 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIG: A Turnkey Library for Diving into Graph Deep Learning Research
Mar 23, 2021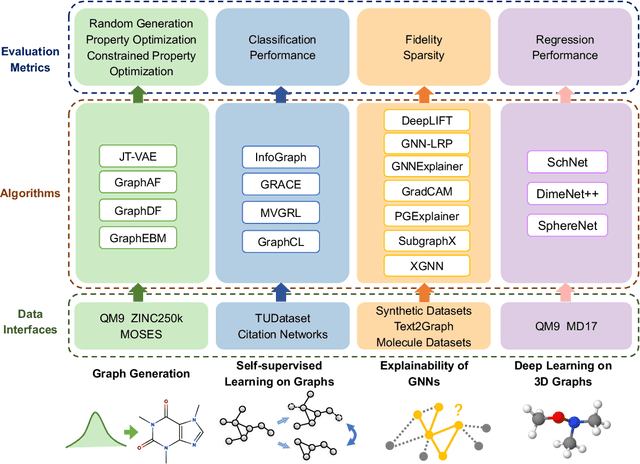
Although there exist several libraries for deep learning on graphs, they are aiming at implementing basic operations for graph deep learning. In the research community, implementing and benchmarking various advanced tasks are still painful and time-consuming with existing libraries. To facilitate graph deep learning research, we introduce DIG: Dive into Graphs, a research-oriented library that integrates unified and extensible implementations of common graph deep learning algorithms for several advanced tasks. Currently, we consider graph generation, self-supervised learning on graphs, explainability of graph neural networks, and deep learning on 3D graphs. For each direction, we provide unified implementations of data interfaces, common algorithms, and evaluation metrics. Altogether, DIG is an extensible, open-source, and turnkey library for researchers to develop new methods and effortlessly compare with common baselines using widely used datasets and evaluation metrics. Source code and documentations are available at https://github.com/divelab/DIG/.
Sent2Matrix: Folding Character Sequences in Serpentine Manifolds for Two-Dimensional Sentence
Mar 15, 2021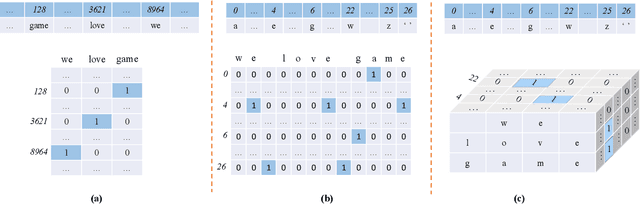



We study text representation methods using deep models. Current methods, such as word-level embedding and character-level embedding schemes, treat texts as either a sequence of atomic words or a sequence of characters. These methods either ignore word morphologies or word boundaries. To overcome these limitations, we propose to convert texts into 2-D representations and develop the Sent2Matrix method. Our method allows for the explicit incorporation of both word morphologies and boundaries. When coupled with a novel serpentine padding method, our Sent2Matrix method leads to an interesting visualization in which 1-D character sequences are folded into 2-D serpentine manifolds. Notably, our method is the first attempt to represent texts in 2-D formats. Experimental results on text classification tasks shown that our method consistently outperforms prior embedding methods.
