 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Refine: Iterative Refinement with Self-Feedback
Mar 30, 2023



Like people, LLMs do not always generate the best text for a given generation problem on their first try (e.g., summaries, answers, explanations). Just as people then refine their text, we introduce SELF-REFINE, a framework for similarly improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an output using an LLM, then allow the same model to provide multi-aspect feedback for its own output; finally, the same model refines its previously generated output given its own feedback. Unlike earlier work, our iterative refinement framework does not require supervised training data or reinforcement learning, and works with a single LLM. We experiment with 7 diverse tasks, ranging from review rewriting to math reasoning, demonstrating that our approach outperforms direct generation. In all tasks, outputs generated with SELF-REFINE are preferred by humans and by automated metrics over those generated directly with GPT-3.5 and GPT-4, improving on average by absolute 20% across tasks.
Adding Instructions during Pretraining: Effective Way of Controlling Toxicity in Language Models
Feb 14, 2023



Pretrained large language models have become indispensable for solving various natural language processing (NLP) tasks. However, safely deploying them in real world applications is challenging because they generate toxic content. To address this challenge, we propose two novel pretraining data augmentation strategies that significantly reduce model toxicity without compromising its utility. Our two strategies are: (1) MEDA: adds raw toxicity score as meta-data to the pretraining samples, and (2) INST: adds instructions to those samples indicating their toxicity. Our results indicate that our best performing strategy (INST) substantially reduces the toxicity probability up to 61% while preserving the accuracy on five benchmark NLP tasks as well as improving AUC scores on four bias detection tasks by 1.3%. We also demonstrate the generalizability of our techniques by scaling the number of training samples and the number of model parameters.
AutoBiasTest: Controllable Sentence Generation for Automated and Open-Ended Social Bias Testing in Language Models
Feb 14, 2023



Social bias in Pretrained Language Models (PLMs) affects text generation and other downstream NLP tasks. Existing bias testing methods rely predominantly on manual templates or on expensive crowd-sourced data. We propose a novel AutoBiasTest method that automatically generates sentences for testing bias in PLMs, hence providing a flexible and low-cost alternative. Our approach uses another PLM for generation and controls the generation of sentences by conditioning on social group and attribute terms. We show that generated sentences are natural and similar to human-produced content in terms of word length and diversity. We illustrate that larger models used for generation produce estimates of social bias with lower variance. We find that our bias scores are well correlated with manual templates, but AutoBiasTest highlights biases not captured by these templates due to more diverse and realistic test sentences. By automating large-scale test sentence generation, we enable better estimation of underlying bias distributions
Can You Label Less by Using Out-of-Domain Data? Active & Transfer Learning with Few-shot Instructions
Nov 21, 2022



Labeling social-media data for custom dimensions of toxicity and social bias is challenging and labor-intensive. Existing transfer and active learning approaches meant to reduce annotation effort require fine-tuning, which suffers from over-fitting to noise and can cause domain shift with small sample sizes. In this work, we propose a novel Active Transfer Few-shot Instructions (ATF) approach which requires no fine-tuning. ATF leverages the internal linguistic knowledge of pre-trained language models (PLMs) to facilitate the transfer of information from existing pre-labeled datasets (source-domain task) with minimum labeling effort on unlabeled target data (target-domain task). Our strategy can yield positive transfer achieving a mean AUC gain of 10.5% compared to no transfer with a large 22b parameter PLM. We further show that annotation of just a few target-domain samples via active learning can be beneficial for transfer, but the impact diminishes with more annotation effort (26% drop in gain between 100 and 2000 annotated examples). Finally, we find that not all transfer scenarios yield a positive gain, which seems related to the PLMs initial performance on the target-domain task.
Evaluating Parameter Efficient Learning for Generation
Oct 25, 2022



Parameter efficient learning methods (PERMs) have recently gained significant attention as they provide an efficient way for pre-trained language models (PLMs) to adapt to a downstream task. However, these conclusions are mostly drawn from in-domain evaluations over the full training set. In this paper, we present comparisons between PERMs and finetuning from three new perspectives: (1) the effect of sample and model size to in-domain evaluations, (2) generalization to unseen domains and new datasets, and (3) the faithfulness of generations. Our results show that for in-domain settings (a) there is a cross point of sample size for which PERMs will perform better than finetuning when training with fewer samples, and (b) larger PLMs have larger cross points. For cross-domain and cross-dataset cases, we show that (a) Adapter (Houlsby et al., 2019) performs the best amongst all the PERMs studied here, and (b) it outperforms finetuning if the task dataset is below a certain size. We also compare the faithfulness of generations and show that PERMs can achieve better faithfulness score than finetuning, especially for small training set, by as much as 6%. Finally, we apply Adapter to MT-NLG 530b (Smith et al., 2022) and achieve new state-of-the-art results on Xsum (Narayan et al., 2018) for all ROUGE scores (ROUGE-1 49.17, ROUGE-2 27.20, ROUGE-L 40.98).
