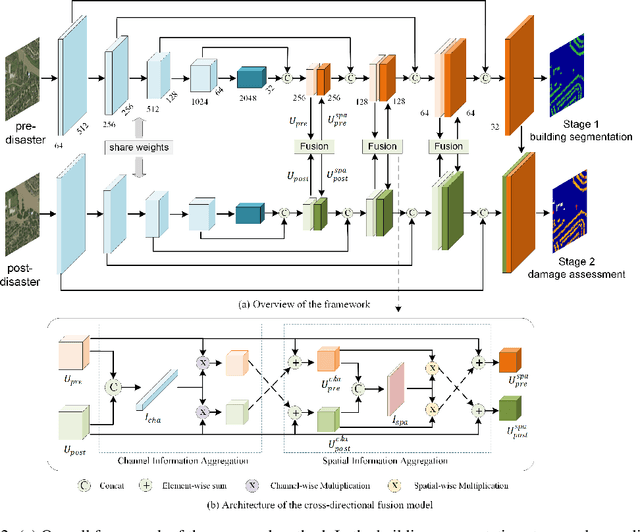
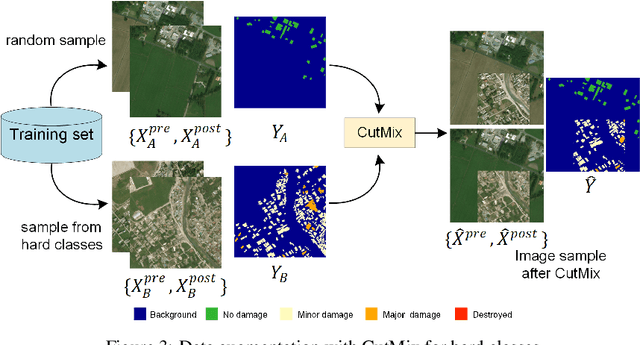

Fast and effective responses are required when a natural disaster (e.g., earthquake, hurricane, etc.) strikes. Building damage assessment from satellite imagery is critical before an effective response is conducted. High-resolution satellite images provide rich information with pre- and post-disaster scenes for analysis. However, most existing works simply use pre- and post-disaster images as input without considering their correlations. In this paper, we propose a novel cross-directional fusion strategy to better explore the correlations between pre- and post-disaster images. Moreover, the data augmentation method CutMix is exploited to tackle the challenge of hard classes. The proposed method achieves state-of-the-art performance on a large-scale building damage assessment dataset -- xBD.