 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployment-Efficient Reinforcement Learning via Model-Based Offline Optimization
Jun 23, 2020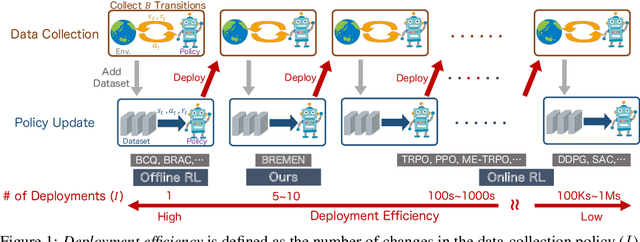
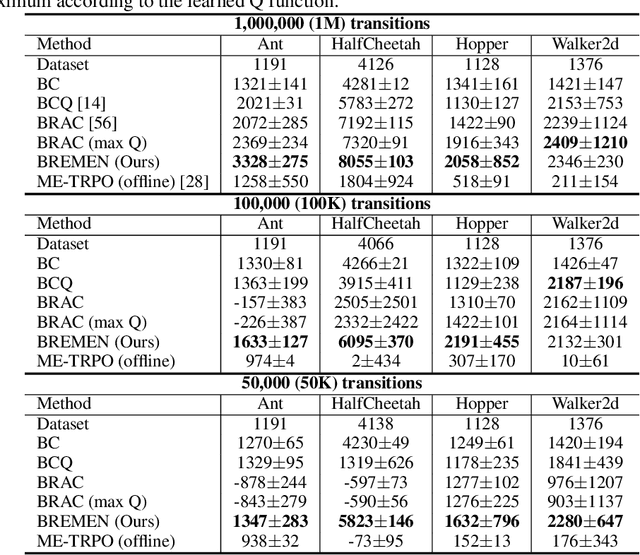
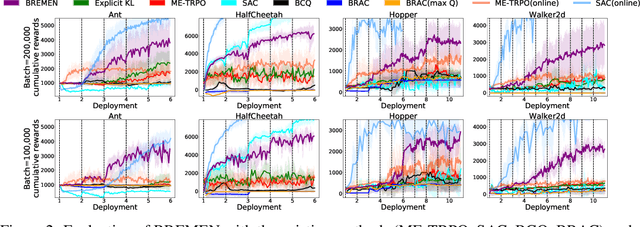

Most reinforcement learning (RL) algorithms assume online access to the environment, in which one may readily interleave updates to the policy with experience collection using that policy. However, in many real-world applications such as health, education, dialogue agents, and robotics, the cost or potential risk of deploying a new data-collection policy is high, to the point that it can become prohibitive to update the data-collection policy more than a few times during learning. With this view, we propose a novel concept of deployment efficiency, measuring the number of distinct data-collection policies that are used during policy learning. We observe that na\"{i}vely applying existing model-free offline RL algorithms recursively does not lead to a practical deployment-efficient and sample-efficient algorithm. We propose a novel model-based algorithm, Behavior-Regularized Model-ENsemble (BREMEN) that can effectively optimize a policy offline using 10-20 times fewer data than prior works. Furthermore, the recursive application of BREMEN is able to achieve impressive deployment efficiency while maintaining the same or better sample efficiency, learning successful policies from scratch on simulated robotic environments with only 5-10 deployments, compared to typical values of hundreds to millions in standard RL baselines. Codes and pre-trained models are available at https://github.com/matsuolab/BREMEN .
