 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation
Feb 23, 2022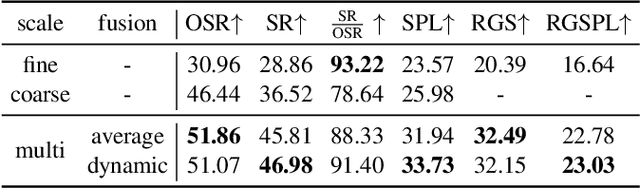
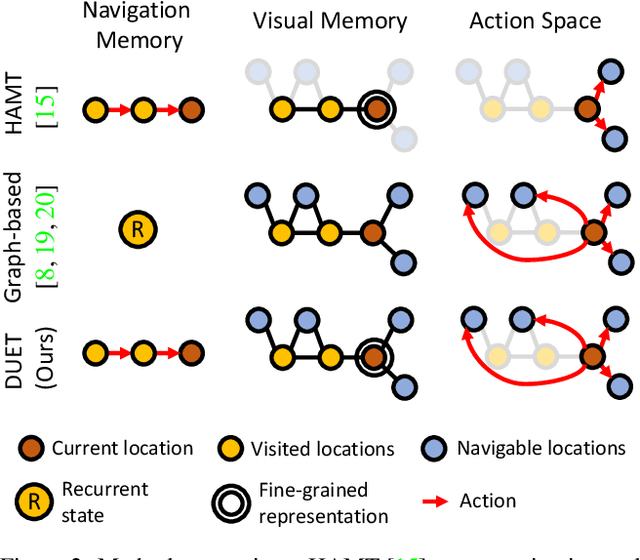
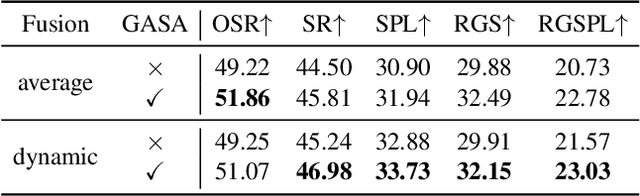
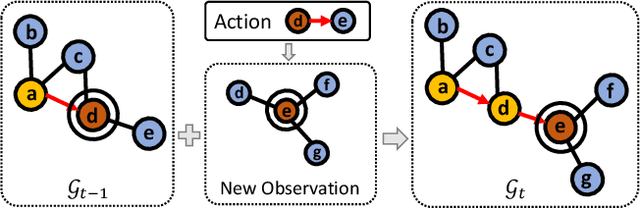
Following language instructions to navigate in unseen environments is a challenging problem for autonomous embodied agents. The agent not only needs to ground languages in visual scenes, but also should explore the environment to reach its target. In this work, we propose a dual-scale graph transformer (DUET) for joint long-term action planning and fine-grained cross-modal understanding. We build a topological map on-the-fly to enable efficient exploration in global action space. To balance the complexity of large action space reasoning and fine-grained language grounding, we dynamically combine a fine-scale encoding over local observations and a coarse-scale encoding on a global map via graph transformers. The proposed approach, DUET, significantly outperforms state-of-the-art methods on goal-oriented vision-and-language navigation (VLN) benchmarks REVERIE and SOON. It also improves the success rate on the fine-grained VLN benchmark R2R.
History Aware Multimodal Transformer for Vision-and-Language Navigation
Oct 25, 2021

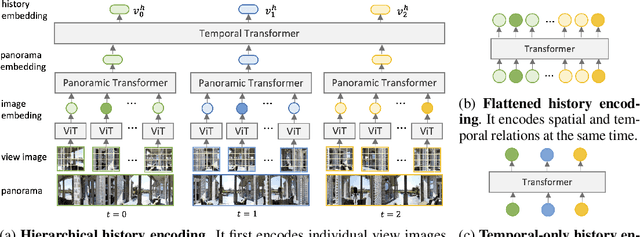

Vision-and-language navigation (VLN) aims to build autonomous visual agents that follow instructions and navigate in real scenes. To remember previously visited locations and actions taken, most approaches to VLN implement memory using recurrent states. Instead, we introduce a History Aware Multimodal Transformer (HAMT) to incorporate a long-horizon history into multimodal decision making. HAMT efficiently encodes all the past panoramic observations via a hierarchical vision transformer (ViT), which first encodes individual images with ViT, then models spatial relation between images in a panoramic observation and finally takes into account temporal relation between panoramas in the history. It, then, jointly combines text, history and current observation to predict the next action. We first train HAMT end-to-end using several proxy tasks including single step action prediction and spatial relation prediction, and then use reinforcement learning to further improve the navigation policy. HAMT achieves new state of the art on a broad range of VLN tasks, including VLN with fine-grained instructions (R2R, RxR), high-level instructions (R2R-Last, REVERIE), dialogs (CVDN) as well as long-horizon VLN (R4R, R2R-Back). We demonstrate HAMT to be particularly effective for navigation tasks with longer trajectories.