Adversarial Graph Disentanglement
Mar 12, 2021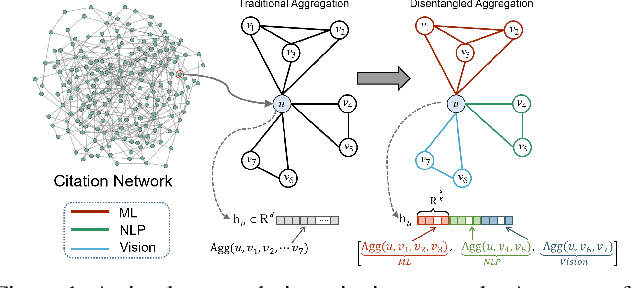
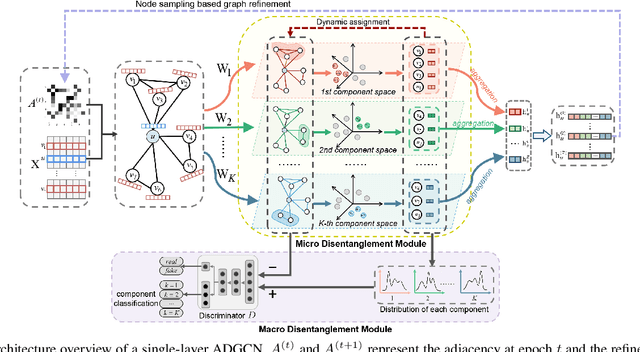
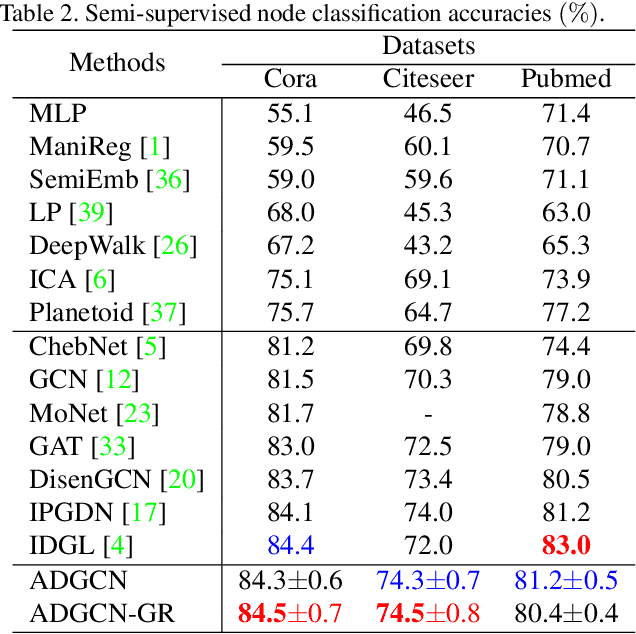
A real-world graph has a complex topology structure, which is often formed by the interaction of different latent factors. Disentanglement of these latent factors can effectively improve the robustness and interpretability of node representation of the graph. However, most existing methods lack consideration of the intrinsic differences in links caused by factor entanglement. In this paper, we propose an Adversarial Disentangled Graph Convolutional Network (ADGCN) for disentangled graph representation learning. Specifically, a dynamic multi-component convolution layer is designed to achieve micro-disentanglement by inferring latent components that caused links between nodes. On the basis of micro-disentanglement, we further propose a macro-disentanglement adversarial regularizer that improves the separability between component distributions, thus restricting interdependence among components. Additionally, to learn collaboratively a better disentangled representation and topological structure, a diversity preserving node sampling-based progressive refinement of graph structure is proposed. The experimental results on various real-world graph data verify that our ADGCN obtains remarkably more favorable performance over currently available alternatives.
Spherical Message Passing for 3D Graph Networks
Feb 26, 2021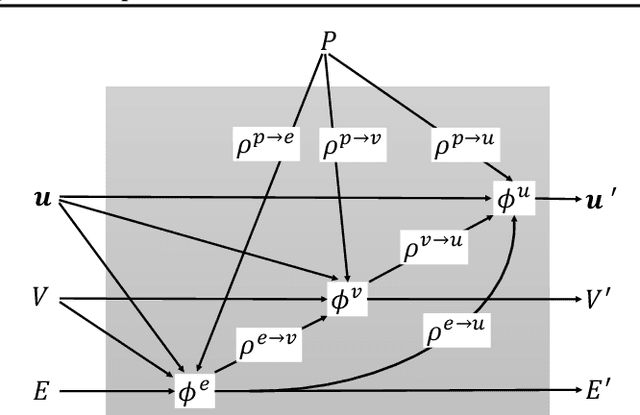
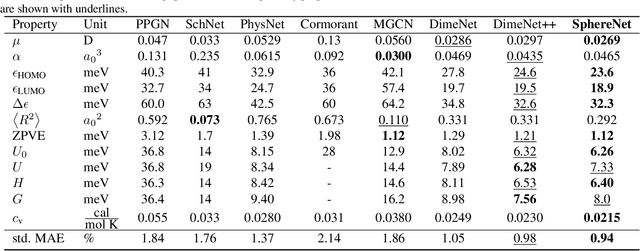
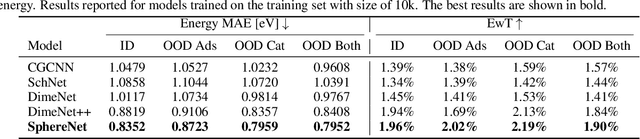
We consider representation learning from 3D graphs in which each node is associated with a spatial position in 3D. This is an under explored area of research, and a principled framework is currently lacking. In this work, we propose a generic framework, known as the 3D graph network (3DGN), to provide a unified interface at different levels of granularity for 3D graphs. Built on 3DGN, we propose the spherical message passing (SMP) as a novel and specific scheme for realizing the 3DGN framework in the spherical coordinate system (SCS). We conduct formal analyses and show that the relative location of each node in 3D graphs is uniquely defined in the SMP scheme. Thus, our SMP represents a complete and accurate architecture for learning from 3D graphs in the SCS. We derive physically-based representations of geometric information and propose the SphereNet for learning representations of 3D graphs. We show that existing 3D deep models can be viewed as special cases of the SphereNet. Experimental results demonstrate that the use of complete and accurate 3D information in 3DGN and SphereNet leads to significant performance improvements in prediction tasks.
