 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContour Transformer Network for One-shot Segmentation of Anatomical Structures
Dec 02, 2020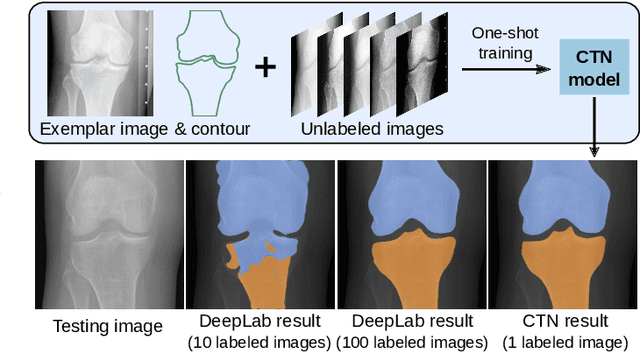
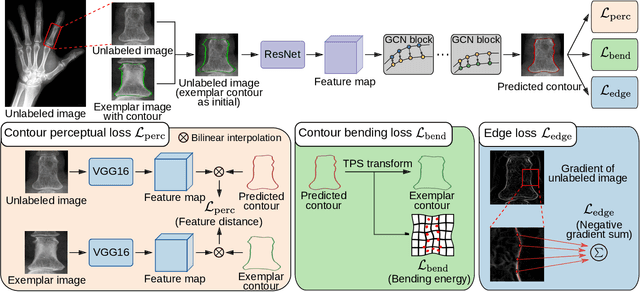
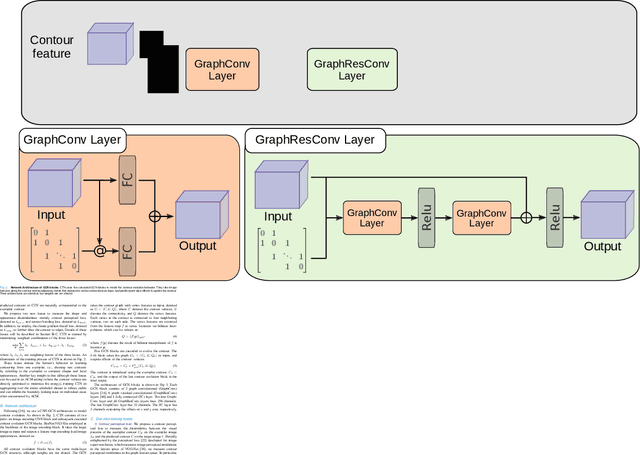
Accurate segmentation of anatomical structures is vital for medical image analysis. The state-of-the-art accuracy is typically achieved by supervised learning methods, where gathering the requisite expert-labeled image annotations in a scalable manner remains a main obstacle. Therefore, annotation-efficient methods that permit to produce accurate anatomical structure segmentation are highly desirable. In this work, we present Contour Transformer Network (CTN), a one-shot anatomy segmentation method with a naturally built-in human-in-the-loop mechanism. We formulate anatomy segmentation as a contour evolution process and model the evolution behavior by graph convolutional networks (GCNs). Training the CTN model requires only one labeled image exemplar and leverages additional unlabeled data through newly introduced loss functions that measure the global shape and appearance consistency of contours. On segmentation tasks of four different anatomies, we demonstrate that our one-shot learning method significantly outperforms non-learning-based methods and performs competitively to the state-of-the-art fully supervised deep learning methods. With minimal human-in-the-loop editing feedback, the segmentation performance can be further improved to surpass the fully supervised methods.