Emergent Real-World Robotic Skills via Unsupervised Off-Policy Reinforcement Learning
Apr 27, 2020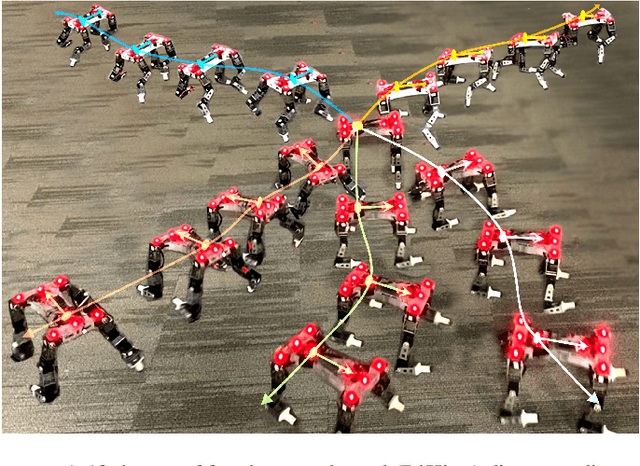
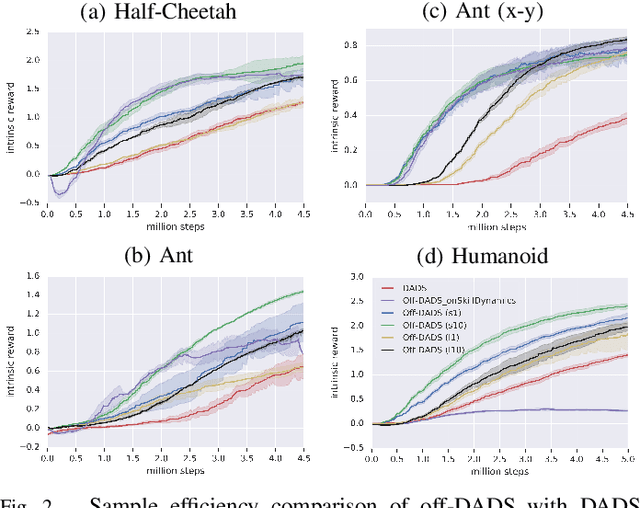


Reinforcement learning provides a general framework for learning robotic skills while minimizing engineering effort. However, most reinforcement learning algorithms assume that a well-designed reward function is provided, and learn a single behavior for that single reward function. Such reward functions can be difficult to design in practice. Can we instead develop efficient reinforcement learning methods that acquire diverse skills without any reward function, and then repurpose these skills for downstream tasks? In this paper, we demonstrate that a recently proposed unsupervised skill discovery algorithm can be extended into an efficient off-policy method, making it suitable for performing unsupervised reinforcement learning in the real world. Firstly, we show that our proposed algorithm provides substantial improvement in learning efficiency, making reward-free real-world training feasible. Secondly, we move beyond the simulation environments and evaluate the algorithm on real physical hardware. On quadrupeds, we observe that locomotion skills with diverse gaits and different orientations emerge without any rewards or demonstrations. We also demonstrate that the learned skills can be composed using model predictive control for goal-oriented navigation, without any additional training.
A Divergence Minimization Perspective on Imitation Learning Methods
Nov 06, 2019
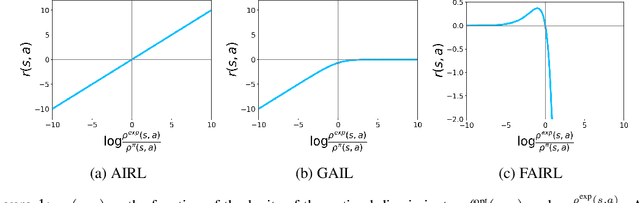
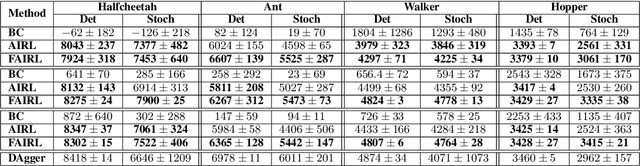
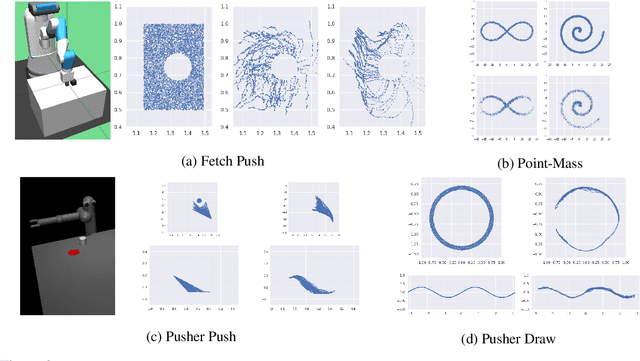
In many settings, it is desirable to learn decision-making and control policies through learning or bootstrapping from expert demonstrations. The most common approaches under this Imitation Learning (IL) framework are Behavioural Cloning (BC), and Inverse Reinforcement Learning (IRL). Recent methods for IRL have demonstrated the capacity to learn effective policies with access to a very limited set of demonstrations, a scenario in which BC methods often fail. Unfortunately, due to multiple factors of variation, directly comparing these methods does not provide adequate intuition for understanding this difference in performance. In this work, we present a unified probabilistic perspective on IL algorithms based on