 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Deep Reinforcement Learning via Isotropic Gaussian Representations
Feb 22, 2026Deep reinforcement learning systems often suffer from unstable training dynamics due to non-stationarity, where learning objectives and data distributions evolve over time. We show that under non-stationary targets, isotropic Gaussian embeddings are provably advantageous. In particular, they induce stable tracking of time-varying targets for linear readouts, achieve maximal entropy under a fixed variance budget, and encourage a balanced use of all representational dimensions--all of which enable agents to be more adaptive and stable. Building on this insight, we propose the use of Sketched Isotropic Gaussian Regularization for shaping representations toward an isotropic Gaussian distribution during training. We demonstrate empirically, over a variety of domains, that this simple and computationally inexpensive method improves performance under non-stationarity while reducing representation collapse, neuron dormancy, and training instability.
SPECTRE: Spectral Pre-training Embeddings with Cylindrical Temporal Rotary Position Encoding for Fine-Grained sEMG-Based Movement Decoding
Dec 27, 2025Decoding fine-grained movement from non-invasive surface Electromyography (sEMG) is a challenge for prosthetic control due to signal non-stationarity and low signal-to-noise ratios. Generic self-supervised learning (SSL) frameworks often yield suboptimal results on sEMG as they attempt to reconstruct noisy raw signals and lack the inductive bias to model the cylindrical topology of electrode arrays. To overcome these limitations, we introduce SPECTRE, a domain-specific SSL framework. SPECTRE features two primary contributions: a physiologically-grounded pre-training task and a novel positional encoding. The pre-training involves masked prediction of discrete pseudo-labels from clustered Short-Time Fourier Transform (STFT) representations, compelling the model to learn robust, physiologically relevant frequency patterns. Additionally, our Cylindrical Rotary Position Embedding (CyRoPE) factorizes embeddings along linear temporal and annular spatial dimensions, explicitly modeling the forearm sensor topology to capture muscle synergies. Evaluations on multiple datasets, including challenging data from individuals with amputation, demonstrate that SPECTRE establishes a new state-of-the-art for movement decoding, significantly outperforming both supervised baselines and generic SSL approaches. Ablation studies validate the critical roles of both spectral pre-training and CyRoPE. SPECTRE provides a robust foundation for practical myoelectric interfaces capable of handling real-world sEMG complexities.
Caption This, Reason That: VLMs Caught in the Middle
May 24, 2025



Vision-Language Models (VLMs) have shown remarkable progress in visual understanding in recent years. Yet, they still lag behind human capabilities in specific visual tasks such as counting or relational reasoning. To understand the underlying limitations, we adopt methodologies from cognitive science, analyzing VLM performance along core cognitive axes: Perception, Attention, and Memory. Using a suite of tasks targeting these abilities, we evaluate state-of-the-art VLMs, including GPT-4o. Our analysis reveals distinct cognitive profiles: while advanced models approach ceiling performance on some tasks (e.g. category identification), a significant gap persists, particularly in tasks requiring spatial understanding or selective attention. Investigating the source of these failures and potential methods for improvement, we employ a vision-text decoupling analysis, finding that models struggling with direct visual reasoning show marked improvement when reasoning over their own generated text captions. These experiments reveal a strong need for improved VLM Chain-of-Thought (CoT) abilities, even in models that consistently exceed human performance. Furthermore, we demonstrate the potential of targeted fine-tuning on composite visual reasoning tasks and show that fine-tuning smaller VLMs substantially improves core cognitive abilities. While this improvement does not translate to large enhancements on challenging, out-of-distribution benchmarks, we show broadly that VLM performance on our datasets strongly correlates with performance on these other benchmarks. Our work provides a detailed analysis of VLM cognitive strengths and weaknesses and identifies key bottlenecks in simultaneous perception and reasoning while also providing an effective and simple solution.
Building spatial world models from sparse transitional episodic memories
May 19, 2025Many animals possess a remarkable capacity to rapidly construct flexible mental models of their environments. These world models are crucial for ethologically relevant behaviors such as navigation, exploration, and planning. The ability to form episodic memories and make inferences based on these sparse experiences is believed to underpin the efficiency and adaptability of these models in the brain. Here, we ask: Can a neural network learn to construct a spatial model of its surroundings from sparse and disjoint episodic memories? We formulate the problem in a simulated world and propose a novel framework, the Episodic Spatial World Model (ESWM), as a potential answer. We show that ESWM is highly sample-efficient, requiring minimal observations to construct a robust representation of the environment. It is also inherently adaptive, allowing for rapid updates when the environment changes. In addition, we demonstrate that ESWM readily enables near-optimal strategies for exploring novel environments and navigating between arbitrary points, all without the need for additional training.