Context Generation Improves Open Domain Question Answering
Oct 12, 2022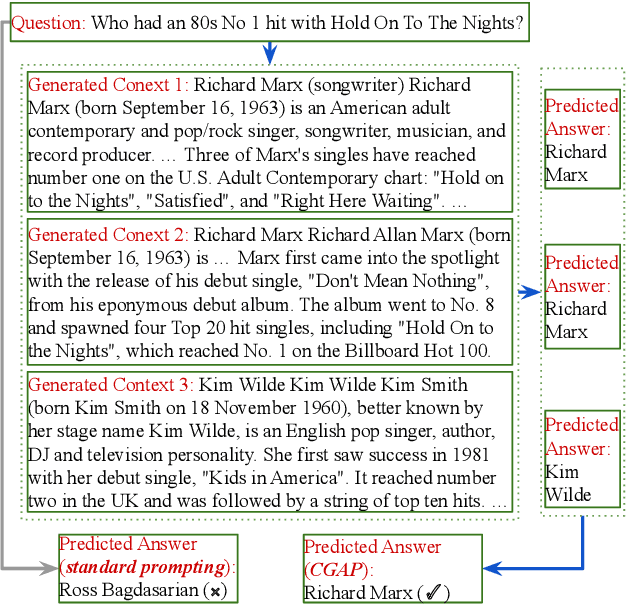

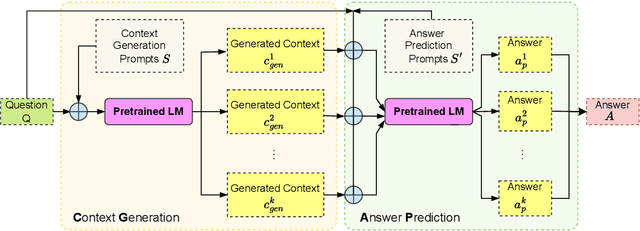
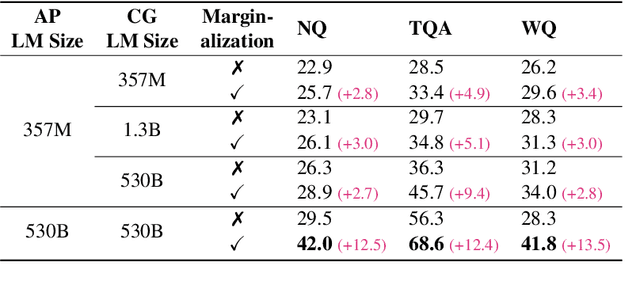
Closed-book question answering (QA) requires a model to directly answer an open-domain question without access to any external knowledge. Prior work on closed-book QA either directly finetunes or prompts a pretrained language model (LM) to leverage the stored knowledge. However, they do not fully exploit the parameterized knowledge. To address this issue, we propose a two-stage, closed-book QA framework which employs a coarse-to-fine approach to extract relevant knowledge and answer a question. Our approach first generates a related context for a given question by prompting a pretrained LM. We then prompt the same LM for answer prediction using the generated context and the question. Additionally, to eliminate failure caused by context uncertainty, we marginalize over generated contexts. Experimental results on three QA benchmarks show that our method significantly outperforms previous closed-book QA methods (e.g. exact matching 68.6% vs. 55.3%), and is on par with open-book methods that exploit external knowledge sources (e.g. 68.6% vs. 68.0%). Our method is able to better exploit the stored knowledge in pretrained LMs without adding extra learnable parameters or needing finetuning, and paves the way for hybrid models that integrate pretrained LMs with external knowledge.
