 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGEITL: Scene Graph Enhanced Image-Text Learning for Visual Commonsense Reasoning
Dec 16, 2021

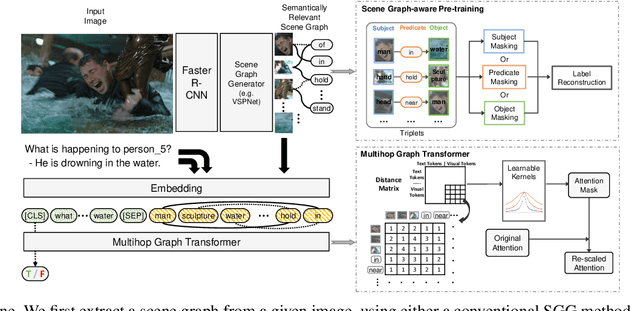

Answering complex questions about images is an ambitious goal for machine intelligence, which requires a joint understanding of images, text, and commonsense knowledge, as well as a strong reasoning ability. Recently, multimodal Transformers have made great progress in the task of Visual Commonsense Reasoning (VCR), by jointly understanding visual objects and text tokens through layers of cross-modality attention. However, these approaches do not utilize the rich structure of the scene and the interactions between objects which are essential in answering complex commonsense questions. We propose a Scene Graph Enhanced Image-Text Learning (SGEITL) framework to incorporate visual scene graphs in commonsense reasoning. To exploit the scene graph structure, at the model structure level, we propose a multihop graph transformer for regularizing attention interaction among hops. As for pre-training, a scene-graph-aware pre-training method is proposed to leverage structure knowledge extracted in the visual scene graph. Moreover, we introduce a method to train and generate domain-relevant visual scene graphs using textual annotations in a weakly-supervised manner. Extensive experiments on VCR and other tasks show a significant performance boost compared with the state-of-the-art methods and prove the efficacy of each proposed component.
* AAAI 2022
PreViTS: Contrastive Pretraining with Video Tracking Supervision
Dec 01, 2021
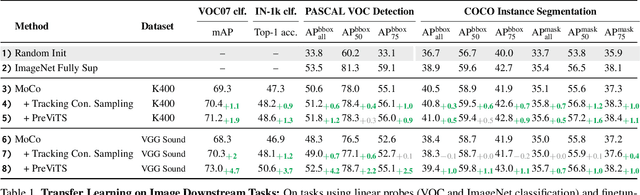
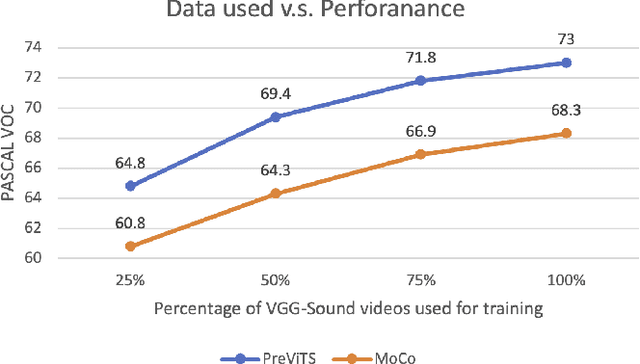
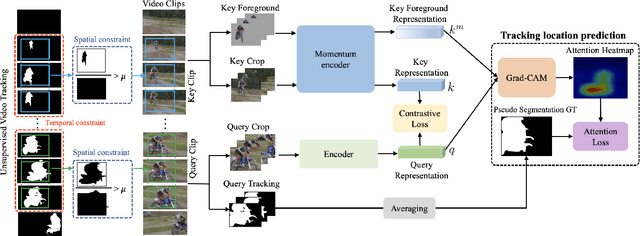
Videos are a rich source for self-supervised learning (SSL) of visual representations due to the presence of natural temporal transformations of objects. However, current methods typically randomly sample video clips for learning, which results in a poor supervisory signal. In this work, we propose PreViTS, an SSL framework that utilizes an unsupervised tracking signal for selecting clips containing the same object, which helps better utilize temporal transformations of objects. PreViTS further uses the tracking signal to spatially constrain the frame regions to learn from and trains the model to locate meaningful objects by providing supervision on Grad-CAM attention maps. To evaluate our approach, we train a momentum contrastive (MoCo) encoder on VGG-Sound and Kinetics-400 datasets with PreViTS. Training with PreViTS outperforms representations learnt by MoCo alone on both image recognition and video classification downstream tasks, obtaining state-of-the-art performance on action classification. PreViTS helps learn feature representations that are more robust to changes in background and context, as seen by experiments on image and video datasets with background changes. Learning from large-scale uncurated videos with PreViTS could lead to more accurate and robust visual feature representations.
