 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize Radiotherapy Plans via Fluence Maps Diffusion Model Generation and LSTM-based Optimization
May 13, 2026Volumetric Modulated Arc Therapy (VMAT) is a cornerstone of modern radiation therapy, enabling highly conformal tumor irradiation and healthy-tissue sparing. Yet, its planning solves inverse and nested optimization for multi-leaf collimators, monitor units and dose parameters, while enforcing their consistency to ensure mechanical deliverability. Nevertheless, this process often requires repeated re-optimization when treatment configurations change, resulting in substantial planning time per patient. To address these problems, we present a diffusion-driven Learning-to-Optimize (L2O) method for end-to-end VMAT planning. A distribution-matching distilled diffusion model learns a clinically feasible manifold of fluence maps, enabling their one-shot generation. On top of this, an LSTM-based L2O module learns gradient update dynamics to swiftly refine fluence maps toward prescribed dose objectives during inference. Experimental results on clinical and public prostate cancer cohorts demonstrate improved planning efficiency, flexibility, and machine deliverability over currently available end-to-end VMAT planners.
Any2Any 3D Diffusion Models with Knowledge Transfer: A Radiotherapy Planning Study
May 10, 2026Voxel-wise dose prediction is a critical yet challenging task in practical radiotherapy (RT) planning, as bespoke models trained from scratch often struggle to generalize across diverse clinical settings. Meanwhile, generative models trained on billion-scale datasets from vision domains have achieved impressive performance. Herein, we propose DiffKT3D, a unified Any2Any 3D diffusion framework that leverages prior knowledge from pretrained video diffusion models for efficient and clinically meaningful dose prediction. To enable flexible conditioning across multiple clinical modalities (CT, anatomical structures, body, beam settings, etc.), we introduce an Any2Any conditional paradigm utilizing modality-specific embeddings without cross-attention overhead. Further, we design a novel reinforcement learning (RL) post-training mechanism guided by a clinically-informed Scorecard explicitly tailored to institutional treatment preferences. Compared with winner of GDP-HMM challenge, DiffKT3D sets a new state-of-the-art in dose prediction by reducing voxel-level MAE from 2.07 to 1.93. In addition, DiffKT3D achieves superior image quality and preference match. These results demonstrate that transferring diffusion priors via modality-aware conditioning and clinically aligned RL post-training can provide a robust and generalizable solution for RT planning across various clinical scenarios.
Demo: Generative AI helps Radiotherapy Planning with User Preference
Dec 08, 2025Radiotherapy planning is a highly complex process that often varies significantly across institutions and individual planners. Most existing deep learning approaches for 3D dose prediction rely on reference plans as ground truth during training, which can inadvertently bias models toward specific planning styles or institutional preferences. In this study, we introduce a novel generative model that predicts 3D dose distributions based solely on user-defined preference flavors. These customizable preferences enable planners to prioritize specific trade-offs between organs-at-risk (OARs) and planning target volumes (PTVs), offering greater flexibility and personalization. Designed for seamless integration with clinical treatment planning systems, our approach assists users in generating high-quality plans efficiently. Comparative evaluations demonstrate that our method can surpasses the Varian RapidPlan model in both adaptability and plan quality in some scenarios.
A Beam's Eye View to Fluence Maps 3D Network for Ultra Fast VMAT Radiotherapy Planning
Feb 05, 2025



Volumetric Modulated Arc Therapy (VMAT) revolutionizes cancer treatment by precisely delivering radiation while sparing healthy tissues. Fluence maps generation, crucial in VMAT planning, traditionally involves complex and iterative, and thus time consuming processes. These fluence maps are subsequently leveraged for leaf-sequence. The deep-learning approach presented in this article aims to expedite this by directly predicting fluence maps from patient data. We developed a 3D network which we trained in a supervised way using a combination of L1 and L2 losses, and RT plans generated by Eclipse and from the REQUITE dataset, taking the RT dose map as input and the fluence maps computed from the corresponding RT plans as target. Our network predicts jointly the 180 fluence maps corresponding to the 180 control points (CP) of single arc VMAT plans. In order to help the network, we pre-process the input dose by computing the projections of the 3D dose map to the beam's eye view (BEV) of the 180 CPs, in the same coordinate system as the fluence maps. We generated over 2000 VMAT plans using Eclipse to scale up the dataset size. Additionally, we evaluated various network architectures and analyzed the impact of increasing the dataset size. We are measuring the performance in the 2D fluence maps domain using image metrics (PSNR, SSIM), as well as in the 3D dose domain using the dose-volume histogram (DVH) on a validation dataset. The network inference, which does not include the data loading and processing, is less than 20ms. Using our proposed 3D network architecture as well as increasing the dataset size using Eclipse improved the fluence map reconstruction performance by approximately 8 dB in PSNR compared to a U-Net architecture trained on the original REQUITE dataset. The resulting DVHs are very close to the one of the input target dose.