Product-oriented Machine Translation with Cross-modal Cross-lingual Pre-training
Aug 25, 2021
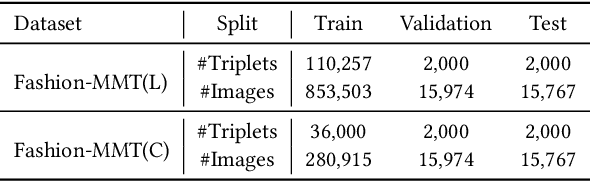

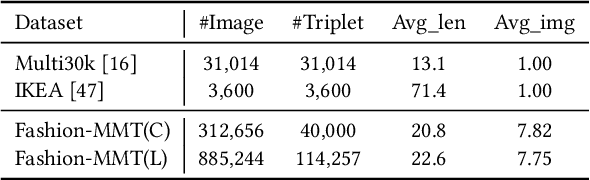
Translating e-commercial product descriptions, a.k.a product-oriented machine translation (PMT), is essential to serve e-shoppers all over the world. However, due to the domain specialty, the PMT task is more challenging than traditional machine translation problems. Firstly, there are many specialized jargons in the product description, which are ambiguous to translate without the product image. Secondly, product descriptions are related to the image in more complicated ways than standard image descriptions, involving various visual aspects such as objects, shapes, colors or even subjective styles. Moreover, existing PMT datasets are small in scale to support the research. In this paper, we first construct a large-scale bilingual product description dataset called Fashion-MMT, which contains over 114k noisy and 40k manually cleaned description translations with multiple product images. To effectively learn semantic alignments among product images and bilingual texts in translation, we design a unified product-oriented cross-modal cross-lingual model (\upoc~) for pre-training and fine-tuning. Experiments on the Fashion-MMT and Multi30k datasets show that our model significantly outperforms the state-of-the-art models even pre-trained on the same dataset. It is also shown to benefit more from large-scale noisy data to improve the translation quality. We will release the dataset and codes at https://github.com/syuqings/Fashion-MMT.
Airbert: In-domain Pretraining for Vision-and-Language Navigation
Aug 20, 2021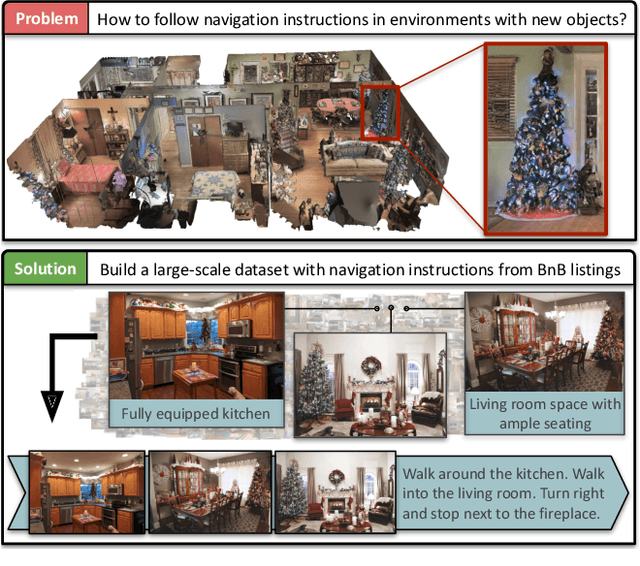
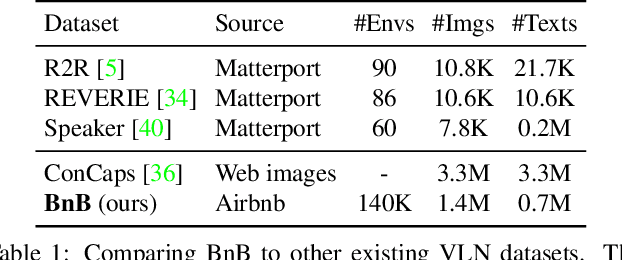

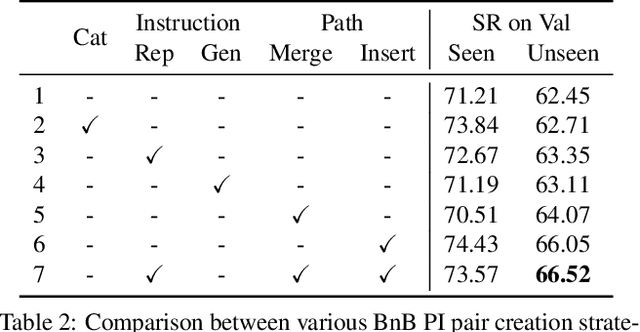
Vision-and-language navigation (VLN) aims to enable embodied agents to navigate in realistic environments using natural language instructions. Given the scarcity of domain-specific training data and the high diversity of image and language inputs, the generalization of VLN agents to unseen environments remains challenging. Recent methods explore pretraining to improve generalization, however, the use of generic image-caption datasets or existing small-scale VLN environments is suboptimal and results in limited improvements. In this work, we introduce BnB, a large-scale and diverse