Joint Multimedia Event Extraction from Video and Article
Sep 27, 2021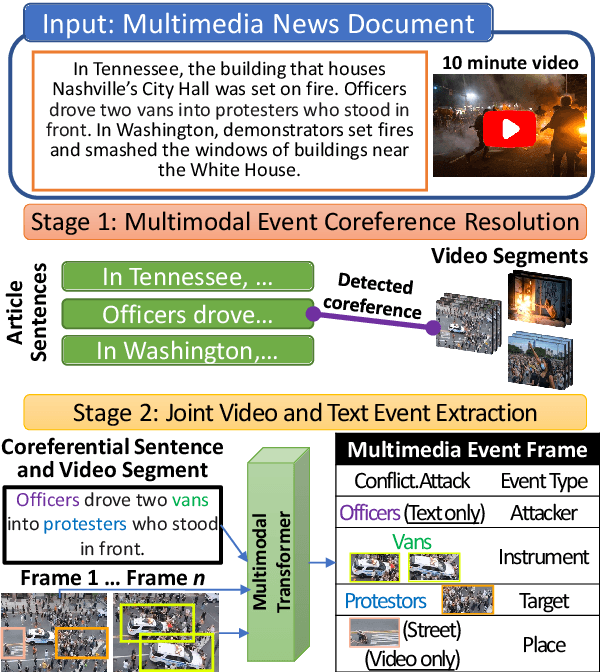
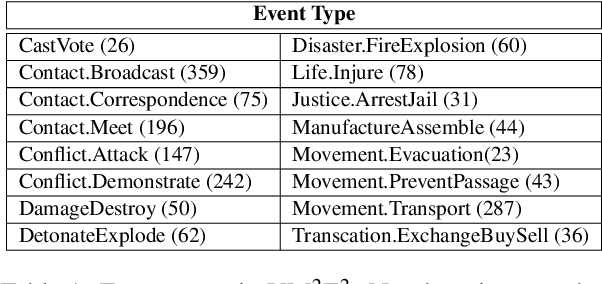


Visual and textual modalities contribute complementary information about events described in multimedia documents. Videos contain rich dynamics and detailed unfoldings of events, while text describes more high-level and abstract concepts. However, existing event extraction methods either do not handle video or solely target video while ignoring other modalities. In contrast, we propose the first approach to jointly extract events from video and text articles. We introduce the new task of Video MultiMedia Event Extraction (Video M2E2) and propose two novel components to build the first system towards this task. First, we propose the first self-supervised multimodal event coreference model that can determine coreference between video events and text events without any manually annotated pairs. Second, we introduce the first multimodal transformer which extracts structured event information jointly from both videos and text documents. We also construct and will publicly release a new benchmark of video-article pairs, consisting of 860 video-article pairs with extensive annotations for evaluating methods on this task. Our experimental results demonstrate the effectiveness of our proposed method on our new benchmark dataset. We achieve 6.0% and 5.8% absolute F-score gain on multimodal event coreference resolution and multimedia event extraction.