Automating High Quality RT Planning at Scale
Jan 21, 2025



Radiotherapy (RT) planning is complex, subjective, and time-intensive. Advances in artificial intelligence (AI) promise to improve its precision, efficiency, and consistency, but progress is often limited by the scarcity of large, standardized datasets. To address this, we introduce the Automated Iterative RT Planning (AIRTP) system, a scalable solution for generating high-quality treatment plans. This scalable solution is designed to generate substantial volumes of consistently high-quality treatment plans, overcoming a key obstacle in the advancement of AI-driven RT planning. Our AIRTP pipeline adheres to clinical guidelines and automates essential steps, including organ-at-risk (OAR) contouring, helper structure creation, beam setup, optimization, and plan quality improvement, using AI integrated with RT planning software like Eclipse of Varian. Furthermore, a novel approach for determining optimization parameters to reproduce 3D dose distributions, i.e. a method to convert dose predictions to deliverable treatment plans constrained by machine limitations. A comparative analysis of plan quality reveals that our automated pipeline produces treatment plans of quality comparable to those generated manually, which traditionally require several hours of labor per plan. Committed to public research, the first data release of our AIRTP pipeline includes nine cohorts covering head-and-neck and lung cancer sites to support an AAPM 2025 challenge. This data set features more than 10 times the number of plans compared to the largest existing well-curated public data set to our best knowledge. Repo:{https://github.com/RiqiangGao/GDP-HMM_AAPMChallenge}
Deep Learning-based Unsupervised Domain Adaptation via a Unified Model for Prostate Lesion Detection Using Multisite Bi-parametric MRI Datasets
Aug 08, 2024



Our hypothesis is that UDA using diffusion-weighted images, generated with a unified model, offers a promising and reliable strategy for enhancing the performance of supervised learning models in multi-site prostate lesion detection, especially when various b-values are present. This retrospective study included data from 5,150 patients (14,191 samples) collected across nine different imaging centers. A novel UDA method using a unified generative model was developed for multi-site PCa detection. This method translates diffusion-weighted imaging (DWI) acquisitions, including apparent diffusion coefficient (ADC) and individual DW images acquired using various b-values, to align with the style of images acquired using b-values recommended by Prostate Imaging Reporting and Data System (PI-RADS) guidelines. The generated ADC and DW images replace the original images for PCa detection. An independent set of 1,692 test cases (2,393 samples) was used for evaluation. The area under the receiver operating characteristic curve (AUC) was used as the primary metric, and statistical analysis was performed via bootstrapping. For all test cases, the AUC values for baseline SL and UDA methods were 0.73 and 0.79 (p<.001), respectively, for PI-RADS>=3, and 0.77 and 0.80 (p<.001) for PI-RADS>=4 PCa lesions. In the 361 test cases under the most unfavorable image acquisition setting, the AUC values for baseline SL and UDA were 0.49 and 0.76 (p<.001) for PI-RADS>=3, and 0.50 and 0.77 (p<.001) for PI-RADS>=4 PCa lesions. The results indicate the proposed UDA with generated images improved the performance of SL methods in multi-site PCa lesion detection across datasets with various b values, especially for images acquired with significant deviations from the PI-RADS recommended DWI protocol (e.g. with an extremely high b-value).
Multi-Agent Reinforcement Learning Meets Leaf Sequencing in Radiotherapy
Jun 03, 2024



In contemporary radiotherapy planning (RTP), a key module leaf sequencing is predominantly addressed by optimization-based approaches. In this paper, we propose a novel deep reinforcement learning (DRL) model termed as Reinforced Leaf Sequencer (RLS) in a multi-agent framework for leaf sequencing. The RLS model offers improvements to time-consuming iterative optimization steps via large-scale training and can control movement patterns through the design of reward mechanisms. We have conducted experiments on four datasets with four metrics and compared our model with a leading optimization sequencer. Our findings reveal that the proposed RLS model can achieve reduced fluence reconstruction errors, and potential faster convergence when integrated in an optimization planner. Additionally, RLS has shown promising results in a full artificial intelligence RTP pipeline. We hope this pioneer multi-agent RL leaf sequencer can foster future research on machine learning for RTP.