Self-Supervised Learning of Graph Neural Networks: A Unified Review
Feb 23, 2021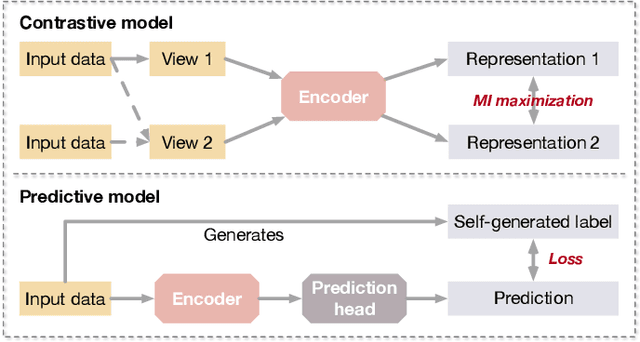
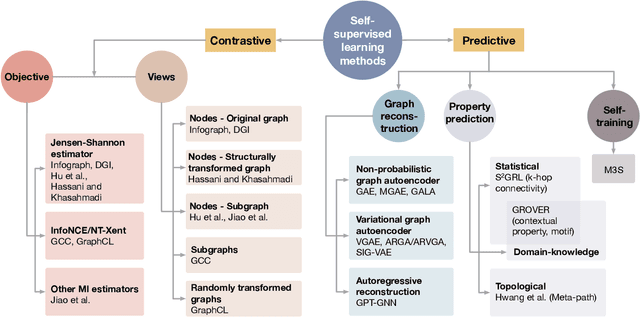
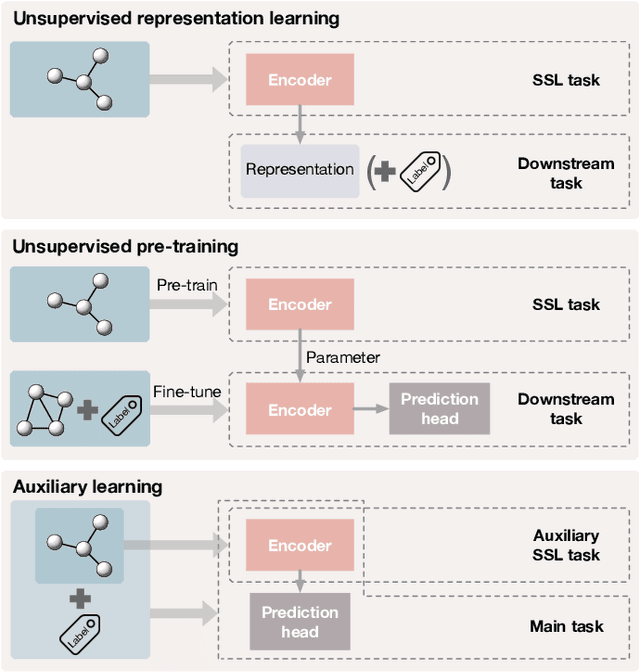
Deep models trained in supervised mode have achieved remarkable success on a variety of tasks. When labeled samples are limited, self-supervised learning (SSL) is emerging as a new paradigm for making use of large amounts of unlabeled samples. SSL has achieved promising performance on natural language and image learning tasks. Recently, there is a trend to extend such success to graph data using graph neural networks (GNNs). In this survey, we provide a unified review of different ways of training GNNs using SSL. Specifically, we categorize SSL methods into contrastive and predictive models. In either category, we provide a unified framework for methods as well as how these methods differ in each component under the framework. Our unified treatment of SSL methods for GNNs sheds light on the similarities and differences of various methods, setting the stage for developing new methods and algorithms. We also summarize different SSL settings and the corresponding datasets used in each setting. To facilitate methodological development and empirical comparison, we develop a standardized testbed for SSL in GNNs, including implementations of common baseline methods, datasets, and evaluation metrics.