Geometry of naturalistic object representations in recurrent neural network models of working memory
Nov 04, 2024



Working memory is a central cognitive ability crucial for intelligent decision-making. Recent experimental and computational work studying working memory has primarily used categorical (i.e., one-hot) inputs, rather than ecologically relevant, multidimensional naturalistic ones. Moreover, studies have primarily investigated working memory during single or few cognitive tasks. As a result, an understanding of how naturalistic object information is maintained in working memory in neural networks is still lacking. To bridge this gap, we developed sensory-cognitive models, comprising a convolutional neural network (CNN) coupled with a recurrent neural network (RNN), and trained them on nine distinct N-back tasks using naturalistic stimuli. By examining the RNN's latent space, we found that: (1) Multi-task RNNs represent both task-relevant and irrelevant information simultaneously while performing tasks; (2) The latent subspaces used to maintain specific object properties in vanilla RNNs are largely shared across tasks, but highly task-specific in gated RNNs such as GRU and LSTM; (3) Surprisingly, RNNs embed objects in new representational spaces in which individual object features are less orthogonalized relative to the perceptual space; (4) The transformation of working memory encodings (i.e., embedding of visual inputs in the RNN latent space) into memory was shared across stimuli, yet the transformations governing the retention of a memory in the face of incoming distractor stimuli were distinct across time. Our findings indicate that goal-driven RNNs employ chronological memory subspaces to track information over short time spans, enabling testable predictions with neural data.
Towards Adversarially Robust Vision-Language Models: Insights from Design Choices and Prompt Formatting Techniques
Jul 15, 2024Vision-Language Models (VLMs) have witnessed a surge in both research and real-world applications. However, as they are becoming increasingly prevalent, ensuring their robustness against adversarial attacks is paramount. This work systematically investigates the impact of model design choices on the adversarial robustness of VLMs against image-based attacks. Additionally, we introduce novel, cost-effective approaches to enhance robustness through prompt formatting. By rephrasing questions and suggesting potential adversarial perturbations, we demonstrate substantial improvements in model robustness against strong image-based attacks such as Auto-PGD. Our findings provide important guidelines for developing more robust VLMs, particularly for deployment in safety-critical environments.
iWISDM: Assessing instruction following in multimodal models at scale
Jun 20, 2024



The ability to perform complex tasks from detailed instructions is a key to many remarkable achievements of our species. As humans, we are not only capable of performing a wide variety of tasks but also very complex ones that may entail hundreds or thousands of steps to complete. Large language models and their more recent multimodal counterparts that integrate textual and visual inputs have achieved unprecedented success in performing complex tasks. Yet, most existing benchmarks are largely confined to single-modality inputs (either text or vision), narrowing the scope of multimodal assessments, particularly for instruction-following in multimodal contexts. To bridge this gap, we introduce the instructed-Virtual VISual Decision Making (iWISDM) environment engineered to generate a limitless array of vision-language tasks of varying complexity. Using iWISDM, we compiled three distinct benchmarks of instruction following visual tasks across varying complexity levels and evaluated several newly developed multimodal models on these benchmarks. Our findings establish iWISDM as a robust benchmark for assessing the instructional adherence of both existing and emergent multimodal models and highlight a large gap between these models' ability to precisely follow instructions with that of humans.
