 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Manifold Learning for No-Reference Image Quality Assessment
Jun 27, 2024



Contrastive learning has considerably advanced the field of Image Quality Assessment (IQA), emerging as a widely adopted technique. The core mechanism of contrastive learning involves minimizing the distance between quality-similar (positive) examples while maximizing the distance between quality-dissimilar (negative) examples. Despite its successes, current contrastive learning methods often neglect the importance of preserving the local manifold structure. This oversight can result in a high degree of similarity among hard examples within the feature space, thereby impeding effective differentiation and assessment. To address this issue, we propose an innovative framework that integrates local manifold learning with contrastive learning for No-Reference Image Quality Assessment (NR-IQA). Our method begins by sampling multiple crops from a given image, identifying the most visually salient crop. This crop is then used to cluster other crops from the same image as the positive class, while crops from different images are treated as negative classes to increase inter-class distance. Uniquely, our approach also considers non-saliency crops from the same image as intra-class negative classes to preserve their distinctiveness. Additionally, we employ a mutual learning framework, which further enhances the model's ability to adaptively learn and identify visual saliency regions. Our approach demonstrates a better performance compared to state-of-the-art methods in 7 standard datasets, achieving PLCC values of 0.942 (compared to 0.908 in TID2013) and 0.914 (compared to 0.894 in LIVEC).
More is Better: Deep Domain Adaptation with Multiple Sources
May 01, 2024In many practical applications, it is often difficult and expensive to obtain large-scale labeled data to train state-of-the-art deep neural networks. Therefore, transferring the learned knowledge from a separate, labeled source domain to an unlabeled or sparsely labeled target domain becomes an appealing alternative. However, direct transfer often results in significant performance decay due to domain shift. Domain adaptation (DA) aims to address this problem by aligning the distributions between the source and target domains. Multi-source domain adaptation (MDA) is a powerful and practical extension in which the labeled data may be collected from multiple sources with different distributions. In this survey, we first define various MDA strategies. Then we systematically summarize and compare modern MDA methods in the deep learning era from different perspectives, followed by commonly used datasets and a brief benchmark. Finally, we discuss future research directions for MDA that are worth investigating.
Re-parameterized Low-rank Prompt: Generalize a Vision-Language Model within 0.5K Parameters
Dec 17, 2023



With the development of large pre-trained vision-language models, how to effectively transfer the knowledge of such foundational models to downstream tasks becomes a hot topic, especially in a data-deficient scenario. Recently, prompt tuning has become a popular solution. When adapting the vision-language models, researchers freeze the parameters in the backbone and only design and tune the prompts. On the one hand, the delicate design of prompt tuning exhibits strong performance. On the other hand, complicated structures and update rules largely increase the computation and storage cost. Motivated by the observation that the evolution pattern of the generalization capability in visual-language models aligns harmoniously with the trend of rank variations in the prompt matrix during adaptation, we design a new type of prompt, Re-parameterized Low-rank Prompt (RLP), for both efficient and effective adaptation. Our method could largely reduce the number of tunable parameters and storage space, which is quite beneficial in resource-limited scenarios. Extensive experiments further demonstrate the superiority of RLP. In particular, RLP shows comparable or even stronger performance than the latest state-of-the-art methods with an extremely small number of parameters. On a series of tasks over 11 datasets, RLP significantly increases the average downstream accuracy of classic prompt tuning by up to 5.25% using merely 0.5K parameters.
MACP: Efficient Model Adaptation for Cooperative Perception
Nov 07, 2023Vehicle-to-vehicle (V2V) communications have greatly enhanced the perception capabilities of connected and automated vehicles (CAVs) by enabling information sharing to "see through the occlusions", resulting in significant performance improvements. However, developing and training complex multi-agent perception models from scratch can be expensive and unnecessary when existing single-agent models show remarkable generalization capabilities. In this paper, we propose a new framework termed MACP, which equips a single-agent pre-trained model with cooperation capabilities. We approach this objective by identifying the key challenges of shifting from single-agent to cooperative settings, adapting the model by freezing most of its parameters and adding a few lightweight modules. We demonstrate in our experiments that the proposed framework can effectively utilize cooperative observations and outperform other state-of-the-art approaches in both simulated and real-world cooperative perception benchmarks while requiring substantially fewer tunable parameters with reduced communication costs. Our source code is available at https://github.com/PurdueDigitalTwin/MACP.