divergence minimization. We present $f$-MAX, an $f$-divergence generalization of AIRL [Fu et al., 2018], a state-of-the-art IRL method. $f$-MAX enables us to relate prior IRL methods such as GAIL [Ho & Ermon, 2016] and AIRL [Fu et al., 2018], and understand their algorithmic properties. Through the lens of divergence minimization we tease apart the differences between BC and successful IRL approaches, and empirically evaluate these nuances on simulated high-dimensional continuous control domains. Our findings conclusively identify that IRL's state-marginal matching objective contributes most to its superior performance. Lastly, we apply our new understanding of IL methods to the problem of state-marginal matching, where we demonstrate that in simulated arm pushing environments we can teach agents a diverse range of behaviours using simply hand-specified state distributions and no reward functions or expert demonstrations. For datasets and reproducing results please refer to https://github.com/KamyarGh/rl_swiss/blob/master/reproducing/fmax_paper.md .
Why Does Hierarchy Work So Well in Reinforcement Learning?
Sep 23, 2019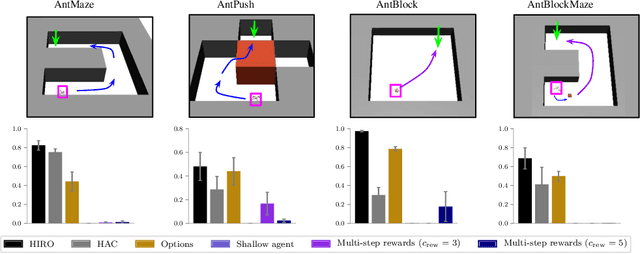
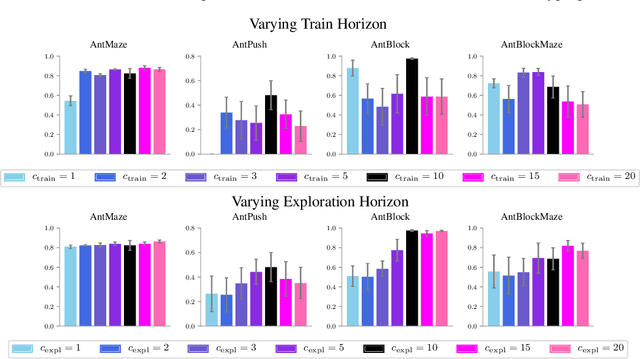
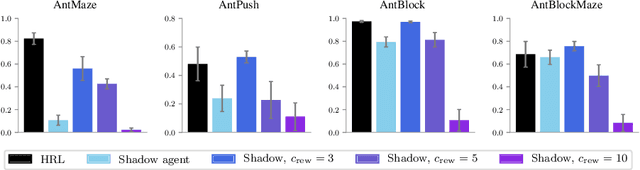
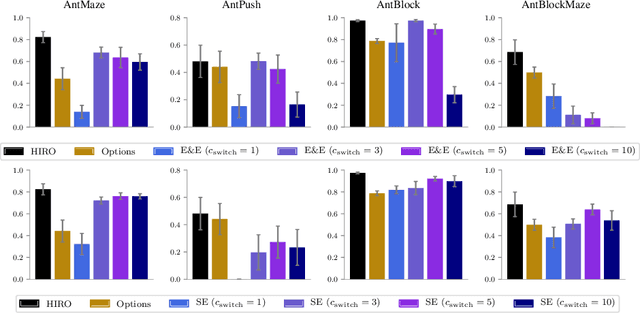
Hierarchical reinforcement learning has demonstrated significant success at solving difficult reinforcement learning (RL) tasks. Previous works have motivated the use of hierarchy by appealing to a number of intuitive benefits, including learning over temporally extended transitions, exploring over temporally extended periods, and training and exploring in a more semantically meaningful action space, among others. However, in fully observed, Markovian settings, it is not immediately clear why hierarchical RL should provide benefits over standard "shallow" RL architectures. In this work, we isolate and evaluate the claimed benefits of hierarchical RL on a suite of tasks encompassing locomotion, navigation, and manipulation. Surprisingly, we find that most of the observed benefits of hierarchy can be attributed to improved exploration, as opposed to easier policy learning or imposed hierarchical structures. Given this insight, we present exploration techniques inspired by hierarchy that achieve performance competitive with hierarchical RL while at the same time being much simpler to use and implement.
