 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Online Domain Adaptive Semantic Segmentation under Adverse Weather Conditions
Sep 02, 2024



Online Domain Adaptation (OnDA) is designed to handle unforeseeable domain changes at minimal cost that occur during the deployment of the model, lacking clear boundaries between the domain, such as sudden weather events. However, existing OnDA methods that rely solely on the model itself to adapt to the current domain often misidentify ambiguous classes amidst continuous domain shifts and pass on this erroneous knowledge to the next domain. To tackle this, we propose \textbf{RODASS}, a \textbf{R}obust \textbf{O}nline \textbf{D}omain \textbf{A}daptive \textbf{S}emantic \textbf{S}egmentation framework, which dynamically detects domain shifts and adjusts hyper-parameters to minimize training costs and error propagation. Specifically, we introduce the \textbf{D}ynamic \textbf{A}mbiguous \textbf{P}atch \textbf{Mask} (\textbf{DAP Mask}) strategy, which dynamically selects highly disturbed regions and masks these regions, mitigating error accumulation in ambiguous classes and enhancing the model's robustness against external noise in dynamic natural environments. Additionally, we present the \textbf{D}ynamic \textbf{S}ource \textbf{C}lass \textbf{Mix} (\textbf{DSC Mix}), a domain-aware mix method that augments target domain scenes with class-level source buffers, reducing the high uncertainty and noisy labels, thereby accelerating adaptation and offering a more efficient solution for online domain adaptation. Our approach outperforms state-of-the-art methods on widely used OnDA benchmarks while maintaining approximately 40 frames per second (FPS).
TransRef: Multi-Scale Reference Embedding Transformer for Reference-Guided Image Inpainting
Jun 21, 2023



Image inpainting for completing complicated semantic environments and diverse hole patterns of corrupted images is challenging even for state-of-the-art learning-based inpainting methods trained on large-scale data. A reference image capturing the same scene of a corrupted image offers informative guidance for completing the corrupted image as it shares similar texture and structure priors to that of the holes of the corrupted image. In this work, we propose a transformer-based encoder-decoder network, named TransRef, for reference-guided image inpainting. Specifically, the guidance is conducted progressively through a reference embedding procedure, in which the referencing features are subsequently aligned and fused with the features of the corrupted image. For precise utilization of the reference features for guidance, a reference-patch alignment (Ref-PA) module is proposed to align the patch features of the reference and corrupted images and harmonize their style differences, while a reference-patch transformer (Ref-PT) module is proposed to refine the embedded reference feature. Moreover, to facilitate the research of reference-guided image restoration tasks, we construct a publicly accessible benchmark dataset containing 50K pairs of input and reference images. Both quantitative and qualitative evaluations demonstrate the efficacy of the reference information and the proposed method over the state-of-the-art methods in completing complex holes. Code and dataset can be accessed at https://github.com/Cameltr/TransRef.
Reference-Guided Texture and Structure Inference for Image Inpainting
Jul 29, 2022
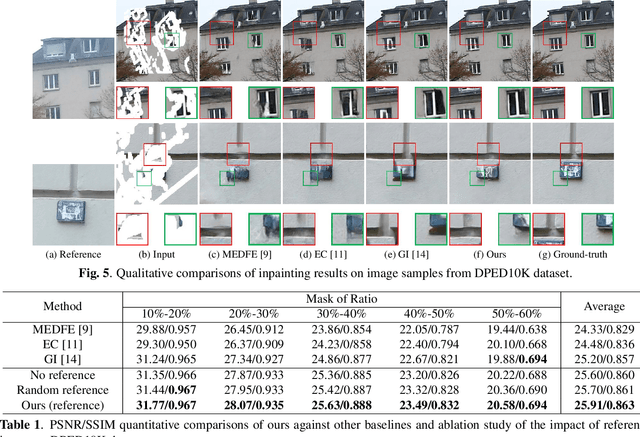

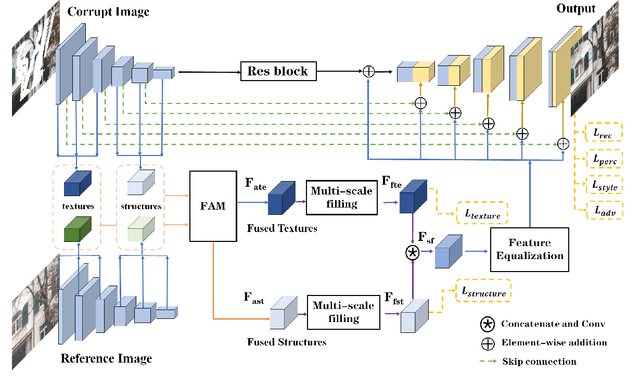
Existing learning-based image inpainting methods are still in challenge when facing complex semantic environments and diverse hole patterns. The prior information learned from the large scale training data is still insufficient for these situations. Reference images captured covering the same scenes share similar texture and structure priors with the corrupted images, which offers new prospects for the image inpainting tasks. Inspired by this, we first build a benchmark dataset containing 10K pairs of input and reference images for reference-guided inpainting. Then we adopt an encoder-decoder structure to separately infer the texture and structure features of the input image considering their pattern discrepancy of texture and structure during inpainting. A feature alignment module is further designed to refine these features of the input image with the guidance of a reference image. Both quantitative and qualitative evaluations demonstrate the superiority of our method over the state-of-the-art methods in terms of completing complex holes.