in-domain VLN dataset. We first collect image-caption (IC) pairs from hundreds of thousands of listings from online rental marketplaces. Using IC pairs we next propose automatic strategies to generate millions of VLN path-instruction (PI) pairs. We further propose a shuffling loss that improves the learning of temporal order inside PI pairs. We use BnB pretrain our Airbert model that can be adapted to discriminative and generative settings and show that it outperforms state of the art for Room-to-Room (R2R) navigation and Remote Referring Expression (REVERIE) benchmarks. Moreover, our in-domain pretraining significantly increases performance on a challenging few-shot VLN evaluation, where we train the model only on VLN instructions from a few houses.
Elaborative Rehearsal for Zero-shot Action Recognition
Aug 18, 2021

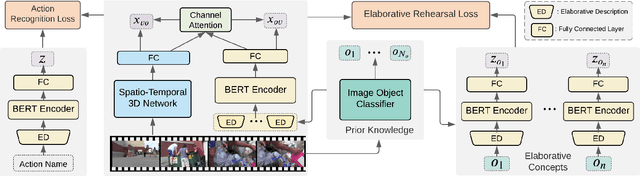
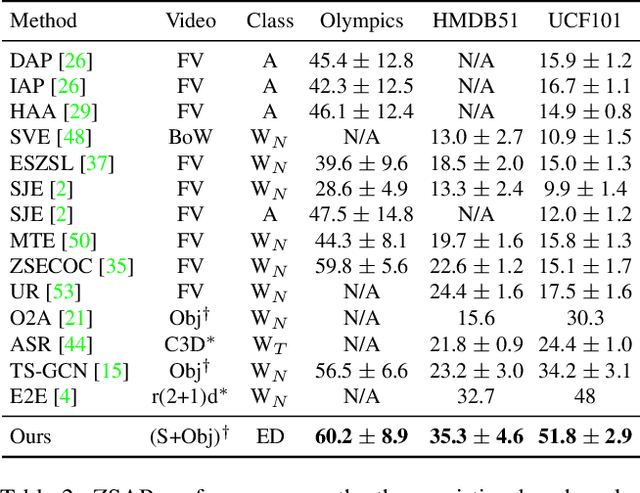
The growing number of action classes has posed a new challenge for video understanding, making Zero-Shot Action Recognition (ZSAR) a thriving direction. The ZSAR task aims to recognize target (unseen) actions without training examples by leveraging semantic representations to bridge seen and unseen actions. However, due to the complexity and diversity of actions, it remains challenging to semantically represent action classes and transfer knowledge from seen data. In this work, we propose an ER-enhanced ZSAR model inspired by an effective human memory technique Elaborative Rehearsal (ER), which involves elaborating a new concept and relating it to known concepts. Specifically, we expand each action class as an Elaborative Description (ED) sentence, which is more discriminative than a class name and less costly than manual-defined attributes. Besides directly aligning class semantics with videos, we incorporate objects from the video as Elaborative Concepts (EC) to improve video semantics and generalization from seen actions to unseen actions. Our ER-enhanced ZSAR model achieves state-of-the-art results on three existing benchmarks. Moreover, we propose a new ZSAR evaluation protocol on the Kinetics dataset to overcome limitations of current benchmarks and demonstrate the first case where ZSAR performance is comparable to few-shot learning baselines on this more realistic setting. We will release our codes and collected EDs at https://github.com/DeLightCMU/ElaborativeRehearsal.