On Explainability of Graph Neural Networks via Subgraph Explorations
Feb 09, 2021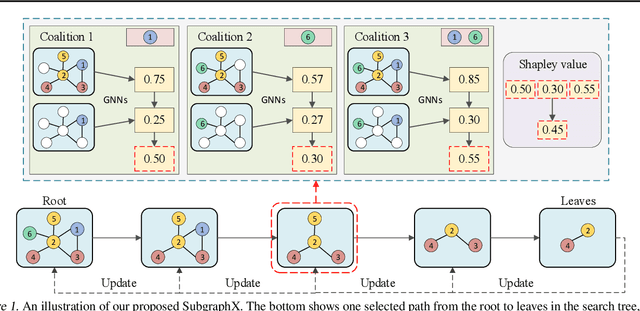
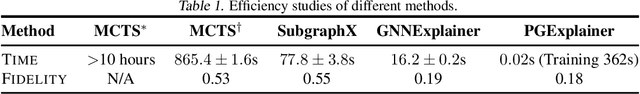
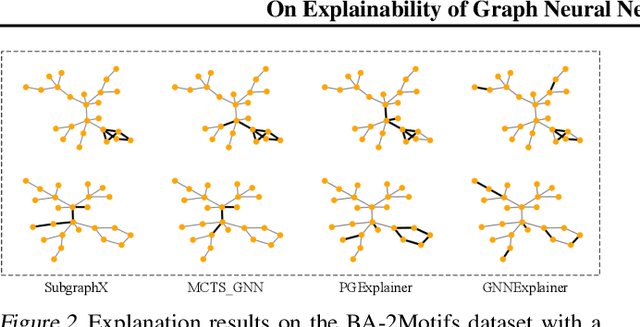
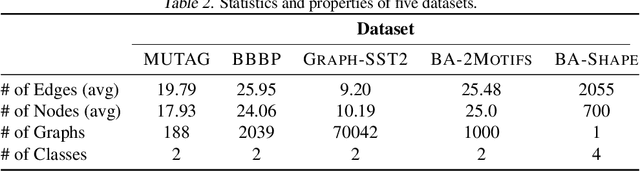
We consider the problem of explaining the predictions of graph neural networks (GNNs), which otherwise are considered as black boxes. Existing methods invariably focus on explaining the importance of graph nodes or edges but ignore the substructures of graphs, which are more intuitive and human-intelligible. In this work, we propose a novel method, known as SubgraphX, to explain GNNs by identifying important subgraphs. Given a trained GNN model and an input graph, our SubgraphX explains its predictions by efficiently exploring different subgraphs with Monte Carlo tree search. To make the tree search more effective, we propose to use Shapley values as a measure of subgraph importance, which can also capture the interactions among different subgraphs. To expedite computations, we propose efficient approximation schemes to compute Shapley values for graph data. Our work represents the first attempt to explain GNNs via identifying subgraphs explicitly. Experimental results show that our SubgraphX achieves significantly improved explanations, while keeping computations at a reasonable level.