Partner-Assisted Learning for Few-Shot Image Classification
Sep 15, 2021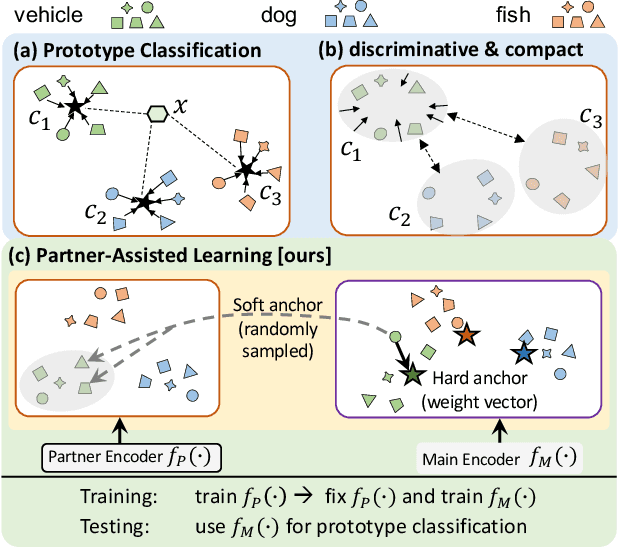
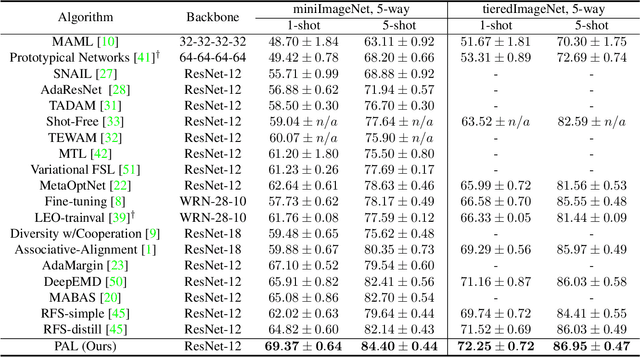
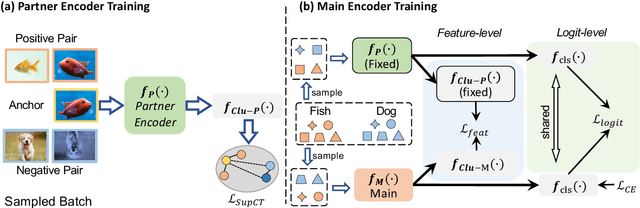
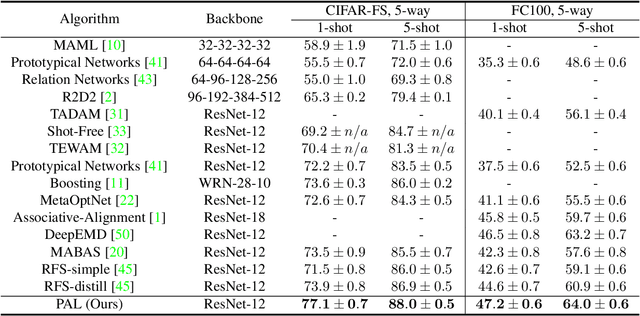
Few-shot Learning has been studied to mimic human visual capabilities and learn effective models without the need of exhaustive human annotation. Even though the idea of meta-learning for adaptation has dominated the few-shot learning methods, how to train a feature extractor is still a challenge. In this paper, we focus on the design of training strategy to obtain an elemental representation such that the prototype of each novel class can be estimated from a few labeled samples. We propose a two-stage training scheme, Partner-Assisted Learning (PAL), which first trains a partner encoder to model pair-wise similarities and extract features serving as soft-anchors, and then trains a main encoder by aligning its outputs with soft-anchors while attempting to maximize classification performance. Two alignment constraints from logit-level and feature-level are designed individually. For each few-shot task, we perform prototype classification. Our method consistently outperforms the state-of-the-art method on four benchmarks. Detailed ablation studies of PAL are provided to justify the selection of each component involved in training.