Towards Out-of-Distribution Adversarial Robustness
Oct 10, 2022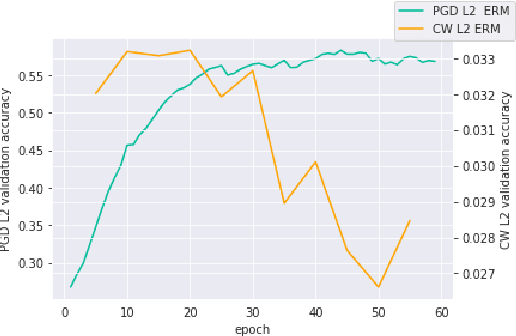
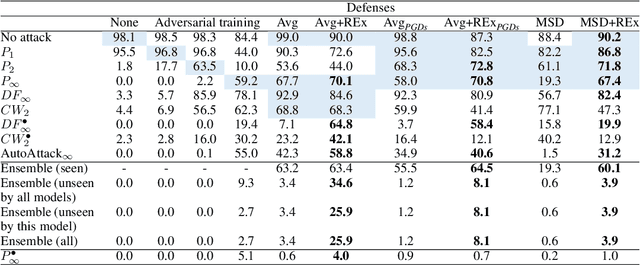
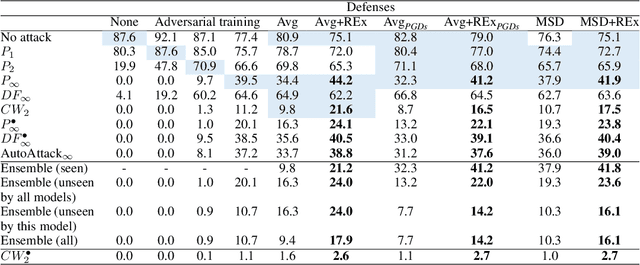
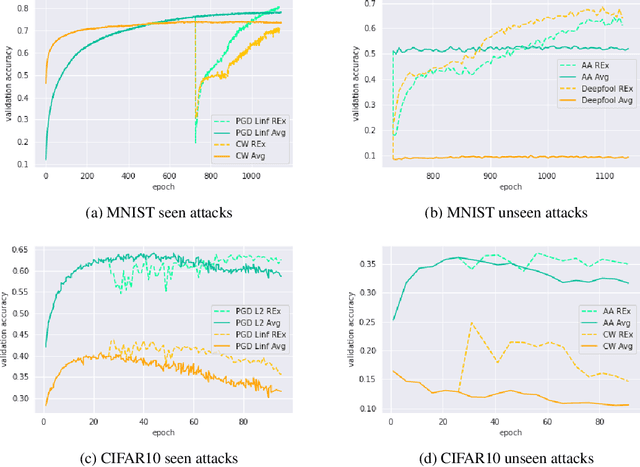
Adversarial robustness continues to be a major challenge for deep learning. A core issue is that robustness to one type of attack often fails to transfer to other attacks. While prior work establishes a theoretical trade-off in robustness against different $L_p$ norms, we show that there is potential for improvement against many commonly used attacks by adopting a domain generalisation approach. Concretely, we treat each type of attack as a domain, and apply the Risk Extrapolation method (REx), which promotes similar levels of robustness against all training attacks. Compared to existing methods, we obtain similar or superior worst-case adversarial robustness on attacks seen during training. Moreover, we achieve superior performance on families or tunings of attacks only encountered at test time. On ensembles of attacks, our approach improves the accuracy from 3.4% the best existing baseline to 25.9% on MNIST, and from 16.9% to 23.5% on CIFAR10.
Learning Robust Kernel Ensembles with Kernel Average Pooling
Sep 30, 2022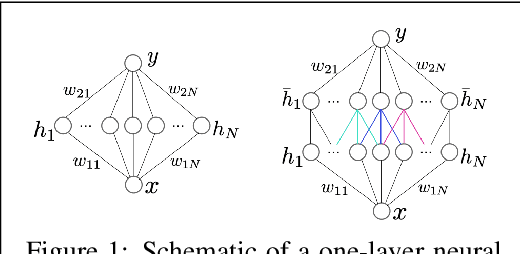

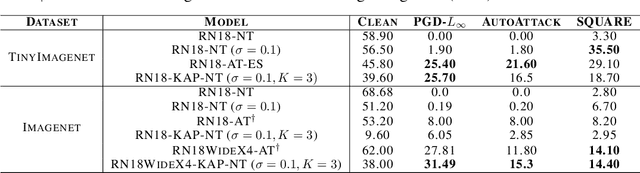
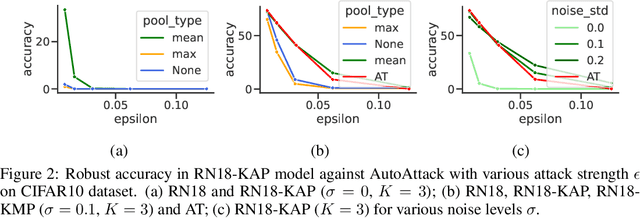
Model ensembles have long been used in machine learning to reduce the variance in individual model predictions, making them more robust to input perturbations. Pseudo-ensemble methods like dropout have also been commonly used in deep learning models to improve generalization. However, the application of these techniques to improve neural networks' robustness against input perturbations remains underexplored. We introduce Kernel Average Pool (KAP), a new neural network building block that applies the mean filter along the kernel dimension of the layer activation tensor. We show that ensembles of kernels with similar functionality naturally emerge in convolutional neural networks equipped with KAP and trained with backpropagation. Moreover, we show that when combined with activation noise, KAP models are remarkably robust against various forms of adversarial attacks. Empirical evaluations on CIFAR10, CIFAR100, TinyImagenet, and Imagenet datasets show substantial improvements in robustness against strong adversarial attacks such as AutoAttack that are on par with adversarially trained networks but are importantly obtained without training on any adversarial examples.