Deep Hiearchical Multi-Label Classification Applied to Chest X-Ray Abnormality Taxonomies
Sep 23, 2020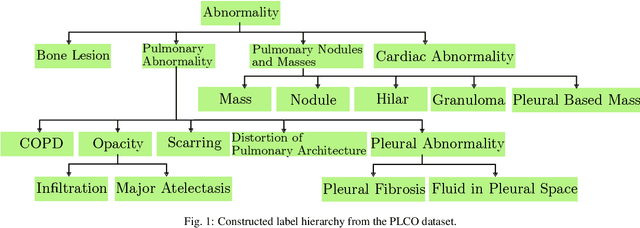
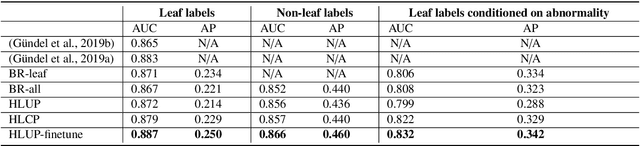
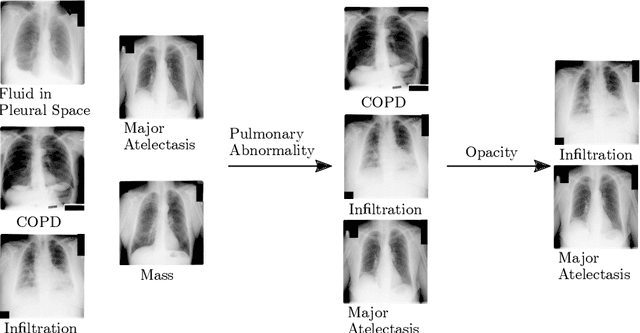
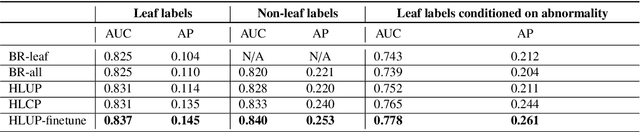
CXRs are a crucial and extraordinarily common diagnostic tool, leading to heavy research for CAD solutions. However, both high classification accuracy and meaningful model predictions that respect and incorporate clinical taxonomies are crucial for CAD usability. To this end, we present a deep HMLC approach for CXR CAD. Different than other hierarchical systems, we show that first training the network to model conditional probability directly and then refining it with unconditional probabilities is key in boosting performance. In addition, we also formulate a numerically stable cross-entropy loss function for unconditional probabilities that provides concrete performance improvements. Finally, we demonstrate that HMLC can be an effective means to manage missing or incomplete labels. To the best of our knowledge, we are the first to apply HMLC to medical imaging CAD. We extensively evaluate our approach on detecting abnormality labels from the CXR arm of the PLCO dataset, which comprises over $198,000$ manually annotated CXRs. When using complete labels, we report a mean AUC of 0.887, the highest yet reported for this dataset. These results are supported by ancillary experiments on the PadChest dataset, where we also report significant improvements, 1.2% and 4.1% in AUC and AP, respectively over strong "flat" classifiers. Finally, we demonstrate that our HMLC approach can much better handle incompletely labelled data. These performance improvements, combined with the inherent usefulness of taxonomic predictions, indicate that our approach represents a useful step forward for CXR CAD.
Anatomy-Aware Siamese Network: Exploiting Semantic Asymmetry for Accurate Pelvic Fracture Detection in X-ray Images
Jul 12, 2020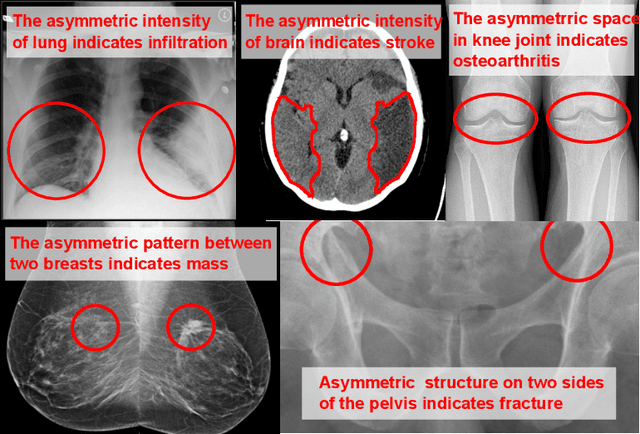
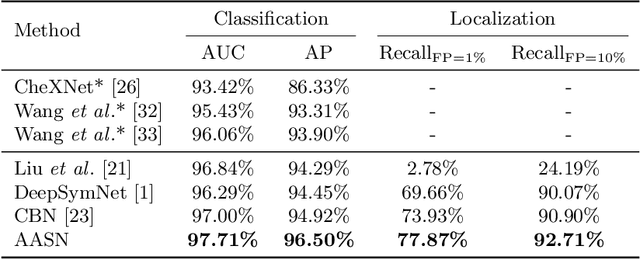
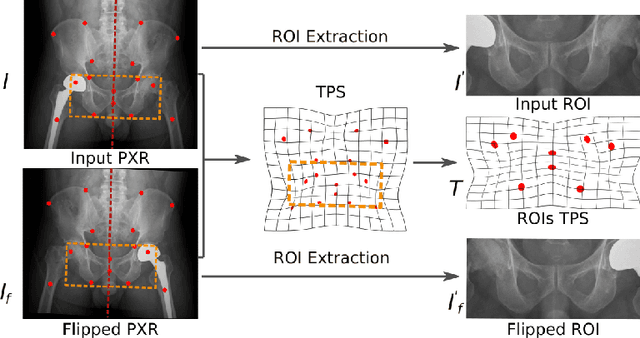
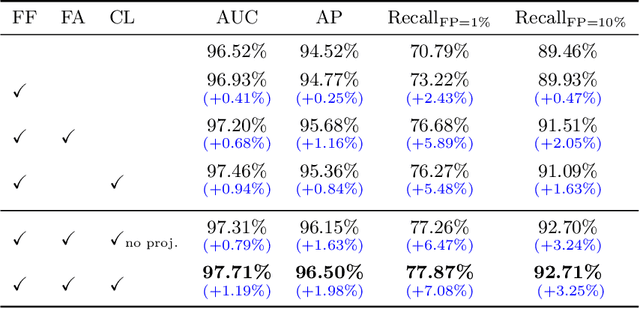
Visual cues of enforcing bilaterally symmetric anatomies as normal findings are widely used in clinical practice to disambiguate subtle abnormalities from medical images. So far, inadequate research attention has been received on effectively emulating this practice in CAD methods. In this work, we exploit semantic anatomical symmetry or asymmetry analysis in a complex CAD scenario, i.e., anterior pelvic fracture detection in trauma PXRs, where semantically