Multimodal Clustering Networks for Self-supervised Learning from Unlabeled Videos
May 05, 2021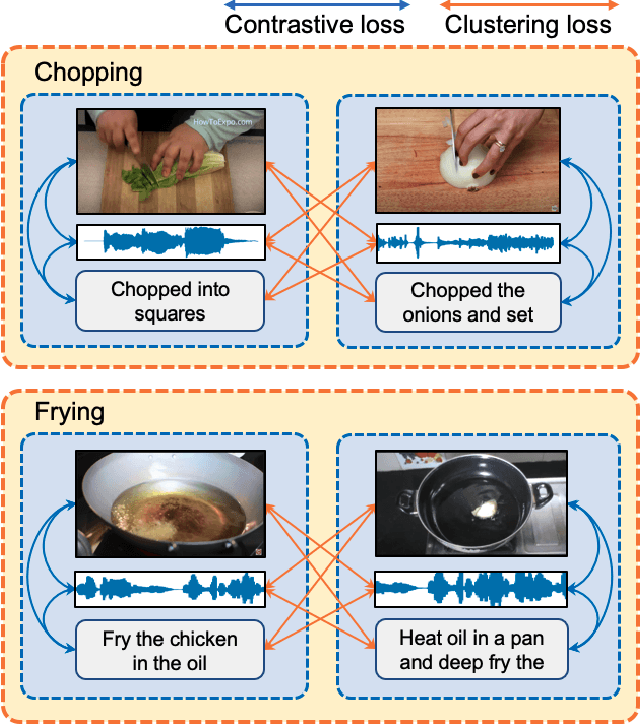
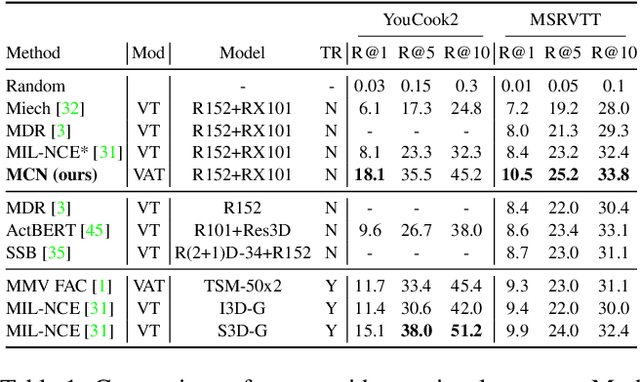
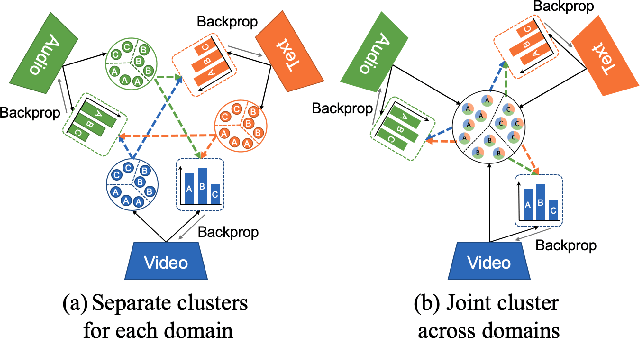
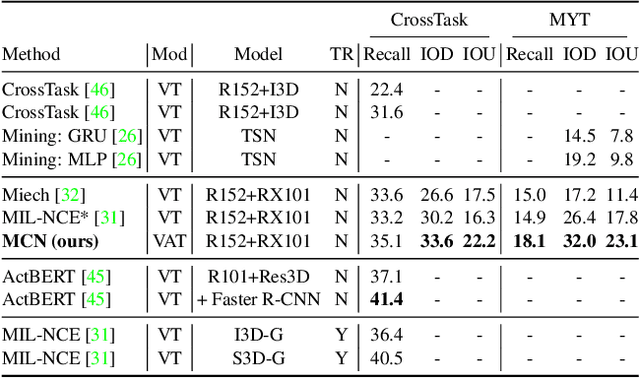
Multimodal self-supervised learning is getting more and more attention as it allows not only to train large networks without human supervision but also to search and retrieve data across various modalities. In this context, this paper proposes a self-supervised training framework that learns a common multimodal embedding space that, in addition to sharing representations across different modalities, enforces a grouping of semantically similar instances. To this end, we extend the concept of instance-level contrastive learning with a multimodal clustering step in the training pipeline to capture semantic similarities across modalities. The resulting embedding space enables retrieval of samples across all modalities, even from unseen datasets and different domains. To evaluate our approach, we train our model on the HowTo100M dataset and evaluate its zero-shot retrieval capabilities in two challenging domains, namely text-to-video retrieval, and temporal action localization, showing state-of-the-art results on four different datasets.
