 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransRef: Multi-Scale Reference Embedding Transformer for Reference-Guided Image Inpainting
Jun 21, 2023



Image inpainting for completing complicated semantic environments and diverse hole patterns of corrupted images is challenging even for state-of-the-art learning-based inpainting methods trained on large-scale data. A reference image capturing the same scene of a corrupted image offers informative guidance for completing the corrupted image as it shares similar texture and structure priors to that of the holes of the corrupted image. In this work, we propose a transformer-based encoder-decoder network, named TransRef, for reference-guided image inpainting. Specifically, the guidance is conducted progressively through a reference embedding procedure, in which the referencing features are subsequently aligned and fused with the features of the corrupted image. For precise utilization of the reference features for guidance, a reference-patch alignment (Ref-PA) module is proposed to align the patch features of the reference and corrupted images and harmonize their style differences, while a reference-patch transformer (Ref-PT) module is proposed to refine the embedded reference feature. Moreover, to facilitate the research of reference-guided image restoration tasks, we construct a publicly accessible benchmark dataset containing 50K pairs of input and reference images. Both quantitative and qualitative evaluations demonstrate the efficacy of the reference information and the proposed method over the state-of-the-art methods in completing complex holes. Code and dataset can be accessed at https://github.com/Cameltr/TransRef.
Rethinking Adversarial Training with A Simple Baseline
Jun 13, 2023



We report competitive results on RobustBench for CIFAR and SVHN using a simple yet effective baseline approach. Our approach involves a training protocol that integrates rescaled square loss, cyclic learning rates, and erasing-based data augmentation. The outcomes we have achieved are comparable to those of the model trained with state-of-the-art techniques, which is currently the predominant choice for adversarial training. Our baseline, referred to as SimpleAT, yields three novel empirical insights. (i) By switching to square loss, the accuracy is comparable to that obtained by using both de-facto training protocol plus data augmentation. (ii) One cyclic learning rate is a good scheduler, which can effectively reduce the risk of robust overfitting. (iii) Employing rescaled square loss during model training can yield a favorable balance between adversarial and natural accuracy. In general, our experimental results show that SimpleAT effectively mitigates robust overfitting and consistently achieves the best performance at the end of training. For example, on CIFAR-10 with ResNet-18, SimpleAT achieves approximately 52% adversarial accuracy against the current strong AutoAttack. Furthermore, SimpleAT exhibits robust performance on various image corruptions, including those commonly found in CIFAR-10-C dataset. Finally, we assess the effectiveness of these insights through two techniques: bias-variance analysis and logit penalty methods. Our findings demonstrate that all of these simple techniques are capable of reducing the variance of model predictions, which is regarded as the primary contributor to robust overfitting. In addition, our analysis also uncovers connections with various advanced state-of-the-art methods.
Certified Zeroth-order Black-Box Defense with Robust UNet Denoiser
Apr 13, 2023



Certified defense methods against adversarial perturbations have been recently investigated in the black-box setting with a zeroth-order (ZO) perspective. However, these methods suffer from high model variance with low performance on high-dimensional datasets due to the ineffective design of the denoiser and are limited in their utilization of ZO techniques. To this end, we propose a certified ZO preprocessing technique for removing adversarial perturbations from the attacked image in the black-box setting using only model queries. We propose a robust UNet denoiser (RDUNet) that ensures the robustness of black-box models trained on high-dimensional datasets. We propose a novel black-box denoised smoothing (DS) defense mechanism, ZO-RUDS, by prepending our RDUNet to the black-box model, ensuring black-box defense. We further propose ZO-AE-RUDS in which RDUNet followed by autoencoder (AE) is prepended to the black-box model. We perform extensive experiments on four classification datasets, CIFAR-10, CIFAR-10, Tiny Imagenet, STL-10, and the MNIST dataset for image reconstruction tasks. Our proposed defense methods ZO-RUDS and ZO-AE-RUDS beat SOTA with a huge margin of $35\%$ and $9\%$, for low dimensional (CIFAR-10) and with a margin of $20.61\%$ and $23.51\%$ for high-dimensional (STL-10) datasets, respectively.
Toward Verifiable and Reproducible Human Evaluation for Text-to-Image Generation
Apr 04, 2023