GraphDF: A Discrete Flow Model for Molecular Graph Generation
Feb 01, 2021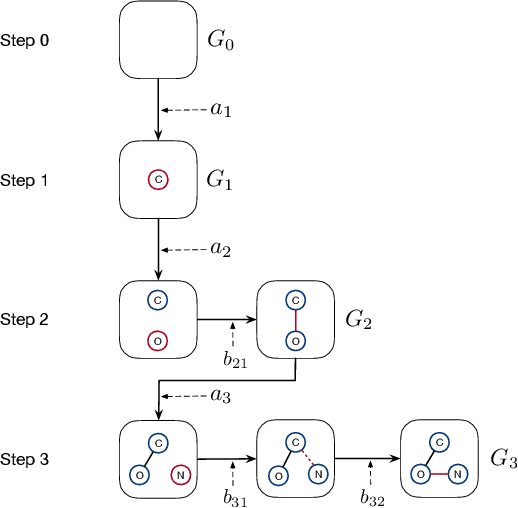
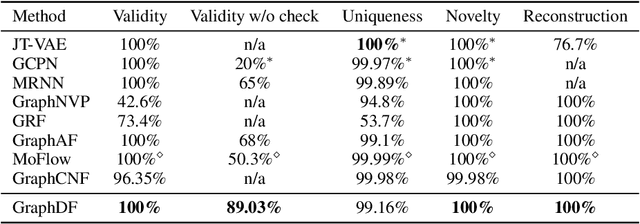
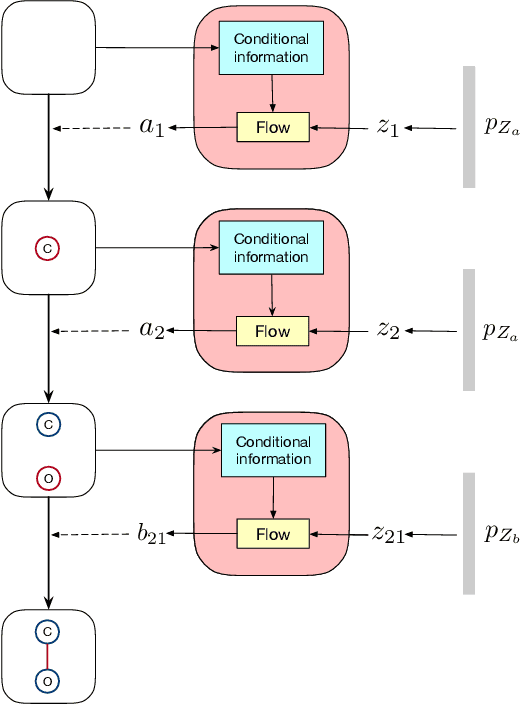
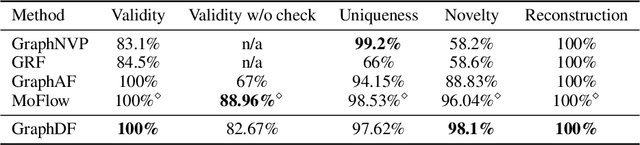
We consider the problem of molecular graph generation using deep models. While graphs are discrete, most existing methods use continuous latent variables, resulting in inaccurate modeling of discrete graph structures. In this work, we propose GraphDF, a novel discrete latent variable model for molecular graph generation based on normalizing flow methods. GraphDF uses invertible modulo shift transforms to map discrete latent variables to graph nodes and edges. We show that the use of discrete latent variables reduces computational costs and eliminates the negative effect of dequantization. Comprehensive experimental results show that GraphDF outperforms prior methods on random generation, property optimization, and constrained optimization tasks.