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
Apr 22, 2021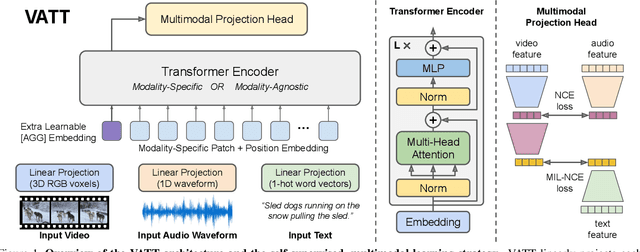
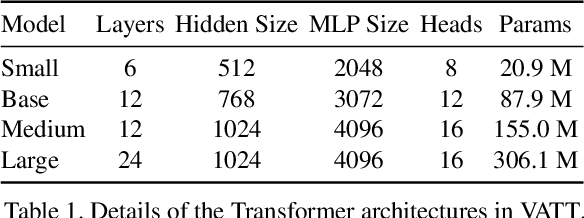
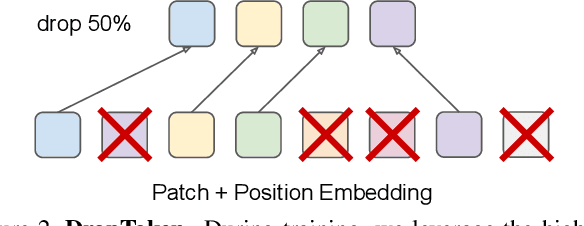
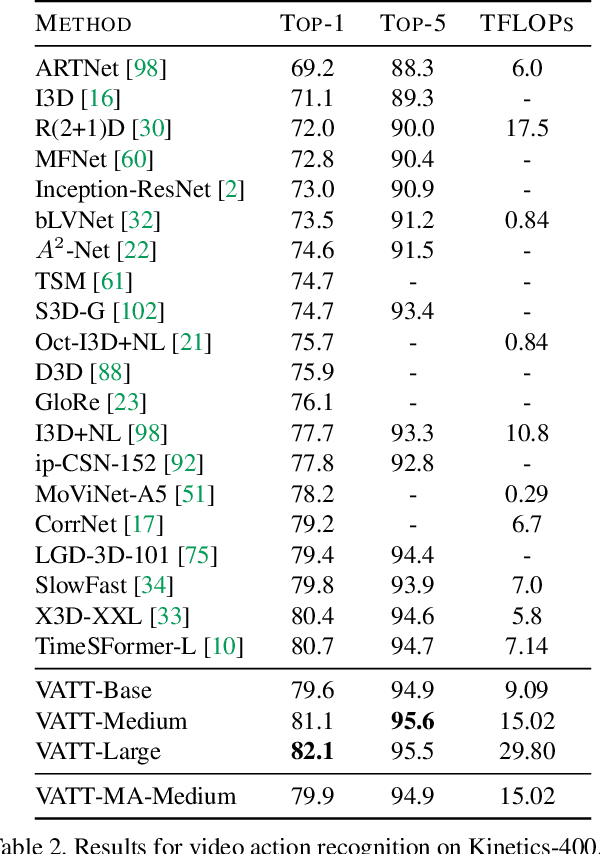
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures. Specifically, our Video-Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multimodal representations that are rich enough to benefit a variety of downstream tasks. We train VATT end-to-end from scratch using multimodal contrastive losses and evaluate its performance by the downstream tasks of video action recognition, audio event classification, image classification, and text-to-video retrieval. Furthermore, we study a modality-agnostic single-backbone Transformer by sharing weights among the three modalities. We show that the convolution-free VATT outperforms state-of-the-art ConvNet-based architectures in the downstream tasks. Especially, VATT's vision Transformer achieves the top-1 accuracy of 82.1% on Kinetics-400, 83.6% on Kinetics-600,and 41.1% on Moments in Time, new records while avoiding supervised pre-training. Transferring to image classification leads to 78.7% top-1 accuracy on ImageNet compared to 64.7% by training the same Transformer from scratch, showing the generalizability of our model despite the domain gap between videos and images. VATT's audio Transformer also sets a new record on waveform-based audio event recognition by achieving the mAP of 39.4% on AudioSet without any supervised pre-training.