Multi-Agent Manipulation via Locomotion using Hierarchical Sim2Real
Aug 13, 2019

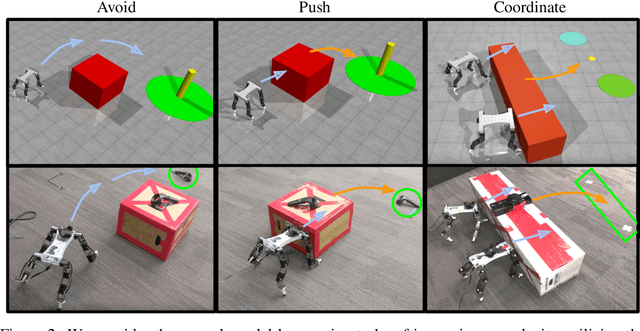

Manipulation and locomotion are closely related problems that are often studied in isolation. In this work, we study the problem of coordinating multiple mobile agents to exhibit manipulation behaviors using a reinforcement learning (RL) approach. Our method hinges on the use of hierarchical sim2real -- a simulated environment is used to learn low-level goal-reaching skills, which are then used as the action space for a high-level RL controller, also trained in simulation. The full hierarchical policy is then transferred to the real world in a zero-shot fashion. The application of domain randomization during training enables the learned behaviors to generalize to real-world settings, while the use of hierarchy provides a modular paradigm for learning and transferring increasingly complex behaviors. We evaluate our method on a number of real-world tasks, including coordinated object manipulation in a multi-agent setting. See videos at https://sites.google.com/view/manipulation-via-locomotion
Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Jul 08, 2019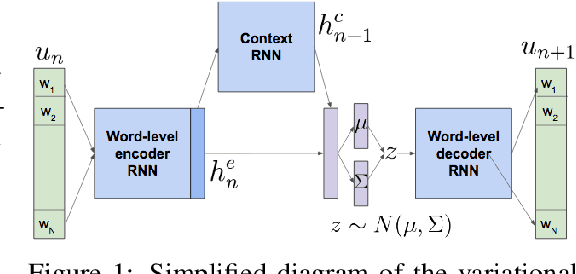
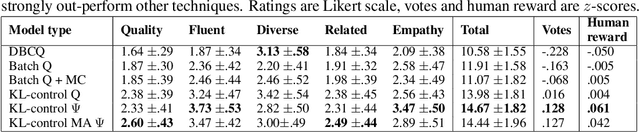

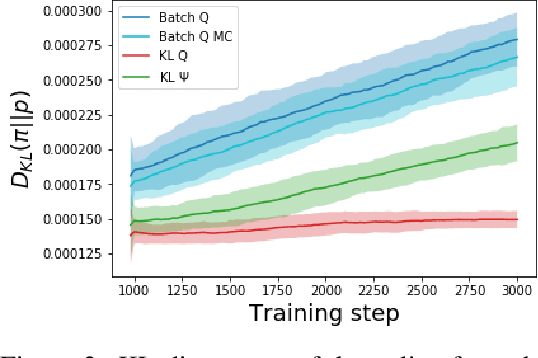
Most deep reinforcement learning (RL) systems are not able to learn effectively from off-policy data, especially if they cannot explore online in the environment. These are critical shortcomings for applying RL to real-world problems where collecting data is expensive, and models must be tested offline before being deployed to interact with the environment -- e.g. systems that learn from human interaction. Thus, we develop a novel class of off-policy batch RL algorithms, which are able to effectively learn offline, without exploring, from a fixed batch of human interaction data. We leverage models pre-trained on data as a strong prior, and use KL-control to penalize divergence from this prior during RL training. We also use dropout-based uncertainty estimates to lower