A Wide-area, Low-latency, and Power-efficient 6-DoF Pose Tracking System for Rigid Objects
Sep 15, 2021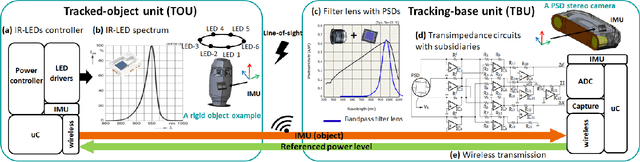
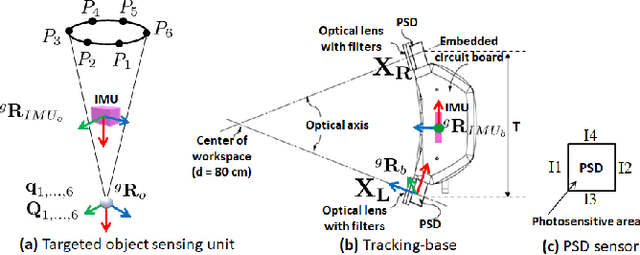
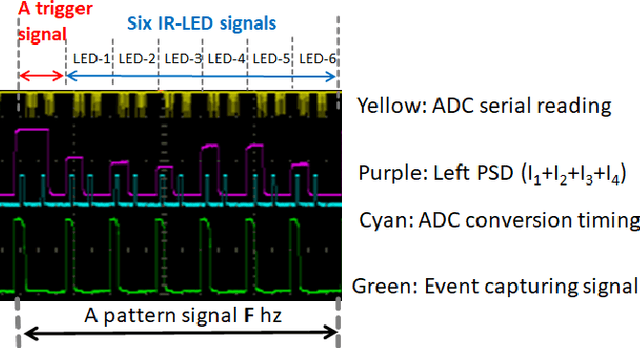

Position sensitive detectors (PSDs) offer possibility to track single active marker's two (or three) degrees of freedom (DoF) position with a high accuracy, while having a fast response time with high update frequency and low latency, all using a very simple signal processing circuit. However they are not particularly suitable for 6-DoF object pose tracking system due to lack of orientation measurement, limited tracking range, and sensitivity to environmental variation. We propose a novel 6-DoF pose tracking system for a rigid object tracking requiring a single active marker. The proposed system uses a stereo-based PSD pair and multiple Inertial Measurement Units (IMUs). This is done based on a practical approach to identify and control the power of Infrared-Light Emitting Diode (IR-LED) active markers, with an aim to increase the tracking work space and reduce the power consumption. Our proposed tracking system is validated with three different work space sizes and for static and dynamic positional accuracy using robotic arm manipulator with three different dynamic motion patterns. The results show that the static position root-mean-square (RMS) error is 0.6mm. The dynamic position RMS error is 0.7-0.9mm. The orientation RMS error is between 0.04 and 0.9 degree at varied dynamic motion. Overall, our proposed tracking system is capable of tracking a rigid object pose with sub-millimeter accuracy at the mid range of the work space and sub-degree accuracy for all work space under a lab setting.
Unsupervised Deformable Registration for Multi-Modal Images via Disentangled Representations
Mar 22, 2019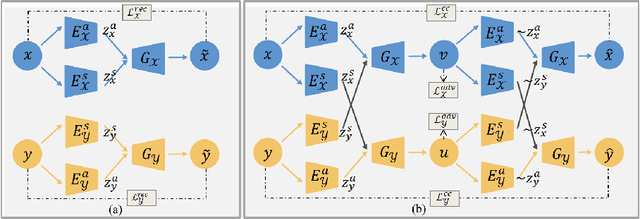
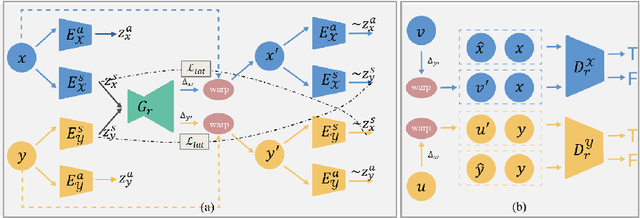
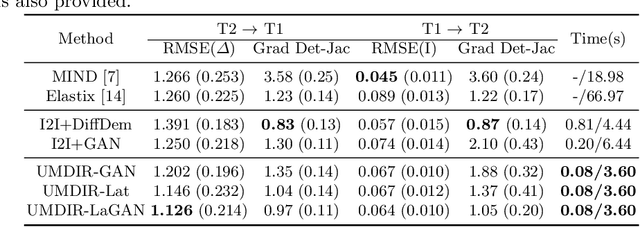
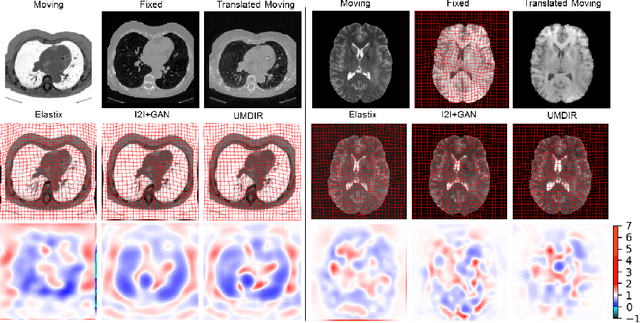
We propose a fully unsupervised multi-modal deformable image registration method (UMDIR), which does not require any ground truth deformation fields or any aligned multi-modal image pairs during training. Multi-modal registration is a key problem in many medical image analysis applications. It is very challenging due to complicated and unknown relationships between different modalities. In this paper, we propose an unsupervised learning approach to reduce the multi-modal registration problem to a mono-modal one through image disentangling. In particular, we decompose images of both modalities into a common latent shape space and separate latent appearance spaces via an unsupervised multi-modal image-to-image translation approach. The proposed registration approach is then built on the factorized latent shape code, with the assumption that the intrinsic shape deformation existing in original image domain is preserved in this latent space. Specifically, two metrics have been proposed for training the proposed network: a latent similarity metric defined in the common shape space and a learningbased image similarity metric based on an adversarial loss. We examined different variations of our proposed approach and compared them with conventional state-of-the-art multi-modal registration methods. Results show that our proposed methods achieve competitive performance against other methods at substantially reduced computation time.