Question-controlled Text-aware Image Captioning
Aug 04, 2021

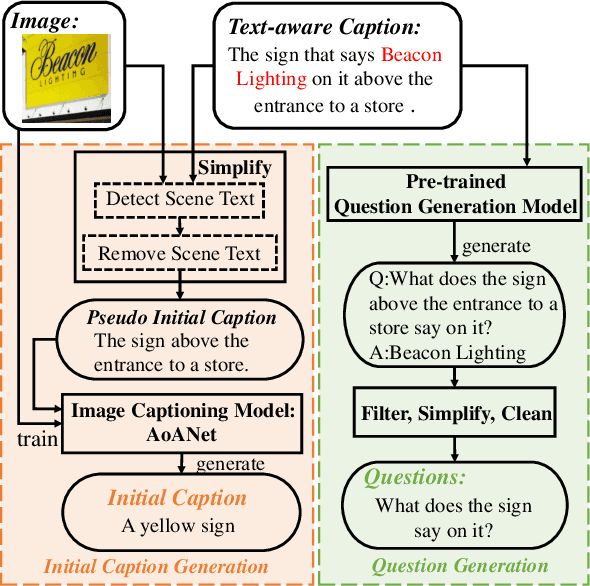
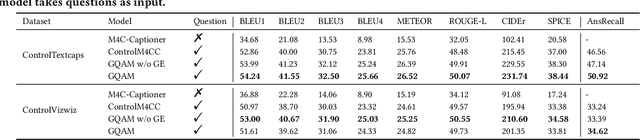
For an image with multiple scene texts, different people may be interested in different text information. Current text-aware image captioning models are not able to generate distinctive captions according to various information needs. To explore how to generate personalized text-aware captions, we define a new challenging task, namely Question-controlled Text-aware Image Captioning (Qc-TextCap). With questions as control signals, this task requires models to understand questions, find related scene texts and describe them together with objects fluently in human language. Based on two existing text-aware captioning datasets, we automatically construct two datasets, ControlTextCaps and ControlVizWiz to support the task. We propose a novel Geometry and Question Aware Model (GQAM). GQAM first applies a Geometry-informed Visual Encoder to fuse region-level object features and region-level scene text features with considering spatial relationships. Then, we design a Question-guided Encoder to select the most relevant visual features for each question. Finally, GQAM generates a personalized text-aware caption with a Multimodal Decoder. Our model achieves better captioning performance and question answering ability than carefully designed baselines on both two datasets. With questions as control signals, our model generates more informative and diverse captions than the state-of-the-art text-aware captioning model. Our code and datasets are publicly available at https://github.com/HAWLYQ/Qc-TextCap.
ICECAP: Information Concentrated Entity-aware Image Captioning
Aug 04, 2021
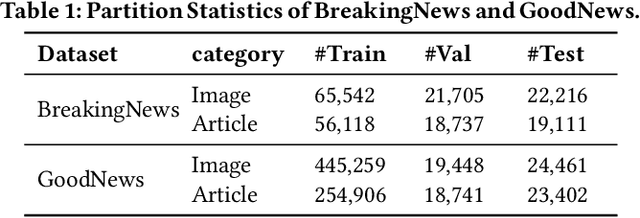
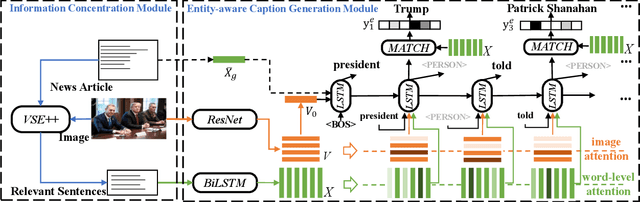
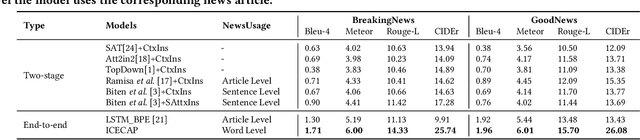
Most current image captioning systems focus on describing general image content, and lack background knowledge to deeply understand the image, such as exact named entities or concrete events. In this work, we focus on the entity-aware news image captioning task which aims to generate informative captions by leveraging the associated news articles to provide background knowledge about the target image. However, due to the length of news articles, previous works only employ news articles at the coarse article or sentence level, which are not fine-grained enough to refine relevant events and choose named entities accurately. To overcome these limitations, we propose an Information Concentrated Entity-aware news image CAPtioning (ICECAP) model, which progressively concentrates on relevant textual information within the corresponding news article from the sentence level to the word level. Our model first creates coarse concentration on relevant sentences using a cross-modality retrieval model and then generates captions by further concentrating on relevant words within the sentences. Extensive experiments on both BreakingNews and GoodNews datasets demonstrate the effectiveness of our proposed method, which outperforms other state-of-the-arts. The code of ICECAP is publicly available at https://github.com/HAWLYQ/ICECAP.