Confidence-based Visual Dispersal for Few-shot Unsupervised Domain Adaptation
Sep 29, 2023



Unsupervised domain adaptation aims to transfer knowledge from a fully-labeled source domain to an unlabeled target domain. However, in real-world scenarios, providing abundant labeled data even in the source domain can be infeasible due to the difficulty and high expense of annotation. To address this issue, recent works consider the Few-shot Unsupervised Domain Adaptation (FUDA) where only a few source samples are labeled, and conduct knowledge transfer via self-supervised learning methods. Yet existing methods generally overlook that the sparse label setting hinders learning reliable source knowledge for transfer. Additionally, the learning difficulty difference in target samples is different but ignored, leaving hard target samples poorly classified. To tackle both deficiencies, in this paper, we propose a novel Confidence-based Visual Dispersal Transfer learning method (C-VisDiT) for FUDA. Specifically, C-VisDiT consists of a cross-domain visual dispersal strategy that transfers only high-confidence source knowledge for model adaptation and an intra-domain visual dispersal strategy that guides the learning of hard target samples with easy ones. We conduct extensive experiments on Office-31, Office-Home, VisDA-C, and DomainNet benchmark datasets and the results demonstrate that the proposed C-VisDiT significantly outperforms state-of-the-art FUDA methods. Our code is available at https://github.com/Bostoncake/C-VisDiT.
CAIT: Triple-Win Compression towards High Accuracy, Fast Inference, and Favorable Transferability For ViTs
Sep 27, 2023



Vision Transformers (ViTs) have emerged as state-of-the-art models for various vision tasks recently. However, their heavy computation costs remain daunting for resource-limited devices. Consequently, researchers have dedicated themselves to compressing redundant information in ViTs for acceleration. However, they generally sparsely drop redundant image tokens by token pruning or brutally remove channels by channel pruning, leading to a sub-optimal balance between model performance and inference speed. They are also disadvantageous in transferring compressed models to downstream vision tasks that require the spatial structure of images, such as semantic segmentation. To tackle these issues, we propose a joint compression method for ViTs that offers both high accuracy and fast inference speed, while also maintaining favorable transferability to downstream tasks (CAIT). Specifically, we introduce an asymmetric token merging (ATME) strategy to effectively integrate neighboring tokens. It can successfully compress redundant token information while preserving the spatial structure of images. We further employ a consistent dynamic channel pruning (CDCP) strategy to dynamically prune unimportant channels in ViTs. Thanks to CDCP, insignificant channels in multi-head self-attention modules of ViTs can be pruned uniformly, greatly enhancing the model compression. Extensive experiments on benchmark datasets demonstrate that our proposed method can achieve state-of-the-art performance across various ViTs. For example, our pruned DeiT-Tiny and DeiT-Small achieve speedups of 1.7$\times$ and 1.9$\times$, respectively, without accuracy drops on ImageNet. On the ADE20k segmentation dataset, our method can enjoy up to 1.31$\times$ speedups with comparable mIoU. Our code will be publicly available.