pathological (refer to as fracture) and non-pathological (e.g., pose) asymmetries both occur. Visually subtle yet pathologically critical fracture sites can be missed even by experienced clinicians, when limited diagnosis time is permitted in emergency care. We propose a novel fracture detection framework that builds upon a Siamese network enhanced with a spatial transformer layer to holistically analyze symmetric image features. Image features are spatially formatted to encode bilaterally symmetric anatomies. A new contrastive feature learning component in our Siamese network is designed to optimize the deep image features being more salient corresponding to the underlying semantic asymmetries (caused by pelvic fracture occurrences). Our proposed method have been extensively evaluated on 2,359 PXRs from unique patients (the largest study to-date), and report an area under ROC curve score of 0.9771. This is the highest among state-of-the-art fracture detection methods, with improved clinical indications.
Learning to Segment Anatomical Structures Accurately from One Exemplar
Jul 08, 2020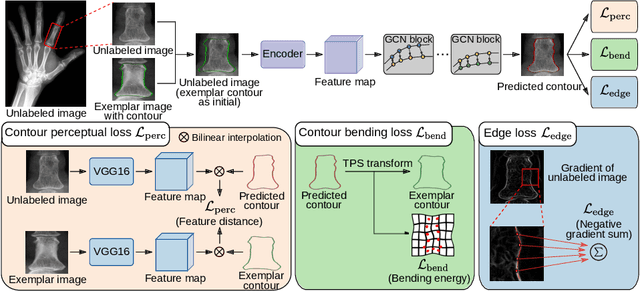
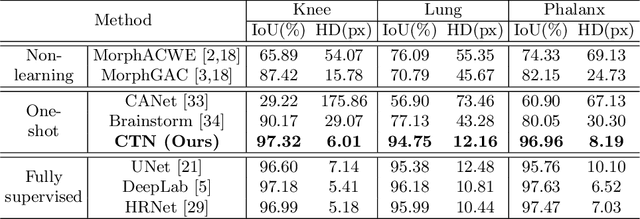
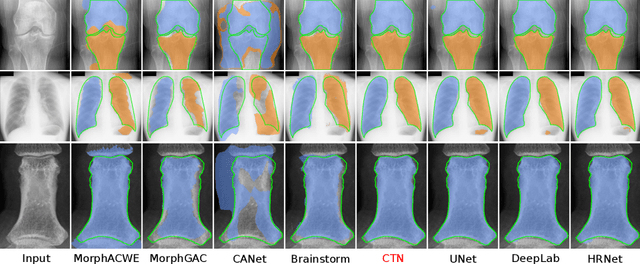

Accurate segmentation of critical anatomical structures is at the core of medical image analysis. The main bottleneck lies in gathering the requisite expert-labeled image annotations in a scalable manner. Methods that permit to produce accurate anatomical structure segmentation without using a large amount of fully annotated training images are highly desirable. In this work, we propose a novel contribution of Contour Transformer Network (CTN), a one-shot anatomy segmentor including a naturally built-in human-in-the-loop mechanism. Segmentation is formulated by learning a contour evolution behavior process based on graph convolutional networks (GCNs). Training of our CTN model requires only one labeled image exemplar and leverages additional unlabeled data through newly introduced loss functions that measure the global shape and appearance consistency of contours. We demonstrate that our one-shot learning method significantly outperforms non-learning-based methods and performs competitively to the state-of-the-art fully supervised deep learning approaches. With minimal human-in-the-loop editing feedback, the segmentation performance can be further improved and tailored towards the observer desired outcomes. This can facilitate the clinician designed imaging-based biomarker assessments (to support personalized quantitative clinical diagnosis) and outperforms fully supervised baselines.