Team RUC_AIM3 Technical Report at ActivityNet 2021: Entities Object Localization
Jun 11, 2021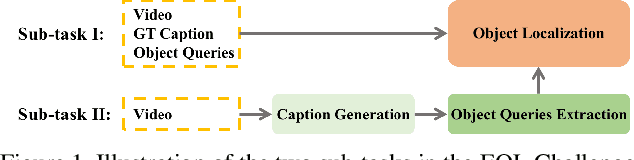
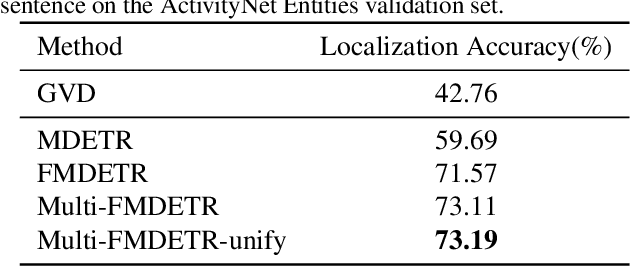
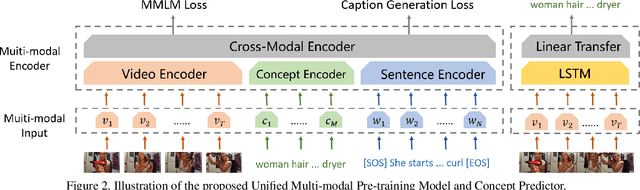
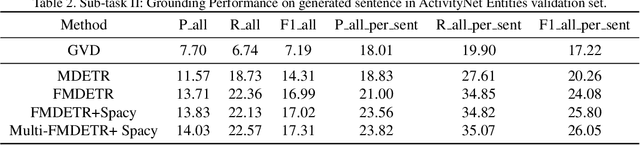
Entities Object Localization (EOL) aims to evaluate how grounded or faithful a description is, which consists of caption generation and object grounding. Previous works tackle this problem by jointly training the two modules in a framework, which limits the complexity of each module. Therefore, in this work, we propose to divide these two modules into two stages and improve them respectively to boost the whole system performance. For the caption generation, we propose a Unified Multi-modal Pre-training Model (UMPM) to generate event descriptions with rich objects for better localization. For the object grounding, we fine-tune the state-of-the-art detection model MDETR and design a post processing method to make the grounding results more faithful. Our overall system achieves the state-of-the-art performances on both sub-tasks in Entities Object Localization challenge at Activitynet 2021, with 72.57 localization accuracy on the testing set of sub-task I and 0.2477 F1_all_per_sent on the hidden testing set of sub-task II.