Dynamic Causal Disentanglement Model for Dialogue Emotion Detection
Sep 13, 2023



Emotion detection is a critical technology extensively employed in diverse fields. While the incorporation of commonsense knowledge has proven beneficial for existing emotion detection methods, dialogue-based emotion detection encounters numerous difficulties and challenges due to human agency and the variability of dialogue content.In dialogues, human emotions tend to accumulate in bursts. However, they are often implicitly expressed. This implies that many genuine emotions remain concealed within a plethora of unrelated words and dialogues.In this paper, we propose a Dynamic Causal Disentanglement Model based on hidden variable separation, which is founded on the separation of hidden variables. This model effectively decomposes the content of dialogues and investigates the temporal accumulation of emotions, thereby enabling more precise emotion recognition. First, we introduce a novel Causal Directed Acyclic Graph (DAG) to establish the correlation between hidden emotional information and other observed elements. Subsequently, our approach utilizes pre-extracted personal attributes and utterance topics as guiding factors for the distribution of hidden variables, aiming to separate irrelevant ones. Specifically, we propose a dynamic temporal disentanglement model to infer the propagation of utterances and hidden variables, enabling the accumulation of emotion-related information throughout the conversation. To guide this disentanglement process, we leverage the ChatGPT-4.0 and LSTM networks to extract utterance topics and personal attributes as observed information.Finally, we test our approach on two popular datasets in dialogue emotion detection and relevant experimental results verified the model's superiority.
Unlocking the Emotional World of Visual Media: An Overview of the Science, Research, and Impact of Understanding Emotion
Jul 25, 2023



The emergence of artificial emotional intelligence technology is revolutionizing the fields of computers and robotics, allowing for a new level of communication and understanding of human behavior that was once thought impossible. While recent advancements in deep learning have transformed the field of computer vision, automated understanding of evoked or expressed emotions in visual media remains in its infancy. This foundering stems from the absence of a universally accepted definition of "emotion", coupled with the inherently subjective nature of emotions and their intricate nuances. In this article, we provide a comprehensive, multidisciplinary overview of the field of emotion analysis in visual media, drawing on insights from psychology, engineering, and the arts. We begin by exploring the psychological foundations of emotion and the computational principles that underpin the understanding of emotions from images and videos. We then review the latest research and systems within the field, accentuating the most promising approaches. We also discuss the current technological challenges and limitations of emotion analysis, underscoring the necessity for continued investigation and innovation. We contend that this represents a "Holy Grail" research problem in computing and delineate pivotal directions for future inquiry. Finally, we examine the ethical ramifications of emotion-understanding technologies and contemplate their potential societal impacts. Overall, this article endeavors to equip readers with a deeper understanding of the domain of emotion analysis in visual media and to inspire further research and development in this captivating and rapidly evolving field.
2nd Place Solution for VisDA 2021 Challenge -- Universally Domain Adaptive Image Recognition
Oct 27, 2021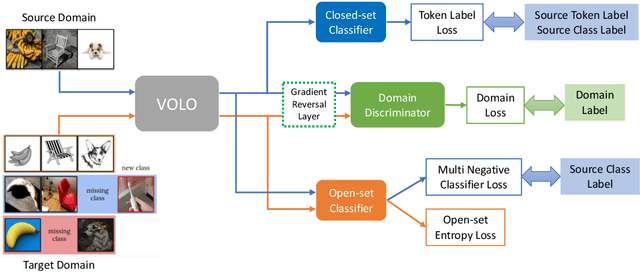
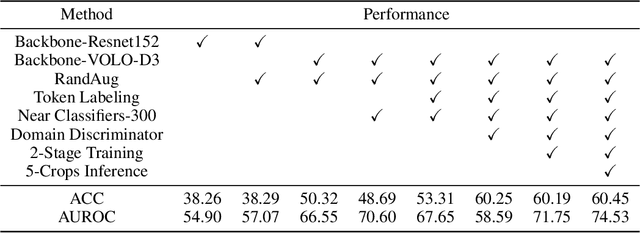
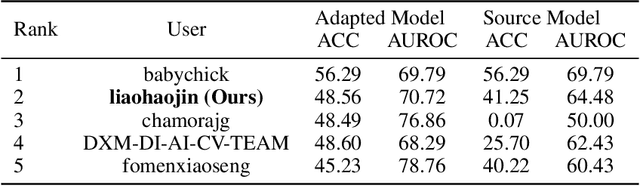
The Visual Domain Adaptation (VisDA) 2021 Challenge calls for unsupervised domain adaptation (UDA) methods that can deal with both input distribution shift and label set variance between the source and target domains. In this report, we introduce a universal domain adaptation (UniDA) method by aggregating several popular feature extraction and domain adaptation schemes. First, we utilize VOLO, a Transformer-based architecture with state-of-the-art performance in several visual tasks, as the backbone to extract effective feature representations. Second, we modify the open-set classifier of OVANet to recognize the unknown class with competitive accuracy and robustness. As shown in the leaderboard, our proposed UniDA method ranks the 2nd place with 48.56% ACC and 70.72% AUROC in the VisDA 2021 Challenge.