Structured Landmark Detection via Topology-Adapting Deep Graph Learning
Apr 23, 2020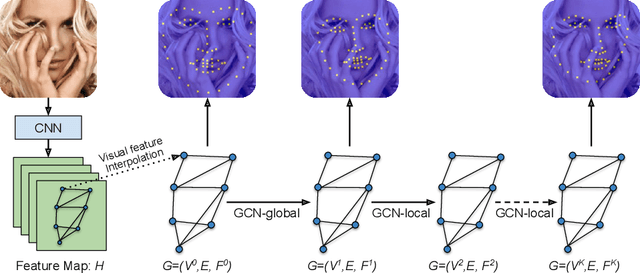
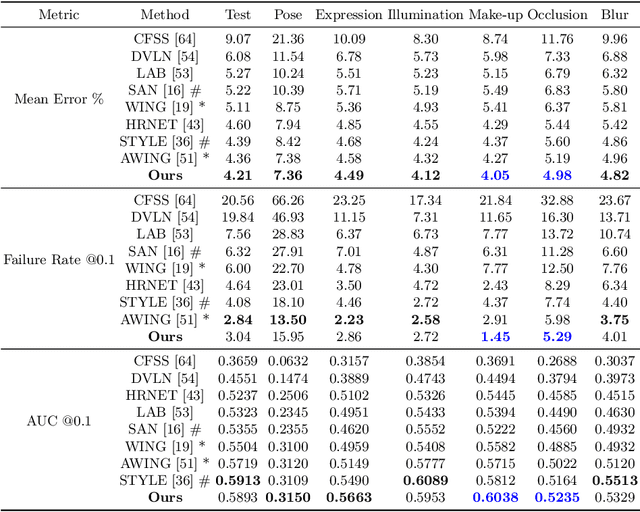

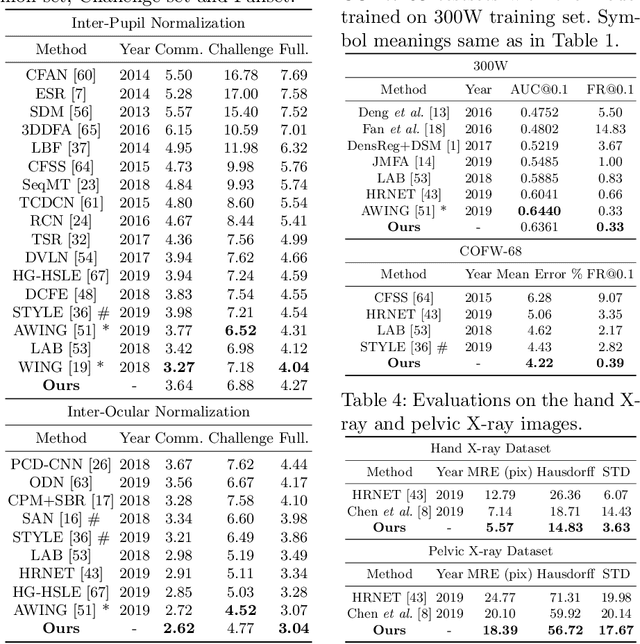
Image landmark detection aims to automatically identify the locations of predefined fiducial points. Despite recent success in this filed, higher-ordered structural modeling to capture implicit or explicit relationships among anatomical landmarks has not been adequately exploited. In this work, we present a new topology-adapting deep graph learning approach for accurate anatomical facial and medical (e.g., hand, pelvis) landmark detection. The proposed method constructs graph signals leveraging both local image features and global shape features. The adaptive graph topology naturally explores and lands on task-specific structures which is learned end-to-end with two Graph Convolutional Networks (GCNs). Extensive experiments are conducted on three public facial image datasets (WFLW, 300W and COFW-68) as well as three real-world X-ray medical datasets (Cephalometric (public), Hand and Pelvis). Quantitative results comparing with the previous state-of-the-art approaches across all studied datasets indicating the superior performance in both robustness and accuracy. Qualitative visualizations of the learned graph topologies demonstrate a physically plausible connectivity laying behind the landmarks.