GraphEBM: Molecular Graph Generation with Energy-Based Models
Jan 31, 2021
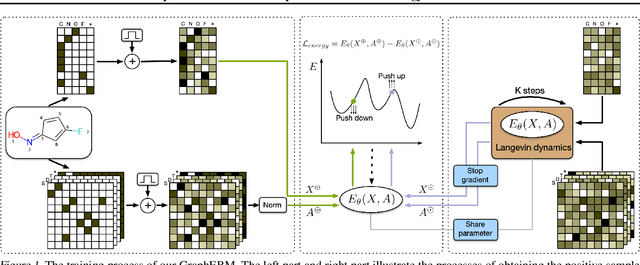
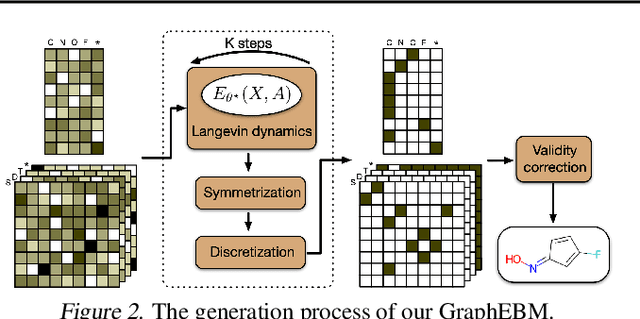

Molecular graph generation is an emerging area of research with numerous applications. This problem remains challenging as molecular graphs are discrete, irregular, and permutation invariant to node order. Notably, most existing approaches fail to guarantee the intrinsic property of permutation invariance, resulting in unexpected bias in generative models. In this work, we propose GraphEBM to generate molecular graphs using energy-based models. In particular, we parameterize the energy function in a permutation invariant manner, thus making GraphEBM permutation invariant. We apply Langevin dynamics to train the energy function by approximately maximizing likelihood and generate samples with low energies. Furthermore, to generate molecules with a specific desirable property, we propose a simple yet effective strategy, which pushes down energies with flexible degrees according to the properties of corresponding molecules. Finally, we explore the use of GraphEBM for generating molecules with multiple objectives in a compositional manner. Comprehensive experimental results on random, goal-directed, and compositional generation tasks demonstrate the effectiveness of our proposed method.
A Multi-Stage Attentive Transfer Learning Framework for Improving COVID-19 Diagnosis
Jan 14, 2021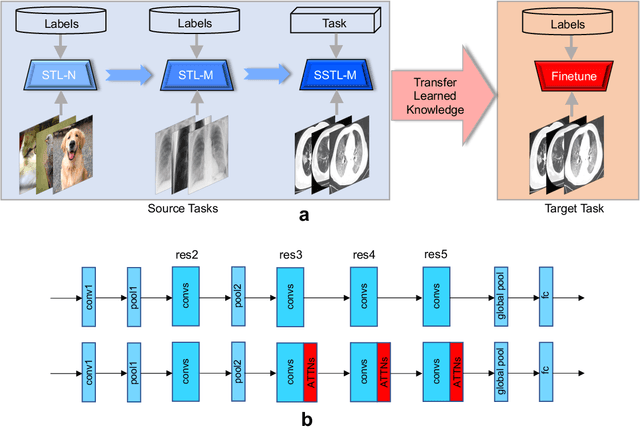
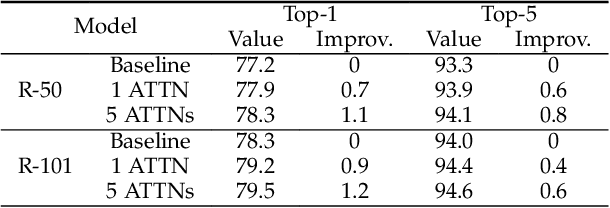
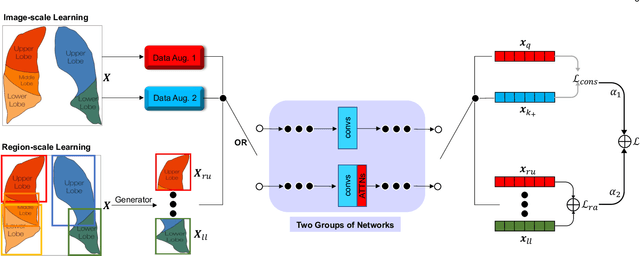
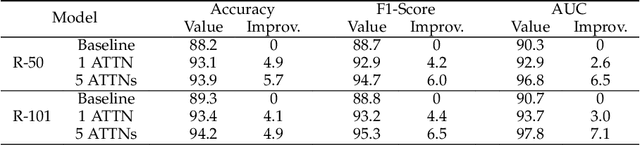
Computed tomography (CT) imaging is a promising approach to diagnosing the COVID-19. Machine learning methods can be employed to train models from labeled CT images and predict whether a case is positive or negative. However, there exists no publicly-available and large-scale CT data to train accurate models. In this work, we propose a multi-stage attentive transfer learning framework for improving COVID-19 diagnosis. Our proposed framework consists of three stages to train accurate diagnosis models through learning knowledge from multiple source tasks and data of different domains. Importantly, we propose a novel self-supervised learning method to learn multi-scale representations for lung CT images. Our method captures semantic information from the whole lung and highlights the functionality of each lung region for better representation learning. The method is then integrated to the last stage of the proposed transfer learning framework to reuse the complex patterns learned from the same CT images. We use a base model integrating self-attention (ATTNs) and convolutional operations. Experimental results show that networks with ATTNs induce greater performance improvement through transfer learning than networks without ATTNs. This indicates attention exhibits higher transferability than convolution. Our results also show that the proposed self-supervised learning method outperforms several baseline methods.