Multi-Stage Prompting for Knowledgeable Dialogue Generation
Mar 16, 2022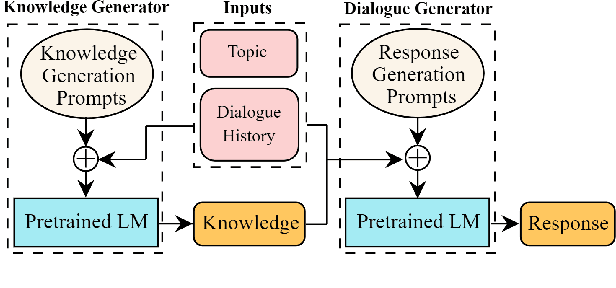
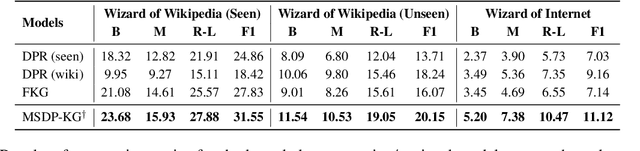
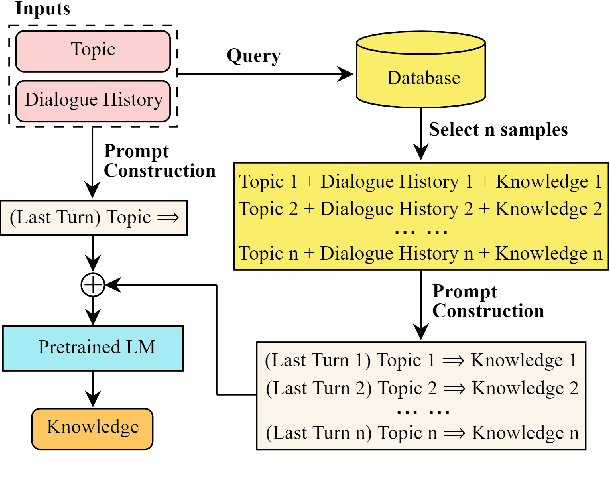

Existing knowledge-grounded dialogue systems typically use finetuned versions of a pretrained language model (LM) and large-scale knowledge bases. These models typically fail to generalize on topics outside of the knowledge base, and require maintaining separate potentially large checkpoints each time finetuning is needed. In this paper, we aim to address these limitations by leveraging the inherent knowledge stored in the pretrained LM as well as its powerful generation ability. We propose a multi-stage prompting approach to generate knowledgeable responses from a single pretrained LM. We first prompt the LM to generate knowledge based on the dialogue context. Then, we further prompt it to generate responses based on the dialogue context and the previously generated knowledge. Results show that our knowledge generator outperforms the state-of-the-art retrieval-based model by 5.8% when combining knowledge relevance and correctness. In addition, our multi-stage prompting outperforms the finetuning-based dialogue model in terms of response knowledgeability and engagement by up to 10% and 5%, respectively. Furthermore, we scale our model up to 530 billion parameters and show that larger LMs improve the generation correctness score by up to 10%, and response relevance, knowledgeability and engagement by up to 10%. Our code is available at: https://github.com/NVIDIA/Megatron-LM.
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022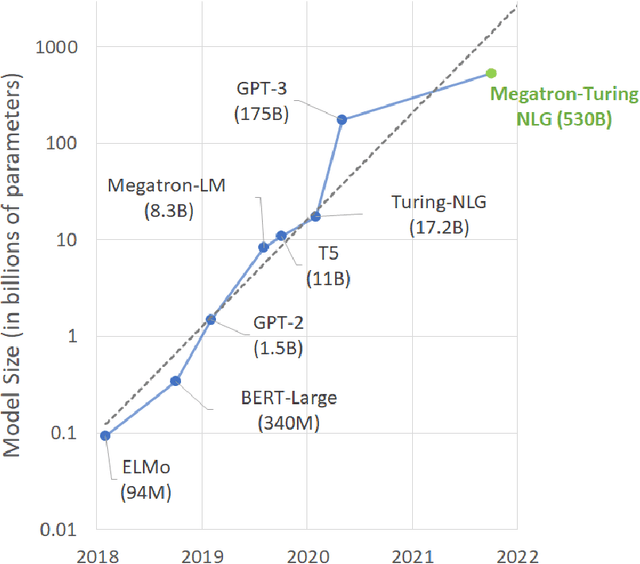