Deep Adversarial Context-Aware Landmark Detection for Ultrasound Imaging
May 28, 2018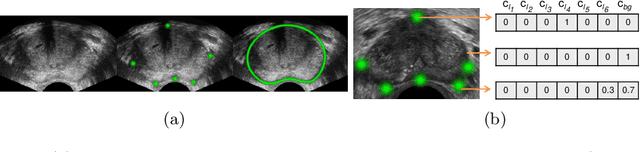
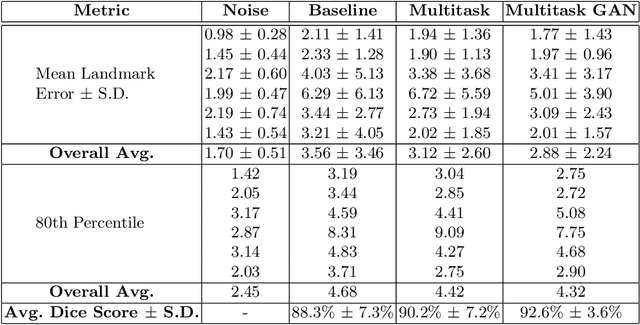
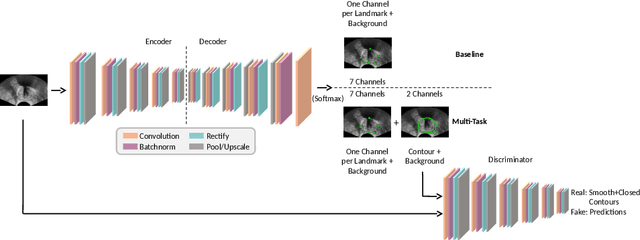
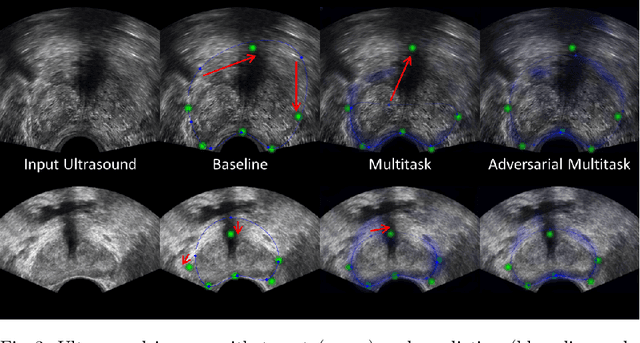
Real-time localization of prostate gland in trans-rectal ultrasound images is a key technology that is required to automate the ultrasound guided prostate biopsy procedures. In this paper, we propose a new deep learning based approach which is aimed at localizing several prostate landmarks efficiently and robustly. We propose a multitask learning approach primarily to make the overall algorithm more contextually aware. In this approach, we not only consider the explicit learning of landmark locations, but also build-in a mechanism to learn the contour of the prostate. This multitask learning is further coupled with an adversarial arm to promote the generation of feasible structures. We have trained this network using ~4000 labeled trans-rectal ultrasound images and tested on an independent set of images with ground truth landmark locations. We have achieved an overall Dice score of 92.6% for the adversarially trained multitask approach, which is significantly better than the Dice score of 88.3% obtained by only learning of landmark locations. The overall mean distance error using the adversarial multitask approach has also improved by 20% while reducing the standard deviation of the error compared to learning landmark locations only. In terms of computational complexity both approaches can process the images in real-time using standard computer with a standard CUDA enabled GPU.