Towards Diverse Paragraph Captioning for Untrimmed Videos
May 30, 2021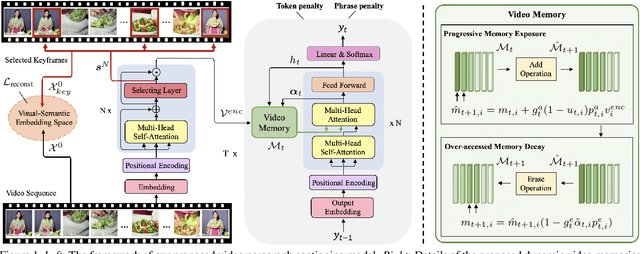
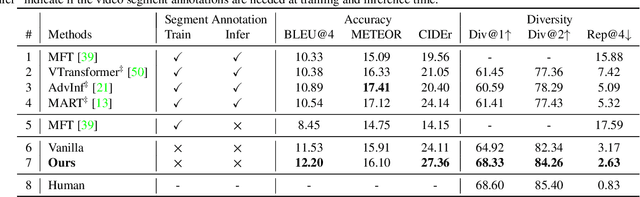
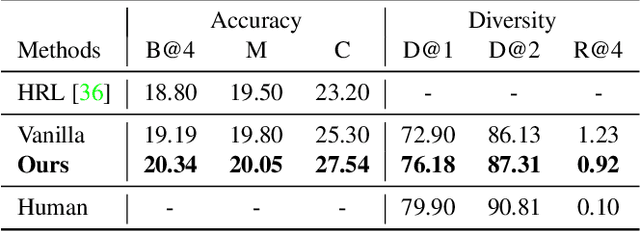
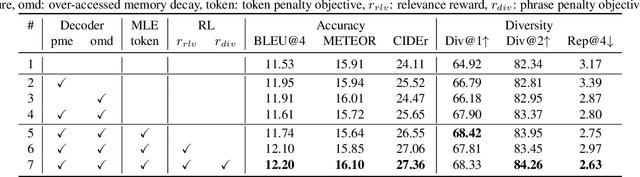
Video paragraph captioning aims to describe multiple events in untrimmed videos with descriptive paragraphs. Existing approaches mainly solve the problem in two steps: event detection and then event captioning. Such two-step manner makes the quality of generated paragraphs highly dependent on the accuracy of event proposal detection which is already a challenging task. In this paper, we propose a paragraph captioning model which eschews the problematic event detection stage and directly generates paragraphs for untrimmed videos. To describe coherent and diverse events, we propose to enhance the conventional temporal attention with dynamic video memories, which progressively exposes new video features and suppresses over-accessed video contents to control visual focuses of the model. In addition, a diversity-driven training strategy is proposed to improve diversity of paragraph on the language perspective. Considering that untrimmed videos generally contain massive but redundant frames, we further augment the video encoder with keyframe awareness to improve efficiency. Experimental results on the ActivityNet and Charades datasets show that our proposed model significantly outperforms the state-of-the-art performance on both accuracy and diversity metrics without using any event boundary annotations. Code will be released at https://github.com/syuqings/video-paragraph.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
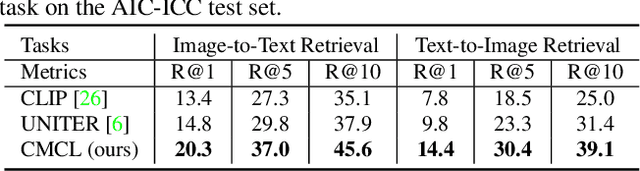
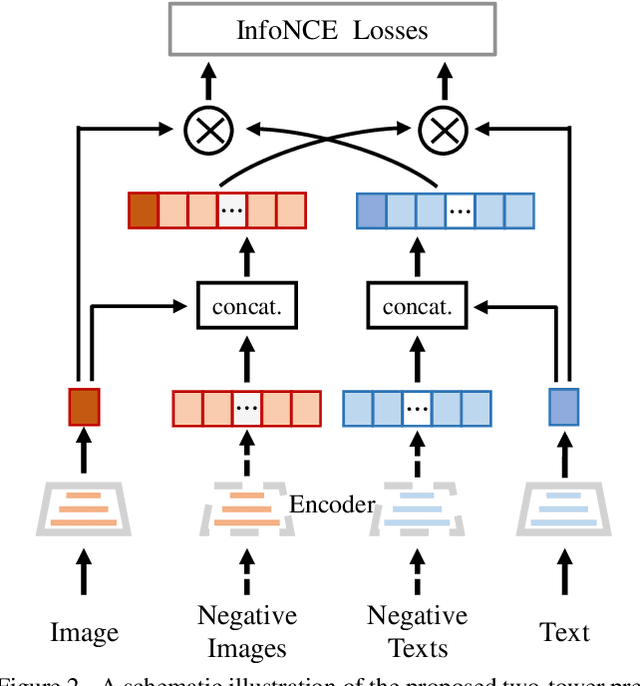
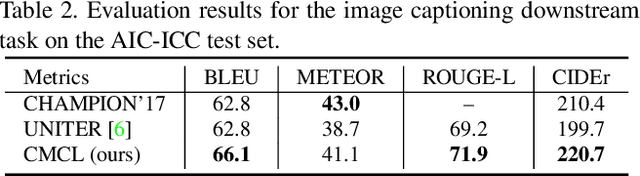
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.