Unsupervised Learning of Landmarks based on Inter-Intra Subject Consistencies
Apr 16, 2020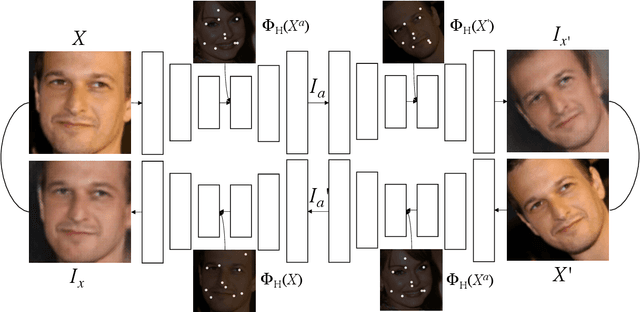

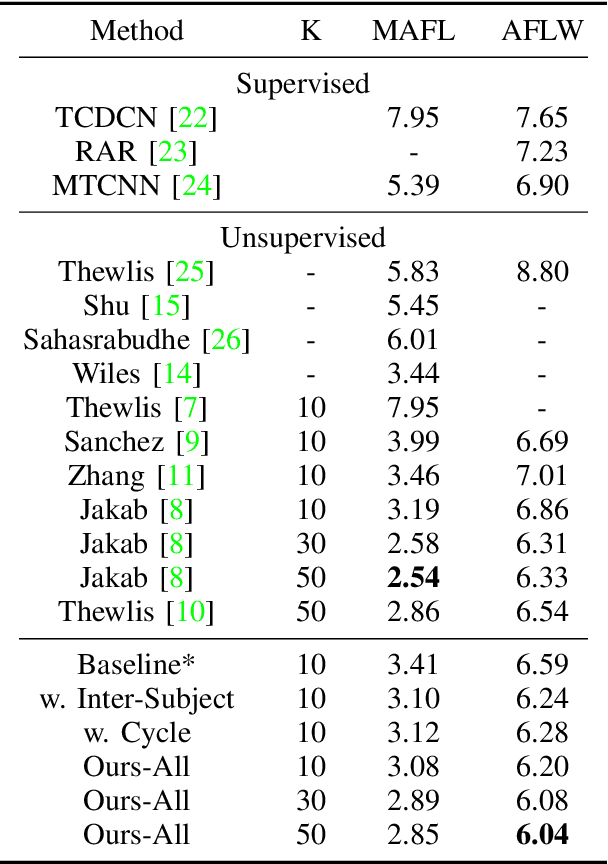
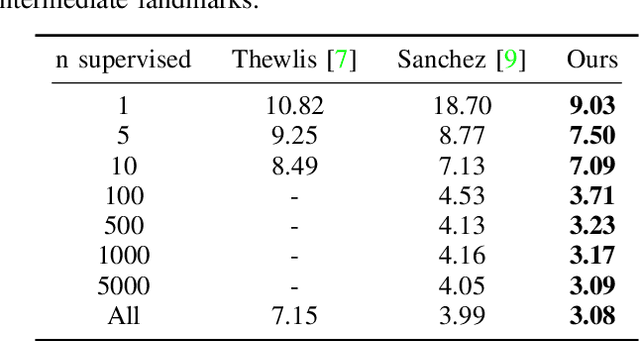
We present a novel unsupervised learning approach to image landmark discovery by incorporating the inter-subject landmark consistencies on facial images. This is achieved via an inter-subject mapping module that transforms original subject landmarks based on an auxiliary subject-related structure. To recover from the transformed images back to the original subject, the landmark detector is forced to learn spatial locations that contain the consistent semantic meanings both for the paired intra-subject images and between the paired inter-subject images. Our proposed method is extensively evaluated on two public facial image datasets (MAFL, AFLW) with various settings. Experimental results indicate that our method can extract the consistent landmarks for both datasets and achieve better performances compared to the previous state-of-the-art methods quantitatively and qualitatively.