Meta Faster R-CNN: Towards Accurate Few-Shot Object Detection with Attentive Feature Alignment
Apr 15, 2021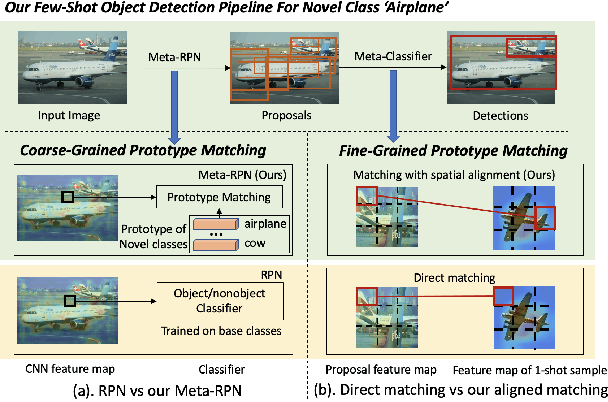
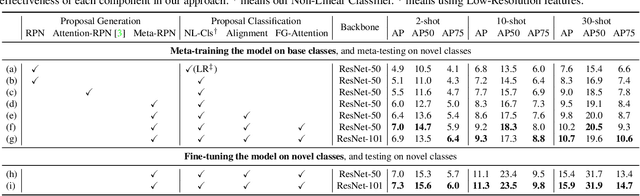
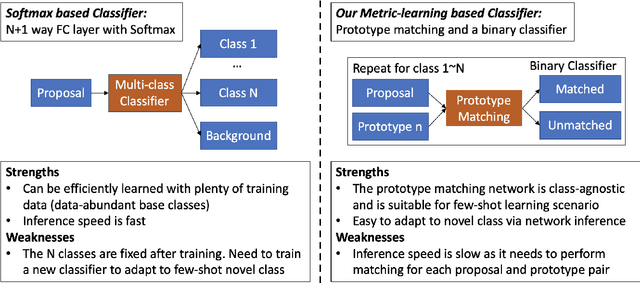
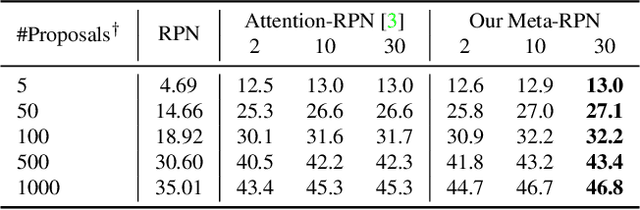
Few-shot object detection (FSOD) aims to detect objects using only few examples. It's critically needed for many practical applications but so far remains challenging. We propose a meta-learning based few-shot object detection method by transferring meta-knowledge learned from data-abundant base classes to data-scarce novel classes. Our method incorporates a coarse-to-fine approach into the proposal based object detection framework and integrates prototype based classifiers into both the proposal generation and classification stages. To improve proposal generation for few-shot novel classes, we propose to learn a lightweight matching network to measure the similarity between each spatial position in the query image feature map and spatially-pooled class features, instead of the traditional object/nonobject classifier, thus generating category-specific proposals and improving proposal recall for novel classes. To address the spatial misalignment between generated proposals and few-shot class examples, we propose a novel attentive feature alignment method, thus improving the performance of few-shot object detection. Meanwhile we jointly learn a Faster R-CNN detection head for base classes. Extensive experiments conducted on multiple FSOD benchmarks show our proposed approach achieves state of the art results under (incremental) few-shot learning settings.