bound the target Q-values as a more efficient alternative to Double Q-Learning. The algorithms are tested on the problem of open-domain dialog generation -- a challenging reinforcement learning problem with a 20,000-dimensional action space. Using our Way Off-Policy algorithm, we can extract multiple different reward functions post-hoc from collected human interaction data, and learn effectively from all of these. We test the real-world generalization of these systems by deploying them live to converse with humans in an open-domain setting, and demonstrate that our algorithm achieves significant improvements over prior methods in off-policy batch RL.
Dynamics-Aware Unsupervised Discovery of Skills
Jul 02, 2019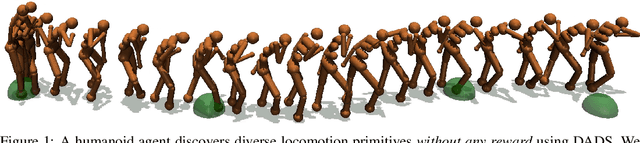
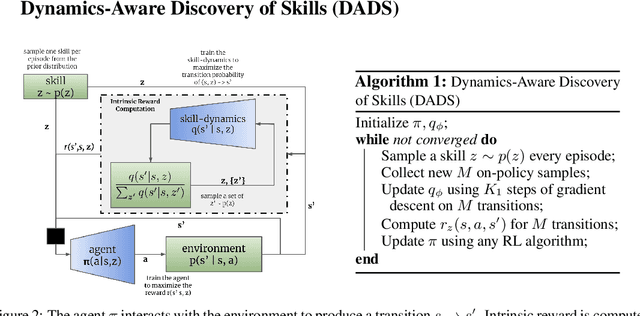
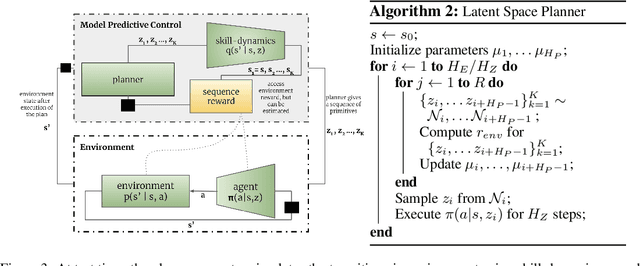

Conventionally, model-based reinforcement learning (MBRL) aims to learn a global model for the dynamics of the environment. A good model can potentially enable planning algorithms to generate a large variety of behaviors and solve diverse tasks. However, learning an accurate model for complex dynamical systems is difficult, and even then, the model might not generalize well outside the distribution of states on which it was trained. In this work, we combine model-based learning with model-free learning of primitives that make model-based planning easy. To that end, we aim to answer the question: how can we discover skills whose outcomes are easy to predict? We propose an unsupervised learning algorithm, Dynamics-Aware Discovery of Skills (DADS), which simultaneously discovers predictable behaviors and learns their dynamics. Our method can leverage continuous skill spaces, theoretically, allowing us to learn infinitely many behaviors even for high-dimensional state-spaces. We demonstrate that zero-shot planning in the learned latent space significantly outperforms standard MBRL and model-free goal-conditioned RL, can handle sparse-reward tasks, and substantially improves over prior hierarchical RL methods for unsupervised skill discovery.