Adversarial Feature Desensitization
Jun 08, 2020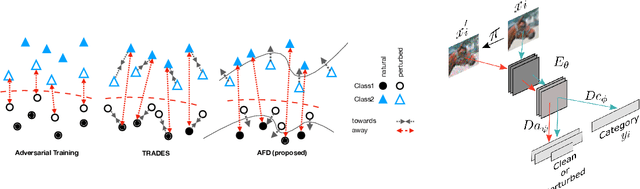
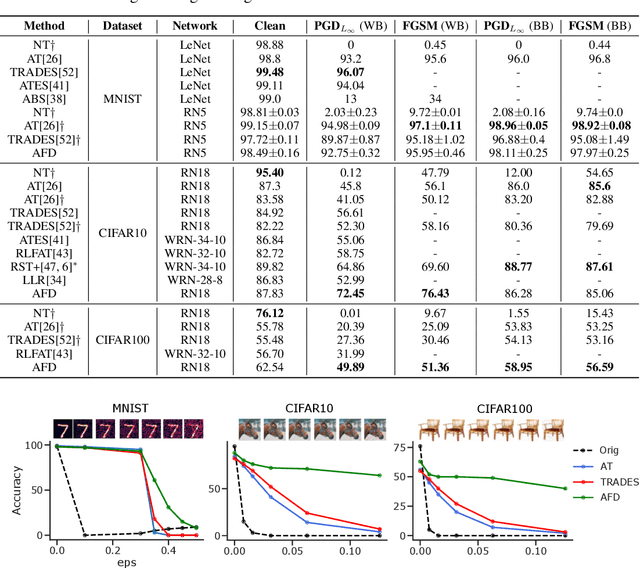
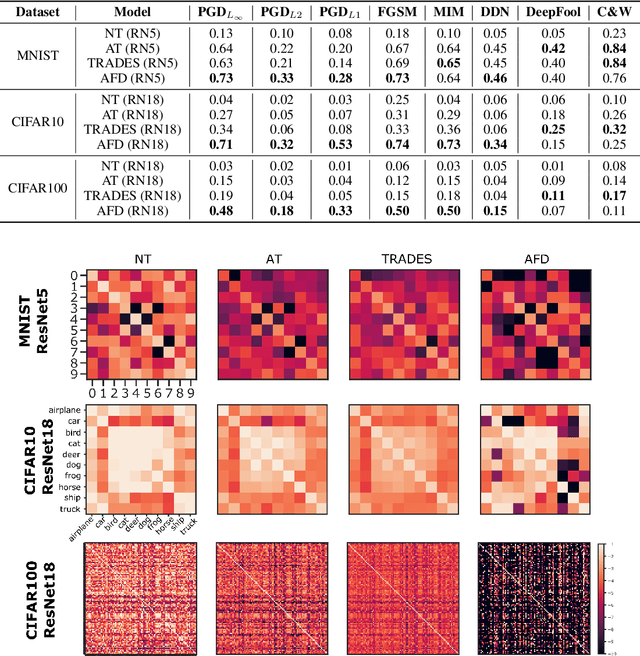
Deep neural networks can now perform many tasks that were once thought to be only feasible for humans. Unfortunately, while reaching impressive performance under standard settings, such networks are known to be susceptible to adversarial attacks -- slight but carefully constructed perturbations of the inputs which drastically decrease the network performance and reduce their trustworthiness. Here we propose to improve network robustness to input perturbations via an adversarial training procedure which we call Adversarial Feature Desensitization (AFD). We augment the normal supervised training with an adversarial game between the embedding network and an additional adversarial decoder which is trained to discriminate between the clean and perturbed inputs from their high-level embeddings. Our theoretical and empirical evidence acknowledges the effectiveness of this approach in learning robust features on MNIST, CIFAR10, and CIFAR100 datasets -- substantially improving the state-of-the-art in robust classification against previously observed adversarial attacks. More importantly, we demonstrate that AFD has better generalization ability than previous methods, as the learned features maintain their robustness against a large range of perturbations, including perturbations not seen during training. These results indicate that reducing feature sensitivity using adversarial training is a promising approach for ameliorating the problem of adversarial attacks in deep neural networks.