Co-Grounding Networks with Semantic Attention for Referring Expression Comprehension in Videos
Mar 23, 2021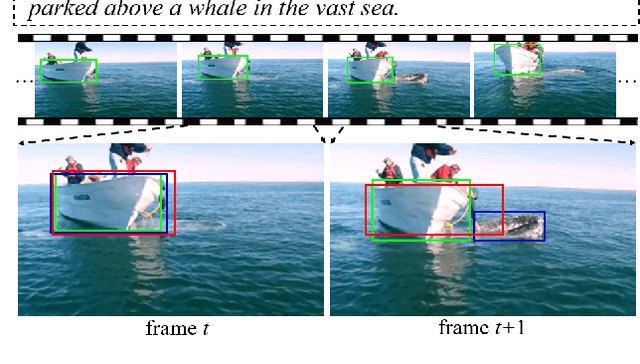
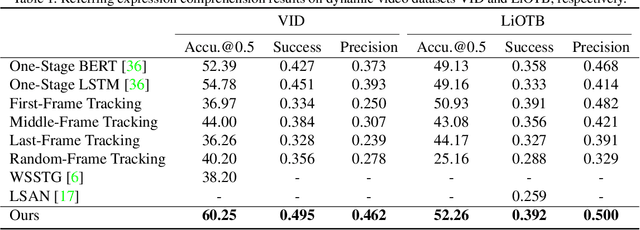
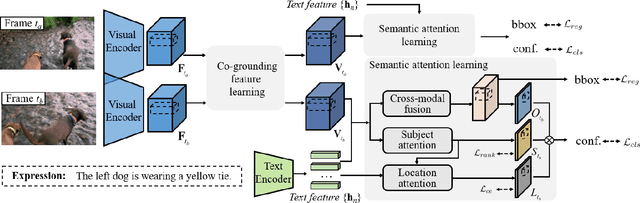
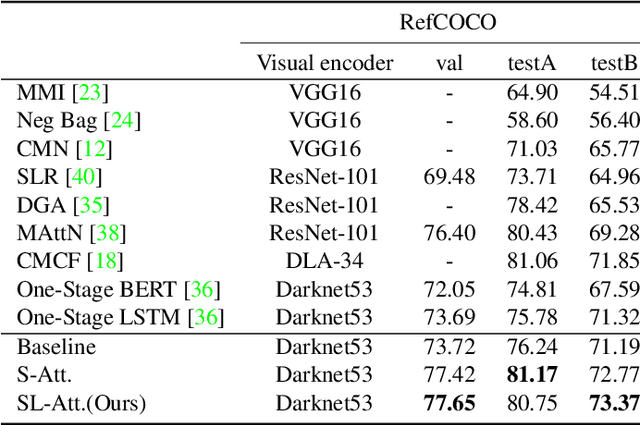
In this paper, we address the problem of referring expression comprehension in videos, which is challenging due to complex expression and scene dynamics. Unlike previous methods which solve the problem in multiple stages (i.e., tracking, proposal-based matching), we tackle the problem from a novel perspective, \textbf{co-grounding}, with an elegant one-stage framework. We enhance the single-frame grounding accuracy by semantic attention learning and improve the cross-frame grounding consistency with co-grounding feature learning. Semantic attention learning explicitly parses referring cues in different attributes to reduce the ambiguity in the complex expression. Co-grounding feature learning boosts visual feature representations by integrating temporal correlation to reduce the ambiguity caused by scene dynamics. Experiment results demonstrate the superiority of our framework on the video grounding datasets VID and LiOTB in generating accurate and stable results across frames. Our model is also applicable to referring expression comprehension in images, illustrated by the improved performance on the RefCOCO dataset. Our project is available at https://sijiesong.github.io/co-grounding.
VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs
Jan 29, 2021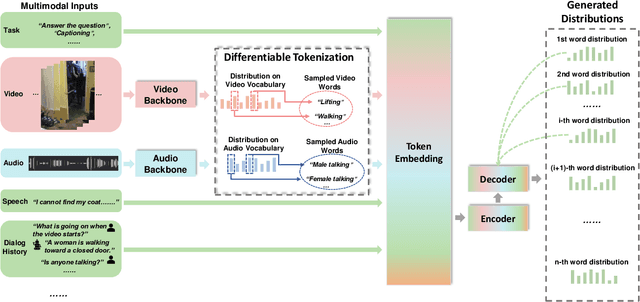



We present \textsc{Vx2Text}, a framework for text generation from multimodal inputs consisting of video plus text, speech, or audio. In order to leverage transformer networks, which have been shown to be effective at modeling language, each modality is first converted into a set of language embeddings by a learnable tokenizer. This allows our approach to perform multimodal fusion in the language space, thus eliminating the need for ad-hoc cross-modal fusion modules. To address the non-differentiability of tokenization on continuous inputs (e.g., video or audio), we utilize a relaxation scheme that enables end-to-end training. Furthermore, unlike prior encoder-only models, our network includes an autoregressive decoder to generate open-ended text from the multimodal embeddings fused by the language encoder. This renders our approach fully generative and makes it directly applicable to different "video+$x$ to text" problems without the need to design specialized network heads for each task. The proposed framework is not only conceptually simple but also remarkably effective: experiments demonstrate that our approach based on a single architecture outperforms the state-of-the-art on three video-based text-generation tasks -- captioning, question answering and audio-visual scene-aware dialog.