Language as an Abstraction for Hierarchical Deep Reinforcement Learning
Jun 18, 2019
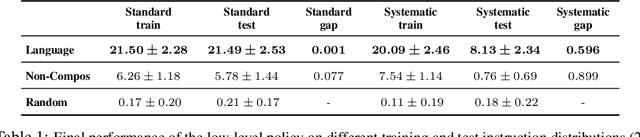
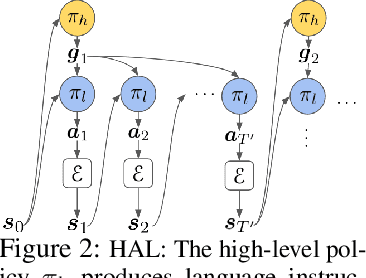
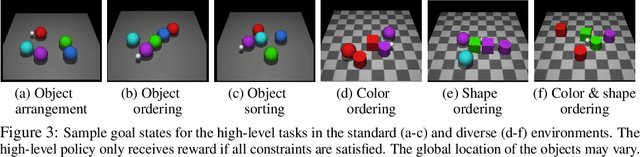
Solving complex, temporally-extended tasks is a long-standing problem in reinforcement learning (RL). We hypothesize that one critical element of solving such problems is the notion of compositionality. With the ability to learn concepts and sub-skills that can be composed to solve longer tasks, i.e. hierarchical RL, we can acquire temporally-extended behaviors. However, acquiring effective yet general abstractions for hierarchical RL is remarkably challenging. In this paper, we propose to use language as the abstraction, as it provides unique compositional structure, enabling fast learning and combinatorial generalization, while retaining tremendous flexibility, making it suitable for a variety of problems. Our approach learns an instruction-following low-level policy and a high-level policy that can reuse abstractions across tasks, in essence, permitting agents to reason using structured language. To study compositional task learning, we introduce an open-source object interaction environment built using the MuJoCo physics engine and the CLEVR engine. We find that, using our approach, agents can learn to solve to diverse, temporally-extended tasks such as object sorting and multi-object rearrangement, including from raw pixel observations. Our analysis find that the compositional nature of language is critical for learning diverse sub-skills and systematically generalizing to new sub-skills in comparison to non-compositional abstractions that use the same supervision.
Doubly Reparameterized Gradient Estimators for Monte Carlo Objectives
Oct 09, 2018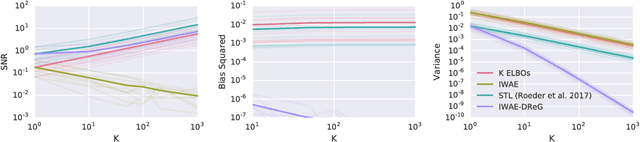
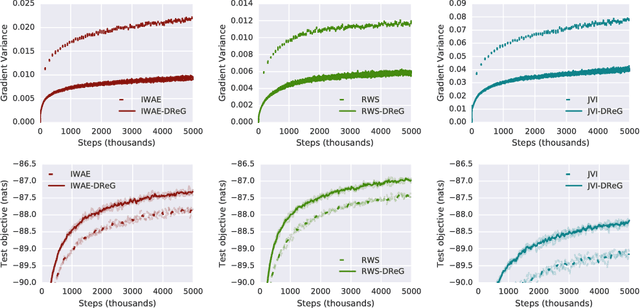
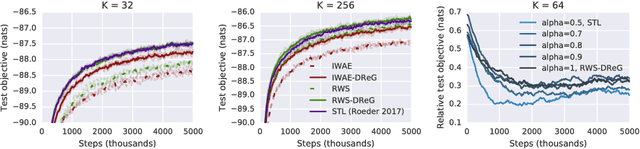
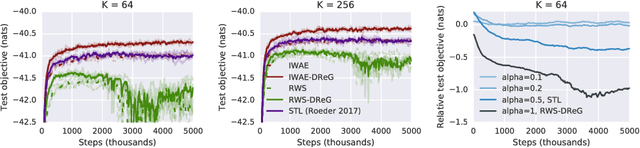
Deep latent variable models have become a popular model choice due to the scalable learning algorithms introduced by (Kingma & Welling, 2013; Rezende et al., 2014). These approaches maximize a variational lower bound on the intractable log likelihood of the observed data. Burda et al. (2015) introduced a multi-sample variational bound, IWAE, that is at least as tight as the standard variational lower bound and becomes increasingly tight as the number of samples increases. Counterintuitively, the typical inference network gradient estimator for the IWAE bound performs poorly as the number of samples increases (Rainforth et al., 2018; Le et al., 2018). Roeder et al. (2017) propose an improved gradient estimator, however, are unable to show it is unbiased. We show that it is in fact biased and that the