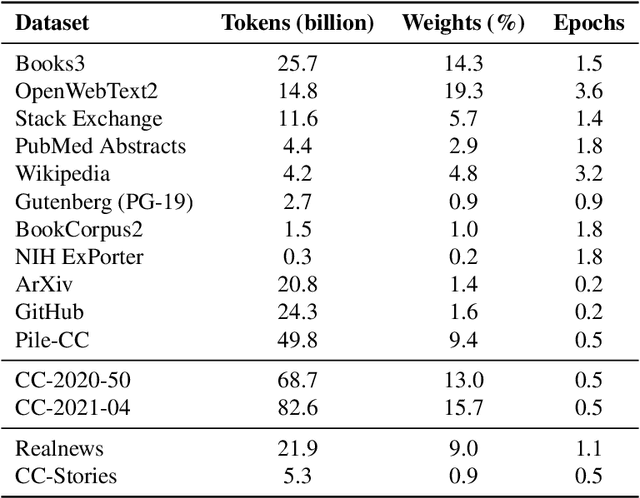
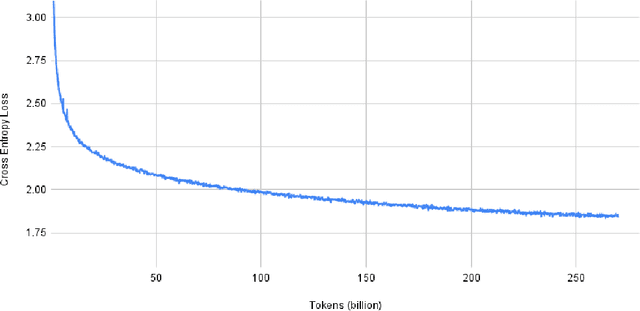
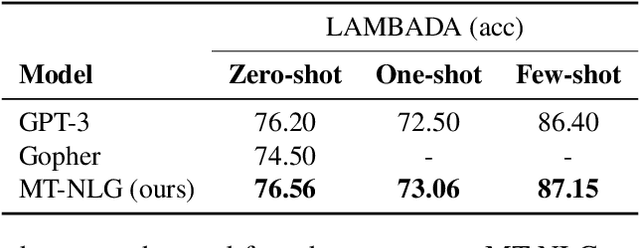
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
Few-shot Instruction Prompts for Pretrained Language Models to Detect Social Biases
Dec 15, 2021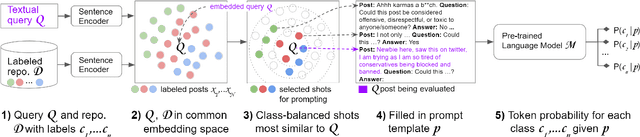
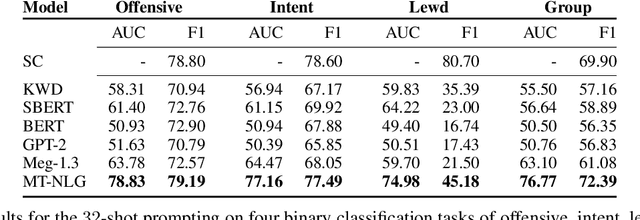
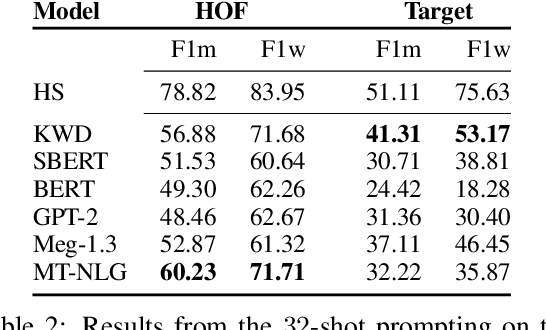
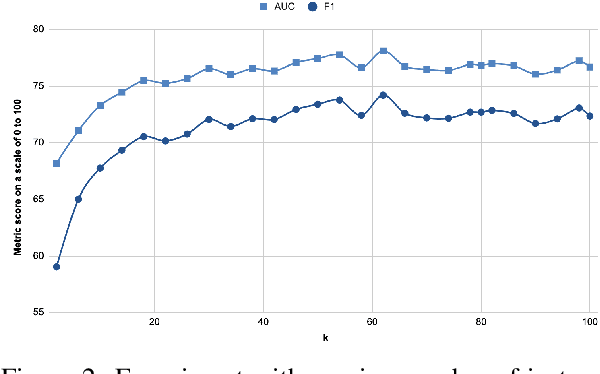
Detecting social bias in text is challenging due to nuance, subjectivity, and difficulty in obtaining good quality labeled datasets at scale, especially given the evolving nature of social biases and society. To address these challenges, we propose a few-shot instruction-based method for prompting pre-trained language models (LMs). We select a few label-balanced exemplars from a small support repository that are closest to the query to be labeled in the embedding space. We then provide the LM with instruction that consists of this subset of labeled exemplars, the query text to be classified, a definition of bias, and prompt it to make a decision. We demonstrate that large LMs used in a few-shot context can detect different types of fine-grained biases with similar and sometimes superior accuracy to fine-tuned models. We observe that the largest 530B parameter model is significantly more effective in detecting social bias compared to smaller models (achieving at least 20% improvement in AUC metric compared to other models). It also maintains a high AUC (dropping less than 5%) in a few-shot setting with a labeled repository reduced to as few as 100 samples. Large pretrained language models thus make it easier and quicker to build new bias detectors.