Human evaluation is critical for validating the performance of text-to-image generative models, as this highly cognitive process requires deep comprehension of text and images. However, our survey of 37 recent papers reveals that many works rely solely on automatic measures (e.g., FID) or perform poorly described human evaluations that are not reliable or repeatable. This paper proposes a standardized and well-defined human evaluation protocol to facilitate verifiable and reproducible human evaluation in future works. In our pilot data collection, we experimentally show that the current automatic measures are incompatible with human perception in evaluating the performance of the text-to-image generation results. Furthermore, we provide insights for designing human evaluation experiments reliably and conclusively. Finally, we make several resources publicly available to the community to facilitate easy and fast implementations.
DisCO: Portrait Distortion Correction with Perspective-Aware 3D GANs
Feb 23, 2023Close-up facial images captured at close distances often suffer from perspective distortion, resulting in exaggerated facial features and unnatural/unattractive appearances. We propose a simple yet effective method for correcting perspective distortions in a single close-up face. We first perform GAN inversion using a perspective-distorted input facial image by jointly optimizing the camera intrinsic/extrinsic parameters and face latent code. To address the ambiguity of joint optimization, we develop focal length reparametrization, optimization scheduling, and geometric regularization. Re-rendering the portrait at a proper focal length and camera distance effectively corrects these distortions and produces more natural-looking results. Our experiments show that our method compares favorably against previous approaches regarding visual quality. We showcase numerous examples validating the applicability of our method on portrait photos in the wild.
HOTCOLD Block: Fooling Thermal Infrared Detectors with a Novel Wearable Design
Dec 12, 2022



Adversarial attacks on thermal infrared imaging expose the risk of related applications. Estimating the security of these systems is essential for safely deploying them in the real world. In many cases, realizing the attacks in the physical space requires elaborate special perturbations. These solutions are often \emph{impractical} and \emph{attention-grabbing}. To address the need for a physically practical and stealthy adversarial attack, we introduce \textsc{HotCold} Block, a novel physical attack for infrared detectors that hide persons utilizing the wearable Warming Paste and Cooling Paste. By attaching these readily available temperature-controlled materials to the body, \textsc{HotCold} Block evades human eyes efficiently. Moreover, unlike existing methods that build adversarial patches with complex texture and structure features, \textsc{HotCold} Block utilizes an SSP-oriented adversarial optimization algorithm that enables attacks with pure color blocks and explores the influence of size, shape, and position on attack performance. Extensive experimental results in both digital and physical environments demonstrate the performance of our proposed \textsc{HotCold} Block. \emph{Code is available: \textcolor{magenta}{https://github.com/weihui1308/HOTCOLDBlock}}.
Self-distillation with Online Diffusion on Batch Manifolds Improves Deep Metric Learning
Nov 14, 2022Recent deep metric learning (DML) methods typically leverage solely class labels to keep positive samples far away from negative ones. However, this type of method normally ignores the crucial knowledge hidden in the data (e.g., intra-class information variation), which is harmful to the generalization of the trained model. To alleviate this problem, in this paper we propose Online Batch Diffusion-based Self-Distillation (OBD-SD) for DML. Specifically, we first propose a simple but effective Progressive Self-Distillation (PSD), which distills the knowledge progressively from the model itself during training. The soft distance targets achieved by PSD can present richer relational information among samples, which is beneficial for the diversity of embedding representations. Then, we extend PSD with an Online Batch Diffusion Process (OBDP), which is to capture the local geometric structure of manifolds in each batch, so that it can reveal the intrinsic relationships among samples in the batch and produce better soft distance targets. Note that our OBDP is able to restore the insufficient manifold relationships obtained by the original PSD and achieve significant performance improvement. Our OBD-SD is a flexible framework that can be integrated into state-of-the-art (SOTA) DML methods. Extensive experiments on various benchmarks, namely CUB200, CARS196, and Stanford Online Products, demonstrate that our OBD-SD consistently improves the performance of the existing DML methods on multiple datasets with negligible additional training time, achieving very competitive results. Code: \url{https://github.com/ZelongZeng/OBD-SD_Pytorch}
Multiple Object Tracking from appearance by hierarchically clustering tracklets
Oct 07, 2022
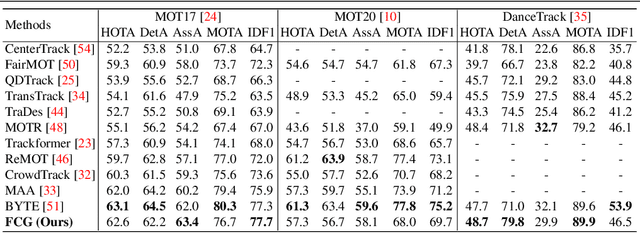