Weakly Supervised Universal Fracture Detection in Pelvic X-rays
Sep 04, 2019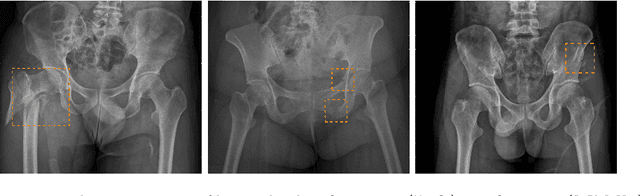
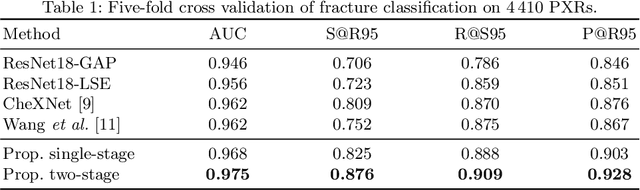
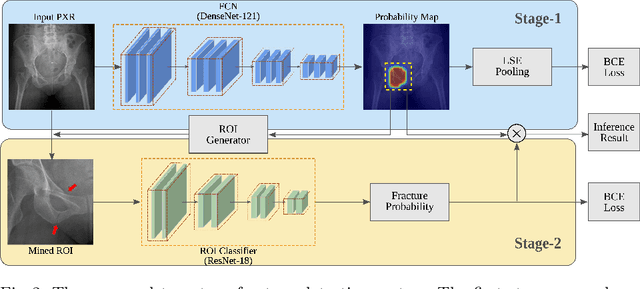
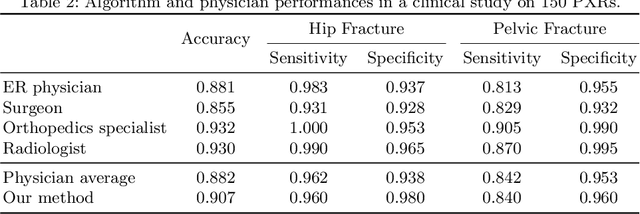
Hip and pelvic fractures are serious injuries with life-threatening complications. However, diagnostic errors of fractures in pelvic X-rays (PXRs) are very common, driving the demand for computer-aided diagnosis (CAD) solutions. A major challenge lies in the fact that fractures are localized patterns that require localized analyses. Unfortunately, the PXRs residing in hospital picture archiving and communication system do not typically specify region of interests. In this paper, we propose a two-stage hip and pelvic fracture detection method that executes localized fracture classification using weakly supervised ROI mining. The first stage uses a large capacity fully-convolutional network, i.e., deep with high levels of abstraction, in a multiple instance learning setting to automatically mine probable true positive and definite hard negative ROIs from the whole PXR in the training data. The second stage trains a smaller capacity model, i.e., shallower and more generalizable, with the mined ROIs to perform localized analyses to classify fractures. During inference, our method detects hip and pelvic fractures in one pass by chaining the probability outputs of the two stages together. We evaluate our method on 4 410 PXRs, reporting an area under the ROC curve value of 0.975, the highest among state-of-the-art fracture detection methods. Moreover, we show that our two-stage approach can perform comparably to human physicians (even outperforming emergency physicians and surgeons), in a preliminary reader study of 23 readers.
