 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentGR: Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendation
May 11, 2026Group Recommendation (GR) aims to suggest items to a group of users, which has become a critical component of modern social platforms. Existing GR methods focus on aggregating individual user preferences with advanced neural networks to infer group preferences. Despite effectiveness, they essentially treat group preference learning as a simple preference aggregation process, failing to capture the complex dynamics of real-world group decision-making. To address these limitations, we propose AgentGR, a novel Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendations, inspired by the semantic reasoning and human behavior simulation capabilities of LLM-driven agents. It aims to jointly capture collaborative-semantic user preferences for member-role-playing and simulate dynamic group interactions to reflect real-world group decision-making processes, thereby boosting recommendation performance. Specifically, to capture collaborative-semantic user preferences, we introduce a semantic meta-path guided chain-of-preference reasoning mechanism that integrates high-order collaborative filtering signals and textual semantics to improve user preference profiles. To model the complex dynamics of group decision-making, we first recognize group topic and leadership to explicitly model the influencing factors within the group decision processes. Building on these, we simulate group-level decision dynamics via two multi-agent simulation strategies for recommendations: a static workflow-based strategy for efficiency and a dynamic dialogue-based strategy for precision. Extensive experiments on two real-world datasets show that AgentGR significantly outperforms state-of-the-art baselines in both recommendation accuracy and group decision simulation, highlighting its potential for real-world GR applications.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Utilizing Complex-valued Network for Learning to Compare Image Patches
Nov 29, 2018
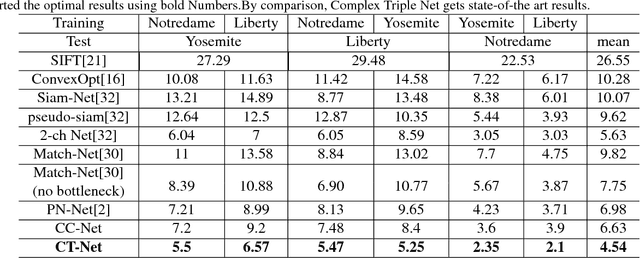
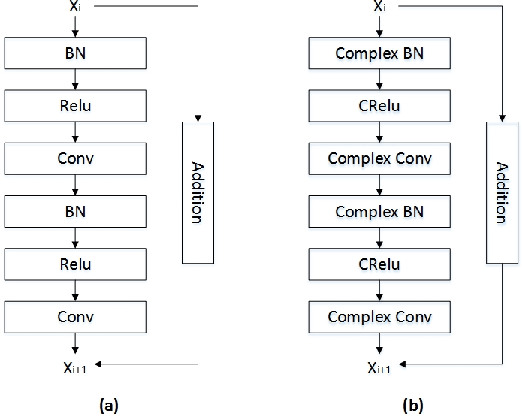

At present, the great achievements of convolutional neural network(CNN) in feature and metric learning have attracted many researchers. However, the vast majority of deep network architectures have been used to represent based on real values. The research of complex-valued networks is seldom concerned due to the absence of effective models and suitable distance of complex-valued vector. Motived by recent works, complex vectors have been shown to have a richer representational capacity and efficient complex blocks have been reported, we propose a new approach for learning image descriptors with complex numbers to compare image patches. We also propose a new architecture to learn image similarity function directly based on complex-valued network. We show that our models can significantly outperform the state-of-the art on benchmark datasets. We make the source code of our models publicly available.