Task-Adaptive Negative Class Envision for Few-Shot Open-Set Recognition
Dec 24, 2020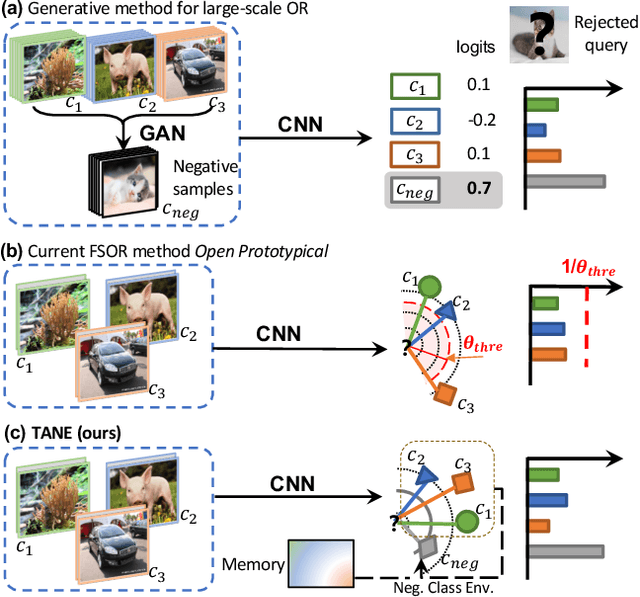
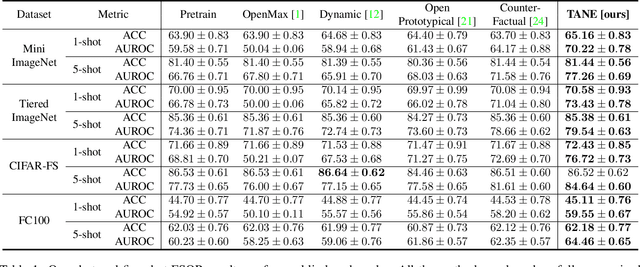
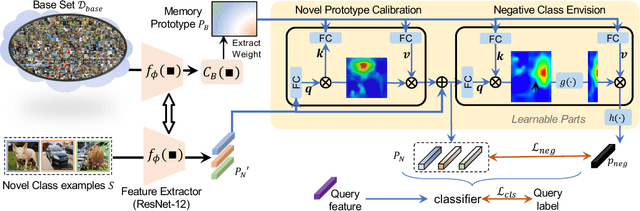
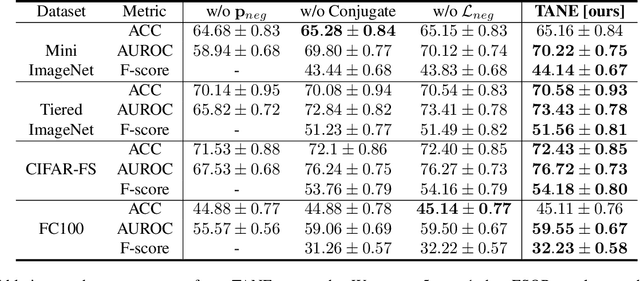
Recent works seek to endow recognition systems with the ability to handle the open world. Few shot learning aims for fast learning of new classes from limited examples, while open-set recognition considers unknown negative class from the open world. In this paper, we study the problem of few-shot open-set recognition (FSOR), which learns a recognition system robust to queries from new sources with few examples and from unknown open sources. To achieve that, we mimic human capability of envisioning new concepts from prior knowledge, and propose a novel task-adaptive negative class envision method (TANE) to model the open world. Essentially we use an external memory to estimate a negative class representation. Moreover, we introduce a novel conjugate episode training strategy that strengthens the learning process. Extensive experiments on four public benchmarks show that our approach significantly improves the state-of-the-art performance on few-shot open-set recognition. Besides, we extend our method to generalized few-shot open-set recognition (GFSOR), where we also achieve performance gains on MiniImageNet.