Task Driven Generative Modeling for Unsupervised Domain Adaptation: Application to X-ray Image Segmentation
Jun 11, 2018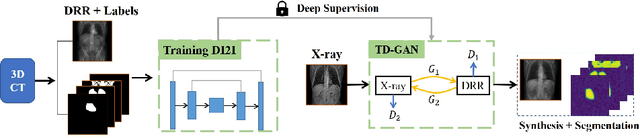
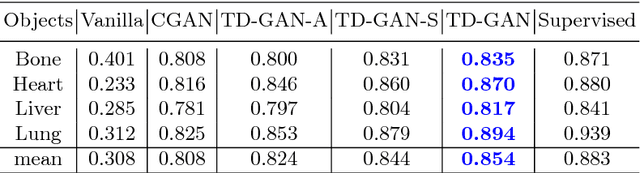
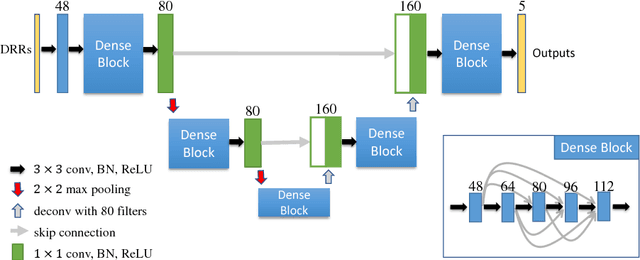
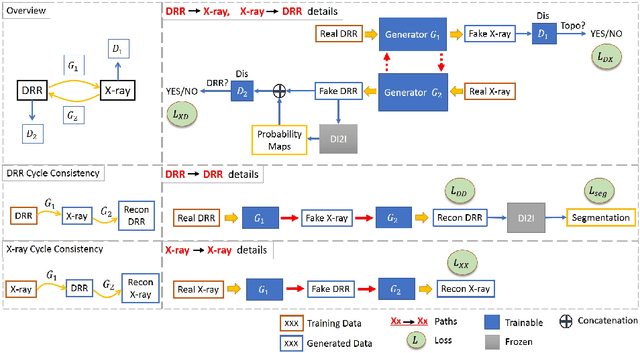
Automatic parsing of anatomical objects in X-ray images is critical to many clinical applications in particular towards image-guided invention and workflow automation. Existing deep network models require a large amount of labeled data. However, obtaining accurate pixel-wise labeling in X-ray images relies heavily on skilled clinicians due to the large overlaps of anatomy and the complex texture patterns. On the other hand, organs in 3D CT scans preserve clearer structures as well as sharper boundaries and thus can be easily delineated. In this paper, we propose a novel model framework for learning automatic X-ray image parsing from labeled CT scans. Specifically, a Dense Image-to-Image network (DI2I) for multi-organ segmentation is first trained on X-ray like Digitally Reconstructed Radiographs (DRRs) rendered from 3D CT volumes. Then we introduce a Task Driven Generative Adversarial Network (TD-GAN) architecture to achieve simultaneous style transfer and parsing for unseen real X-ray images. TD-GAN consists of a modified cycle-GAN substructure for pixel-to-pixel translation between DRRs and X-ray images and an added module leveraging the pre-trained DI2I to enforce segmentation consistency. The TD-GAN framework is general and can be easily adapted to other learning tasks. In the numerical experiments, we validate the proposed model on 815 DRRs and 153 topograms. While the vanilla DI2I without any adaptation fails completely on segmenting the topograms, the proposed model does not require any topogram labels and is able to provide a promising average dice of 85% which achieves the same level accuracy of supervised training (88%).
Dilated FCN for Multi-Agent 2D/3D Medical Image Registration
Nov 22, 2017
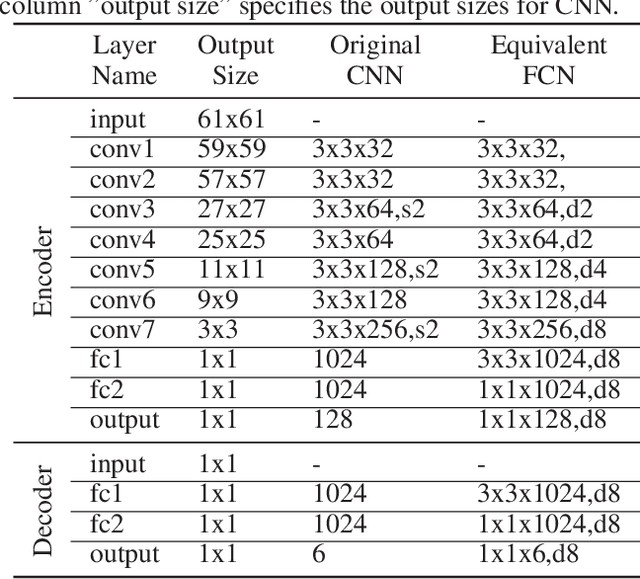

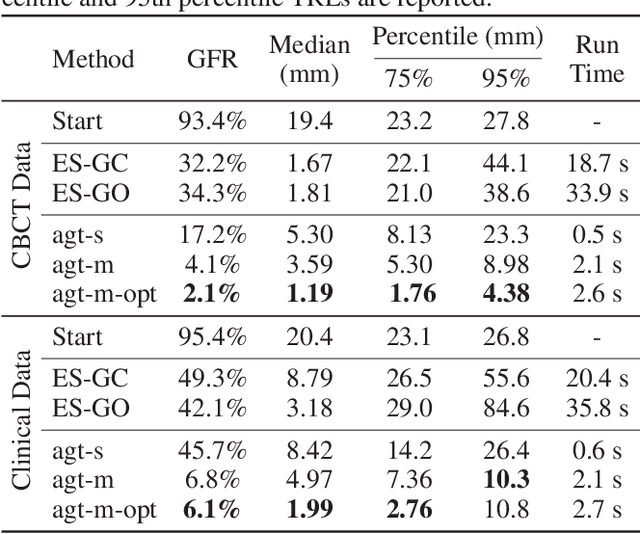
2D/3D image registration to align a 3D volume and 2D X-ray images is a challenging problem due to its ill-posed nature and various artifacts presented in 2D X-ray images. In this paper, we propose a multi-agent system with an auto attention mechanism for robust and efficient 2D/3D image registration. Specifically, an individual agent is trained with dilated Fully Convolutional Network (FCN) to perform registration in a Markov Decision Process (MDP) by observing a local region, and the final action is then taken based on the proposals from multiple agents and weighted by their corresponding confidence levels. The contributions of this paper are threefold. First, we formulate 2D/3D