bias can be estimated efficiently with a second application of the reparameterization trick. The doubly reparameterized gradient (DReG) estimator does not suffer as the number of samples increases, resolving the previously raised issues. The same idea can be used to improve many recently introduced training techniques for latent variable models. In particular, we show that this estimator reduces the variance of the IWAE gradient, the reweighted wake-sleep update (RWS) (Bornschein & Bengio, 2014), and the jackknife variational inference (JVI) gradient (Nowozin, 2018). Finally, we show that this computationally efficient, unbiased drop-in gradient estimator translates to improved performance for all three objectives on several modeling tasks.
Data-Efficient Hierarchical Reinforcement Learning
Oct 05, 2018
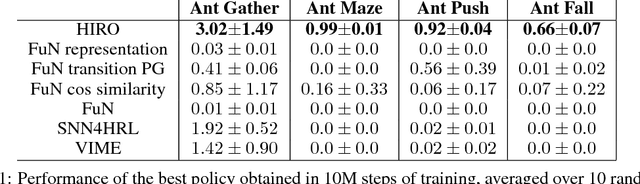
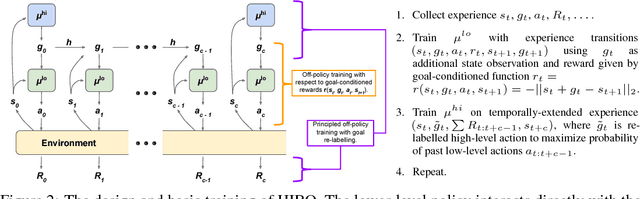
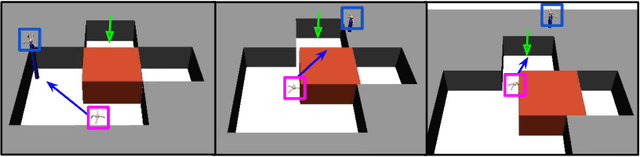
Hierarchical reinforcement learning (HRL) is a promising approach to extend traditional reinforcement learning (RL) methods to solve more complex tasks. Yet, the majority of current HRL methods require careful task-specific design and on-policy training, making them difficult to apply in real-world scenarios. In this paper, we study how we can develop HRL algorithms that are general, in that they do not make onerous additional assumptions beyond standard RL algorithms, and efficient, in the sense that they can be used with modest numbers of interaction samples, making them suitable for real-world problems such as robotic control. For generality, we develop a scheme where lower-level controllers are supervised with goals that are learned and proposed automatically by the higher-level controllers. To address efficiency, we propose to use off-policy experience for both higher and lower-level training. This poses a considerable challenge, since changes to the lower-level behaviors change the action space for the higher-level policy, and we introduce an off-policy correction to remedy this challenge. This allows us to take advantage of recent advances in off-policy model-free RL to learn both higher- and lower-level policies using substantially fewer environment interactions than on-policy algorithms. We term the resulting HRL agent HIRO and find that it is generally applicable and highly sample-efficient. Our experiments show that HIRO can be used to learn highly complex behaviors for simulated robots, such as pushing objects and utilizing them to reach target locations, learning from only a few million samples, equivalent to a few days of real-time interaction. In comparisons with a number of prior HRL methods, we find that our approach substantially outperforms previous state-of-the-art techniques.