CleftNet: Augmented Deep Learning for Synaptic Cleft Detection from Brain Electron Microscopy
Jan 12, 2021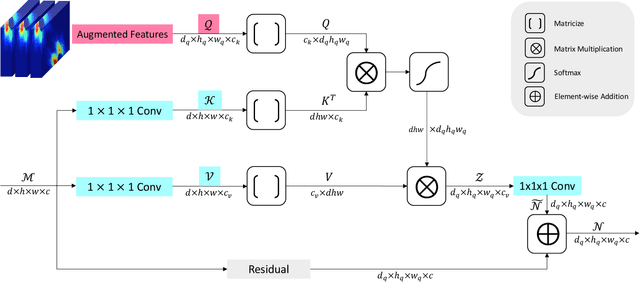
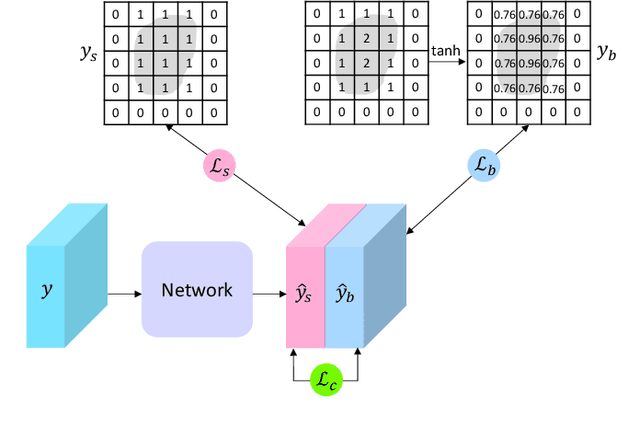
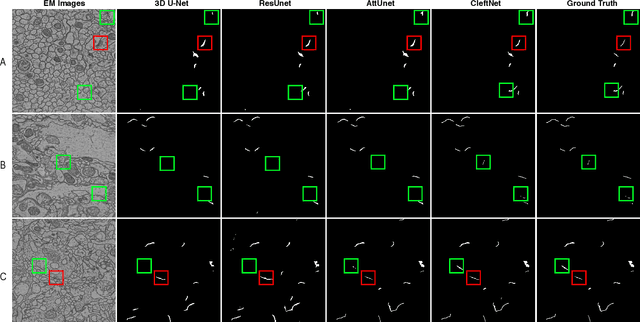

Detecting synaptic clefts is a crucial step to investigate the biological function of synapses. The volume electron microscopy (EM) allows the identification of synaptic clefts by photoing EM images with high resolution and fine details. Machine learning approaches have been employed to automatically predict synaptic clefts from EM images. In this work, we propose a novel and augmented deep learning model, known as CleftNet, for improving synaptic cleft detection from brain EM images. We first propose two novel network components, known as the feature augmentor and the label augmentor, for augmenting features and labels to improve cleft representations. The feature augmentor can fuse global information from inputs and learn common morphological patterns in clefts, leading to augmented cleft features. In addition, it can generate outputs with varying dimensions, making it flexible to be integrated in any deep network. The proposed label augmentor augments the label of each voxel from a value to a vector, which contains both the segmentation label and boundary label. This allows the network to learn important shape information and to produce more informative cleft representations. Based on the proposed feature augmentor and label augmentor, We build the CleftNet as a U-Net like network. The effectiveness of our methods is evaluated on both online and offline tasks. Our CleftNet currently ranks \#1 on the online task of the CREMI open challenge. In addition, both quantitative and qualitative results in the offline tasks show that our method outperforms the baseline approaches significantly.