Focused Attention Improves Document-Grounded Generation
Apr 26, 2021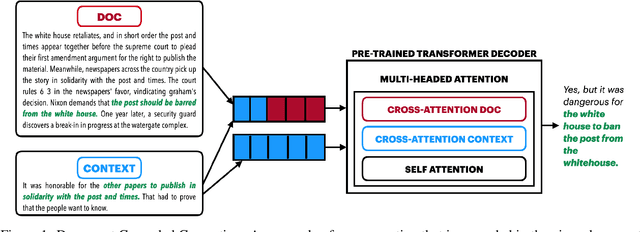
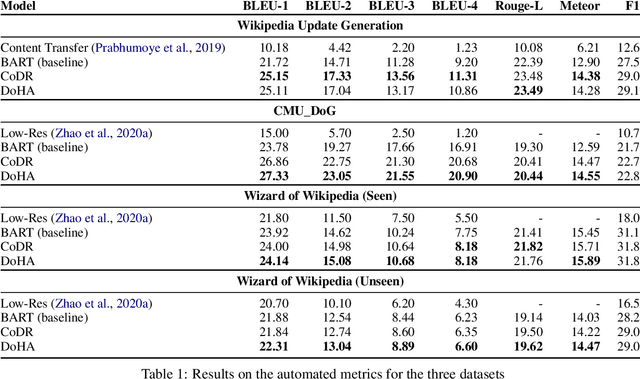
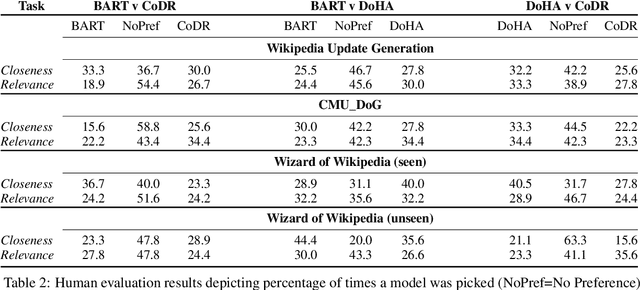
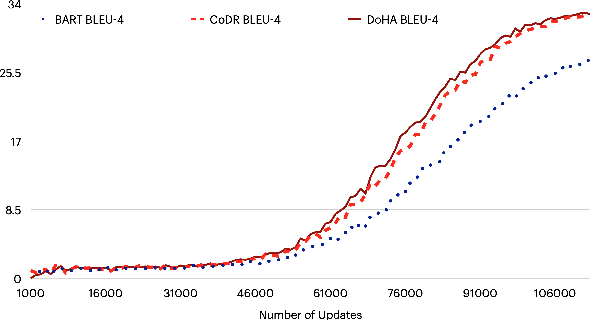
Document grounded generation is the task of using the information provided in a document to improve text generation. This work focuses on two different document grounded generation tasks: Wikipedia Update Generation task and Dialogue response generation. Our work introduces two novel adaptations of large scale pre-trained encoder-decoder models focusing on building context driven representation of the document and enabling specific attention to the information in the document. Additionally, we provide a stronger BART baseline for these tasks. Our proposed techniques outperform existing methods on both automated (at least 48% increase in BLEU-4 points) and human evaluation for closeness to reference and relevance to the document. Furthermore, we perform comprehensive manual inspection of the generated output and categorize errors to provide insights into future directions in modeling these tasks.