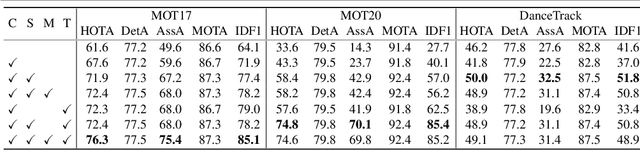
Current approaches in Multiple Object Tracking (MOT) rely on the spatio-temporal coherence between detections combined with object appearance to match objects from consecutive frames. In this work, we explore MOT using object appearances as the main source of association between objects in a video, using spatial and temporal priors as weighting factors. We form initial tracklets by leveraging on the idea that instances of an object that are close in time should be similar in appearance, and build the final object tracks by fusing the tracklets in a hierarchical fashion. We conduct extensive experiments that show the effectiveness of our method over three different MOT benchmarks, MOT17, MOT20, and DanceTrack, being competitive in MOT17 and MOT20 and establishing state-of-the-art results in DanceTrack.
Physical Adversarial Attack meets Computer Vision: A Decade Survey
Sep 30, 2022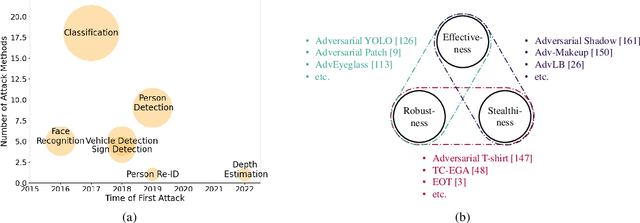
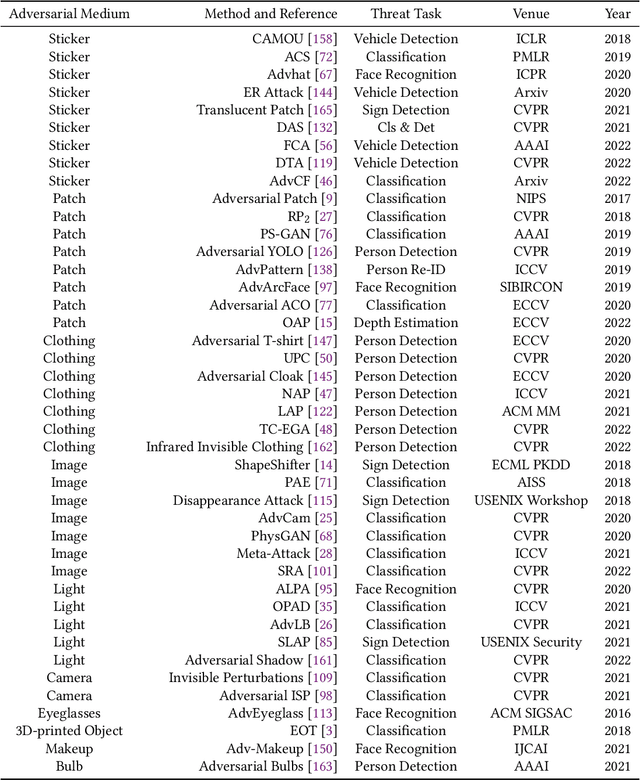