registration as a MDP with observations, actions, and rewards properly defined with respect to X-ray imaging systems. Second, to handle various artifacts in 2D X-ray images, multiple local agents are employed efficiently via FCN-based structures, and an auto attention mechanism is proposed to favor the proposals from regions with more reliable visual cues. Third, a dilated FCN-based training mechanism is proposed to significantly reduce the Degree of Freedom in the simulation of registration environment, and drastically improve training efficiency by an order of magnitude compared to standard CNN-based training method. We demonstrate that the proposed method achieves high robustness on both spine cone beam Computed Tomography data with a low signal-to-noise ratio and data from minimally invasive spine surgery where severe image artifacts and occlusions are presented due to metal screws and guide wires, outperforming other state-of-the-art methods (single agent-based and optimization-based) by a large margin.
An Artificial Agent for Robust Image Registration
Nov 30, 2016
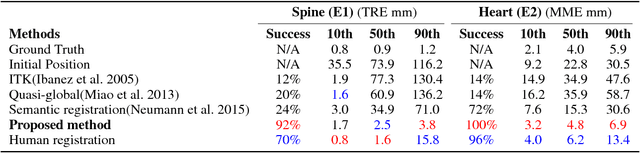
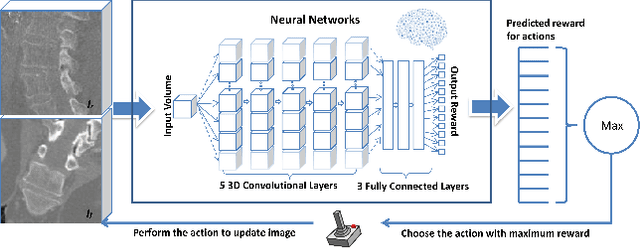

3-D image registration, which involves aligning two or more images, is a critical step in a variety of medical applications from diagnosis to therapy. Image registration is commonly performed by optimizing an image matching metric as a cost function. However, this task is challenging due to the non-convex nature of the matching metric over the plausible registration parameter space and insufficient approaches for a robust optimization. As a result, current approaches are often customized to a specific problem and sensitive to image quality and artifacts. In this paper, we propose a completely different approach to image registration, inspired by how experts perform the task. We first cast the image registration problem as a "strategy learning" process, where the goal is to find the best sequence of motion actions (e.g. up, down, etc.) that yields image alignment. Within this approach, an artificial agent is learned, modeled using deep convolutional neural networks, with 3D raw image data as the input, and the next optimal action as the output. To cope with the dimensionality of the problem, we propose a greedy supervised approach for an end-to-end training, coupled with attention-driven hierarchical strategy. The resulting registration approach inherently encodes both a data-driven matching metric and an optimal registration strategy (policy). We demonstrate, on two 3-D/3-D medical image registration examples with drastically different nature of challenges, that the artificial agent outperforms several state-of-art registration methods by a large margin in terms of both accuracy and robustness.