Emotion Recognition from Multiple Modalities: Fundamentals and Methodologies
Aug 18, 2021
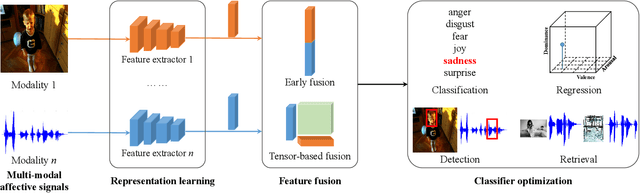
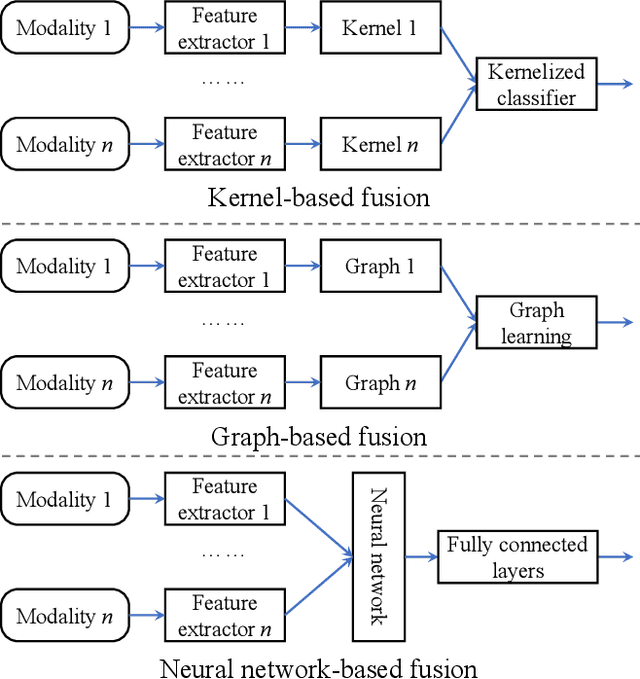
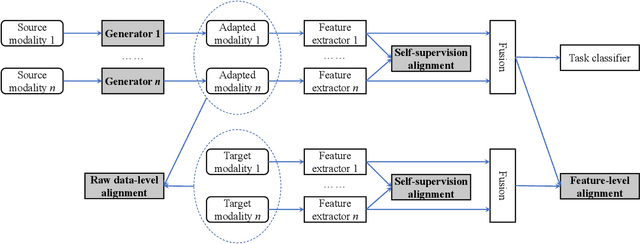
Humans are emotional creatures. Multiple modalities are often involved when we express emotions, whether we do so explicitly (e.g., facial expression, speech) or implicitly (e.g., text, image). Enabling machines to have emotional intelligence, i.e., recognizing, interpreting, processing, and simulating emotions, is becoming increasingly important. In this tutorial, we discuss several key aspects of multi-modal emotion recognition (MER). We begin with a brief introduction on widely used emotion representation models and affective modalities. We then summarize existing emotion annotation strategies and corresponding computational tasks, followed by the description of main challenges in MER. Furthermore, we present some representative approaches on representation learning of each affective modality, feature fusion of different affective modalities, classifier optimization for MER, and domain adaptation for MER. Finally, we outline several real-world applications and discuss some future directions.