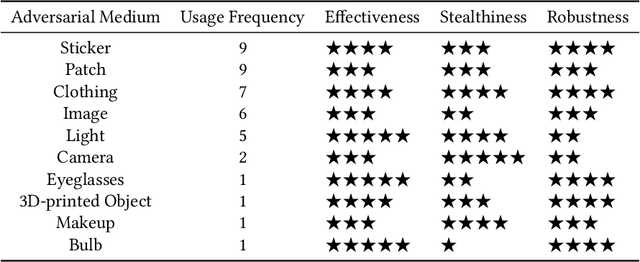
Although Deep Neural Networks (DNNs) have achieved impressive results in computer vision, their exposed vulnerability to adversarial attacks remains a serious concern. A series of works has shown that by adding elaborate perturbations to images, DNNs could have catastrophic degradation in performance metrics. And this phenomenon does not only exist in the digital space but also in the physical space. Therefore, estimating the security of these DNNs-based systems is critical for safely deploying them in the real world, especially for security-critical applications, e.g., autonomous cars, video surveillance, and medical diagnosis. In this paper, we focus on physical adversarial attacks and provide a comprehensive survey of over 150 existing papers. We first clarify the concept of the physical adversarial attack and analyze its characteristics. Then, we define the adversarial medium, essential to perform attacks in the physical world. Next, we present the physical adversarial attack methods in task order: classification, detection, and re-identification, and introduce their performance in solving the trilemma: effectiveness, stealthiness, and robustness. In the end, we discuss the current challenges and potential future directions.
Reference-Guided Texture and Structure Inference for Image Inpainting
Jul 29, 2022
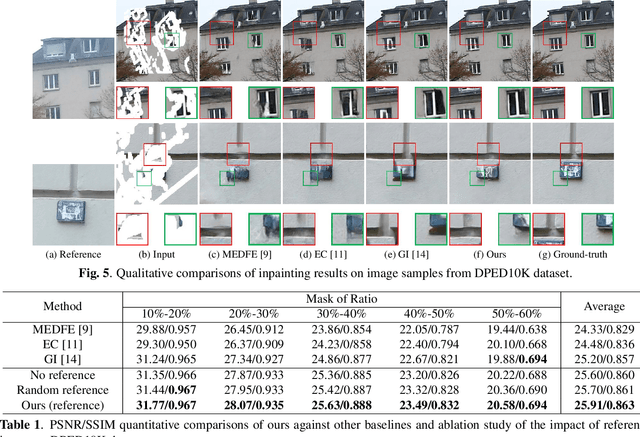

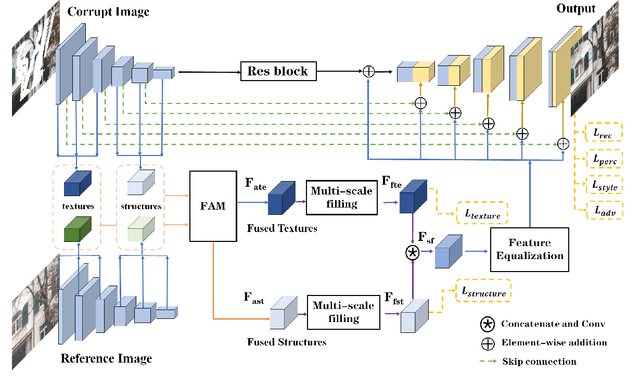
Existing learning-based image inpainting methods are still in challenge when facing complex semantic environments and diverse hole patterns. The prior information learned from the large scale training data is still insufficient for these situations. Reference images captured covering the same scenes share similar texture and structure priors with the corrupted images, which offers new prospects for the image inpainting tasks. Inspired by this, we first build a benchmark dataset containing 10K pairs of input and reference images for reference-guided inpainting. Then we adopt an encoder-decoder structure to separately infer the texture and structure features of the input image considering their pattern discrepancy of texture and structure during inpainting. A feature alignment module is further designed to refine these features of the input image with the guidance of a reference image. Both quantitative and qualitative evaluations demonstrate the superiority of our method over the state-of-the-art methods in terms of completing complex holes.